爬虫python 英文,python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍
爬取英文名:
一. 爬虫模块详细设计
(1)整体思路
对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个csv文件中;再读取csv文件当中的每个英文名链接,采用循环的方法读取每一个英文名链接,根据每个英文名链接爬取每个链接中的数据,保存在新的csv文件当中。
需要写一个爬取英文名链接的函数、将爬取的内容保存在csv文件的函数以及读取csv文件内容的函数、爬取英文名详情页内容的函数。
表5.3.1
函数名
作用
def get_nameLink():
爬取英文名链接
def save_to_csv(dict,filename):
将爬取的内容以字典的形式保存在csv文件
def get_WebLinkcsv(name):
读取csv文件的内容
def get_namedata():
根据链接爬取每个英文名的具体数据
(2)爬取英文名链接
首先观察A-Z英文名的网页的内容,发现每个字母都对应一个网站,刚打开网站只会显示三个模块的英文名,每个模块30个英文名;关于一个字母的更多的英文名是根据鼠标的移动再进行动态的加载才会在网页上显示出来;但每个字母的英文名不同的网页上显示。如图:
图5.3.2(1)
经观察,每个字母的所有英文名都可以根据页数来确定,可以不用动态爬取的方法,根据观察每个字母的英文名页数来确定每个字母英文名的数量进行爬取链接。链接格式为:
https://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajax=true
Letter表示A-Z的字母,number表示页数,page_size表示每个页面所显示的英文名数量为30个。
代码如下:
图5.3.2(2)
(3) 爬取详情页
打开某个英文名对应的详情页,右键点开查看需要爬取内容的审查元素,观察每个模块内容所对应的标签进行解析。经观察,有的英文名存在Celebrity模块,有的英文名不存在Celebrity模块,就需要进行判断,若存在就解析保存在csv文件中,不存在显示为空跳过,继续解析下一个内容。如图:
Abigail名字中就有Celebrity模块的内容,Annabelle名字中就没有这个Celebrity中的内容,这种情况下,就会存入空的内容。
图5.3.3(1)
代码如下:
采用try except进行异常处理。
图5.3.3(2)
(4)存储内容
采用字典的形式存入内容保存在csv文件当中。字典(dictionary)是Python中另一个非常有用的内置数据类型,列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取;字典是一种映射类型,字典用“{ }”标识,它是一个无序的键(key)、值(value)对集合,键(key)必须使用不可变类型。
def save_to_csv(dict,filename)函数表示存储数据,使用字典形式存储,因为本次实验数据较大,不能一次性爬取,所以在爬取内容的时候都是分开爬的,对于数据的存储也是采用追加的方式进行存取的。
如图:
图5.3.4
(5)读取文件
读取文件主要是用来读取名字链接,根据名字链接进行详情页的爬取
图5.3.5
二. 调试与测试
(1) 调试过程中遇到的问题
(1)在爬取关于A的英文名链接的时候,只出现了90个链接,剩下的爬不出来,但在网页中剩下的英文名可以根据鼠标的滑动进行加载出现在网页中,经观察可以根据此链接https://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajax=true,进行获取每个英文名的爬取以及对每个字母的英文名数量进行确认;用此url形式就相当于是进行翻页操作,每一页只有30个英文名。
(2)在运行的过程中会显示缩紧错误,但在观察过程中,并没有缩进的错误,在网上查询得只是因为在定义一个函数时,函数里面没有内容才会报此错误。
(3)在进行几次爬取过程中,会经常在某一个固定的地方停止爬取,经多次修改,最终发现是请求头的问题。
(2)爬取显示
爬取的内容会保存在csv文件当中,如图:
图5.2
三 课程设计心得与体会
(1) 通过这次课程设计,使我更加扎实的掌握了有关Python方面的知识,在设计过程中,虽然遇到了一些问题,但经过一次又一次的思考,一遍又一遍的检查终于找出了原因所在,也暴露出了前期我在这方面的知识欠缺以及经验不足。实践出真知,通过亲自动手设计,使我们找你哥我的知识不再是纸上谈兵。
(2) 过而能改,善莫大焉。在课程设计过程中,我们不断发现错误,不断改正,不断领悟,不断获取。最终的检测调试环节,本身就是在实践“过而能改,善莫大焉”的知行观。这次的课程设计终于顺利完成了,在设计中遇到了很多问题,最后在同学们的帮助下迎刃而解,这也告诉我们,在今后的社会发展和学习实践过程中,一定要不懈努力,不能遇到问题就想到要退缩,一定要不厌其烦的发现问题所在,然后一一解决,只有这样才能成功的做成想做的事,才能在今后的道路上披荆斩棘,而不是知难而退,那样永远不可能收获成功,收获喜悦,也永远不可能得到社会及他人的认可。
(3) 课程设计诚然是一门专业课,给我很多专业知识以及专业技能上的提升,同时又是一门思辨课,给了我许多道,很多思。是我对抽象理论有了具体的认识。通过这次课程设计,我对正则表达式有了更深一步的理解运用,通过查询资料也了解了Python的爬虫原理。我认为,在这学期的实验中,不仅培养了独立思考、动手操作能力,在各种其他能力上也都有了提高。更重要的是,在课程设计学习中,我学会了很多学习方法,而这是日后最实用的,真的是受益匪浅。要面对社会的挑战,只有不断的学习、实践。在学习、在实践。这对于我们的将来也有很大的帮助。
一:什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
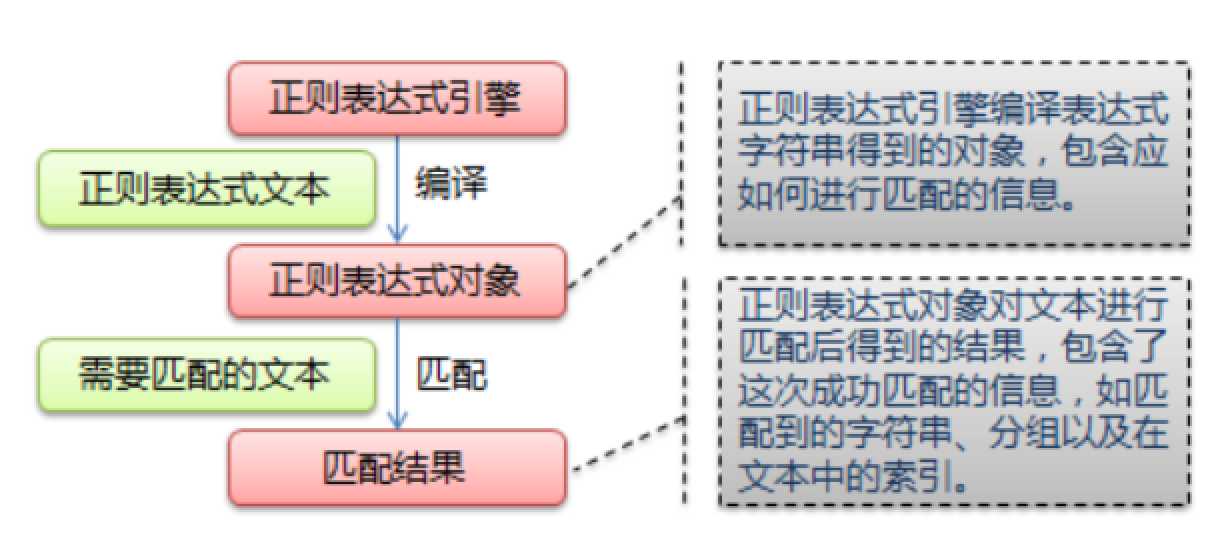
二:爬虫的四个主要步骤
明确目标 (要知道你准备在哪个范围或者网站去搜索)
爬 (将所有的网站的内容全部爬下来)
取 (过滤和匹配我们需要的数据,去掉没用的数据)
处理数据(按照我们想要的方式存储和使用)
三:正则表达式匹配规则
元字符说明
.
代表任意字符
\
[ ]
匹配内部的任一字符或子表达式
[^]
对字符集和取非
-
定义一个区间
\
对下一字符取非(通常是普通变特殊,特殊变普通)
*
匹配前面的字符或者子表达式0次或多次
*?
惰性匹配上一个
+
匹配前一个字符或子表达式一次或多次
+?
惰性匹配上一个
?
匹配前一个字符或子表达式0次或1次重复
{n}
匹配前一个字符或子表达式
{m,n}
匹配前一个字符或子表达式至少m次至多n次
{n,}
匹配前一个字符或者子表达式至少n次
{n,}?
前一个的惰性匹配
^
匹配字符串的开头
\A
匹配字符串开头
$
匹配字符串结束
[\b]
退格字符
\c
匹配一个控制字符
\d
匹配任意数字
\D
匹配数字以外的字符
\t
匹配制表符
\w
匹配任意数字字母下划线
\W
不匹配数字字母下划线
四.正则表达式例子
原文:https://www.cnblogs.com/cyt99/p/12079029.html
爬虫python 英文,python爬虫—爬取英文名以及正则表达式的介绍相关推荐
- Python 淘宝商品价格爬取(requests库+正则表达式)
淘宝搜索关键词链接:https://s.taobao.com/search?q=关键词 第2页商品链接:https://s.taobao.com/search?q=关键词&s=44 第3页商品 ...
- python爬虫提取人名_python爬虫—爬取英文名以及正则表达式的介绍
python爬虫-爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个csv ...
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起. 很多人学习python,掌握了基本语法过后,不知道在哪里 ...
- Python爬虫基础:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 运行平台:Windows Python版本:Python3.6 IDE: Sublime Text ...
- 实践▍Python爬虫基础:验证码的爬取和识别详解
每天学一点Python 作者:HDMI,信息管理与信息系统 博客地址:zhihu.com/people/hdmi-blog 今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也 ...
- 从入门到入土:Python爬虫学习|实例练手|爬取猫眼榜单|Xpath定位标签爬取|代码
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出.欢迎各位前来交流.(部分材料来源网络,若有侵权,立即删除) 本人博客所有文章纯属学习之用,不涉及商业利益.不合适引用,自当删除! 若 ...
- 从入门到入土:Python爬虫学习|实例练手|爬取百度翻译|Selenium出击|绕过反爬机制|
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出.欢迎各位前来交流.(部分材料来源网络,若有侵权,立即删除) 本人博客所有文章纯属学习之用,不涉及商业利益.不合适引用,自当删除! 若 ...
- 从入门到入土:Python爬虫学习|实例练手|爬取新浪新闻搜索指定内容|Xpath定位标签爬取|代码注释详解
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出.欢迎各位前来交流.(部分材料来源网络,若有侵权,立即删除) 本人博客所有文章纯属学习之用,不涉及商业利益.不合适引用,自当删除! 若 ...
- 从入门到入土:Python爬虫学习|实例练手|爬取百度产品列表|Xpath定位标签爬取|代码注释详解
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出.欢迎各位前来交流.(部分材料来源网络,若有侵权,立即删除) 本人博客所有文章纯属学习之用,不涉及商业利益.不合适引用,自当删除! 若 ...
- python 写csv scrapy_scrapy爬虫框架实例一,爬取自己博客
本篇就是利用scrapy框架来抓取本人的博客,博客地址:http://www.cnblogs.com/shaosks scrapy框架是个比较简单易用基于python的爬虫框架,相关文档:http:/ ...
最新文章
- 我自己写的3D图形数学库。。。有点乱!
- python开发安卓程序-如何使用python开发Android手机应用?
- Android 最火的高速开发框架xUtils
- 驱动设计的思想:面向对象/分层/分离
- x11 gtk qt gnome kde 之间的区别和联系
- 这些面试中的智力题,你都会了吗
- java多态的简单例子_要JAVA的简单例子,继承\多态的,详细讲解运行的每一步
- vue中warning_vue项目运行提示Warnings while compiling.警告的解决方法
- linux wegt克隆网站,linux利用wget命令备份网站(镜像拷贝)
- ABP:在多语句事务内不允许使用 CREATE DATABASE 语句
- 显示最新的Picasaweb上传
- 怎样复制秀米html码,来,今天学习秀米的“复制粘贴”快捷键~
- mysql busy buffer_与buffer cache相关的等待事件—buffer busy waits等待事件!
- php后端开发要学会哪些,PHP程序员需要学什么_后端开发
- 京东“百亿补贴”提前20小时上线,电商价格战开打; iPhone 15 Pro玻璃面板泄露;凹语言 0.5.0发布|极客头条
- 主成分分析,充分图,聚类,主成分回归——数据分析与R语言 Lecture 11
- java基础之package和import语句
- mybatis XML 中大于等于小于等于的写法
- 互联网产品上线前,做些什么——产品、开发、测试的视角(转载)
- 西安计算机三本院校排名2015,2015年陕西三本院校排名