【论文笔记】视频息肉分割VPS:Video Polyp Segmentation A Deep Learning Perspective
- 论文地址:VPS
- 代码地址:GitHub - GewelsJI/VPS: Video Polyp Segmentation (VPS)
- 数据集说明:VPS/DATA_PREPARATION.md at main · GewelsJI/VPS · GitHub
贡献:
- 效果:170fps
- 视频息肉分割数据集:SUN-SEG-Easy Dataset
- VPS Baseline:PNS+ (baseline是指基线,表示比该方法性能还低的是不能接受的)
- VPS Benchmark
针对:结肠息肉的多样性(如边界对比、形状、方向、拍摄角度)、内部伪影(如水流、残留物)和成像退化(如颜色失真、镜面反射)。
SUN-SEG数据集
在SUN数据集的基础上,增加了新的注释,包括物体掩码、边界、
![]()
网络架构
![]()
Global Encoder
将T帧序列中的第一帧(H’, W’, 3)作为锚点,通过全局编码器提取锚点特征Ah∈RHh×Wh×ChA^h ∈ R^{H^h×W^h×C^h}Ah∈RHh×Wh×Ch
Local Encoder
利用滑动窗口内的一块连续帧作为输入,利用编码器提取两组特征high和low
![]()
![]()
NS块
动态更新感受野
![]()
通道划分
得到Q、K、V矩阵(T * H * W * C)后,从通道维度化为N份,得到Qi,Ki,Vi∈RT×H×W×CN{Q_i, K_i, V_i}∈R^{T\times H\times W\times \frac{C}{N}}Qi,Ki,Vi∈RT×H×W×NC,分别输入N个self-attention模块
查询依赖规则
参考了:PCSA
为了对连续帧之间的时空关系进行建模,需要测量分割的查询特征(Qi)i=1N{(Q_i)}_{i=1}^N(Qi)i=1N和关键特征(Ki)i=1N{(K_i)}_{i=1}^N(Ki)i=1N之间的相似度,参考PCSA引入N个相关性测量块来计算目标像素的受限领域的空间-时间矩阵。
在Non-local中,计算的是Q中的像素与K中所有像素之间的关系,计算查询位置与所有位置关键特征之间的关系,而本文中的块是渐进的扩大特征块的范围
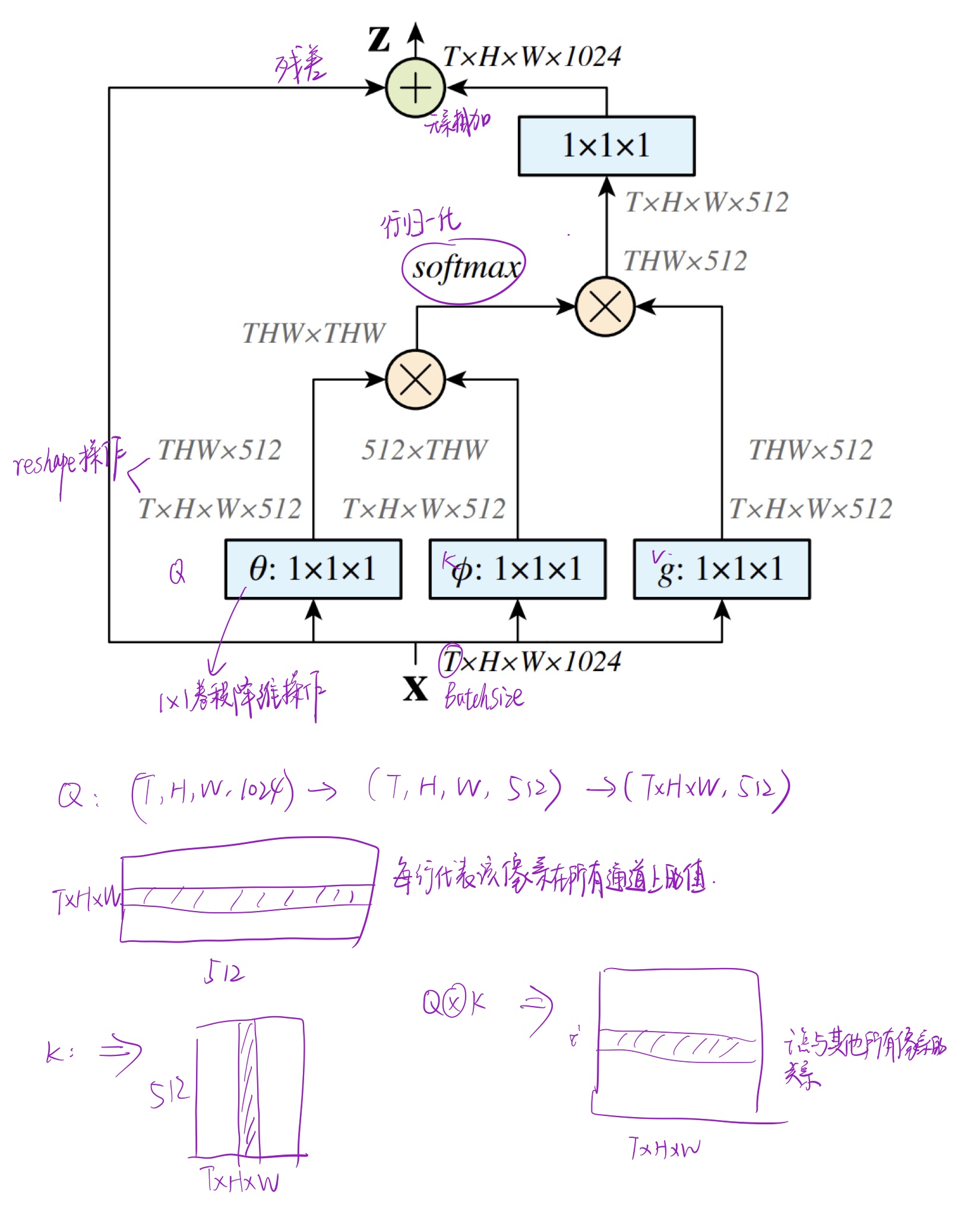
具体的说,就是类似于金字塔网络,给定QiQ_iQi矩阵的一个像素点XqX^qXq(更准确地说应该是高x,宽y,第z帧的所有C/8通道像素值),根据窗口的尺寸kkk和空洞卷积的扩张率did_idi,在KiK_iKi矩阵中选取高为(x−kdi,x+kdi)(x-kd_i,x+kd_i)(x−kdi,x+kdi),宽为(y−kdi,y+kdi)(y-kd_i,y+kd_i)(y−kdi,y+kdi),所有帧所有通道的像素值加起来,同时随着N个块中块数的增加,di=2i−1d_i=2i-1di=2i−1会增加,相当于要获取QiQ_iQi与更大范围的KiK_iKi之间的关系。类似于扩大感受野
![]()
归一化规则
对QiQ_iQi利用Norm()Norm()Norm()沿时间维度进行层归一化
Qi^=Norm(Qi)\hat{Q_i}=Norm(Q_i) Qi^=Norm(Qi)
相关性测量
最终的相关度计算公式,整体的形式与原始的transformer的自注意力公式是一样的
![]()
Spatial-Temporal(时空聚合)
与相似度计算类似,计算V矩阵与Q和K相似度结果,其实
![]()
其实整体的计算过程与transformer的自注意力机制是一样的,不过在计算像素之间的相关的方式改了
soft-attention
通过此模块融合相似度矩阵的特征MiAM^A_iMiA和时空聚合特征MiTM^T_iMiT,应该加强相关的时空模式,抑制弱相关的时空模式
先将一组相似度矩阵MiAM_i^AMiA沿通道维度串联起来,生成MAM^AMA
Max函数计算了MAM^AMA在通道维度上的最大值,然后将一组沿着通道维度的时空聚合特征MiTM^T_iMiT拼接生成MTM^TMT
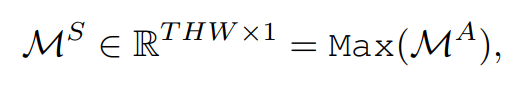
归一化的自注意力
WTW_TWT是可学习的权重,※表示通道式Hadamard积(矩阵对应元素相乘)
![]()
哈达玛积:
对于m×nm\times nm×n的两个矩阵A和B,相同位置元素相乘
(a11a12a13a21a22a23a31a32a33)∗(b11b12b13b21b22b23b31b32b33)=(a11b11a12b12a13b13a21b21a22b22a23b23a31b31a32b32a33b33)\left( \begin{matrix} a_{11}\ a_{12}\ a_{13}\\ a_{21}\ a_{22}\ a_{23}\\ a_{31}\ a_{32}\ a_{33}\\ \end{matrix} \right) * \left( \begin{matrix} b_{11}\ b_{12}\ b_{13}\\ b_{21}\ b_{22}\ b_{23}\\ b_{31}\ b_{32}\ b_{33}\\ \end{matrix} \right) = \left( \begin{matrix} a_{11}b_{11}\ a_{12}b_{12}\ a_{13}b_{13}\\ a_{21}b_{21}\ a_{22}b_{22}\ a_{23}b_{23}\\ a_{31}b_{31}\ a_{32}b_{32}\ a_{33}b_{33}\\ \end{matrix} \right) ⎝⎛a11 a12 a13a21 a22 a23a31 a32 a33⎠⎞∗⎝⎛b11 b12 b13b21 b22 b23b31 b32 b33⎠⎞=⎝⎛a11b11 a12b12 a13b13a21b21 a22b22 a23b23a31b31 a32b32 a33b33⎠⎞
NS块的输出
![]()
全局-局部学习策略
在任意的时间距离上实现长期和短期的时空传播
![]()
Global Spatial-Temporal Modeling
全局时空建模
第一个NS块来模拟任意时间距离的长期关系,需要四维的时间特征作为输入。
![]()
利用锚点特征AhA^hAh作为查询矩阵QgQ^gQg,采用局部编码器生成的high特征作为KgK^gKg和QgQ^gQg
目的是建立锚点和局部high特征之间的像素相似性,残差连接,得到ZgZ^gZg,其中+是逐元素相加
![]()
Global-to-Local Propagation
第二个NS块,将长距离依赖关系ZgZ^gZg传播到滑动窗口内的帧,将其作为第二个NS块的输入
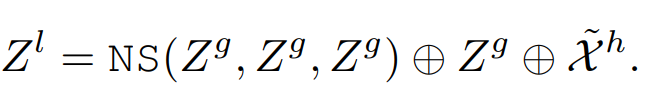
解码器
将局部编码器的low特征和第二个NS块的输出特征ZlZ^lZl恢复到空间形式,作为一个两级U-Net解码器的输入
![]()
利用二进制交叉熵损失进行优化
![]()
PCSA
CSA(受约束的self-attetion)专注于局部运动模式,而不是学习全局背景
考虑到突出物体可以有不同的尺寸,并以不同的速度移动,所以利用一组CSA形成金字塔结构
受约束的self-attention
将连续帧中的相关性测量和上下文约束到Q的邻近区域
比如下面这个图,第一帧中的物体与相邻帧中的物体有相似的位置,基于此,对于Q矩阵中的一个特征元素x(t, h, w),取其在K矩阵中的周围区域用来测量相关性,该区域被限制在帧:1-T,高:h-dr,h+dr,宽:w-dr,w+dr
![]()
金字塔的组合
这就是应用于PNS-Net中的参考
具有固定尺寸的单一的受约束的自注意力无法识别有各种速度和各种大小引起的移动目标,多头机制每个头都有不同的窗口大小和移动范围,以适应不同的运动情况
将多头与多尺度相结合
多头:并行的,将输入特征沿着通道分为g组,对每一组使用受约束的自注意力
mg-g44DU2tR-1653467435113)]
金字塔的组合
这就是应用于PNS-Net中的参考
具有固定尺寸的单一的受约束的自注意力无法识别有各种速度和各种大小引起的移动目标,多头机制每个头都有不同的窗口大小和移动范围,以适应不同的运动情况
将多头与多尺度相结合
多头:并行的,将输入特征沿着通道分为g组,对每一组使用受约束的自注意力
多尺度:不同的组,采用不同的窗口大小,d和r不同
【论文笔记】视频息肉分割VPS:Video Polyp Segmentation A Deep Learning Perspective相关推荐
- 虹膜识别论文1:Iris Recognition With Off-the-Shelf CNN Features: A Deep Learning Perspective 2017年 学习心得
论文百度一下 官网可以下载. 题目:Iris Recognition With Off-the-Shelf CNN Features: A Deep Learning Perspective 虹膜识别 ...
- 视频物体分割--One-Shot Video Object Segmentation
One-Shot Video Object Segmentation CVPR2017 http://www.vision.ee.ethz.ch/~cvlsegmentation/osvos/ One ...
- [论文笔记]图片语义分割 文献综述
原文:<基于深度学习的图像语义分割方法综述>2019_田萱,引用量=19 1.简介 是什么:ISS 为图像中的每一个像素分配一个预先定义好的表示其语义类别的标签.(田萱,2019) 与目标 ...
- enet分割_[论文笔记] 图像语义分割——ENet(ICLR 2017)
[论文笔记] 图像语义分割--ENet(ICLR 2017) bluestyle • 2019 年 05 月 03 日 介绍 Motivation: 移动应用上的实时像素级语义分割是一个重要的问题,然 ...
- 行为识别论文笔记|TSN|Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
行为识别论文笔记|TSN|Temporal Segment Networks: Towards Good Practices for Deep Action Recognition Temporal ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Brain tumor segmentation using deep learning +HybridResUnet脑胶质瘤分割BraTs +论文解读
Brain tumor segmentation using deep learning 下载地址 摘要 Brain tumor is one of the deadliest forms of ca ...
- 阅读笔记:What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
阅读笔记:What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? 1.介绍 2.相关工作 2.1 贝叶 ...
- 【医学+深度论文:F18】2019 Robust optic disc and cup segmentation with deep learning for glaucoma detection
18 2019 Computerized Medical Imaging and Graphics Robust optic disc and cup segmentation with deep l ...
最新文章
- oracle中的赋权
- Base64加密---加密学习笔记(一)
- 业务库负载翻了百倍,我做了什么来拯救MySQL架构
- iphone如何信任软件_【手机软件】千禾影院:全新观影神器,支持安卓+iOS,最新、最全、高清、免费!...
- ThinkPHP的增、删、改、查
- Flash发布iOS应用全攻略(二)——如何成为一个合法的iOS开发者
- 【CNN】94页论文综述卷积神经网络:从基础技术到研究前景
- Seek and Destroy
- android 可拖拽控件,安卓实现任意控件view可拖拽,并监听拖拽和点击事件,可自动拉回屏幕边缘...
- t3服务器一登录就运行时错误,用友T3软件登陆系统管理提示运行时错误3709
- 华为一员工猝死出租屋 警方初步排除他杀
- vs2015+openCV(x64)出现运行时”无法查找或打开 PDB 文件”问题
- 人生是一个连续的过程,没什么东西能影响人的一生,怎么选择不是问题。问题是每天都要努力 (转)...
- NEO改进协议提案2(NEP-2) 1
- Method.invoke
- Trinity安装全过程并解决部分报错
- html的代码怎麼格式化,怎么格式化html代码? Dreamweaver格式化html代码的技巧
- 港股打新丨放弃药明巨诺,搞蚂蚁金服
- c++ 中乘方的运算符是什么
- iOS极光推送和极光IM中的JCore冲突问题