论文阅读13:ENHANCING COLLABORATIVE FILTERING MUSIC RECOMMENDATION BY BALANCING EXPLORATION AND EXPLOITAT
参考论文:ENHANCING COLLABORATIVE FILTERING MUSIC RECOMMENDATION BY BALANCING EXPLORATION AND EXPLOITATION
知乎同文链接:https://zhuanlan.zhihu.com/p/41068720
通过平衡探索和开发,增强协同过滤音乐推荐
ABSTRACT
协同过滤技术在音乐推荐应用中取得了巨大的成功。然而,传统的协作过滤音乐推荐算法以greedy方式工作,总是推荐用户评分最高的歌曲。这种只有exploit的策略可能导致长期表现不佳。利用强化学习方法,我们将explore引入到CF中,并试图在exploit和explore之间找到平衡。为了了解用户的音乐品味,我们使用了考虑CF潜在因素和推荐新事物的贝叶斯图形模型。此外,我们设计了一种贝叶斯推理算法来有效地估计后验等级分布。在以往的音乐推荐中,这是第一次尝试去弥补CF的贪婪本性。仿真实验和用户研究的结果表明,我们提出的方法显著提高了推荐性能。
(本笔记只针对强化学习的引入)
INTRODUCTION
在音乐推荐领域,基于内容的方法和协作过滤(CF)方法是流行的推荐策略。基于内容的算法分析用户过去评价较高的歌曲的声学特征,只推荐具有较高声学相似性的歌曲。另一方面,协同过滤(CF)算法认为,根据与其有相似偏好的邻居得到好的建议。
这两个传统的推荐方法弱点是以一种贪婪的方式工作,他们总是通过选择具有最高预期用户评级的歌曲来产生“safe”推荐。这种纯粹的exploitative策略可能会由于缺乏exploring而导致在一段长时间内会表现不佳。原因是用户偏好的估计仅基于推荐系统中现有的知识。因此,不确定性现象总是存在于预测的用户评级中,并可能导致一些非贪婪方法被认为几乎和贪婪方法一样好,但实际上它们比贪婪选项更好。然而,没有exploring,我们永远不会知道哪个更好。通过适当的exploring,推荐系统可以在exploit之前获得更多用户真实偏好知识。
我们之前的工作试图缓解基于内容的音乐推荐中的贪心问题,但是没有在CF上解决这个问题。因此,我们打算开发一种基于cf的音乐推荐算法,在探索和开发之间取得平衡,提高长期的推荐性能。为此,我们探索引入协同过滤推荐问题通过制定音乐强化学习任务称为多臂老虎机问题。提出了一种考虑协同过滤潜在因素和推荐新颖性的贝叶斯图形模型来学习用户偏好。然而,当我们采用现成的马尔可夫链蒙特卡罗(MCMC)抽样算法进行贝叶斯后验估计时,效率的缺乏成为一个主要的挑战。因此,我们为贝叶斯推理设计一个更快的采样算法。我们进行了仿真实验和用户研究,以证明该方法的有效性和有效性。本文的贡献总结如下:
1、音乐推荐中第一个用强化学习方法研究探索-开发权衡来缓和CF贪婪性质
2、与现成的 MCMC algorithm相比,提出更有效的抽样算法加速贝叶斯后验估计。
3、实验结果表明,我们提出的方法显著提高了CF-based音乐推荐的性能。
RELATEDWORK
基于人们倾向于从具有相似偏好的人那里得到好的推荐的假设,协同过滤(CF)技术分为两类:基于近邻的CF和基于模型的CF。基于内存的CF算法[3,8]首先搜索与目标用户有相似评级历史的邻居。然后,目标用户的评级可以根据邻居的评级进行预测。基于模型的CF算法[7,14]使用各种模型和机器学习技术来发现潜在的因素来解释观察到的评级。
我们以前的工作[12]提出了强化学习的方法来平衡explore&exploit进行音乐推荐。然而,这项工作利用基于内容的方法。个性化用户评级模型的一个主要缺点是使用低层次的音频特性来表示歌曲的内容。这种纯粹基于内容的方法并不令人满意,因为低级音频特性和高级用户首选项之间存在语义差异。此外,很难确定哪些潜在的声学特性在音乐推荐场景中是有效的,因为这些特性最初不是为音乐推荐而设计的。另一个缺点是,基于内容的方法推荐的歌曲往往缺乏多样性,因为它们在声学上彼此相似。理想情况下,应该向用户提供一系列的类型,而不是一个同构的集合。
虽然没有人试图在音乐推荐中解决CF方法的贪心问题,Karimi等人试图在其他推荐应用中进行研究[4,5]。然而,他们的主动学习方法仅仅是在预先确定的测试集[4]上探索项目以优化预测精度,并没有重视explore&exploit的权衡问题不。在他们的其他工作中,推荐过程被分为两个步骤[5]。在explore步骤中,他们选择对用户参数有最大改变的item,然后在exploit步骤中,他们根据当前参数选择item。这项工作考虑到了探索和开发的平衡,但只是以一种临时的方式。此外,他们的方法仅使用离线和预先确定的数据集进行评估。最后,由于其算法效率较低,在在线推荐系统中应用不实用。
PROPOSED APPROACH
我们首先提出一个简单的矩阵分解模型的协同过滤(CF)音乐推荐。然后,我们指出传统CF算法的局限性,最后详细描述我们建议的方法。
3.1 Matrix Factorization for Collaborative Filtering
假设在音乐推荐系统中有m个用户和n首歌曲。让R 表示用户-歌曲评级矩阵,其中每个元素rij表示用户i给出的歌曲j的评级。矩阵分解通过潜在因素的向量来描述用户和歌曲。每个用户都都有一个特征向量ui,每首歌都有一个特征向量vj。对于给定的歌曲j, vj衡量的是歌曲包含潜在因素的程度。对于给定的用户i, ui度量他喜欢这些潜在因素的程度。因此,用户评分可以用这两个向量的内积来近似:

为了学习潜在的特征向量,系统最小化了训练集上的正规化平方误差:

这里I是指数组所有已知的评级,λ正则化参数,努伊评级由用户的数量,和歌曲j nvj评级的数量。我们使用交替最小二乘(ALS)[14]技术来最小化Eq。
传统CF推荐方法有两个主要的缺点。(一)缺乏推荐新颖性。对于用户来说,歌曲的新奇感会随着每次聆听而改变。(II)贪婪性质,总是推荐具有最高预期平均收视率的歌曲,而更好的方法可能是积极探索用户兴趣,而不是仅仅利用现有的评分信息[12]。针对这些不足,我们提出了一种基于cf的音乐推荐的强化学习方法。
3.2 A Reinforcement Learning Approach
音乐推荐是一个互动的过程。系统在n首不同的歌曲中反复选择推荐。在每次推荐之后,它会从一个未知的概率分布中得到一个评价反馈(或奖励),它的目标是最大化用户满意度,即从长远来看,预期的总回报。类似地,强化学习探索一个环境并采取行动最大化累积回报。因此,将音乐推荐作为强化学习任务,称为n-armed bandit是非常合适的。
n-armed bandit问题假定老虎机有n个杠杆,拉动一个杠杆产生的回报来自于未知概率分布。目标是在给定数量的动作选择(比如超过1000个动作)的基础上,使期望的总回报最大化。
3.2.1 Modeling User Rating,用户评分建模
为了解决传统推荐系统的第一个缺点,我们假设音乐评分受两个因素的影响:CF score(用户对歌曲的喜爱程度取决于每个CF潜在因素)和novelty score(一首歌动态变化的新颖程度)
根据用户评分公式,我们定义CF score ; θ是用户对于不同CF潜在特征的喜爱程度

定义novelty score : t表示最后一次听到这首歌的据当前的时间,s代表用户对于这首歌记忆的相对强度,e指数表示遗忘曲线
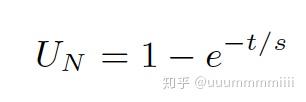
公式表示一首歌的新奇性当听过后会随着时间的推移立即减少。我们将这两个分数结合起来,对最终用户评分进行建模:

考虑到音乐偏好和记忆强度的变化,每个用户都有一对从用户评级历史中学到的参数Ω= (θ;s)。更多的技术细节将在第3.2.2节中解释。
由于预测用户评分总是伴随着不确定性,我们假设他们是随机变量,而不是固定的数字。让R.j表示目标用户给出的歌曲j的评级,R.j遵循一个未知的概率分布。我们假定U.j是R.j的期望。因此,预期的歌曲评级j可以估

传统的推荐策略首先获取系统中每首歌曲的vj和tj,利用Eq.(6)计算期望评级,然后推荐期望评级最高的歌曲。因为该系统利用当前用户评级的信息,我们称此为贪婪的推荐。通过选择一个非贪婪的推荐和收集更多的用户反馈,系统进一步探索和获得更多关于用户偏好的知识。
在当前迭代中,贪婪推荐可能会使预期的回报最大化,但从长期来看会导致性能不佳。这是因为一些非贪婪的建议可能一样好,但有大量的方差(或不确定性),因此可能其中的一些实际上比贪婪推荐更好。然而,没有探索,我们永远不会知道它们是什么。
因此,应对CF(缺点II)的贪婪的本性,我们将explore引入到音乐推荐中。为此,我们采用了一种最先进的算法,称为贝叶斯上置信度界(Bayes-UCB)[6]。在Bayes-UCB中,预期报酬Uj是一个随机变量,而不是一个固定值。考虑到目标用户的评级历史D,Uj的后验分布表示为p(Uj|D),需要估计。然后向目标用户推荐p(Uj|D)数值最高的歌曲。
3.2.2 Bayesian Graphical Model
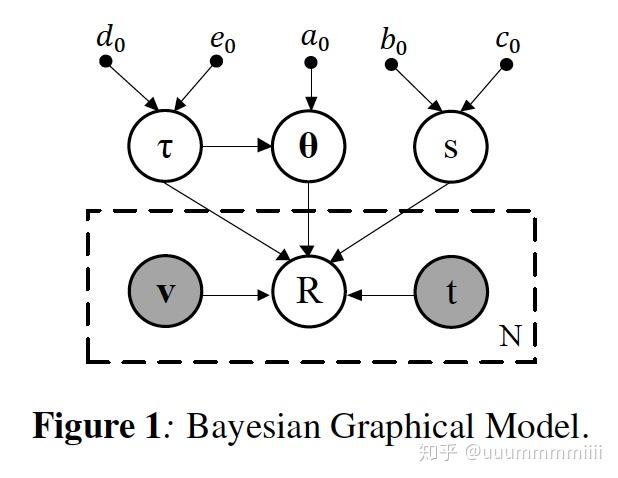
为了估计U的后验分布,我们采用[12]中使用的贝叶斯模型(图1)。对应的概率分布关系定义如下:

当前在当前第h+1次迭代中,我们收集了前h次观察到的推荐历史Dh。模型中的每个用户都被描述为Ω= (θ;s),根据贝叶斯定理:
![]()
那么,音乐j的评分的期望值Uj的后验概率密度函数(PDF)可以估计为:
![]()
由于Eq.(11)没有相近的形式解,我们无法直接估计Eq.(12)中的后验概率密度函数。因此,我们使用马尔可夫链蒙特卡洛(MCMC)算法来充分地采样参数Ω= (θ,s),然后将每个参数样本代入Eq.(6)得到一个Uj的样本。最后,PDF可以用直方图近似得到Uj。估计每首歌的后验PDF的预期评级,我们遵循Bayes-UCB方法最大化分位数函数,推荐歌曲j*
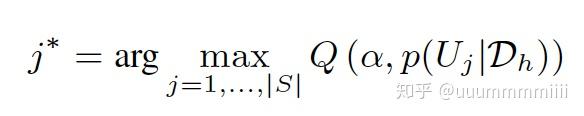
![]()
伪代码:


3.3没看
4. EVALUATION
4.1 Dataset
在“Million Song Dataset Challenge”中使用的Taste Profile Subset有超过4800万的(用户、歌曲、计数)三元信息描述了超过100万用户和38万首歌曲的听力历史。我们选择了2万首收听次数最多的歌曲,收听歌曲最多的10万用户。由于听力历史的收集是隐式反馈数据的一种形式,我们使用[11]中提出的方法进行负采样。最终数据集的详细统计数据如表1所示


论文阅读13:ENHANCING COLLABORATIVE FILTERING MUSIC RECOMMENDATION BY BALANCING EXPLORATION AND EXPLOITAT相关推荐
- [论文阅读] (13)英文论文模型设计(Model Design)如何撰写及精句摘抄——以入侵检测系统(IDS)为例
<娜璋带你读论文>系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢.由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学 ...
- 论文笔记(Neural Collaborative Filtering)
神经协同过滤 论文链接:Neural Collaborative Filtering, WWW'17 原理:融合 GMF 和 MLP 1. 摘要 虽然最近的一些研究使用深度学习作为推荐,但他们主要是用 ...
- 论文阅读笔记:Geography-Aware Sequential Location Recommendation
论文阅读笔记:Geography-Aware Sequential Location Recommendation 文章目录 论文阅读笔记:Geography-Aware Sequential Loc ...
- 论文笔记:Neural Collaborative Filtering
一.基本信息 论文题目:<Neural Collaborative Filtering> 发表时间:WWW 2017 作者及单位: 二.摘要 In recent years, deep n ...
- 论文笔记:Neural Collaborative Filtering(NCF)
前言 论文链接:https://arxiv.org/abs/1708.05031 github:https://github.com/yihong-chen/neural-collaborative- ...
- 论文笔记【Neural Collaborative Filtering】
标题 * 表示未完成 论文原文 本文使用基于神经网络的模型来分析 user 和 item 的潜在特征,最终设计出了一个基于神经网络的协同过滤通用框架(NCF).此框架融合了线性MF和非线性MLP模型. ...
- (论文阅读笔记1)Collaborative Metric Learning(一)(WWW2017)
一.摘要 度量学习算法产生的距离度量捕获数据之间的重要关系.这里,我们将度量学习和协同过滤联系起来,提出了协同度量学习(CML),它可以学习出一个共同的度量空间来编码用户偏好和user-user 和 ...
- 论文笔记《Item-based Collaborative Filtering Recommendation Algorithms》基于物品的协同过滤算法
这是一篇很经典的论文,2001年发表的.如果你已经很熟悉基于item的CF,那么这篇论文看起来就很舒适,很简单. 读完这篇论文还是能收获很多实验设计上知识,实验严谨性和论证.值得一读.
- 论文阅读《Knowledge Collaborative Fine-tuning for Low-resource Knowledge GraphCompletion》
论文链接 基于知识协同微调的低资源知识图谱补全方法 2022年3月发表于软件学报 是浙大prompt系列的一个延续 本文之前的工作: AdaPrompt: Adaptive Prompt-based ...
最新文章
- 数学与当代生命科学(吴家睿)
- 深入浅出SharePoint——数据库维护
- CentOS中配置VNC Server
- Android Monkey测试入门(摘)
- python web应用_如何使用Python将通知发送到Web应用
- 实现购物车的Session
- MyBatis3:SQL映射
- 机器学习- 吴恩达Andrew Ng 编程作业技巧
- yb3防爆电机型号含义_YB3防爆电机和YBX3防爆电机的区别
- 低频时码授时技术与中国电波钟表发展历程简介
- ps格式文件如何打开
- 惠州VOCs实验室建设:日常废气处理工艺
- mac 打开网页慢_Safari打开网页卡住或加载极慢问题解决方案
- 操作系统的基本特征、区别及功能
- geoserver osm 导入_OSM导入PostGreSQL数据库 | 学步园
- Burpsuite简单代理配置
- 使用Helm在k8s集群上部署以太坊私有链
- 人人都可以用的项目管理工具,5分钟告诉你如何做好活动策划
- 通过ipmitool监控机房内服务器温度
- MySQL自定义函数和存储过程