钉钉设置jira机器人_这是当您机器学习JIRA票证时发生的事情
钉钉设置jira机器人
For software developers, one of the most-debated and maybe even most-hated questions is “…and how long will it take?”. I’ve experienced those discussions myself, which oftentimes lacked precise information on the requirements. What I’ve learned is: If only sparse information is available, a reliable estimate is almost impossible. To make matters worse, developers found themselves under pressure after having issued a wild guess and then requiring more time.
对于软件开发人员而言,最受争议甚至最讨厌的问题之一是“……需要多长时间?”。 我自己经历了这些讨论,而这些讨论通常缺少有关要求的准确信息。 我了解到的是:如果只有稀疏信息可用,那么几乎不可能进行可靠的估计。 更糟糕的是,开发人员在做出了疯狂的猜测之后发现自己处于压力之下,然后需要更多的时间。
体验另一面 (Experiencing the other side)
As I started working in direct contact with customers, I’ve (reluctantly) realized that the collaboration oftentimes benefits from providing a schedule. In my experience, time becomes an important factor when customers have plans and projects on their own which can’t continue without knowing when a missing piece arrives.
当我开始与客户直接联系时,我(很不情愿地)意识到,协作通常可以从提供计划中受益。 根据我的经验,当客户自己制定计划和项目时,时间变得很重要,而计划和项目无法不知道丢失的零件何时到达。
相互理解(业务理解) (Understanding each other (Business Understanding))
In the end, this comes down to a simple problem: “How can managers and developers work together on a project and get what they, respectively, need?”. For those who interact with a customer, this means that they need the information (estimates) to make the collaboration go smoothly. In turn, developers need accurate requirements and some flexibility has to be respected as well.
最后,这归结为一个简单的问题:“管理人员和开发人员如何才能共同完成一个项目,并分别获得他们需要的东西?”。 对于那些与客户互动的人来说,这意味着他们需要信息(估算)来使协作顺利进行。 反过来,开发人员需要准确的要求,并且还必须尊重一些灵活性。
学习! (Learn!)
With that in mind, I’ve decided to use a data-science-driven approach to gain insights into the estimation problem. You can find the code that I used and more detailed technical explanations in my github repository. What I wanted to know, was:
考虑到这一点,我决定使用数据科学驱动的方法来深入了解估计问题。 您可以在github存储库中找到我使用的代码以及更详细的技术说明。 我想知道的是:
- As a baseline reference, what are the average times that a “New Feature”, “Bug” (etc) spends in implementation (i.e. status “in progress”)?作为基准参考,“新功能”,“错误”(等)在实施(即状态“进行中”)上花费的平均时间是多少?
- Is it possible to estimate the time spent “in progress” from analyzing the text in the summary and description of a ticket?是否可以通过分析票证摘要和说明中的文本来估计“进行中”所花费的时间?
- Which words in the description make up for large / small durations?说明中的哪些词组成了较长/较短的持续时间?
数据理解 (Data Understanding)
As data, I gathered around 20.000 tickets from the RTFACT-repository of the JFrog open source project. For all tickets, the following is available: Issuetype (i.e. “Bug”, “New Feature”), summary, description, time spent “in progress”. Some initial data exploration showed, that out of all the tickets, only 10% (2258) have a nonzero “in progress”-time. All the others have not been worked at or they were never put in that status.
作为数据,我从JFrog开源项目的RTFACT存储库中收集了大约20.000张票证。 对于所有票证,以下内容可用:发行类型(即“错误”,“新功能”),摘要,描述,“进行中”所花费的时间。 一些初步的数据研究表明,在所有故障单中,只有10%(2258)的“进行中”时间为非零。 所有其他人都没有工作过,或者从未处于这种状态。
To get a feeling for the data, I checked the counts of tickets by their issuetype. And as you can see in the next image, there is a large variation in the types with the highest count being Bugs.
为了了解数据,我按票证发行类型检查了票数。 正如您在下一张图片中看到的那样,类型之间的差异很大,其中错误最多。

准备数据 (Prepare Data)
As a first cleaning step, I only kept entries with a non-zero “in progress”-time and removed outliers (outside of the 96%-quantile). Now, keep in mind that statistical models can only understand numbers, not text. To translate between strings of characters, I computed TFIDF text analysis features. These are a way of numerically representing the occurrence and importance of certain words in a text document.
作为第一步清理,我只保留“进行中”时间为非零的条目,并删除了异常值(在96%的位数之外)。 现在,请记住,统计模型只能理解数字,而不能理解文本。 为了在字符串之间进行翻译,我计算了TFIDF文本分析功能。 这是一种数字表示文本文档中某些单词的出现和重要性的方法。
资料建模 (Data Modeling)
A powerful and insightful model for analyzing data are decision trees / random forests. One branch of that type of model are gradient boosted trees. These are my model of choice due to their performance (won several Kaggle competitions) and their interpretability. This mainly means, that we can draw further insight from the decisions made in the trees.
决策树/随机森林是分析数据的强大而有见地的模型。 这种模型的一个分支是梯度增强树 。 由于它们的表现(赢得了几次Kaggle比赛)和可解释性,这些是我选择的模型。 这主要意味着,我们可以从树中做出的决策中获得更多的见解。
评估结果 (Evaluate the Results)
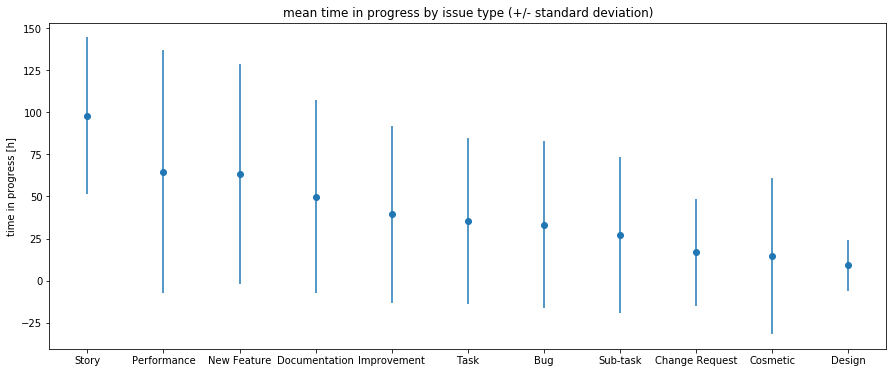
So, the first question asked regarded a baseline for the duration of a ticket. As you can see in the next image, the mean duration spans between ~10h and ~100h. Note, that the standard deviation is very large (~50 or higher), which calls for additional estimation information through e.g. the boosted trees.
因此,首先要问的问题是机票期限的基准。 如下图所示,平均持续时间介于〜10h和〜100h之间。 请注意,标准偏差非常大(〜50或更高),这需要通过增强树等其他估算信息。
For the trees, the performance is good (and can be tuned to “great”) — on the training set. However, on the test set, the model generalized badly. This is, why I captioned this article by “early results”. As you can see in the next image, the ground truth (blue) deviates significantly from the estimated values (orange).
对于树木而言, 训练集上的表现很好(并且可以调整为“出色”)。 但是,在测试集上,该模型的推广效果很差。 这就是为什么我用“早期结果”为本文加上标题。 如您在下一张图片中所看到的,地面实况(蓝色)与估计值(橙色)明显不同。

I think it’s still interesting to take a look at the keywords contribute in a positive way (larger time “in progress”) or a negative way (smaller time “in progress”):
我认为,以积极的方式(较长的时间在“进行中”)或否定的方式(较短的时间在“进行中”)查看关键字贡献是很有趣的:

As you can see from the results, the issue types “Bug” and “New Feature” have the largest positive impact on the estimation. On the other end of the spectrum are the “error” and “com”, which have the largest negative impact on the estimation. For the top 15 words that cause the highest positive / negative impact, see the figure below.
从结果中可以看出,问题类型“错误”和“新功能”对估计的影响最大。 另一方面,“误差”和“ com”对估计的负面影响最大。 有关正面/负面影响最大的前15个字,请参见下图。
未来的工作 (Future Work)
What else needs to be done?
还有什么需要做的?
- The dataset is not very large (the model had to be trained based on only ~2200 valid samples). The next step would be to find a ticket repository with a larger number of valid tickets.数据集不是很大(必须仅基于约2200个有效样本来训练模型)。 下一步将是查找具有大量有效票证的票证存储库。
instead of only estimating the implementation time (time “in progress”), the cycle time is possibly as well interesting to know
不仅可以估计实施时间(“进行中”的时间 ),还可以了解周期时间
- Is it possible to estimate (classify) the ‘resolution’ (Fixed, Duplicate, Won’t Fix, …) of a ticket?是否可以估计(分类)票证的“解决方案”(固定,重复,无法解决……)?
谢谢 (Thanks)
This was my first article on medium! Thanks a lot for taking the time. If you have any feedback or insights that you’d like to share: I’d be glad to get some feedback.
这是我关于媒体的第一篇文章! 非常感谢您抽出宝贵的时间。 如果您想分享任何反馈或见解:很高兴获得一些反馈。
翻译自: https://medium.com/@steffen.herbort/early-results-this-is-what-happens-when-you-machine-learn-jira-tickets-1ea0d82f39fa
钉钉设置jira机器人
http://www.taodudu.cc/news/show-997501.html
相关文章:
- 小程序点击地图气泡获取气泡_气泡上的气泡
- PopTheBubble —测量媒体偏差的产品创意
- 面向Tableau开发人员的Python简要介绍(第3部分)
- pymc3使用_使用PyMC3了解飞机事故趋势
- 吴恩达神经网络1-2-2_图神经网络进行药物发现-第2部分
- 数据图表可视化_数据可视化十大最有用的图表
- 接facebook广告_Facebook广告分析
- eda可视化_5用于探索性数据分析(EDA)的高级可视化
- css跑道_如何不超出跑道:计划种子的简单方法
- 熊猫数据集_为数据科学拆箱熊猫
- matplotlib可视化_使用Matplotlib改善可视化设计的5个魔术技巧
- 感知器 机器学习_机器学习感知器实现
- 快速排序简便记_建立和测试股票交易策略的快速简便方法
- 美剧迷失_迷失(机器)翻译
- 我如何预测10场英超联赛的确切结果
- 深度学习数据自动编码器_如何学习数据科学编码
- 图深度学习-第1部分
- 项目经济规模的估算方法_估算英国退欧的经济影响
- 机器学习 量子_量子机器学习:神经网络学习
- 爬虫神经网络_股市筛选和分析:在投资中使用网络爬虫,神经网络和回归分析...
- 双城记s001_双城记! (使用数据讲故事)
- rfm模型分析与客户细分_如何使用基于RFM的细分来确定最佳客户
- 数据仓库项目分析_数据分析项目:仓库库存
- 有没有改期末考试成绩的软件_如果考试成绩没有正常分配怎么办?
- 探索性数据分析(EDA):Python
- 写作工具_4种加快数据科学写作速度的工具
- 大数据(big data)_如何使用Big Query&Data Studio处理和可视化Google Cloud上的财务数据...
- 多元时间序列回归模型_多元时间序列分析和预测:将向量自回归(VAR)模型应用于实际的多元数据集...
- 数据分析和大数据哪个更吃香_处理数据,大数据甚至更大数据的17种策略
- 批梯度下降 随机梯度下降_梯度下降及其变体快速指南
钉钉设置jira机器人_这是当您机器学习JIRA票证时发生的事情相关推荐
- 单据点击套打设置报错,显示可用的套打单据列表时发生错误处理方法
单据点击套打设置报错,显示可用的套打单据列表时发生错误.提示如下: 请按照下列步骤操作: 1.登录 K/3 主控台后,依次单击[系统设置]→[系统设置]→[销售管理],双击[打印控制]: 2.打开[系 ...
- cad安装日志文件发生错误_安装软件提示“打开安装日志文件时发生错误”解决办法...
最近有朋友在安装loadrunner时发生报错,windows installer报错:打开安装日志文件时发生错误.请检查指定的日志文件位置是否存在并且可以写入. 造成报错的原因就是他之前安装过一次l ...
- 神码ai人工智能写作机器人_真正的人工智能和机器学习的未来
神码ai人工智能写作机器人 "Is there a true AI?" This is one question that a lot of experts in the indu ...
- excel怎么设置打印区域_在excel上怎么可以使打印时,将整个纸张占满?
excel打印时,将整个纸张占满方法: 1.打印预览:⑴ 页面设置:⑵ 页边距归零:⑶ 可以选择成居中:⑷ 页面:⑸ 选择成横向:⑹ 缩放比例放大到单页纸张允许的最大. 2.在"视图&quo ...
- python向钉钉发送本地文件_Python实现向钉钉群发送消息通知
一 钉钉机器人使用场景 钉钉机器人是钉钉群的高级扩展功能,可以简单实现将第三方服务信息聚合到钉钉群中,实现信息的自动同步,常用场景如下:聚合Github.Gitlab等源码管理服务,实现源码更新同步: ...
- 钉钉机器人怎么设置自动回复_项目部署成功后触发钉钉机器人发送消息提醒——入门配置...
钉钉建好一个群 打开群设置, 找到群机器人 添加一个你想要的机器人 可以使用自定义 自定义机器人可以自定义头像,名字,生成一个webhook(https post的请求地址) 到这里, 钉钉机器人设置 ...
- 钉钉机器人智能提醒_如何设置钉钉群通知
## 一.功能说明: 独创通过**钉钉群**或**企业微信群**实时通知 1.通知软件异常状态,如:微信掉线,联盟离线,授权过期等 2.手动提现审核通知(提现走手动,每一笔都会自动通知管理员) 3.自 ...
- 机器人聊天软件c#_使用python3.7配置开发钉钉群自定义机器人(2020年新版攻略)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_132 最近疫情比较严重,很多公司依靠阿里旗下的办公软件钉钉来进行远程办公,当然了,钉钉这个产品真的是让人一言难尽,要多难用有多难用 ...
- java消息推送怎么实现_调用钉钉接口实现机器人推送消息
一.摘要 现实交易中为了能及时了解发明者量化机器人交易状态,有时候我们需要将机器人所执行的交易结果发送到微信.邮箱.短信等等.但每天上百条各种各样的信息,使得对这些信息已经不敏感,导致重要的信息不能及 ...
最新文章
- 用jsp实现右导航窗格_不想升级操作系统,可以用这三种方法阻止Windows10更新
- 无法启动MySQL数据库
- WCF常见问题之端口共享
- C#和Java的对比
- 使用css的类名交集复合选择器
- JPA连接Mysql数据库时提示:Table 'jpa.sequence' dosen't exisit
- 小姐姐亲身体验:在阿里数据库科研团队实习是种怎样的体验?
- C语言深度剖析书籍学习记录 第四章 指针和数组
- maven打包可执行jar
- Android自定义图形shape
- Windows切换窗口
- Visual Basic 概述
- 如何生成SSH key?
- C语言数据结构-队列
- 安卓系统双屏异显_Android10模拟器上调试双屏异显
- 【毕设项目】新闻推荐平台功能详解----新闻推荐系统
- _exit(0) exit(0) exit(1) return区别
- 管理者运动初衷不是竞技,只为健康吗?
- Docker私有仓库与Harbor部署使用
- LVS负载均衡与DR模式