迁移学习NLP:BERT、ELMo等直观图解
2018年是自然语言处理的转折点,能捕捉潜在意义和关系的方式表达单词和句子的概念性理解正在迅速发展。此外,NLP社区已经出现了非常强大的组件,你可以在自己的模型和管道中自由下载和使用(它被称为NLP的ImageNet时刻)。
在这个时刻中,最新里程碑是发布的BERT,它被描述NLP一个新时代的开始。BERT是一个模型,它打破了前几个模型处理基于语言的任务的记录。该模型的论文发布后不久,团队还开放了该模型的代码,并提供了已经在大量数据集上预先训练过的模型的下载版本。这是一个重大的发展,因为它使任何人都可以构建一个涉及语言处理的机器学习模型,他们成功的将这个强大的工具变成了一个易于使用的组件,从而节省了训练NLP模型所需的时间,精力和资源。
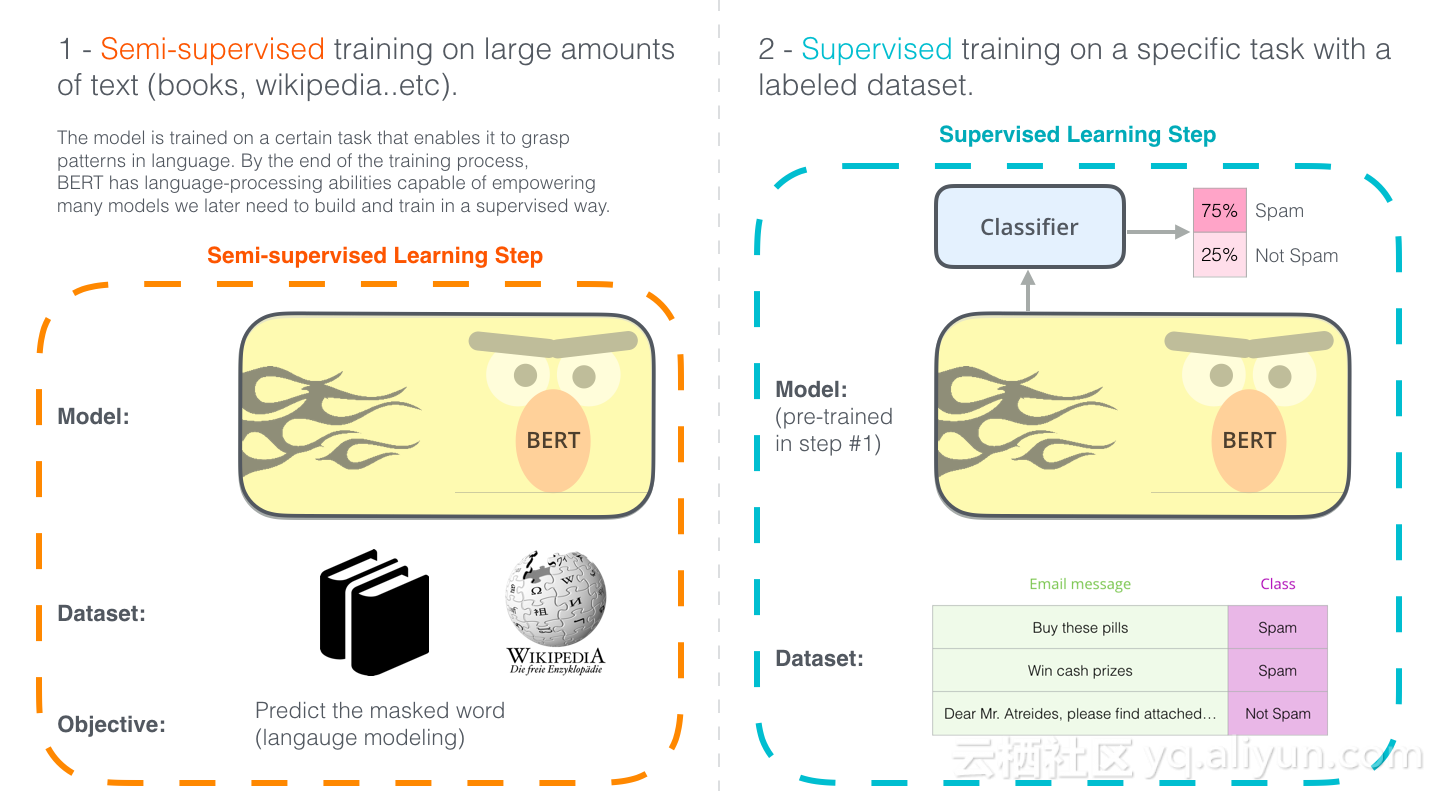
两种不同的BERT。你可以下载在1中预训练的模型(它是在未注释的数据上进行训练),在2中是针对特殊场景对其进行微调。
BERT是建立在最近NLP社区中涌现的一些聪明的想法之上,包括但不限于半监督序列学习(Andrew Dai和Quoc Le)、ELMo(由Matthew Peters和来自AI2的研究人员和UW CSE),ULMFiT(由fast.ai创始人Jeremy Howard和Sebastian Ruder提供)和OpenAI转换器(由OpenAI研究人员Radford,Narasimhan,Salimans和Sutskever提供)和Transformer(Vaswani等人)。
需要注意的一些概念才能完全了解BERT的内容。因此,让我们首先看一下在查看模型本身所涉及的概念之前可以使用BERT的场景。
示例:句子分类
BERT最擅长的是分类单个文本,这个模型看起来像这样:
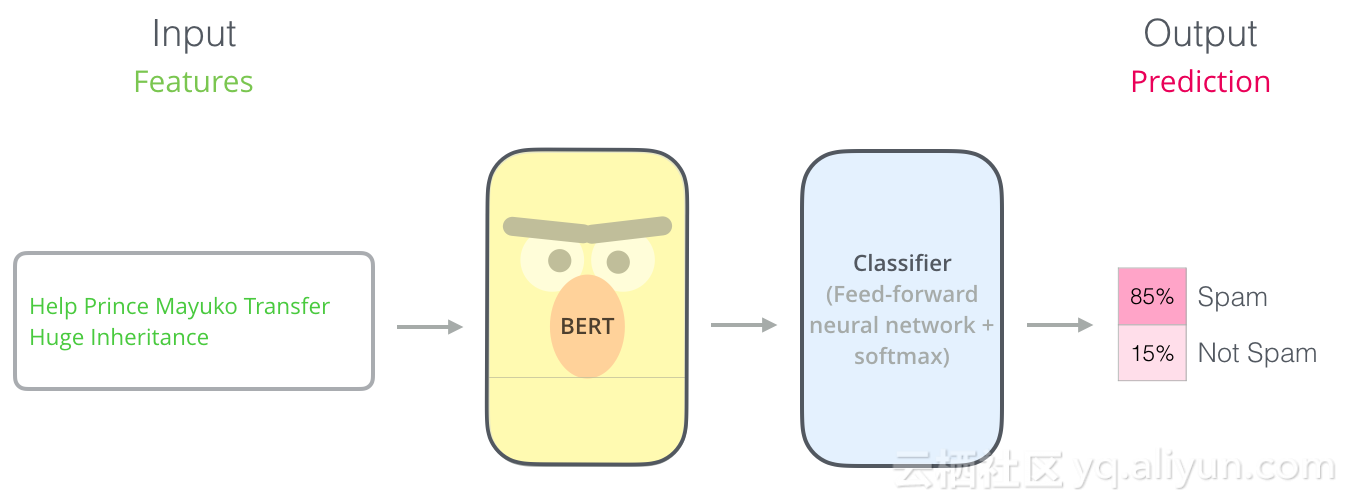
为了训练这样的模型,你必须训练分类器,在训练阶段BERT模型发生的变化很小。该过程称为微调,并且整个过程是源于半监督序列学习和ULMFiT。
既然我们在讨论分类器,那么我们就处于机器学习的监督学习领域。这意味着我们需要一个标记的数据集来训练这样的模型。以垃圾邮件分类器示例,标记的数据集将是电子邮件和标签的列表(“垃圾邮件”或“非垃圾邮件”)。

这种用例的其他示例包括:
1、情绪分析
输入:电影/产品评论。输出:评论是正面还是负面?
示例数据集:SST
2、事实查证
输入:句子。输出:“索赔”或“不索赔”
更夸张/前沿的例子:
输入:是否进行索赔。输出:“真”或“假”
Full Fact是一个为公众利益建立自动事实检查工具的组织。他们的部分管道其实是一个分类器,它可以读取新闻文章并检测声明(将文本分类为“声明”或“不声明”),以此进行事实验证。
模型架构
现在你已经了解了如何使用BERT的用例,接下来让我们仔细看看它是如何工作的。

首先介绍BERT的两种型号:
l BERT BASE:与OpenAI Transformer的尺寸相当,性价比很高;
l BERT LARGE:一个非常庞大的模型,它的性能最好;
BERT基本上是训练有素的转换器(Transformer)编码器堆栈。现在是你阅读The Illustrated Transformer的好时机,该文章解释了Transformer模型-BERT的基本概念以及我们接下来要讨论的概念。
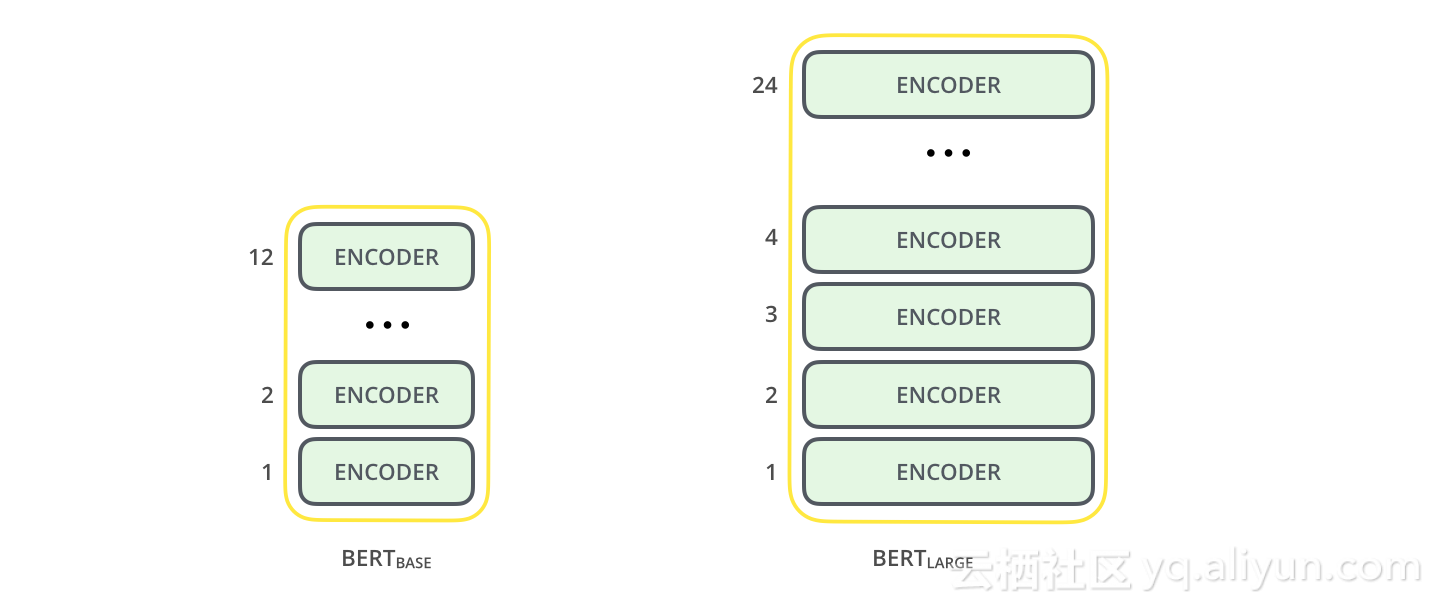
两种BERT模型都有大量的编码器层(本文称之为Transformer Blocks),其中Base版本为12个,Large版本为24个。它们还具有更大的前馈网络(分别为768和1024个隐藏单元)以及比初始论文中的转换器更多attention heads(分别为12和16)(初始论文的转换器中有6个编码器层,512个隐藏单元,和8个attention heads)。
模型输入
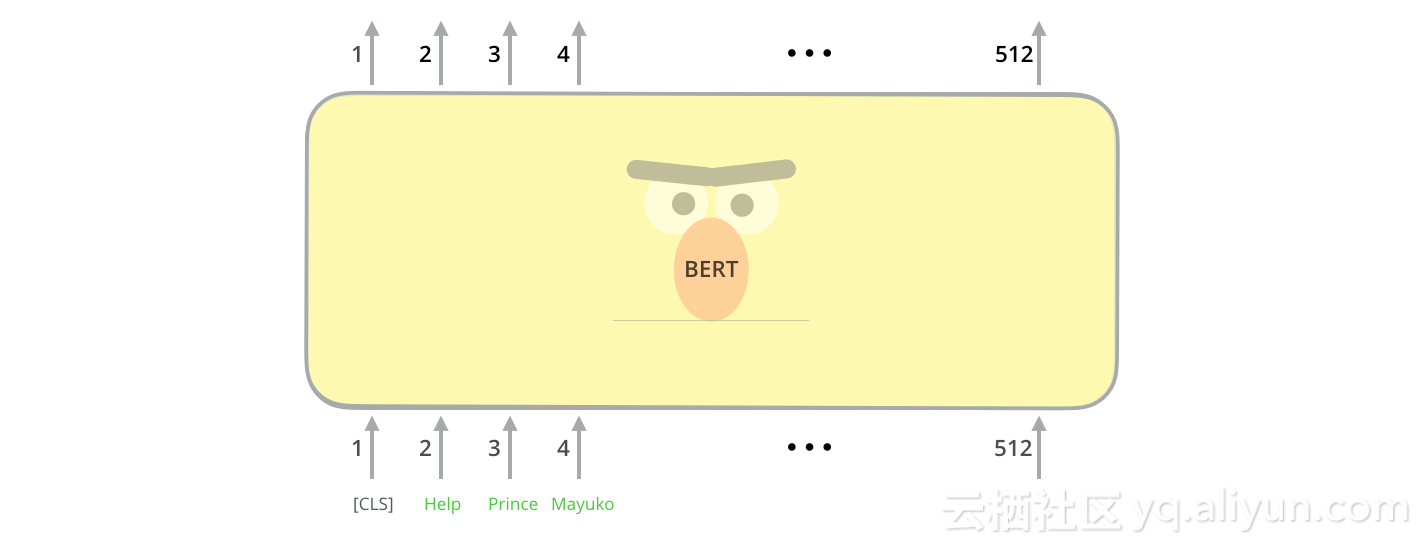
第一个接口输入提供了一个特殊的接口[CLS],原因将在后面变得明显,CLS在这里代表分类。
就像转换器的香草编码器一样,BERT采用一系列字作为输入。每一层都应用自我关注,并通过前馈网络传递其结果,然后将其交给下一个编码器。
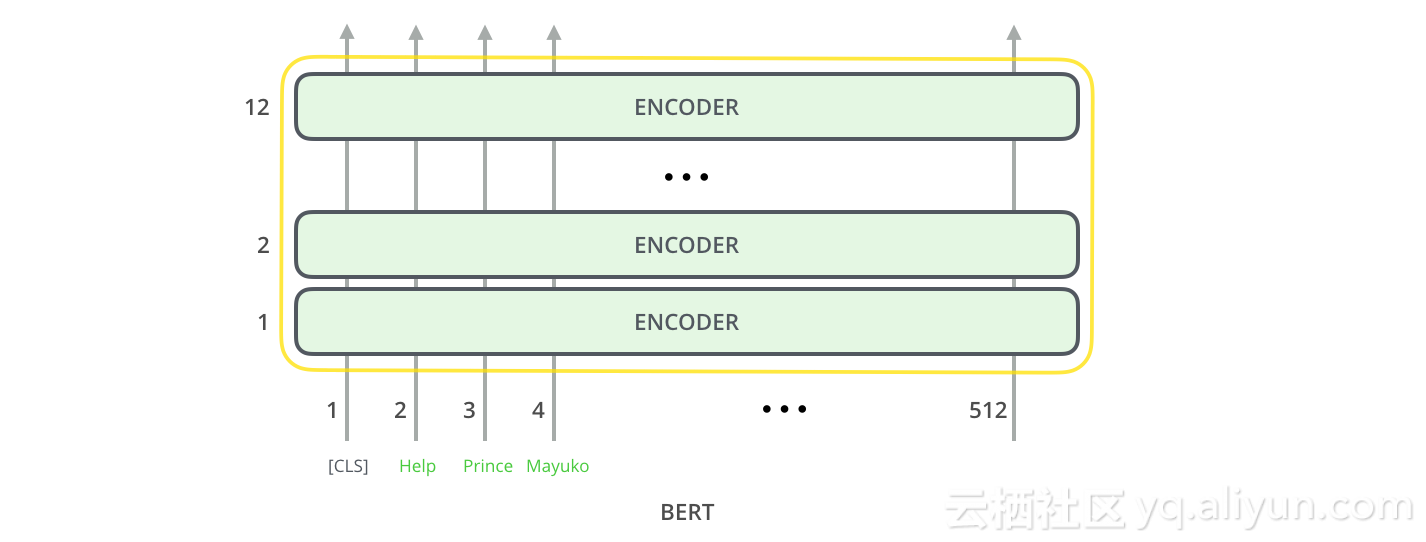
在架构方面,到目前为止,这与转换器完全相同。
模型输出
每个位置输出大小为hidden_size的矢量(BERT Base中的768)。对于我们上面看过的句子分类示例,我们只关注第一个位置的输出(我们将特殊的接口[CLS]标记传递到)。
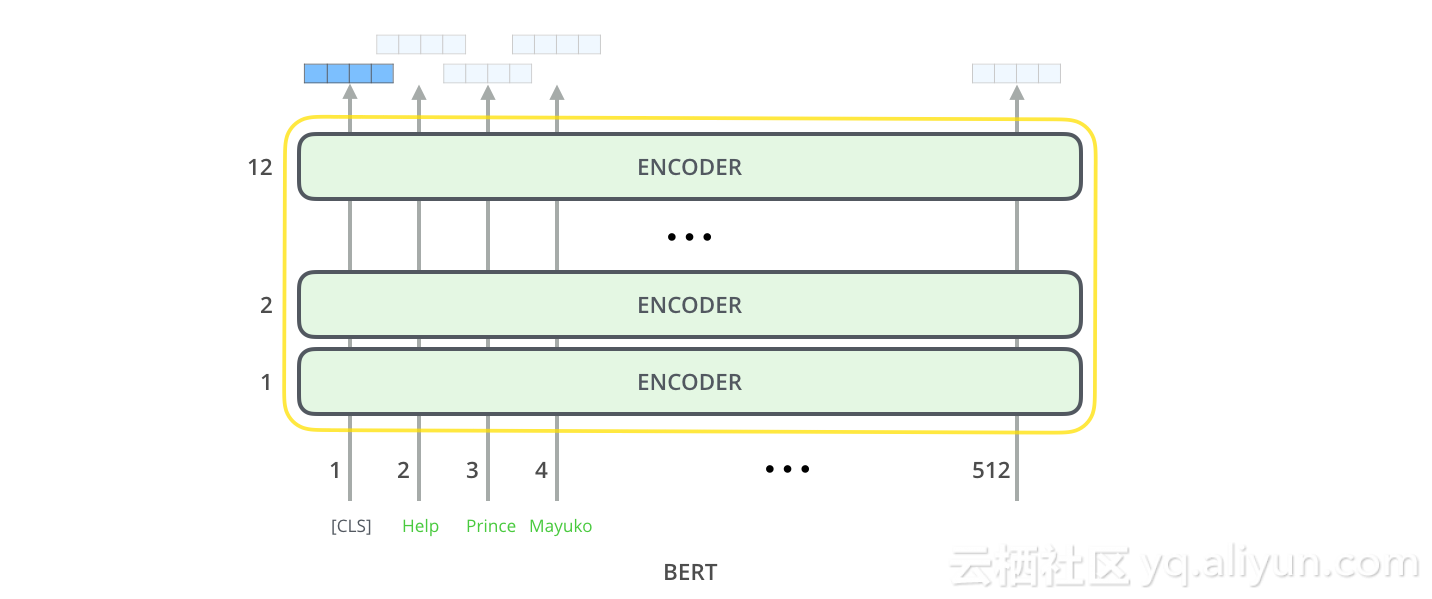
该向量现在可以用作我们选择的分类器的输入,通过使用单层神经网络作为分类器,这样效果就能达到我们想要的。
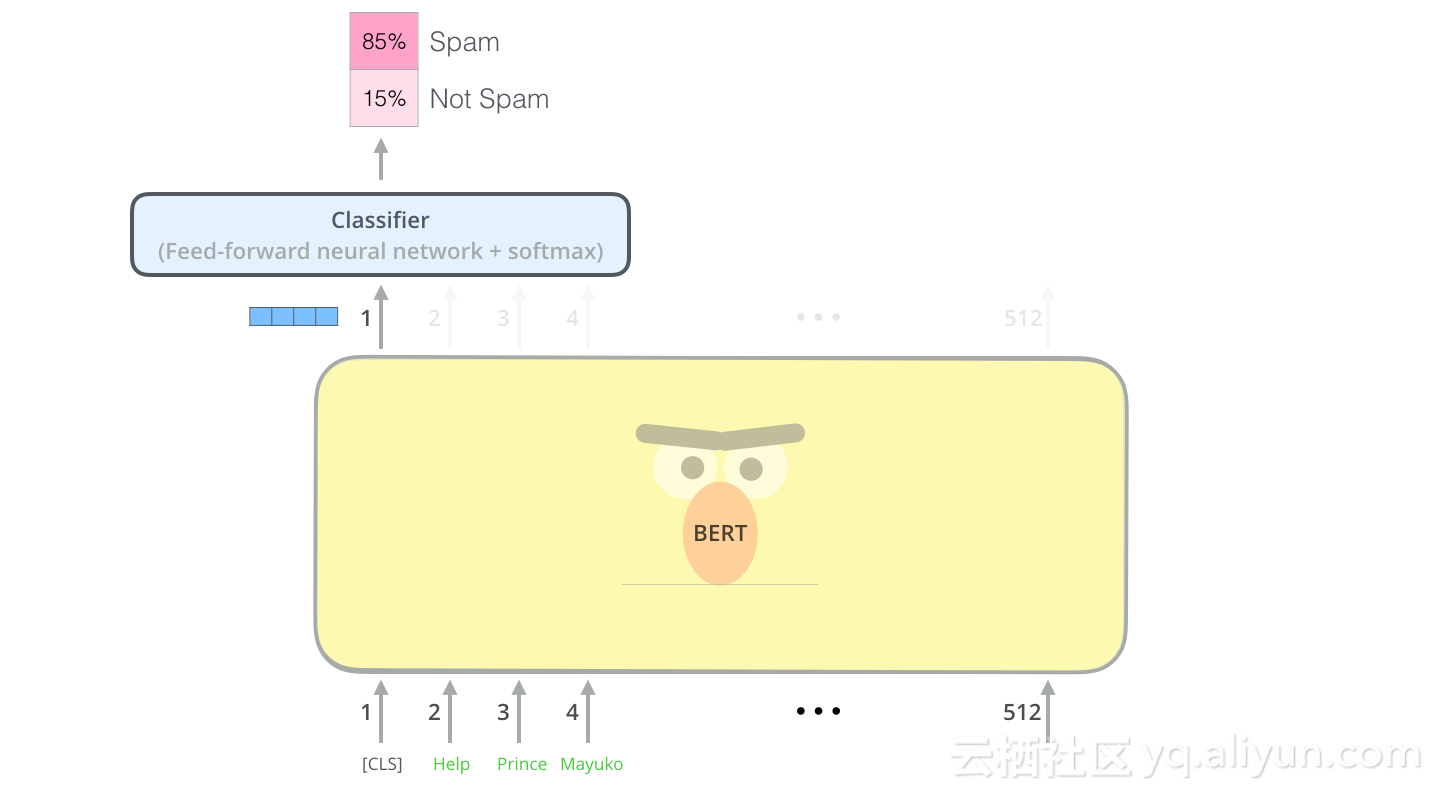
如果你有更多标签(例如,如果你是使用“垃圾邮件”,“非垃圾邮件”,“社交”和“促销”标记电子邮件),你只需调整分类器网络以获得更多输出神经元即可,然后通过softmax。
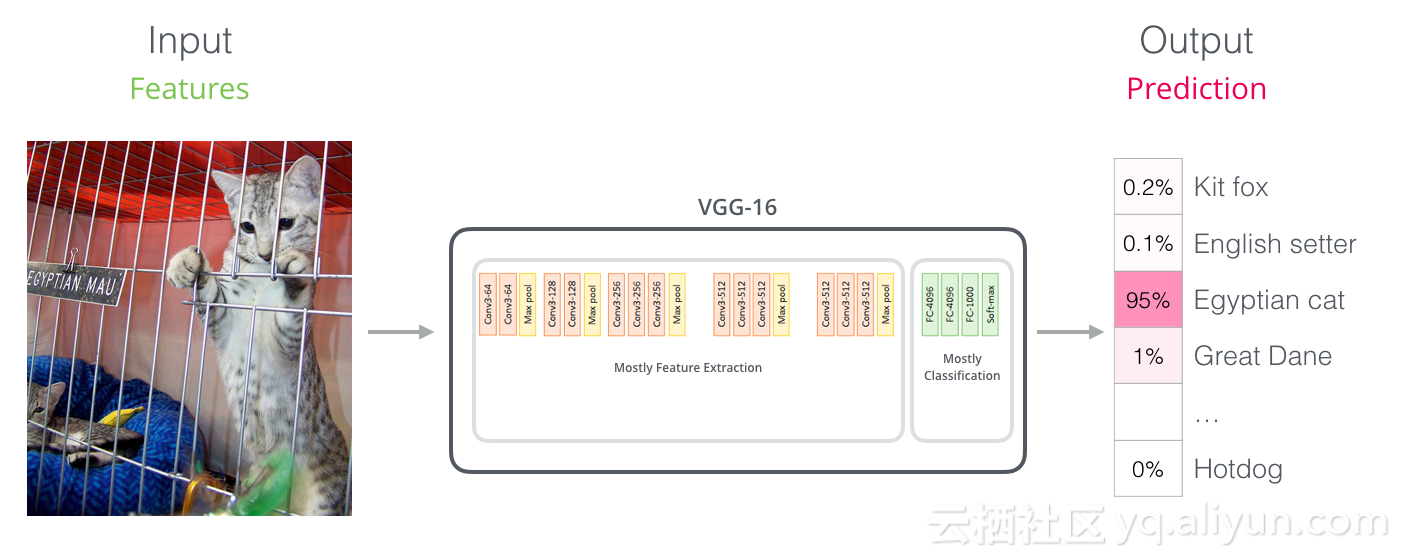
卷积网相似操作
对于那些具有计算机视觉背景的人来说,这个矢量切换应该让人联想到VGGNet等网络的卷积部分与网络末端的完全连接的分类部分之间发生的事情。
嵌入(Embedding)的新时代
到目前为止,词嵌入一直是影响NLP模型处理语言的主要力量。Word2Vec和Glove等方法已被广泛用于此类任务。让我们回顾一下之前是如何使用它们的。
Word嵌入是个啥?
对于要由机器学习模型处理的词,它们需要以某种形式的数字表示,这样模型才可以在计算中使用。Word2Vec让我们可以使用一个向量(一个数字列表)以一种捕获语义相关关系的方式正确表示单词(例如,判断单词是相似的,判断还是在它们之间具有的关系,如“开罗”和“埃及”之间的关系)以及句法或基于语法的关系(例如“was”和“is”之间的关系)。
该领域的研究者很快意识到,使用经过大量文本数据预训练的嵌入技术,而不将模型与经常是小型数据集的模型一起训练,这是一个好主意。因此,你可以下载Word2Vec或GloVe预训练生成的单词列表及其嵌入。
![]()
GloVe词嵌入中“stick”一词-是200个浮点数的向量。
ELMo:语境问题
如果我们使用GloVe,那么“stick”这个词将由一个向量表示,无论上下文是什么。但是,许多NLP研究人员(Peters等人,2017年,McCann等人,2017年及Peters等人,2018年在ELMo论文中)发现“stick”有多个含义,这取决于它的使用位置。为什么不根据它所使用的上下文给它一个嵌入呢?这样既捕获该上下文中的单词含义以及其他上下文信息。因此,语境化嵌入词诞生了!

语境化词嵌入可以根据它们在句子的上下文中携带的含义给出单词不同的嵌入
ELMo不是对每个单词使用固定嵌入,而是在为其中的每个单词分配嵌入之前查看整个句子,它使用在特定任务上训练的双向LSTM来创建这些嵌入。
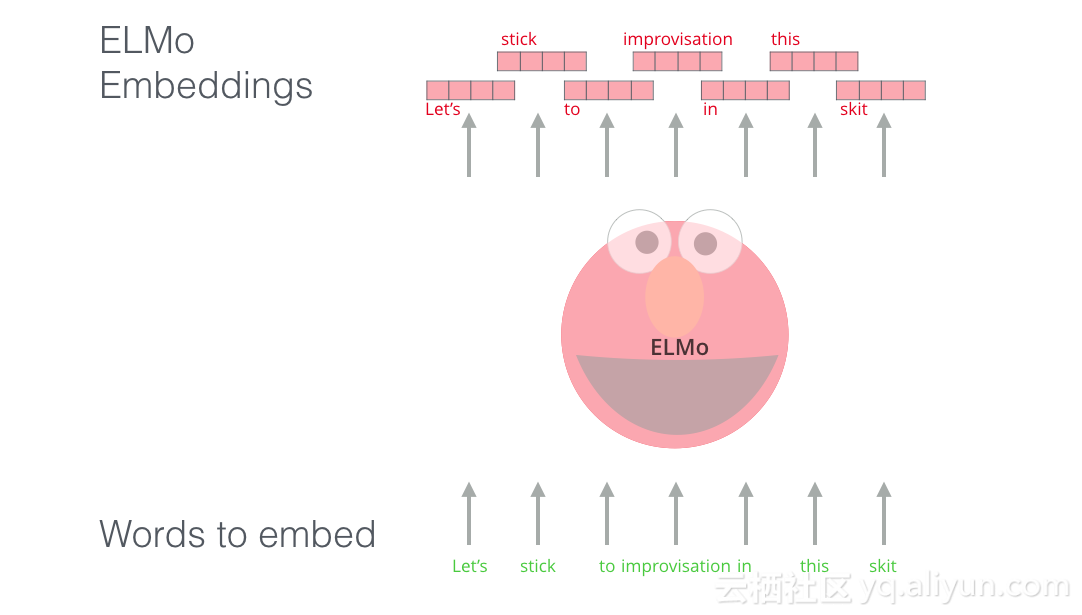
ELMo在NLP背景下向预训练迈出了重要一步。ELMo LSTM将使用我们数据集语言中的大量数据集进行训练,然后我们可以将其用作需要处理语言的其他模型中的组件。
ELMo的秘密是什么?
ELMo通过训练来预测单词序列中的下一个单词,这是一项称为获得语言理解语言建模的任务。这很方便,因为我们拥有大量的文本数据,这样的模型可以在不需要标签的情况下学习。
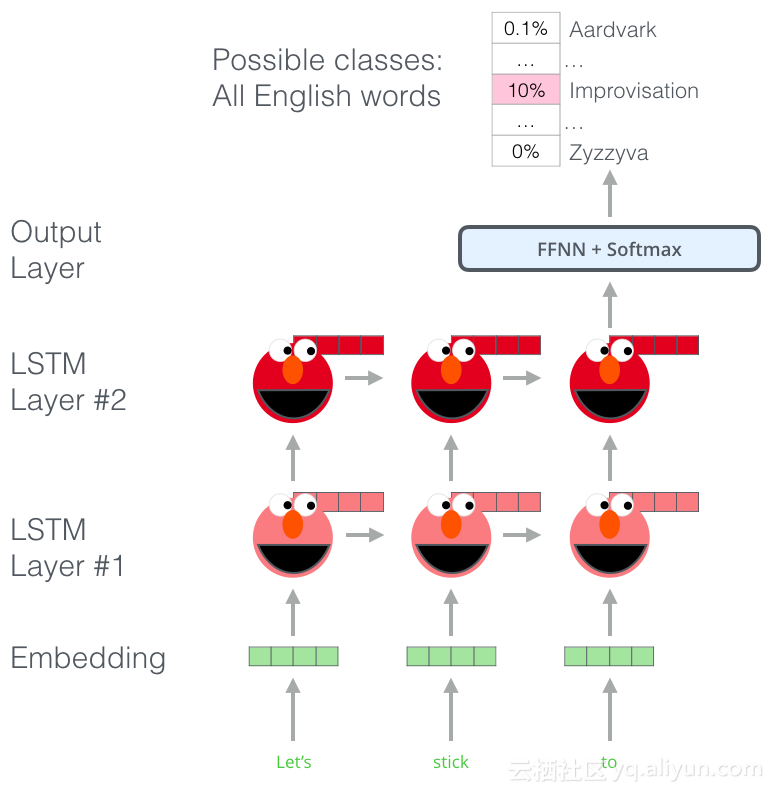
ELMo预训练过程中的一个过程:给定输入,预测下一个最可能的单词。在诸如“hang”之类的单词出现之后,它将为诸如“out”之类的单词赋予比“camera”更高的概率。
我们可以看到每个展开的LSTM步骤的隐藏状态都是从ELMo的头部后面突出。在完成预训练之后,这些在嵌入式proecss可以派上用场。
ELMo实际上更进一步,因为双向LSTM,这意味着它的语言模型不仅具有下一个词的感觉,而且还有前一个词。
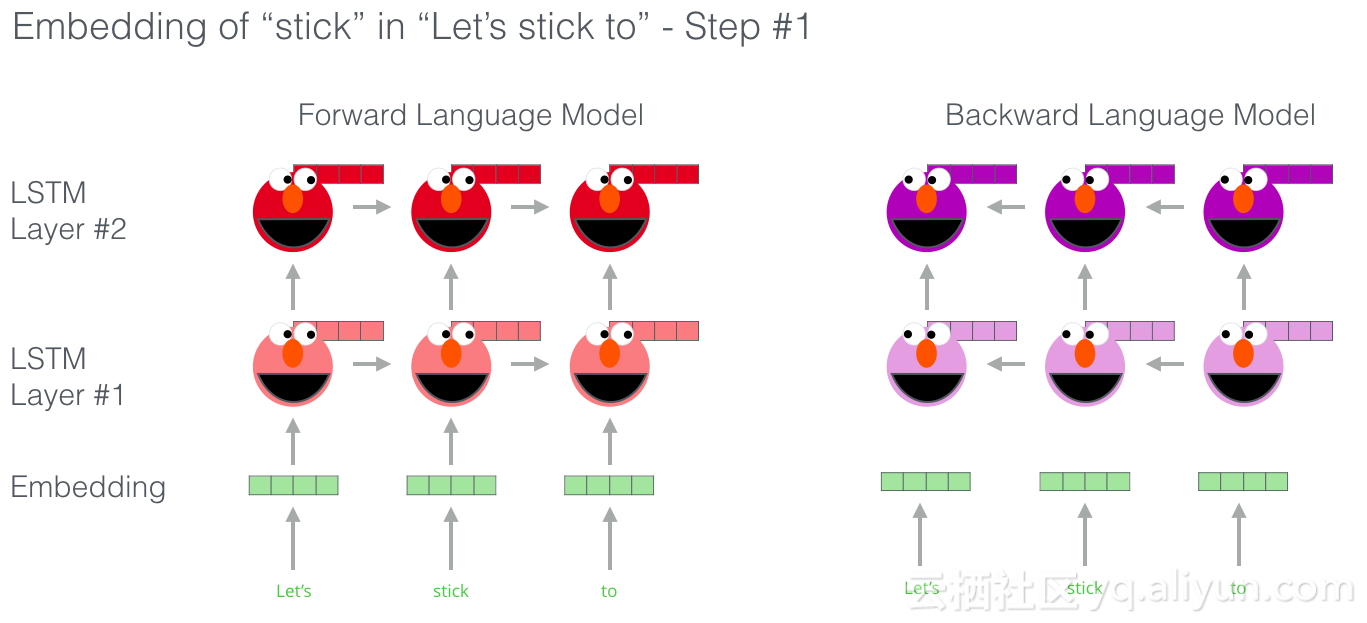
ELMo通过以某种方式将隐藏状态(和初始嵌入)组合在一起来提出情境化嵌入(连接后加权求和)。
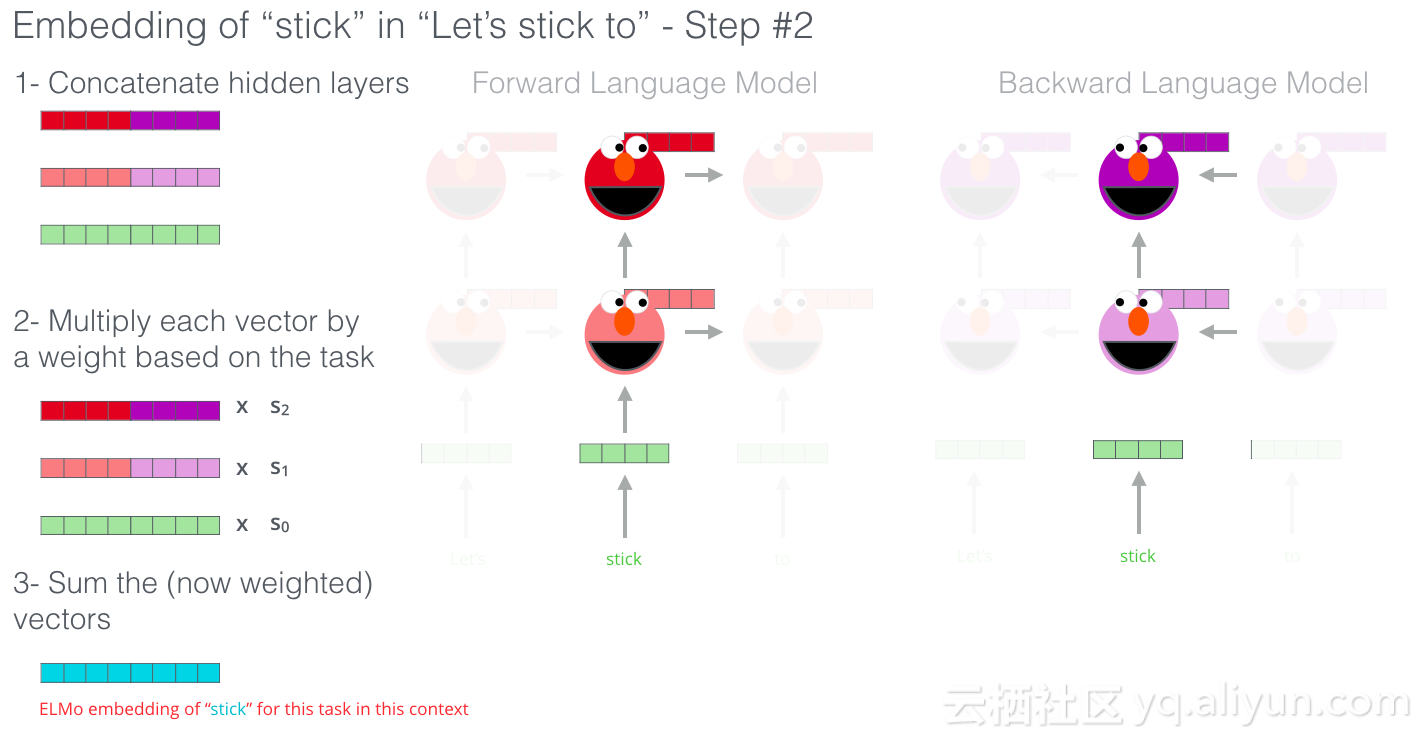
ULM-FiT:在NLP中使用迁移学习
ULM-FiT引入了有效利用模型在预训练期间学到的内容的方法,这不仅仅是嵌入,而且是上下文嵌入。ULM-FiT引入了语言模型和流程,从而有效地微调该语言模型以执行各种任务。
NLP可能与计算机视觉一样,有了一种方法来进行转移学习。
The Transformer:超越LSTMs
Transformer论文和代码的发布,以及它在机器翻译等任务上取得的成果开始让一些人认为它们是LSTM的替代品。事实上Transformer比LSTM更好地处理长期依赖性。
Transformer的编码器-解码器结构使其非常适合机器翻译。但是你如何将它用于句子分类?你如何使用它来预训练可以针对其他任务进行微调的语言模型(这些任务就是被该领域称为使用预训练模型或组件的监督学习任务)。
OpenAI Transformer:预训练用于语言建模的Transformer解码器
事实证明,我们不需要整个Transformer来为NLP任务采用转移学习和精细可调语言模型,我们可以只使用Transformer的解码器。解码器是一个很好的选择,因为它是语言建模(预测下一个单词)的必备选择,它是为掩盖未来的接口而构建的。

OpenAI Transformer由Transformer的解码器堆栈组成
该模型堆叠了十二个解码器层。由于在该设置中没有编码器,因此这些解码器层将不具有香草Transformer解码器层具有的编码器。然而,它仍然会有自我关注层。
通过这种结构,我们可以继续在同一语言建模任务上训练模型:使用大量(未标记)数据集预测下一个单词。只是使用7000本书的文字,让它学习!书籍非常适合这类任务,因为它允许模型学习关联相关信息,即使它们被大量文本分开。例如,当你使用推文或文章进行训练时,你无法获得这些信息。
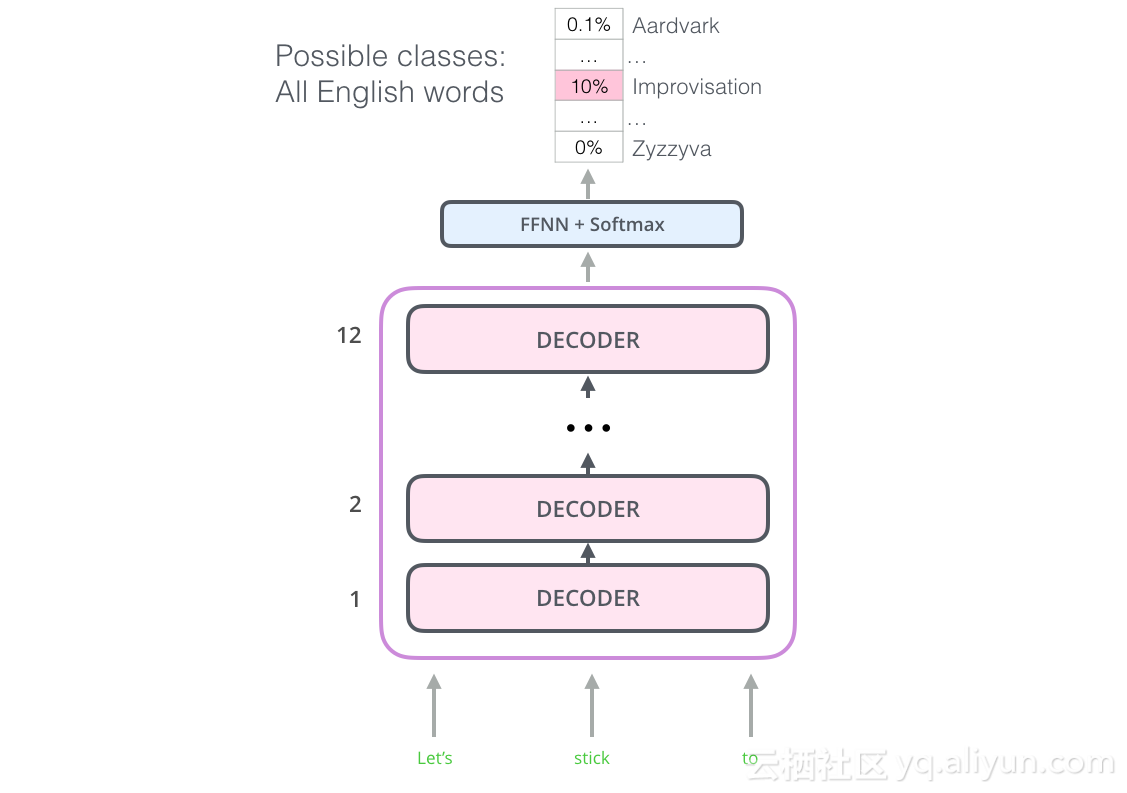
现在,OpenAI Transformer已经准备好接受训练,预测由7,000本书组成的数据集上的下一个单词。
将学习能力转移到下游任务
既然OpenAI Transformer已经过预先训练,并且其层也经过调整以合理地处理语言,我们就可以开始将它用于下游任务。让我们首先看一下句子分类(将电子邮件分类为“垃圾邮件”或“非垃圾邮件”):
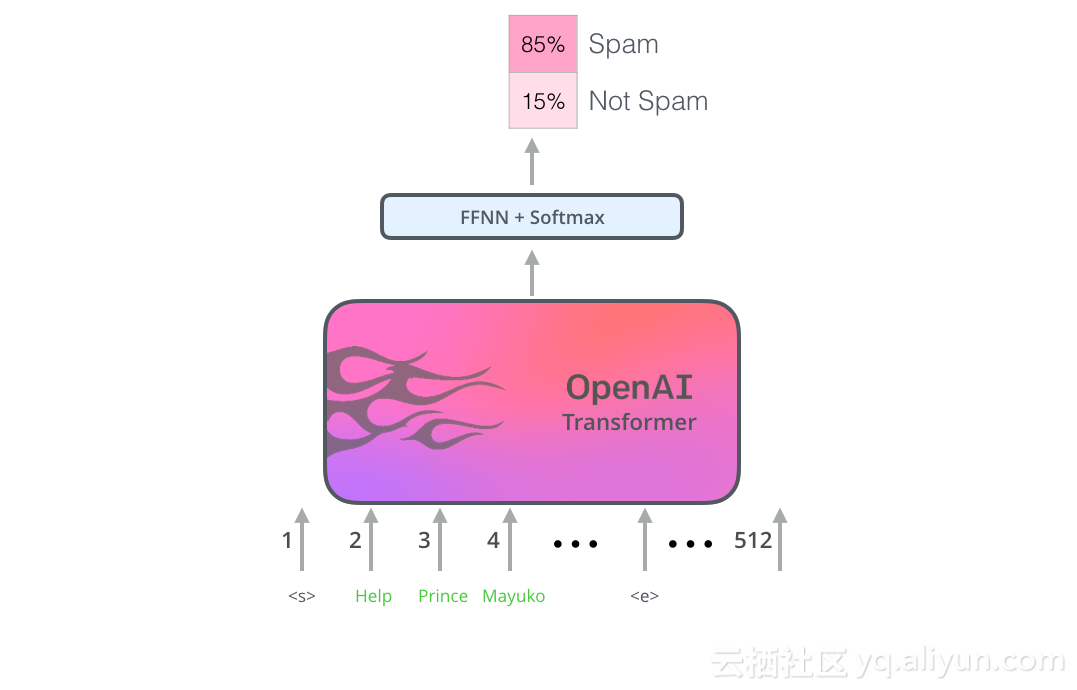
如何使用预先训练的OpenAI Transformer进行句子分类
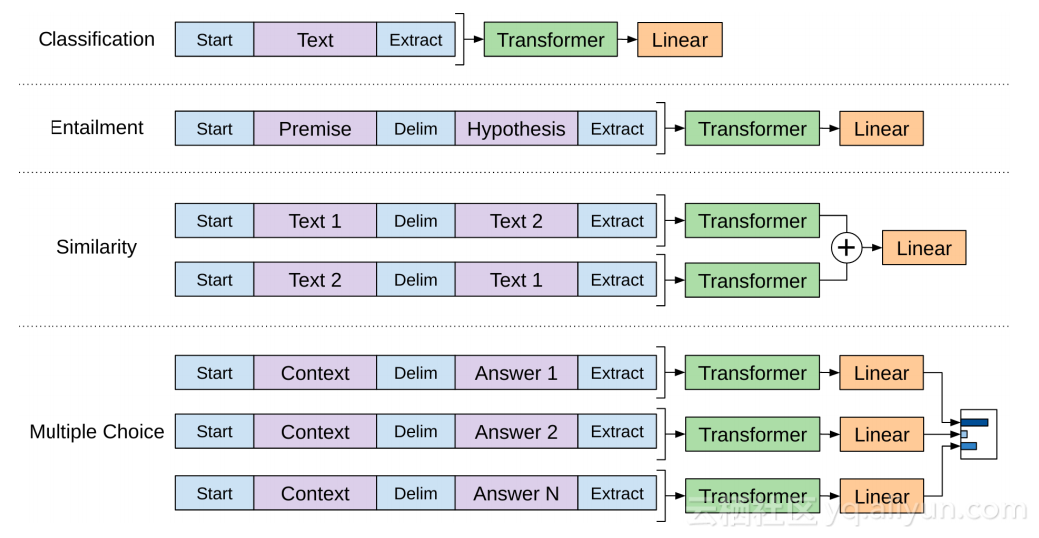
OpenAI论文概述了许多输入转换,以处理不同类型任务的输入。下图显示了模型的结构和输入转换,以执行不同的任务。
BERT:从解码器到编码器
openAI的Transformer为我们提供了基于Transformer的可调预训练模型。但是从LSTM到Transformer的过渡中缺少了一些东西,因为ELMo的语言模型是双向的,但openAI的Transformer只训练向前语言模型。我们能否建立一个基于Transformer的模型,其语言模型同时向前和向后?
蒙面语言模型(NLM:Masked Language Model)
“我们将使用Transformer编码器”,BERT说。
“这很疯狂”,Ernie回答说,“每个人都知道双向调节会让每个词在多层次的背景下间接地审视自己。”
“我们将使用蒙面工具”,BERT自信地说。
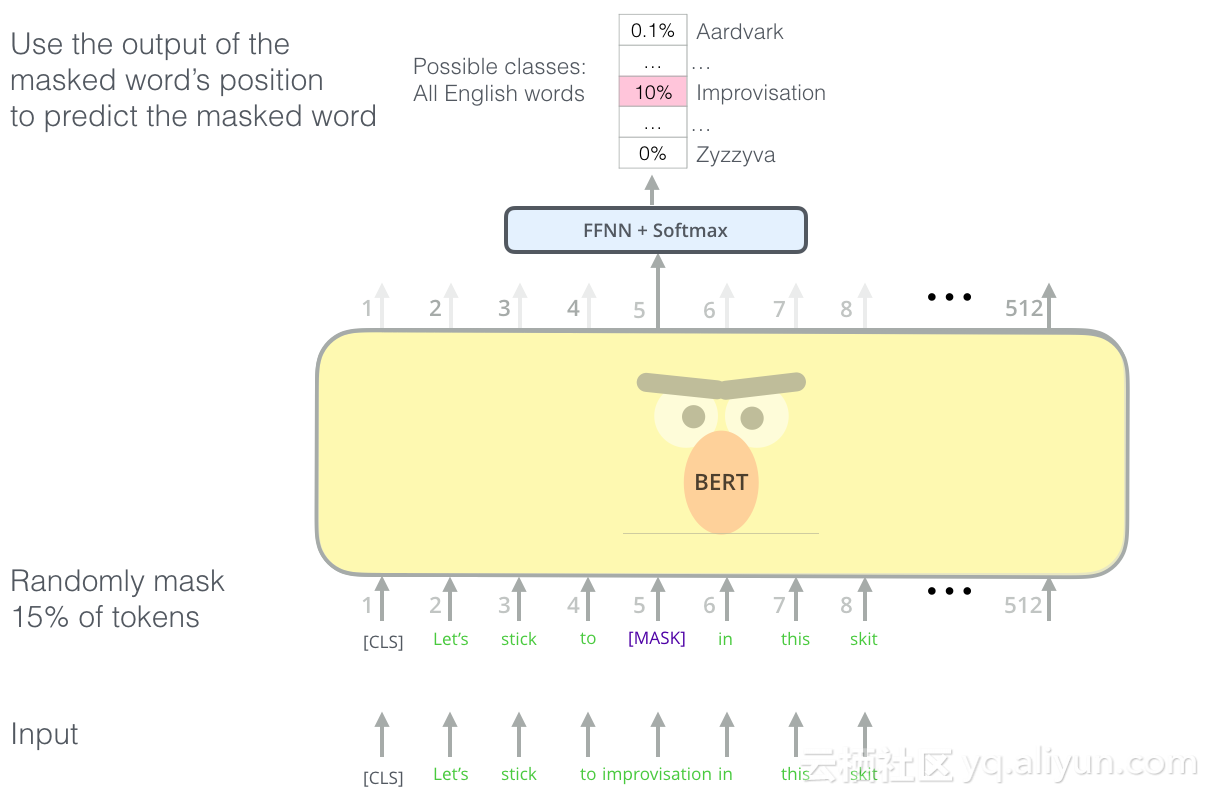
BERT的语言建模任务掩盖了输入中15%的单词,并要求模型预测缺失的单词。
找到正确的任务来训练Transformer堆栈的编码器是一个复杂的障碍,BERT通过采用早期文献中的“蒙面语言模型”概念(称为完成任务)来解决。
除了掩盖15%的输入之外,BERT还混合了一些东西,以改善模型后来如何微调。有时它会随机用另一个单词替换一个单词,并要求模型预测该位置的正确单词。
两个句子的任务(Two-sentence Tasks)
如果你回顾一下OpenAI的Transformer处理不同任务的输入变换,你会注意到一些任务要求模型具有说出两个句子的能力(例如,它们是否只是对方的复述?给出一个维基百科条目作为输入,以及关于该条目作为另一个输入的问题。)。
为了使BERT更好地处理多个句子之间的关系,预训练过程包括一个额外的任务:给定两个句子(A和B),B可能是跟随A的句子,或不是?

由于BERT实际上使用WordPieces作为接口而不是单词,因此标记化在此图形中过于简化了,因此有些单词被分解为较小的块。
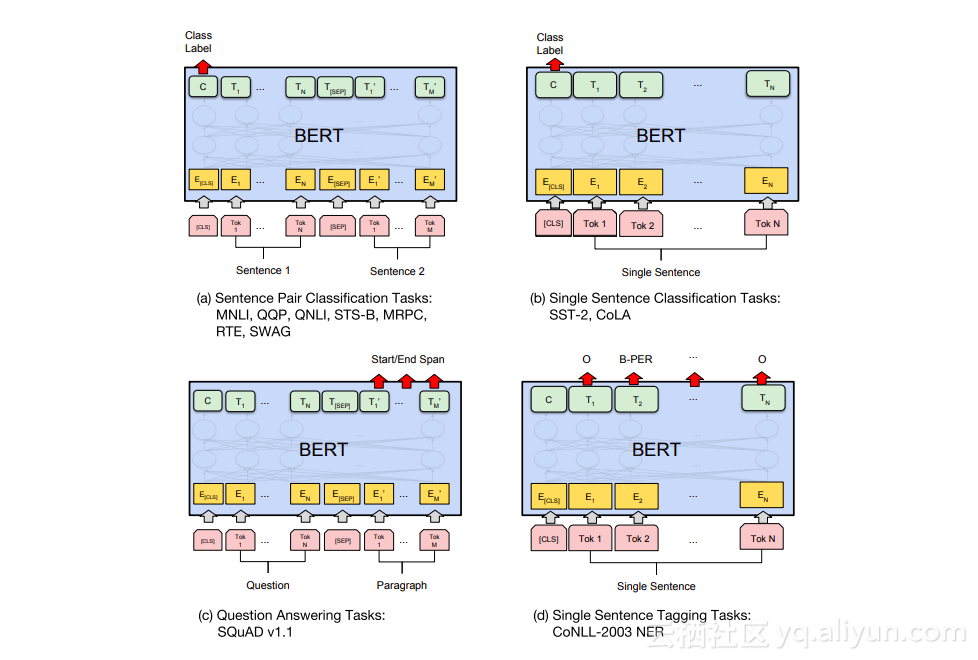
特定任务-模型
BERT论文展示了将BERT用于不同任务的多种方法。
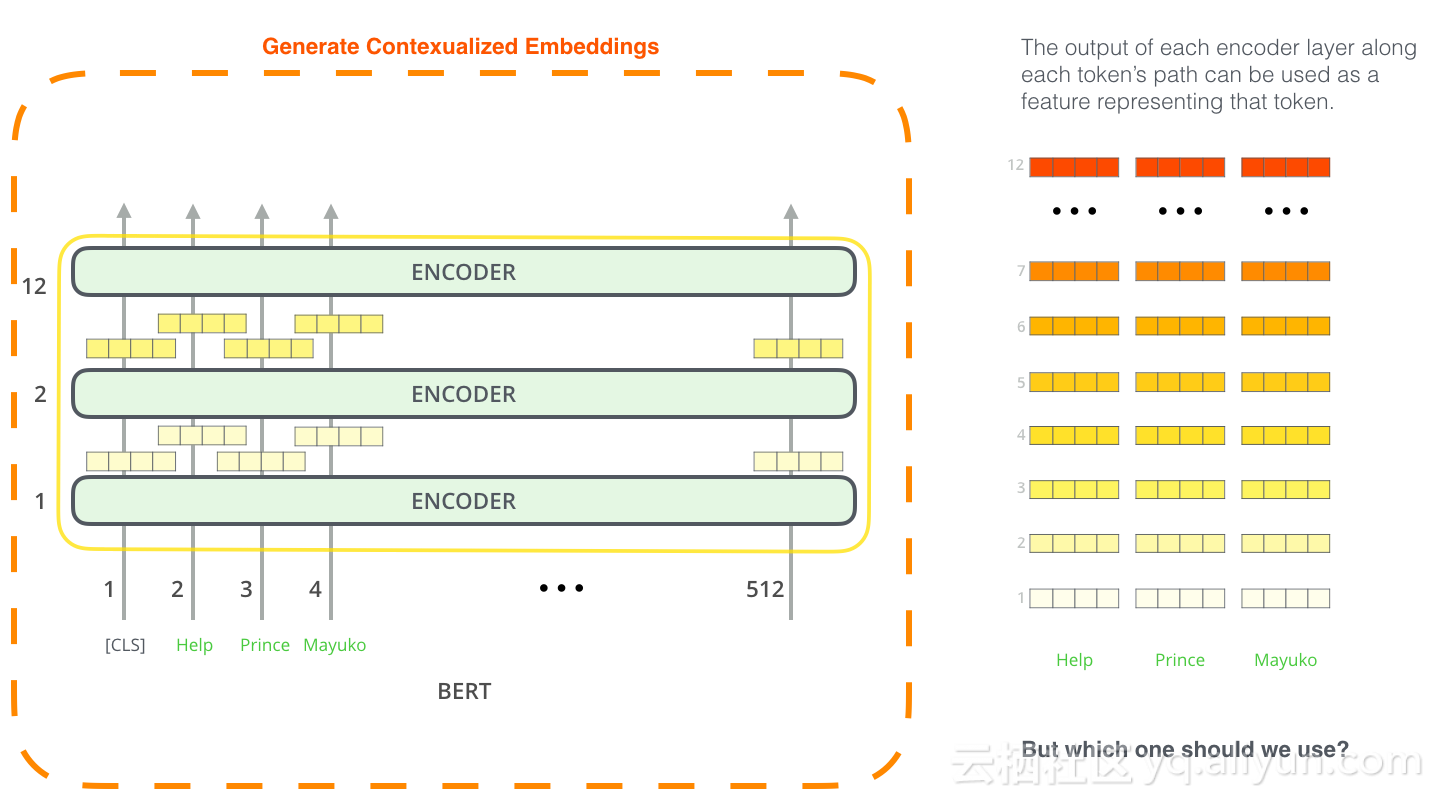
BERT用于特征提取
微调不是使用BERT的唯一方法。就像ELMo一样,你可以使用预先训练的BERT来创建语境化词嵌入。然后,你可以将这些嵌入提供给现有模型-该过程论文已经证实可以产生结果,在命名实体识别等任务上应用微调BERT并不远。
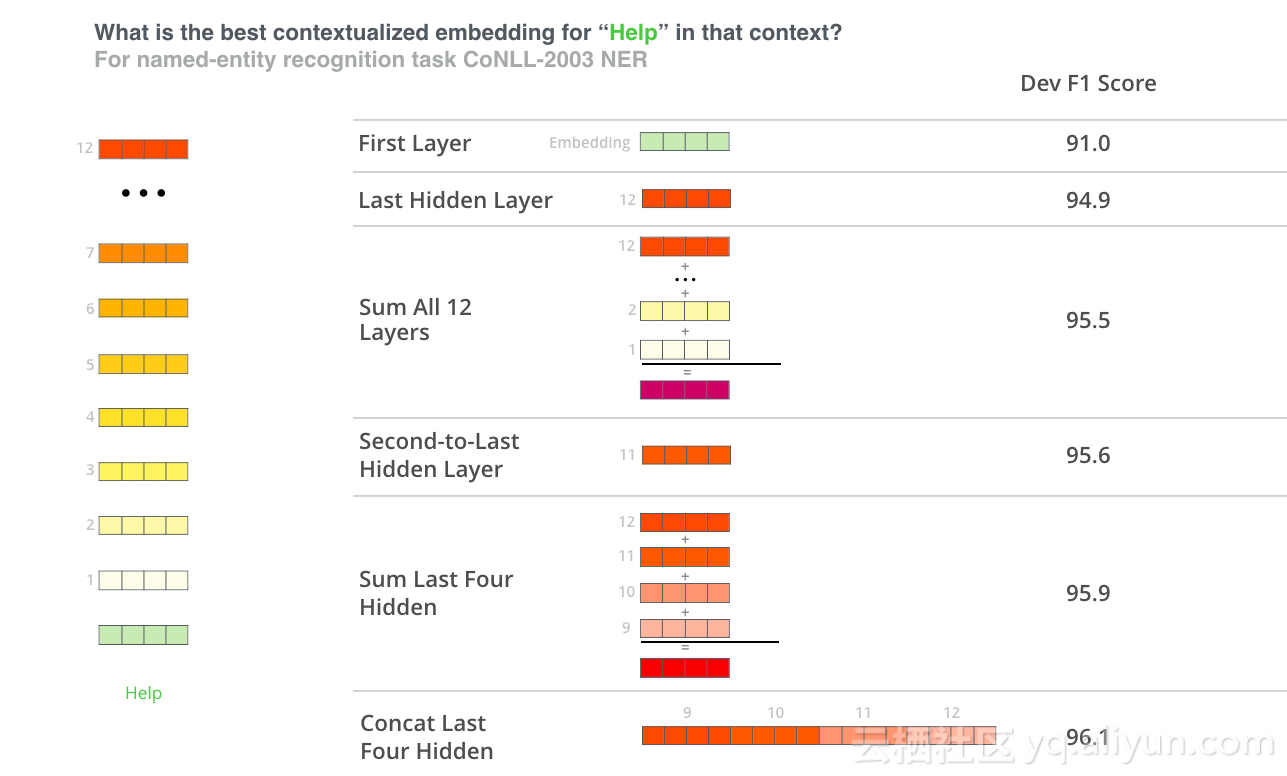
哪个向量最适合作为上下文嵌入?我认为这取决于任务。我们考察了六种选择(与微调模型相比,得分为96.4):
BERT延伸
使用BERT的最佳方式是通过BERT FineTuning与Google Colab托管的Cloud TPU笔记本。如果你之前从未使用过云TPU,那么这也是尝试它们的良好起点,以及BERT代码也适用于TPU,CPU和GPU。
下一步是查看BERT仓库中的代码:
l 该模型在modeling.py(class BertModel)中构建,与vanilla Transformer编码器完全相同。
l run_classifier.py是微调过程的一个示例。它还构建了监督模型的分类层,如果要构建自己的分类器,请查看create_model()该文件中的方法。
l 可以下载几种预先训练的模型,它们跨越了BERT Base和BERT Large,以及英语,中文等语言,以及涵盖102种语言的多语言模型,这些语言在维基百科上进行了训练。
l BERT不会将单词视为标记,相反,它注意者WordPieces。tokenization.py是将你的单词转换为适合BERT的wordPieces的标记器。
l 你还可以查看BERT的PyTorch实现。该AllenNLP库使用此实现允许使用的嵌入BERT与任何模型。
本文由阿里云云栖社区组织翻译。
文章原标题《The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)》
作者:Jay Alammar 译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。
迁移学习NLP:BERT、ELMo等直观图解相关推荐
- Pytorch:NLP 迁移学习、NLP中的标准数据集、NLP中的常用预训练模型、加载和使用预训练模型、huggingface的transfomers微调脚本文件
日萌社 人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) run_glue.py微调脚本代码 python命令执行run ...
- 自然语言处理中的迁移学习(上)
作者:哈工大SCIR 徐啸 来源:Transfer Learning in Natural Language Processing Tutorial (NAACL 2019) 作者:Sebastian ...
- vs需要迁移_赛尔笔记 | 自然语言处理中的迁移学习(上)
点击上方"MLNLP",选择"星标"公众号 重磅干货,第一时间送达 作者:哈工大SCIR 徐啸 转载自公众号:哈工大SCIR 来源:Transfer Learn ...
- 迁移学习 nlp_NLP的发展-第3部分-使用ULMFit进行迁移学习
迁移学习 nlp This is the third part of a series of posts showing the improvements in NLP modeling approa ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- 图解BERT、ELMo(NLP中的迁移学习)| The Illustrated BERT, ELMo, and co.
看我看我 这是我翻译这位大佬的第三篇文章了,我的翻译结束,翻译授权见最后. 之前的工作: 图解transformer | The Illustrated Transformer 图解GPT-2 | T ...
- 图解当前最强语言模型BERT:NLP是如何攻克迁移学习的?
选自jalammar.github.io 作者:Jay Alammar 机器之心编译 参与:Panda 前段时间,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT,该预训练 ...
- 如何用最强模型BERT做NLP迁移学习?
作者 | 台湾大学网红教授李宏毅的三名爱徒 来源 | 井森堡,不定期更新机器学习技术文并附上质量佳且可读性高的代码. 编辑 | Jane 谷歌此前发布的NLP模型BERT,在知乎.Reddit上都引起 ...
- bert 中文 代码 谷歌_如何用最强模型BERT做NLP迁移学习?
作者 | 台湾大学网红教授李宏毅的三名爱徒 来源 | 井森堡,不定期更新机器学习技术文并附上质量佳且可读性高的代码. 编辑 | Jane 谷歌此前发布的NLP模型BERT,在知乎.Reddit上都引起 ...
最新文章
- C++字符串函数与C字符串函数比较
- 学习Vim有什么好处? [关闭]
- 计算机技术应用及信息管理,计算机应用技术与信息管理整合研究(共2808字).doc...
- 10个实用的但偏执的Java编程技术
- Go包导入与Java的差别
- 开发函数计算的正确姿势——运行 Selenium Java
- Angular - angular2升级到angular8
- 证书体系: PFX 文件格式解析
- 结合深度学习的工业大数据应用研究
- Android开发中使用startActivityForResult()方法从Activity A跳转Activity B出现B退出时A也同时退出的解决办法...
- word中文输入时,符号却是英文符号,修改方法
- web 实现在线拍照。。
- android技术牛人的博客[转]
- python中的MRO
- 计算机电子表格题教程,计算机电子表格题教程.doc
- 单调队列java_单调队列单调栈
- gba模拟器ios_不越狱iOS设备安装GBA模拟器 GBA4iOS 方法
- (转)被讨厌的勇气--目录
- 2016年软件产业规模
- 基于javaweb的宠物商城系统(java+jsp+javascript+servlet+mysql)
热门文章
- Java中JMX管理器的作用,项目中有什么具体使用?
- Java 多线程:synchronized 关键字用法(修饰类,方法,静态方法,代码块)
- [MySQL] 索引与性能(3)- 覆盖索引
- Eclipse、NetBeans、IntelliJ集成开发工具 Java IDE
- 论文返修(response letter)最有用的开场白
- Python入门笔记(17):错误、异常
- 【数字智能三篇】之三: 一页纸说清楚“什么是深度学习?”
- SIFT(ASIFT) Matching with RANSAC
- Hadoop命令手册
- 斯坦福大学机器学习第十课“应用机器学习的建议(Advice for applying machine learning)”