深度神经网络 轻量化_正则化对深度神经网络的影响
深度神经网络 轻量化
介绍 (Introduction)
In this era of the information superhighway, the world around us is changing for good and it would not be an overstatement to say that Deep Learning is the next transformation. Deep Learning is a set of powerful mathematical tools that enable us, to represent, interpret, and control the complex world around us.
在这个信息高速公路的时代,我们周围的世界正在发生永远的变化,说深度学习是下一个变革,这并不夸张。 深度学习是一组强大的数学工具,使我们能够表示,解释和控制我们周围的复杂世界。
The programming paradigm is changing: Instead of programming a computer, we teach it to learn something and it does what we want.
编程范式正在发生变化:我们不是在对计算机编程,而是在教计算机学一些东西,并按照自己的意愿去做。
This particular notion is extremely captivating and has driven machine learning practitioners to develop models to take these concepts and ideas further along and apply them in real-world scenarios.
这个特殊的概念极具吸引力,并促使机器学习从业人员开发模型,以进一步推进这些概念和思想并将其应用于现实世界中。
However, the fundamental problem in building sophisticated machine learning models is how to make the architecture to do good not just on the training data but also on the testing data, i.e., on previously unseen features. In order to overcome this central problem, we must modify the model by applying certain strategies to reduce the test error, possibly at the expense of increased training error. These strategies are collectively known as regularization techniques. Nevertheless, regularization is useful only when the model is suffering from a high variance problem where the network overfits to the training data but fails to generalize new features (validation or test data).
但是,构建复杂的机器学习模型的根本问题是如何使体系结构不仅在训练数据上而且在测试数据(即以前看不见的功能)上都表现出色。 为了克服这个中心问题,我们必须通过应用某些策略来减少测试误差来修改模型,可能以增加训练误差为代价。 这些策略统称为正则化技术。 尽管如此,仅当模型存在高方差问题(网络过度适合训练数据但无法归纳新功能(验证或测试数据))时,正则化才有用。
L2规范或重量衰减 (L2 Norm or Weight Decay)
One of the most extensively used regularization strategies is the utilization of the L2 norm. This can be implemented by adding a regularization term to the cost function of the network.
最广泛使用的正则化策略之一是L2范数的利用。 这可以通过在网络的成本函数中添加正则项来实现。

The first part of the equation corresponds to the computation of net network loss. The terms w & b represents the weights and biases that the model has learned. The second part corresponds to the regularization term where the norm of the weight vector (w) is calculated. This regularization term is explicitly referred to as the famous L2 norm or Weight Decay. The net result of this is that the weight matrices of the network are penalized according to the value of the regularization parameter lambda (λ). So, the regularization parameter λ can be thought of as another hyper-parameter that is required to fine-tune.
等式的第一部分对应于净网络损耗的计算。 w & b项表示模型已了解的权重和偏差。 第二部分对应于正则化项,其中计算了权重向量( w )的范数。 该正则化术语明确地称为著名的L2范数或权重衰减。 这样做的最终结果是根据正则化参数lambda(λ)的值对网络的权重矩阵进行惩罚。 因此,可以将正则化参数λ视为微调所需的另一个超参数。
了解工作 (Understanding the working)
The intuition behind the regularizing impact of the L2 norm can be understood by taking an extreme case. Let’s set the value of the regularization parameter λ to be on the higher end. This would heavily penalize the weight matrices (w) of the network and they will be assigned with the values that are near to zero. The immediate impact of this is that the net activations of the neural network are reduced and the forward pass effect is diminished. Now, with a much simplified neural network architecture, the model would not be able to overfit to the training data and will be able to generalize much better on novel data and features.
L2规范的正则化影响背后的直觉可以通过极端的例子来理解。 让我们将正则化参数λ的值设置为更高端。 这将严重惩罚网络的权重矩阵( w ),并且将为它们分配接近零的值。 这样的直接影响是减少了神经网络的净激活,并减小了前向通过效应。 现在,通过大大简化的神经网络体系结构,该模型将无法过拟合训练数据,并且能够更好地推广新颖的数据和特征。

This intuition was based on the fact that the value of the regularization parameter λ was set to be very high. If however, an intermediate value of this parameter is chosen, it would increase the model performance on the testing set.
该直觉是基于将正则化参数λ的值设置为非常高的事实。 但是,如果选择此参数的中间值,则会提高测试集上的模型性能。
何时对模型进行规范化? (When to regularize your model?)
Figuring out the intuition behind the concept of regularization is all well and good, however, one more important aspect is to know whether your network really needs regularization or not. Here, plotting learning curves play an essential role.
弄清楚正则化概念背后的直觉是好事,但是,更重要的方面是要知道您的网络是否真的需要正则化。 在这里,绘制学习曲线起着至关重要的作用。
Graphing out the model's training and validation loss over the number of epochs is the most widely used method to determine whether a model has overfitted or not. The concept behind this methodology is based upon the fact that, if the model has overfitted to the training data, then the training loss and validation loss will differ by a lot, moreover the validation loss will always be higher than the training loss. The reason for this is that, if the model cannot generalize well on previously unseen data, then the corresponding loss or cost value will be inevitably high.
在历时数上绘制模型的训练和验证损失是确定模型是否过度拟合的最广泛使用的方法。 该方法背后的概念基于以下事实: 如果模型过度拟合训练数据,则训练损失和验证损失将相差很多,此外,验证损失将始终高于训练损失。 原因是,如果模型不能很好地概括以前看不见的数据,那么相应的损失或成本值将不可避免地很高。

As evident from the graph above, there exists a huge gap between training loss and validation loss which shows that the model has clearly overfitted to the training samples.
从上图可以明显看出,训练损失和验证损失之间存在巨大的差距,这表明该模型明显适合训练样本。
使用TensorFlow 2.0实施L2规范 (Implementing L2 norm using TensorFlow 2.0)
The practical implementation of the L2 norm can be demonstrated easily. For this purpose, let’s take the Diabetes Dataset from sklearn and plot the learning curves of first an unregularized model and then of a regularized model.
可以很容易地证明L2规范的实际实施。 为此,让我们从sklearn中获取“ 糖尿病数据集” ,并绘制先是非正规化模型然后是正规化模型的学习曲线。
The dataset has 442 instances and takes in ten baseline variables: age, sex, BMI, average BP, and six blood serum measurements (S1 to S6) as its training features (called x) and the measure of disease progression after one year as its labels (called y).
该数据集有442个实例,并包含十个基线变量: 年龄,性别,BMI,平均BP和六个血清测量值(S1至S6)作为训练特征(称为x),以及一年后疾病进展的测量值作为其训练特征。标签(称为y)。
非正规模型 (Unregularized Model)
Let’s import the dataset using TensorFlow and sklearn.
让我们使用TensorFlow和sklearn导入数据集。
We now split the data into training and testing sets. The testing set will have 10% of the training data reserved. This can be done using the train_test_split() function available in sklearn.
现在,我们将数据分为训练和测试集。 测试集将保留10%的训练数据。 可以使用sklearn中的train_test_split()函数来完成。
We now create an unregularized model using only Dense layers from the Sequential API from Keras. This unregularized model will have 6 hidden layers each with a ReLU activation function.
现在,我们仅使用Keras的Sequential API中的Dense层来创建非正规模型。 该非正规模型将具有6个具有ReLU激活功能的隐藏层。
After designing the model architecture we now compile the model with the Adam optimizer and mean squared error loss function. Training occurs for 100 epochs and the metrics are stored in a variable that can be used for plotting the learning curves.
设计完模型架构后,我们现在使用Adam编译模型 优化器和均方误差 损失函数。 训练进行100个纪元 ,并且度量标准存储在一个变量中,该变量可用于绘制学习曲线。
We now plot the loss of the model as observed for both the training data and the validation data:
现在,我们针对训练数据和验证数据绘制了模型的损失图:

The outcome here turns to be that, the validation loss continuously spikes up after approximately 10 epochs whereas the training loss keeps decreasing. This converse trend generates a huge gap between the two losses which indicates that the model has overfitted to the training data.
结果是,验证损失在大约10个纪元后持续上升,而训练损失却不断减少。 这种相反的趋势在两个损失之间产生了巨大的差距,这表明该模型已过度拟合训练数据。
使用L2范数对模型进行正则化 (Regularizing the model with L2 norm)
We have concluded from the previous learning curve that an unregularized model suffers from overfitting, and to fix this issue we introduce the L2 norm.
我们从先前的学习曲线得出的结论是,非正规模型存在过度拟合的问题,为了解决这个问题,我们引入了L2范数。
Dense layers as well as convolutional layers have an optional kernel_regularizer keyword argument. To add in Weight Decay or L2 regularization, we set the kernel regularizer argument equal to tf.keras.regularizers.l2(parameter). This parameter object is created with one required argument, which is the coefficient that multiplies the sum of squared weights or the regularization parameter λ.
密集层和卷积层都有一个可选的kernel_regularizer关键字参数。 要添加权重衰减或L2正则化,我们将内核正则化器参数设置为等于tf.keras.regularizers.l2(parameter) 。 该参数对象是使用一个必需的参数创建的,该参数是将权重平方和或正则化参数λ相乘的系数。
We now create a similar network architecture, but this time, we include the kernel_regularizer argument.
现在,我们创建了一个类似的网络体系结构,但是这次,我们包含了kernel_regularizer参数。
We compile and train the model with the same optimizer, loss function, metrics, and the number of epochs as it makes the comparison between the two models easier.
我们使用相同的优化程序,损失函数,指标和历时数来编译和训练模型,因为这使两个模型之间的比较更加容易。
After training, the following learning curve was observed when the training and validation loss was plotted against the number of epochs:
训练后,将训练和验证损失与历时数作图时,观察到以下学习曲线:
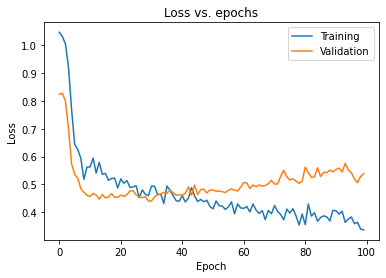
The regularized model’s learning curve is much smoother and the training, as well as the validation losses, are much closer to each other, which represents less variance in the network. Both, the training loss and the validation loss are now comparable to each other which shows the increased confidence of the model to generalize new features.
正则化模型的学习曲线更加平滑,并且训练以及验证损失彼此之间更加接近,这表示网络中的方差较小。 训练损失和验证损失现在都可以相互比较,这表明模型推广新功能的置信度更高。
结论 (Conclusion)
In this edifying journey, we did an extensive analysis by comparing the performance of two models, one of which suffered from overfitting and the other to solve the former model’s drawbacks. The problem of Bias and Variance in Machine Learning cannot be disregarded, and strategies must be applied to overcome these non-trivial complications. We covered one such strategy today to avoid variance in our model.
在这个充满启发的旅程中,我们通过比较两个模型的性能进行了广泛的分析,其中一个模型过度拟合,而另一个模型则解决了前一个模型的缺点。 偏差和方差问题 在机器学习中不可忽视,必须应用策略来克服这些非同寻常的复杂性。 今天,我们讨论了一种这样的策略,以避免模型中的差异。
However, the journey doesn't stop here, and therefore, we have to look beyond the horizon and must keep our noses to the wind.
但是,旅程并不会就此停止,因此,我们必须超越视野,必须保持警惕。
Here is the link to the author’s GitHub repository which can be referred for the unabridged code.
这是指向作者的GitHub存储库的链接,该链接可用于未删节的代码。
翻译自: https://towardsdatascience.com/impact-of-regularization-on-deep-neural-networks-1306c839d923
深度神经网络 轻量化
http://www.taodudu.cc/news/show-1874101.html
相关文章:
- dbscan js 实现_DBSCAN在PySpark上的实现
- 深度学习行人检测简介_深度学习简介
- ai初创企业商业化落地_初创企业需要问的三个关于人工智能的问题
- scikit keras_使用Scikit-Learn,Scikit-Opt和Keras进行超参数优化
- 异常检测时间序列_DeepAnT —时间序列的无监督异常检测
- 机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言
- mc2180 刷机方法_MC控制和时差方法
- 城市ai大脑_激发AI研究的大脑五个功能
- 神经网络算法优化_训练神经网络的各种优化算法
- 算法偏见是什么_人工智能中的偏见有什么作用?
- 查看-增强会话_会话助手平台-Hinglish Voice等!
- 可解释ai_人工智能解释
- 机器学习做自动聊天机器人_聊天机器人业务领袖指南
- 神经网络 代码python_详细使用Python代码和数学构建神经网络— II
- tensorflow架构_TensorFlow半监督对象检测架构
- 最牛ai波士顿动力上台阶_波士顿动力的位置如何使美国成为人工智能的关键参与者...
- 阿里ai人工智能平台_AI标签众包平台
- 标记偏见_人工智能的偏见
- lstm预测单词_从零开始理解单词嵌入| LSTM模型|
- 动态瑜伽 静态瑜伽 初学者_使用计算机视觉对瑜伽姿势进行评分
- 全自动驾驶论文_自动驾驶汽车:我们距离全自动驾驶有多近?
- ocr图像识别引擎_CycleGAN作为OCR图像的去噪引擎
- iphone 相机拍摄比例_在iPhone上拍摄:Apple如何解决Deepfakes和其他媒体操纵问题
- 机器学习梯度下降举例_举例说明:机器学习
- wp-autoblog_AutoBlog简介
- 人脸识别 特征值脸_你的脸值多少钱?
- 机器学习算法的差异_我们的机器学习算法可放大偏差并永久保留社会差异
- ai人工智能_AI破坏已经开始
- 无监督学习 k-means_无监督学习-第5部分
- 负熵主义者_未来主义者
深度神经网络 轻量化_正则化对深度神经网络的影响相关推荐
- 基于深度学习的病理_组织病理学的深度学习(第二部分)
基于深度学习的病理 计算机视觉/深度学习/医学影像 (COMPUTER VISION/ DEEP LEARNING/ MEDICAL IMAGING) In the last part, we sta ...
- cad模型轻量化_【技术帖】基于轻量化概念的碳纤维复合材料汽车保险杠设计
摘要:汽车工业的飞速发展使交通事故的发生量明显增多,轻量化高性能的汽车保险杠可在交通事故的撞击中减少车身的受损,并保障乘员的安全.简要介绍了使用碳纤维复合材料作为原材料的轻量化汽车保险杠的设计过程. ...
- cad模型轻量化_保持外观的CAD模型轻量化技术
保持外观的 CAD 模型轻量化技术 殷明强 * ,李世其 [摘 要] 摘要 : 随着 CAD/CAM 技术的发展,整个产品的设计.虚拟制造和数 字化样机都可在计算机中完成,使得包含大量数据的复杂装配体 ...
- cad模型轻量化_什么是真正的 3D CAD 模型(2)
为了方便您为您的客户和潜在客户提供最佳的服务,在对工程师.技术及采购人员的调查访问之后,结果显示:工程人员真正需要CAD模型的信息有诸如重量.重心.颜色.运动信息.选型助手等22种. 1. 重量和重心 ...
- bim webgl 模型 轻量化_数字化交付模型轻量化技术研究
研究背景 随着BIM应用的越来越深入,无论是在民建领域还是在基建领域,BIM模型越来越精细.越来越大已经成为一种现实与趋势,而建筑业全面推行数字化交付,模型轻量化技术与数据存储技术必将成为其中的关键. ...
- cad模型轻量化_碳纤维泡沫三明治夹层复合材料汽车扰流板的轻量化设计
前言 目前,汽车制造中用到的复合材料多为纤维增强或机织物及非织造布增强的树脂基复合材料.车辆在行驶过程中会遭受外部振动,从而导致内部零件受损,因此,运输车辆一般需要具有较好的减震性.目前,在运输类车辆 ...
- cad模型轻量化_国内首款:新一代基于云架构的三维CAD产品CrownCAD正式公测!
4月15号,华天软件控股子公司华云三维科技有限公司研发的国内首款.完全自主可控的新一代基于云架构的三维CAD产品CrownCAD正式上线公测. 公测地址:http://www.crowncad.com ...
- python神经网络构建图_如何用卷积神经网络构建图像?
原标题:如何用卷积神经网络构建图像? 原标题 |Everything you need to know to master Convolutional Neural Networks 作者 | Tir ...
- 深度学习实现象棋_象棋的深度学习
深度学习实现象棋 Erik Bernhardsson | 2017年2月2日 (by Erik Bernhardsson | February 2, 2017) About Erik: Dad and ...
- 深度学习 免费课程_深入学习深度学习,提供15项免费在线课程
深度学习 免费课程 by David Venturi 大卫·文图里(David Venturi) 深入学习深度学习,提供15项免费在线课程 (Dive into Deep Learning with ...
最新文章
- 力扣(LeetCode)刷题,简单题(第9期)
- 12位黄金技术大佬发出警告:一大波必读好书向你袭来!
- 皮一皮:论一件艺术品的诞生...
- Azkaban启动与激活命令
- 【转载】TCP和TCP/IP的区别
- 2019纪中暑假游记+总结
- 【ArcGis for javascript从零开始】之一 ArcGis加载天地图
- Markdown数学符号
- 【数据分享】全国POI数据分享(持续更新中)
- wincc7.4sp1硬件狗破解不成功
- js 实现井字棋游戏
- aamp;m大学计算机科学,斑马博士捷报|德克萨斯AM大学 (TAMU) MSc Computer Science录取!...
- linux扩展模式触摸屏,Ubuntu14.04下使用触摸屏以及笔记本扩展触摸屏设置方法
- get 传值 是params
- 一键php win10,一键批处理制作纯64位网络骨头版WIN10pe
- 详解 Jenkins 自动化部署平台
- blender 保留贴图转换 mmd 模型到 ue4/ue5 引擎
- AML与PIO整合问题
- 2022年全球市场男士防脱发和增长产品总体规模、主要生产商、主要地区、产品和应用细分研究报告
- 如何查看、复制caj、PDF文件文本内容