MYSQL性能优化详解(二)
接着上一篇学习:http://www.cnblogs.com/quanzhiguo/p/6401453.html
七、MySQL数据库Schema设计的性能优化
高效的模型设计
适度冗余-让Query尽两减少Join
大字段垂直分拆-summary表优化
大表水平分拆-基于类型的分拆优化
统计表-准实时优化
合适的数据类型
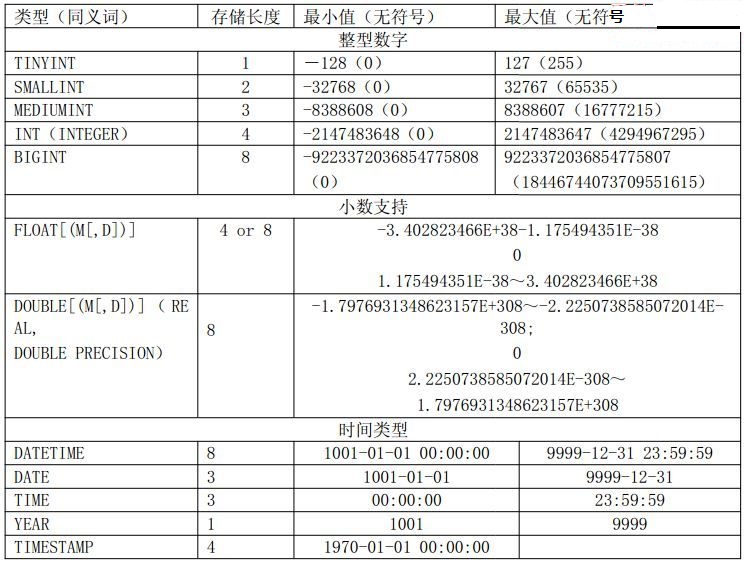
时间存储格式总类并不是太多,我们常用的主要就是DATETIME,DATE和TIMESTAMP这三种了。从存储空间来看TIMESTAMP最少,四个字节,而其他两种数据类型都是八个字节,多了一倍。而TIMESTAMP的缺点在于他只能存储从1970年之后的时间,而另外两种时间类型可以存放最早从1001年开始的时间。如果有需要存放早于1970年之前的时间的需求,我们必须放弃TIMESTAMP类型,但是只要我们不需要使用1970年之前的时间,最好尽量使用TIMESTAMP来减少存储空间的占用。
字符存储类型

CHAR[(M)]类型属于静态长度类型,存放长度完全以字符数来计算,所以最终的存储长度是基于字符集的,如latin1则最大存储长度为255字节,但是如果使用gbk则最大存储长度为510字节。CHAR类型的存储特点是不管我们实际存放多长数据,在数据库中都会存放M个字符,不够的通过空格补上,M默认为1。虽然CHAR会通过空格补齐存放的空间,但是在访问数据的时候,MySQL会忽略最后的所有空格,所以如果我们的实际数据中如果在最后确实需要空格,则不能使用CHAR类型来存放。
VARCHAR[(M)]属于动态存储长度类型,仅存占用实际存储数据的长度。TINYTEXT,TEXT,MEDIUMTEXT和LONGTEXT这四种类型同属于一种存储方式,都是动态存储长度类型,不同的仅仅是最大长度的限制。
事务优化
1. 脏读:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
2. 不可重复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
3. 幻读:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
Innodb在事务隔离级别方面支持的信息如下:
1.READ UNCOMMITTED
常被成为Dirty Reads(脏读),可以说是事务上的最低隔离级别:在普通的非锁定模式下SELECT的执行使我们看到的数据可能并不是查询发起时间点的数据,因而在这个隔离度下是非Consistent Reads(一致性读);
2.READ COMMITTED
这一隔离级别下,不会出现DirtyRead,但是可能出现Non-RepeatableReads(不可重复读)和PhantomReads(幻读)。
3. REPEATABLE READ
REPEATABLE READ隔离级别是InnoDB默认的事务隔离级。在REPEATABLE READ隔离级别下,不会出现DirtyReads,也不会出现Non-Repeatable Read,但是仍然存在PhantomReads的可能性。
4.SERIALIZABLE
SERIALIZABLE隔离级别是标准事务隔离级别中的最高级别。设置为SERIALIZABLE隔离级别之后,在事务中的任何时候所看到的数据都是事务启动时刻的状态,不论在这期间有没有其他事务已经修改了某些数据并提交。所以,SERIALIZABLE事务隔离级别下,PhantomReads也不会出现。
八、可扩展性设计之数据切分
数据的垂直切分
数据的垂直切分,也可以称之为纵向切分。将数据库想象成为由很多个一大块一大块的“数据块”(表)组成,我们垂直的将这些“数据块”切开,然后将他们分散到多台数据库主机上面。这样的切分方法就是一个垂直(纵向)的数据切分。
垂直切分的优点
◆数据库的拆分简单明了,拆分规则明确;
◆应用程序模块清晰明确,整合容易;
◆数据维护方便易行,容易定位;
垂直切分的缺点
◆部分表关联无法在数据库级别完成,需要在程序中完成;
◆对于访问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求;
◆事务处理相对更为复杂;
◆切分达到一定程度之后,扩展性会遇到限制;
◆过读切分可能会带来系统过渡复杂而难以维护。
数据的水平切分
数据的垂直切分基本上可以简单的理解为按照表按照模块来切分数据,而水平切分就不再是按照表或者是功能模块来切分了。一般来说,简单的水平切分主要是将某个访问极其平凡的表再按照某个字段的某种规则来分散到多个表之中,每个表中包含一部分数据。
水平切分的优点
◆表关联基本能够在数据库端全部完成;
◆不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆应用程序端整体架构改动相对较少;
◆事务处理相对简单;
◆只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点
◆切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
◆后期数据的维护难度有所增加,人为手工定位数据更困难;
◆应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
数据切分与整合中可能存在的问题
1.引入分布式事务的问题
完全可以将一个跨多个数据库的分布式事务分拆成多个仅处于单个数据库上面的小事务,并通过应用程序来总控各个小事务。当然,这样作的要求就是我们的俄应用程序必须要有足够的健壮性,当然也会给应用程序带来一些技术难度。
2.跨节点Join的问题
推荐通过应用程序来进行处理,先在驱动表所在的MySQLServer中取出相应的驱动结果集,然后根据驱动结果集再到被驱动表所在的MySQL Server中取出相应的数据。
3.跨节点合并排序分页问题
从多个数据源并行的取数据,然后应用程序汇总处理。
九、可扩展性设计之Cache与Search的利用
通过引入Cache(Redis、Memcached),减少数据库的访问,增加性能。
通过引入Search(Lucene、Solr、ElasticSearch),利用搜索引擎高效的全文索引和分词算法,以及高效的数据检索实现,来解决数据库和传统的Cache软件完全无法解决的全文模糊搜索、分类统计查询等功能。
以上就是本文的全部内容,希望大家可以喜欢。
转载于:https://www.cnblogs.com/quanzhiguo/p/6401551.html
MYSQL性能优化详解(二)相关推荐
- mysql --skip-locking_skip-external-locking – MySQL性能参数详解
skip-external-locking – MySQL性能参数详解 MySQL的配置文件my.cnf中默认存在一行skip-external-locking的参数,即"跳过外部锁定&qu ...
- 一零四、前端性能优化详解
1 前端性能优化 介绍 页面性能优化 浏览器 浏览器的主要作用 浏览器的组成结构 浏览器是多进程的 浏览器的渲染机制 重排reflow与重绘repaint 页面加载缓慢的原因 浏览器部分 代码部分 优 ...
- logback性能优化详解
前言 不正确的日志打印不但会降低程序运行性能,还会占用大量IO资源和硬盘存储空间. 本文主要总结一些能提高日志打印性能的手段. 一.通过AsyncAppender异步输出日志 我们通常使用的Conso ...
- Mysql索引优化详解
索引优化分析详解: http://liucw.cn/2018/01/07/mysql/%E7%B4%A2%E5%BC%95%E4%BC%98%E5%8C%96%E5%88%86%E6%9E%90/
- 转载:SqlServer数据库性能优化详解
本文转载自:http://blog.csdn.net/andylaudotnet/article/details/1763573 性能调节的目的是通过将网络流通.磁盘 I/O 和 CPU 时间减到最小 ...
- T- SQL性能优化详解
http://www.cnblogs.com/Shaina/archive/2012/04/22/2464576.html 故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较 ...
- JavaScript性能优化详解
性能优化介绍 性能优化是不可避免的 无处不在的前端性能优化 function func(){arr = []arr[100000] = 'lg is a dog' } func() JavaScrip ...
- Android UI性能优化详解
此文来自于MrPeak杂货铺,由于没法转载,只能贴这了,妄作者见谅:http://mrpeak.cn/android/2016/01/11/android-performance-ui 设计师,开发人 ...
- postgresql 开启大页_Postgresql-11.X 性能优化详解
系统优化 修改 /etc/grub.conf 关闭 numa=off ,修改磁盘IO调度方式 elevator=deadline 修改方法: grubby --update-kernel=ALL -- ...
最新文章
- python处理流程-python的处理流程
- css( div和span)——读书笔记
- svc android,在android中,如何使用 Svc WCF服务_android_开发99编程知识库
- c语言中如何取消最后一个空格,新人提问:如何将输出时每行最后一个空格删除...
- 工作215:打印出父子组件的this
- tomcat jsvc java_opts_Tomcat 学习笔记(2) - 使用 jsvc 启动tomcat
- C++:获取图片文件信息-图片名称、类型、像素宽高
- IBM打造云访问量子计算机 规模仅相当于D-Wave系统的四百分之一
- Filecoin Gas基础费率降至0.23 nanoFIL
- 【大数据部落】R语言多元Copula GARCH 模型时间序列预测
- 「运维有小邓」三款性价比超高的AD域管理工具
- 推送微信公众号模板消息通知(Java版)
- Python 制作迷宫游戏(一)——地图
- CORTEX:我知道你在真笑还是假笑 | 前辅助运动区的激活与对笑声传染性和真实性的感知
- QT 水晶圆角按钮样式
- Spring Boot中的配置文件使用以及重新加载
- 怎么去搭建聚合支付系统比较划算
- XXXXXXX\android-sdk\\tools\zipalign.exe”无效
- 2022-iOS个人开发者账号申请流程
- AE基础教程第一阶段——18首选项设置
热门文章
- 手机调试python的软件_Appium+Python(ios真机移动端App H5混合自动化实战测试)
- matlab dir函数_MATLAB自动管理文件
- Chapter7-1_Overview of NLP Tasks
- 【Kaggle】Intermediate Machine Learning(XGBoost + Data Leakage)
- LeetCode 863. 二叉树中所有距离为 K 的结点(公共祖先/ DFS+BFS)
- 程序员面试金典 - 面试题 02.03. 删除中间节点
- LeetCode 133. 克隆图(图的BFS/DFS)
- fastdfs windows部署_Go在windows下编译Linux可执行文件
- 爬虫最基本的工作流程:内涵社区网站为例
- Matplotlib - 折线图 plot() 所有用法详解