python爬虫如何爬亚马逊_Python爬取当当、京东、亚马逊图书信息代码实例
注:1.本程序采用MSSQLserver数据库存储,请运行程序前手动修改程序开头处的数据库链接信息
2.需要bs4、requests、pymssql库支持
3.支持多线程
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\n爬取已经结束,即将关闭....')
os.system('pause')
main()
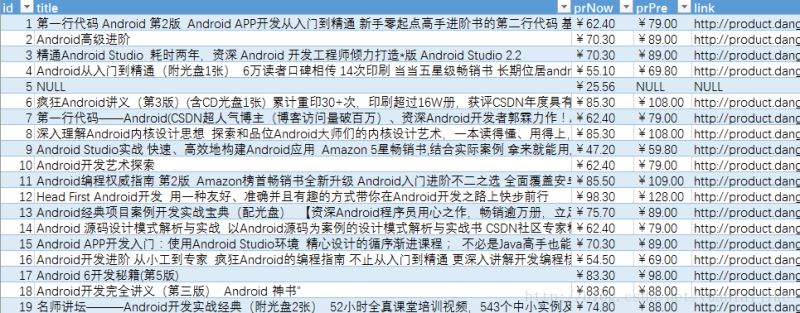
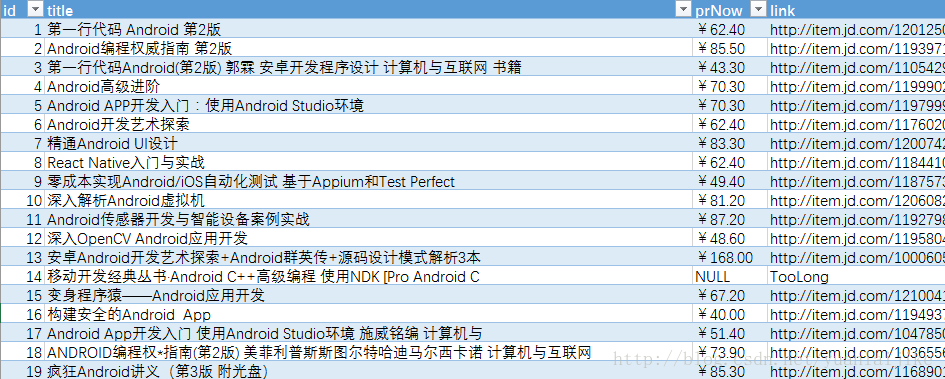
示例截图:
关键词:Android下的部分运行结果(以导出至Excel)

总结
以上就是本文关于Python爬取当当、京东、亚马逊图书信息代码实例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
python爬虫如何爬亚马逊_Python爬取当当、京东、亚马逊图书信息代码实例相关推荐
- python爬取京东书籍_Python爬取当当、京东、亚马逊图书信息代码实例
注:1.本程序采用MSSQLserver数据库存储,请运行程序前手动修改程序开头处的数据库链接信息 2.需要bs4.requests.pymssql库支持 3.支持多线程 from bs4 impor ...
- 在当当买了python怎么下载源代码-Python爬取当当、京东、亚马逊图书信息代码实例...
注:1.本程序采用MSSQLserver数据库存储,请运行程序前手动修改程序开头处的数据库链接信息 2.需要bs4.requests.pymssql库支持 3.支持多线程 from bs4 impor ...
- Python爬虫 离线爬取当当网畅销书Top500的图书信息
本实例还有另外的在线爬虫实现,有兴趣可点击在线爬取当当网畅销书Top500的图书信息 爬虫说明 1.使用requests和Lxml库爬取,(用BS4也很简单,这里是为了练习Xpath的语法) 2.爬虫 ...
- Python爬虫 在线爬取当当网畅销书Top500的图书信息
本实例还有另外的离线爬虫实现,有兴趣可点击离线爬取当当网畅销书Top500的图书信息 爬虫说明 1.使用requests和Lxml库爬取,(用BS4也很简单,这里是为了练习Xpath的语法) 2.爬虫 ...
- java爬取当当网所有分类的图书信息(ISBN,作者,出版社,价格,所属分类等)
java爬取当当网所有分类的图书信息(ISBN,作者,出版社,价格,所属分类等) 顺手写的,没有建立新项目,放我自己的项目的一个文件夹里了,有兴趣的朋友可以拉下来试试 https://gitee.co ...
- python模拟百度搜索点击链接_python采集百度搜索结果带有特定URL的链接代码实例...
这篇文章主要介绍了python采集百度搜索结果带有特定URL的链接代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #coding utf-8 ...
- python爬虫搜特定内容的论文_python爬取指定微信公众号文章
python怎么抓取微信阅清晨的阳光比不上你的一缕微笑那么动人,傍晚的彩霞比不上你的一声叹息那么心疼,你的一个个举动,一句句话语都给小编带来无尽的幸福. 抓取微信公众号的文章 一.思路分析 目前所知晓 ...
- python删除字典中性别为男_python初学者,用python3实现基本的学生管理系统代码实例...
本篇文章主要分享python学生管理系统的使用,文章非常详细地介绍了通过示例代码实现的学生管理系统,该系统对每个人的研究或工作都有一定的参考学习价值,希望你能在其中有所收获. 这个是用python实现 ...
- Python爬虫:最牛逼的 selenium爬取方式!
Python爬虫:最牛逼的 selenium爬取方式! 作为一个男人 在最高光的时刻 这是小编准备的python爬虫学习资料,加群:700341555即可免费获取! Python爬虫:最牛逼的 sel ...
最新文章
- 解决无法将类型为“System.Web.UI.WebControls.HiddenField”的对象强制转换为类型的错误...
- OAuth2.0学习(1-6)授权方式3-密码模式(Resource Owner Password Credentials Grant)
- 【职场】聊聊P5晋升P6之后
- boost::log模块测试样板,用于检查每个公共标头是否都是独立的并且没有任何缺失的 #includes
- rabbitmq中的消息有id吗_RabbitMQ 如何实现对同一个应用的多个节点进行广播
- Linux 基金会成立持续交付基金会
- xmapp mysql启动失败 Attempting to start MySQL service...
- 最新遇到的产品经理面试题
- linux 压缩文件夹.gz,Linux 系统 压缩和解压 gz 格式文件
- firewall和企业级的Open ViP服务
- Java九阳神功-内部类
- Hive自定义函数(字母大小写转换)
- 中亦安图oracle培训,【中亦安图】Systemstate Dump分析经典案例(8)
- 通过图新地球把大疆L1激光雷达点云成果和影像地形等其他GIS数据进行融合
- uniapp使用高德地图定位(兼容app)
- 从联想昭阳到MacBook Pro,致我的那些败家玩意——电脑
- Silverlight的未来【转于博客园】
- Linux_Shell脚本 + 配置文件:按照不同文件类型合并文件,小文件合并成大文件
- 前端性能优化方案都有哪些?
- pcm编码为aac/MP3格式ffmpeg(八)