不平衡数据的数据处理方法
在机器学习中,不平衡数据是常见场景。不平衡数据一般指正样本数量远远小于负样本数量。如果数据不平衡,那么分类器总是预测比例较大的类别,就能使得准确率达到很高的水平。比如正样本的比例为 1%,负样本的比例为 99%。这时候分类器不需要经过训练,直接预测所有样本为负样本,准确率能够达到 99%。经过训练的分类器反而可能没有办法达到99%。
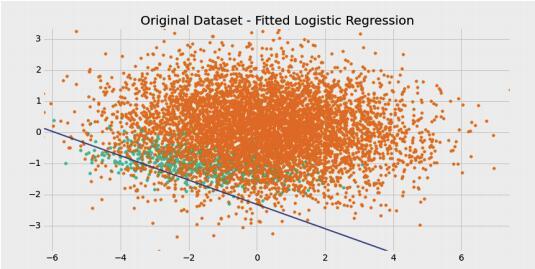
对于不平衡数据的分类,为了解决上述准确率失真的问题,我们要换用 F 值取代准确率作为评价指标。用不平衡数据训练,召回率很低导致 F 值也很低。这时候有两种不同的方法。第一种方法是修改训练算法,使之能够适应不平衡数据。著名的代价敏感学习就是这种方法。另一种方法是操作数据,人为改变正负样本的比率。本文主要介绍数据操作方法。
1. 欠抽样方法
欠抽样方法是针对多数的负样本,减少负样本的数量,反而提高整体 F 值。最简单的欠抽样方法是随机地删掉一些负样本。欠抽样的缺点很明显,就是会丢失负样本的一些重要信息,不能够充分利用已有的信息。
2. 过抽样方法
欠抽样方法是针对少数的正样本,减少正样本的数量,从而提高整体 F 值。最简单的过抽样方法是简单地复制一些正样本。过抽样的缺点是没有给正样本增加任何新的信息。过抽样方法对 SVM 算法是无效的。因为 SVM 算法是找支持向量,复制正样本并不能改变数据的支持向量。
改进的过抽样方法则采用加入随机高斯噪声或产生新的合成样本等方法。根据不同的数据类型,我们可以设计很巧妙的过抽样方法。有 博客 在识别交通信号问题上就提出了一个新颖的方法。交通信号处理识别是输入交通信号的图片,输出交通信号。我们可以通过变换交通信号图片的角度等方法,生成新的交通信号图片,如下所示。

3. SMOTE
Synthetic Minority Over-sampling Technique (SMOTE) 算法是一个最有名的过抽样的改进。SMOTE 是为了解决针对原始过抽样方法不能给正样本增加新信息的问题。算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。

4. 总结
从理论上来说,SMOTE 方法要优于过抽样方法,过抽样方法要优于欠抽样方法。但是很多工业界场景,我们反而采用欠抽样方法。工业界数据量大,即使正样本占比小,数据量也足够训练出一个模型。这时候我们采用欠抽样方法的主要目的是提高模型训练效率。总之一句话就是,有数据任性。。
本文作者:佚名
来源:51CTO
不平衡数据的数据处理方法相关推荐
- givemesomecredit数据_EasyEnsemble:一种简单的不平衡数据的建模方法(附测试代码)...
摘要 虽然我这里洋洋洒洒写了2000字,但实际原理我一句话就能讲完,那就是"通过重复组合正样本与随机抽样的同样数量的负样本,训练若干数量分类器进行集成学习".但为了让大家对这个算法 ...
- 商业智能中的决策, 数据和数据处理方法
声明 个人原创, 转载需注明来源 https://www.cnblogs.com/milton/p/16296974.html 数据和决策 商业智能(Business Intelligence)是一个 ...
- 【机器学习基础】如何在Python中处理不平衡数据
特征锦囊:如何在Python中处理不平衡数据 ???? Index 1.到底什么是不平衡数据 2.处理不平衡数据的理论方法 3.Python里有什么包可以处理不平衡样本 4.Python中具体如何处理 ...
- linux中python如何调用matlab的数据_特征锦囊:如何在Python中处理不平衡数据
今日锦囊 特征锦囊:如何在Python中处理不平衡数据 ? Index 1.到底什么是不平衡数据 2.处理不平衡数据的理论方法 3.Python里有什么包可以处理不平衡样本 4.Python中具体如何 ...
- 原生table html,html table 原生表格数据处理方法
数据接口返回的数据格式如下: { "errcode":"1", "list":[ { "stone_name":&quo ...
- ctd数据 matlab,基于auv的ctd数据处理方法
基于auv的ctd数据处理方法 [技术领域] [0001 ] 本发明涉及水下机器人技术领域,尤其涉及一种基于AUV (Autonomous underwater vehicle,无人无缆潜水器)获得的 ...
- 海量数据处理方法总结 常见大数据题目汇总
海量数据处理方法大总结 方式一:分而治之/hash映射(哈希映射) + hashmap统计 + 快速/归并/堆排序(万能方法) 这种方法是典型的"分而治之"的策略,是解决空间限制最 ...
- matlab中离开网格的流量,数学建模【数据处理方法(一维、二维插值方法;数据拟合方法;插值and拟合的MATLAB实现)】...
[学习网址:MOOC---郑州轻工业大学---数学建模与实验]数学建模专栏 笔记01[第1.2章][概述.软件介绍] 笔记02[第3章][数据处理方法] 笔记03[第4章][规划模型] 笔记04[第5 ...
- 在大数据时代,传统的数据处理方法还适用吗?
大数据环境下的数据处理需求 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来 ...
最新文章
- hdu1285 拓扑排序+优先队列
- 【译】Why Decentralized AI Matters Part III: Technologies
- matlab变量由非标量,matlab中的if语句
- [分享] Flask 网络开发经典书籍: Flask Web Development
- python在linux编程_python要在linux下编程吗
- (2)机械臂Simscape建模:模型导入MATLAB
- 云计算IaaS-Pssa-Saas(云计算的基本架构)
- 自定义DatetimePicker起始默认值
- 计算机前沿技术科论文,计算机前沿技术论文
- 计算机表格常用根式,平方根表
- mysql从删库到跑路 Ubuntu篇
- 主干(trunk)、分支(branch )、标记(tag) 用法示例 + 图解
- *转载 Tarjan有向图详解
- 象棋里的天地炮与重炮
- PHP 、Java、Python、C、C++ 特点或优点?
- Python入门练习 计算两个日期相隔的天数
- [原创]WCF技术剖析之二十: 服务在WCF体系中是如何被描述的?
- wps上下标怎么对齐_在EXCEL中,怎样将上、下标对齐?
- SAP 国家代码为CN的客户主数据邮政编码只能是六位数字的设置
- 边缘计算顶会SEC 2019论文速览(一)