有没有改期末考试成绩的软件_如果考试成绩没有正常分配怎么办?
有没有改期末考试成绩的软件
Usually, when I tell you a student has got 90 marks, you would think this is a very good student. Instead, if I say the marks are 75, that probably means the student might be average. However, as a Data Scientist/Analyst, we need at least ask two questions immediately:
通常,当我告诉您一个学生获得90分时,您会认为这是一个非常好的学生。 相反,如果我说分数是75,则可能意味着该学生可能是平均水平。 但是,作为数据科学家/分析师,我们至少需要立即提出两个问题:
- Is the full mark 100?满分是100?
- What’s the distribution of the marks in the class?班上分数的分布是什么?
The first question is obviously important and perhaps everyone would ask because 90/150 is definitely not better than 75/100. The second question is a little bit subtle and possibly only a “data person” will have this sensitivity.
第一个问题显然很重要,也许每个人都会问,因为90/150绝对不比75/100好。 第二个问题有些微妙,可能只有“数据人”才具有这种敏感性。
In fact, in order to make sure an exam having its results normally distributed in the class, it is quite common to select exam questions as follows:
实际上,为了确保考试的成绩能在班级中正常分布,选择考试问题非常普遍,如下所示:
- Basic and easy questions — 70%基本问题和简单问题-70%
- Extended questions that will need a deep understanding of the knowledge — 20%需要深入了解知识的扩展问题-20%
- Difficult questions that will need to be solved with not only adequate knowledge but also some insights — 10%不仅需要足够的知识而且还需要一些洞察力来解决困难的问题-10%
What if we have 100% easy questions or 100% difficult questions? If so, we’re very likely to have results that are not normally distributed in a class.
如果我们有100%的简单问题或100%的困难问题怎么办? 如果是这样,我们很可能会获得不在类中正常分布的结果。
为什么我们需要规范化/标准化数据? (Why Do We Need to Normalise/Standardise Data?)

Then, we have our main topic now. I have been a tutor at a University for 5 years. It sometimes cannot be guaranteed that the exam questions are precisely followed the above proportions. To make sure it is fair to all the students, in other words, not too many students failed or too many students got A grades, sometimes we need to normalise the marks to make sure it follows the normal distribution.
然后,我们现在有了我们的主要主题。 我已经在大学任教5年了。 有时不能保证考试题准确地遵循上述比例。 为确保对所有学生公平,换句话说,没有太多的学生不及格或没有太多的学生获得A级,有时我们需要对分数进行归一化以确保其服从正态分布。
Also, when we want to compare students from different universities, or we want to aggregate the results of multiple exams, normalisation is also very important.
另外,当我们想比较来自不同大学的学生,或者想要汇总多次考试的结果时,标准化也很重要。
For demonstration purposes, Let’s suppose we have 5 different exams. Because we need to randomly generate the expected distribution, the following imports are needed.
为了演示的目的,我们假设我们有5种不同的考试。 因为我们需要随机生成期望的分布,所以需要以下导入。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom scipy.stats import skewnorm # used to generate skewed dist1.满分是100。基本问题太多 (1. Full mark is 100. Too many basic questions)
ex1 = np.array(skewnorm.rvs(a=-10, loc=95, scale=20, size=200)).astype(int)
2.满分为100。难题太多 (2. Full mark is 100. Too many difficult questions)
ex2 = np.array(skewnorm.rvs(a=5, loc=30, scale=20, size=200)).astype(int)
3.满分是100。正态分布 (3. Full mark is 100. Normally distributed)
ex3 = np.random.normal(70, 15, 200).astype(int)ex3 = ex3[ex3 <= 100]
4.满分是50。正态分布 (4. Full mark is 50. Normally distributed)
ex4 = np.random.normal(25, 7, 200).astype(int)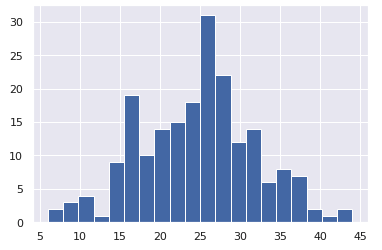
5.满分是200。正态分布 (5. Full mark is 200. Normally distributed)
ex5 = np.random.normal(120, 30, 200).astype(int)
Let’s plot them together using Seaborn distplot.
让我们使用Seaborn distplot它们绘制在一起。
plt.figure(figsize=(16,10))sns.distplot(ex1)sns.distplot(ex2)sns.distplot(ex3)sns.distplot(ex4)sns.distplot(ex5)plt.show()
It is very obvious that these 5 different exams have completely different distributions. When we get such a dataset, we can’t compare them directly.
很明显,这5种不同的考试分布完全不同。 当我们获得这样的数据集时,我们不能直接比较它们。
最小-最大归一化 (Min-Max Normalisation)

The basic idea of Min-Max Normalisation is to normalise all the values into the interval [0,1]. It is fairly easy to do this.
最小-最大归一化的基本思想是将所有值归一化为间隔[0,1]。 这很容易做到。
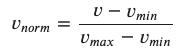
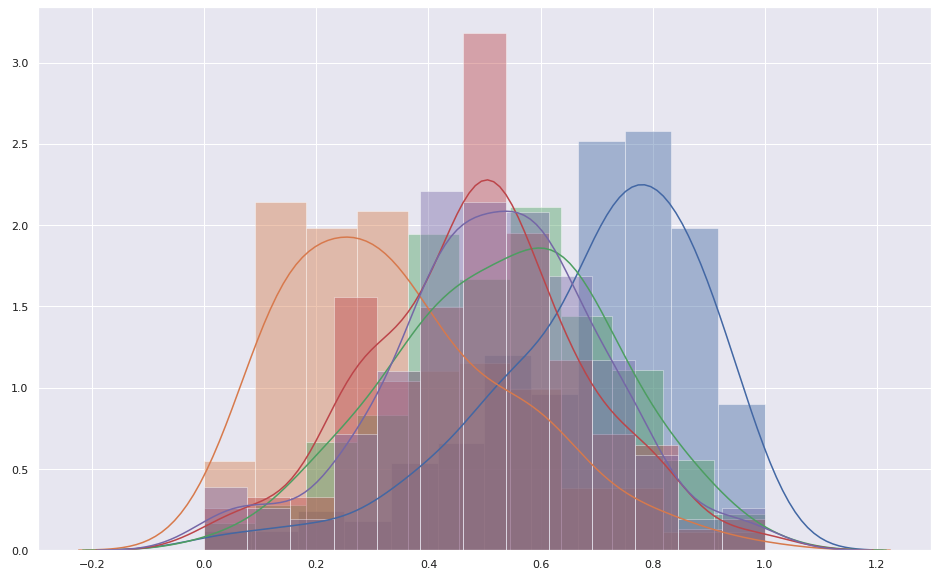
from sklearn import preprocessingmin_max_scaler = preprocessing.MinMaxScaler()ex1_norm_min_max = min_max_scaler.fit_transform(ex1.reshape(-1,1))ex2_norm_min_max = min_max_scaler.fit_transform(ex2.reshape(-1,1))ex3_norm_min_max = min_max_scaler.fit_transform(ex3.reshape(-1,1))ex4_norm_min_max = min_max_scaler.fit_transform(ex4.reshape(-1,1))ex5_norm_min_max = min_max_scaler.fit_transform(ex5.reshape(-1,1))Please be noticed that we need to convert our NumPy arrays into vectors before they can be normalised. So, the easiest way of doing this is to reshape them into column vectors reshape(-1, 1).
请注意,我们需要先将NumPy数组转换为向量,然后才能对其进行归一化。 因此,最简单的方法是将它们整形为列向量reshape(-1, 1) 。
After they are normalised, we don’t have to convert it back to a 1-D array to visualise. Below is the histogram after normalising. It is more confident now to put the 5 different exam results together.
将它们标准化后,我们不必将其转换回一维数组即可进行可视化。 以下是归一化后的直方图。 现在将5种不同的考试结果放在一起更有信心。
Z分数标准化 (Z-Score Standardisation)

Z-Score is another commonly used technique. It is called standardisation rather than normalisation because it “standardises” the data in two aspects:
Z分数是另一种常用的技术。 之所以称为标准化而不是标准化是因为它从两个方面“标准化”数据:
- De-mean the data so that all the standardised data will have their mean equals to zero.对数据进行去均值,以便所有标准化数据的均值等于零。
- Re-scale the data by dividing the standard deviation so that the data distribution will be either “expanded” or “shrank” based on the extent they deviate from the mean.通过划分标准偏差来重新缩放数据,以便根据数据偏离均值的程度来“扩大”或“缩小”数据分布。
Therefore, we can calculate it as follows.
因此,我们可以如下计算。

from sklearn import preprocessingex1_scaled = preprocessing.scale(ex1)ex2_scaled = preprocessing.scale(ex2)ex3_scaled = preprocessing.scale(ex3)ex4_scaled = preprocessing.scale(ex4)ex5_scaled = preprocessing.scale(ex5)
It can be seen that the Z-Score Standardisation not only normalised the exam results, but also re-scaled them.
可以看出,Z-Score标准化不仅规范了考试结果,而且还对它们进行了重新定标。
摘要 (Summary)

In this article, the exams are used as examples to explain why we need to normalise or standardise datasets. In fact, I have seen many learners and Data Science students who are really enthusiasts of algorithms. They may know many different types of data mining and machine learning algorithms. However, I would say that data transformation is more important than selecting an algorithm in most of the time.
在本文中,以考试为例来说明为什么我们需要标准化或标准化数据集。 实际上,我见过很多真正喜欢算法的学习者和数据科学专业的学生。 他们可能知道许多不同类型的数据挖掘和机器学习算法。 但是,我要说的是,在大多数情况下,数据转换比选择算法更重要。
Therefore, I have also demonstrated how to use the Python Sci-kit Learn library to easily normalise/standardise the data. Hope it helps someone who has just entered in the Data Science and Data Analytics area.
因此,我还演示了如何使用Python Sci-kit Learn库轻松地对数据进行标准化/标准化。 希望它对刚进入“数据科学和数据分析”区域的人有所帮助。
All the code used in this article can be found in this Google Colab Notebook.
本文中使用的所有代码都可以在此Google Colab笔记本中找到。
翻译自: https://towardsdatascience.com/what-if-the-exam-marks-are-not-normally-distributed-67e2d2d56286
有没有改期末考试成绩的软件
http://www.taodudu.cc/news/show-997477.html
相关文章:
- 探索性数据分析(EDA):Python
- 写作工具_4种加快数据科学写作速度的工具
- 大数据(big data)_如何使用Big Query&Data Studio处理和可视化Google Cloud上的财务数据...
- 多元时间序列回归模型_多元时间序列分析和预测:将向量自回归(VAR)模型应用于实际的多元数据集...
- 数据分析和大数据哪个更吃香_处理数据,大数据甚至更大数据的17种策略
- 批梯度下降 随机梯度下降_梯度下降及其变体快速指南
- 生存分析简介:Kaplan-Meier估计器
- 使用r语言做garch模型_使用GARCH估计货币波动率
- 方差偏差权衡_偏差偏差权衡:快速介绍
- 分节符缩写p_p值的缩写是什么?
- 机器学习 预测模型_使用机器学习模型预测心力衰竭的生存时间-第一部分
- Diffie Hellman密钥交换
- linkedin爬虫_您应该在LinkedIn上关注的8个人
- 前置交换机数据交换_我们的数据科学交换所
- 量子相干与量子纠缠_量子分类
- 知识力量_网络分析的力量
- marlin 三角洲_带火花的三角洲湖:什么和为什么?
- eda分析_EDA理论指南
- 简·雅各布斯指数第二部分:测试
- 抑郁症损伤神经细胞吗_使用神经网络探索COVID-19与抑郁症之间的联系
- 如何开始使用任何类型的数据? - 第1部分
- 机器学习图像源代码_使用带有代码的机器学习进行快速房地产图像分类
- COVID-19和世界幸福报告数据告诉我们什么?
- lisp语言是最好的语言_Lisp可能不是数据科学的最佳语言,但是我们仍然可以从中学到什么呢?...
- python pca主成分_超越“经典” PCA:功能主成分分析(FPCA)应用于使用Python的时间序列...
- 大数据平台构建_如何像产品一样构建数据平台
- 时间序列预测 时间因果建模_时间序列建模以预测投资基金的回报
- 贝塞尔修正_贝塞尔修正背后的推理:n-1
- php amazon-s3_推荐亚马逊电影-一种协作方法
- 简述yolo1-yolo3_使用YOLO框架进行对象检测的综合指南-第一部分
有没有改期末考试成绩的软件_如果考试成绩没有正常分配怎么办?相关推荐
- 考试大纲-青少年软件编程等级考试Python1-6级
考试大纲-青少年软件编程等级考试Python1-6级 Python一级 一.考试标准 二.考核目标 三.能力目标 四.知识块 五.知识点描述 六.题型配比及分值 Python二级 一.考试标准 二.考 ...
- 测试高考体育成绩的软件,高考体育考试项目内容及成绩评定标准
体育高考离我们也是越来越近了,想要参加体育考试的考生也要开始准备了.那么,高考体育考试项目的内容和成绩评定标准就非常有必要了解了. 高考体育考试考什么 其一是身体素质项目,一般规定为100米跑.5米三 ...
- 刷题神器怎么导入java,怎么导题库_有没有比较好的可以自己导入题库进行模拟考试练习的软件_淘题吧...
① 本人有一题库,怎么把里面的试题全部导出 题库都加密了,没有导出功能.只能固定抽题后,整理出来. ② 在线考试系统题库怎么导入数据库 优考试的考试系统导入题库是用word和excel的模板去编辑试题 ...
- 青少年软件编程等级考试 python-青少年软件编程等级考试Python(一级)
全国青少年软件编程等级考试是由中国电子学会发起的面向青少年机器人软件编程能力水平的社会化评价项目 .中国电子学会是工业和信息化部直属事业单位 ,是中国科学技术协会的团体会员单位. 全国青少年软件编程等 ...
- Java 成绩分析绘图_学生考试成绩分析的设计与实现
随着科学技术的不断提高,计算机科学日渐成熟,其强大的功能已为人们深刻认识,它已进入人类社会的各个领域并发挥着越来越重要的作用. 作为计算机应用的一部分,使用计算机对学生成绩信息进行管理,具有着手工管理 ...
- 学计算机等级考试电脑版软件,计算机二级考试宝典电脑版
计算机二级考试宝典电脑版是一款专业的二级计算机内容学习软件.该软件由武汉大学团队真情研发,软件包含选择题1600道,非选择题109套,成功实现了考点和重点的全面覆盖式学习目的,对学生们学习起到了巨大的 ...
- 测试学生成绩的软件,《软件测试-学生成绩管理系统》.doc
宿迁学院 软件测试 -学生成绩管理系统 姓名: ***** 班级:计算机(3)班 学号:****** 系部: 三 系 指导老师:***** 成绩: 目录 目录2 1引言3 1.1开发系统目标3 1.2 ...
- 无忧全国计算机等级考试超级模拟软件_一级计算机基础及MS Office应用安装教程
本套软件是根据国家教育部新考试大纲,并汇聚了多年开发全国计算机等级考试模拟软件的丰富经验,并综合有经验的命题专家.教授和全国各地考点一线教师的建议基础上研制而成.本套软件采用模拟考试形式,以大量的习题 ...
- python分析学生成绩的相关性_学生文理科成绩相关性分析
为简化学生成绩模型,将传统的语文.数学.英语.历史.政治.物理.化学降为文科.理科两个维度方便分析,现分别进行文科内.理科内成绩的相关性分析. Python代码: # encoding=utf-8 注 ...
最新文章
- 计算机右键功能总结,计算机基础知识:右键快捷菜单功能介绍
- IIS与ASP.NET管道
- 普通话测试系统_普通话
- Change Unidirectional Association to Bidirectional(将单向关联改为双向关联)
- 合并两个链表数据结构c语言,合并两个链表.
- 给P40让路!华为Mate 30 5G降至这个价,还贵吗?
- vsftpd 本地用户登录和上传设置
- 《图解HTTP》-读
- 直击前沿技术:云原生应用低代码开发平台实践
- centos yum源配置
- Scrum和TFS2010
- ieeetran_IEEEtran BibTex样式
- 苹果开发者后台,修改付费app中银行账户信息时注意
- 手写一个java爬虫,获取网页信息。
- 平面设计入门新手需看技巧
- 教育智能硬件站上了风口
- ffmpeg之mp4文件解封装截取一段视频并重封装
- python中global什么意思_python中的global关键字的使用方法
- matlab形态学降噪,基于MATLAB的荧光分子图像降噪方法
- Word基础(七)文字添加拼音