HBase在阿里搜索中的应用实践
http://blog.51cto.com/wangxy/1952591
李钰,花名绝顶,WOTA全球架构与运维技术峰会分享嘉宾,现任阿里巴巴搜索事业部高级技术专家,HBase开源社区PMC & committer。开源技术爱好者,主要关注分布式系统设计、大数据基础平台建设等领域。连续3年基于HBase/HDFS设计和开发存储系统应对双十一访问压力,具备丰富的大规模集群生产实战经验。
HBase作为淘宝全网索引构建以及在线机器学习平台的核心存储系统,是阿里搜索基础架构的重要组成部分。本文我们将介绍HBase在阿里搜索的历史、规模,应用的场景以及在实际应用当中遇到的问题和优化。
HBase在阿里搜索的历史、规模和服务能力
历史:阿里搜索于2010年开始使用HBase,从最早到目前已经有十余个版本。目前使用的版本是在社区版本的基础上经过大量优化而成。社区版本建议不要使用1.1.2版本,有较严重的性能问题, 1.1.3以后的版本体验会好很多。
集群规模:目前,仅在阿里搜索节点数就超过3000个,最大集群超过1500个。阿里集团节点数远远超过这个数量。
服务能力:去年双十一,阿里搜索离线集群的吞吐峰值一秒钟访问超过4000万次,单机一秒钟吞吐峰值达到10万次。还有在CPU使用量超过70%的情况下,单cpu core还可支撑 8000+ QPS。
HBase在阿里搜索的角色和主要应用场景
角色:HBase是阿里搜索的核心存储系统,它和计算引擎紧密结合,主要服务搜索和推荐的业务。
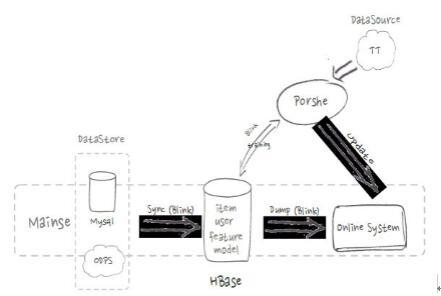
HBase在搜索和推荐的应用流程
如上图,是HBase在搜索和推荐的应用流程。在索引构建流程中会从线上MySQL等数据库中存储的商品和用户产生的所有线上数据通过流式的方式导入到HBaes中,并提供给搜索引擎构建索引。在推荐流程中,机器学习平台Porshe会将模型和特征数据存储在HBase里,并将用户点击数据实时的存入HBase,通过在线training更新模型,提高线上推荐的准确度和效果。
应用场景一:索引构建。淘宝和天猫有各种各样的的线上数据源,这取决于淘宝有非常多不同的线上店铺和各种用户访问。
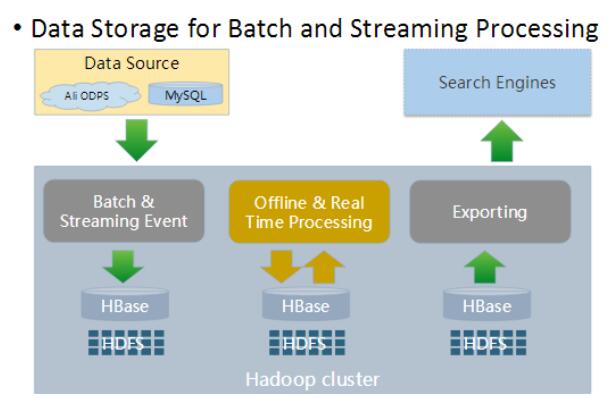
索引构建应用场景
如上图,在夜间我们会将数据从HBase批量导出,供给搜索引擎来构建全量索引。而在白天,线上商品、用户信息等都在不停的变化,这些动态的变化数据也会从线上存储实时的更新到HBase并触发增量索引构建,进而保证搜索结果的实时性。
目前,可以做到端到端的延时控制在秒级,即库存变化,产品上架等信息在服务端更新后,迅速的可在用户终端搜索到。

索引构建应用场景抽象图
如上图,整个索引构建过程可以抽象成一个持续更新的流程。如把全量和增量看做是一个Join,线上有不同的数据源且实时处于更新状态,整个过程是长期持续的过程。这里,就凸显出HBase和流式计算引擎相结合的特点。
应用场景二:机器学习。这里举一个简单的机器学习示例:用户想买一款三千元的手机,于是在淘宝按照三千元的条件筛选下来,但是没有中意的。之后 ,用户会从头搜索,这时就会利用机器学习模型把三千块钱左右的手机排在搜索结果的靠前位置,也就是用前一个搜索结果来影响后一个搜索结果的排序。
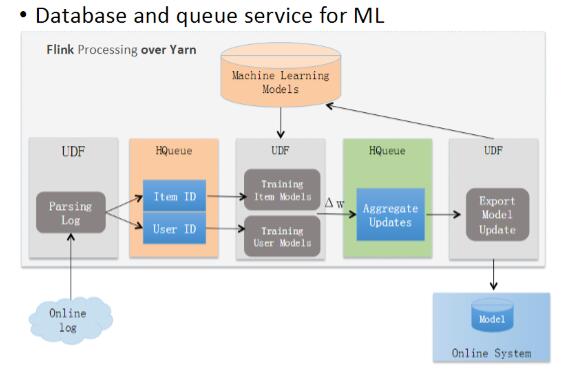
分析线上日志
如上图,分析线上日志,归结为商品和用户两个纬度,导入分布式、持久化消息队列,存放到HBase上。随线上用户的点击行为日志来产生数据更新,对应模型随之更新,进行机器学习训练,这是一个反复迭代的过程。
HBase在阿里搜索应用中遇到的问题和优化
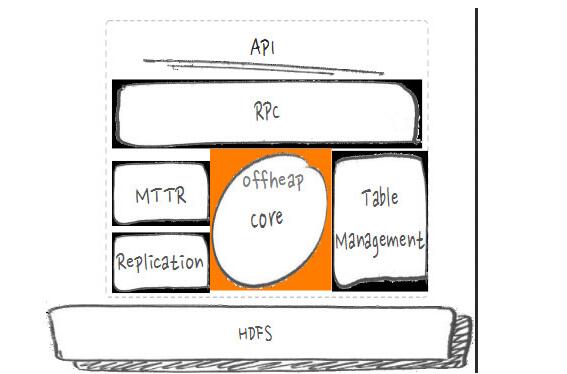
HBase架构分层。在说问题和优化之前,先来看HBase的架构图,大致分为如下几个部分:
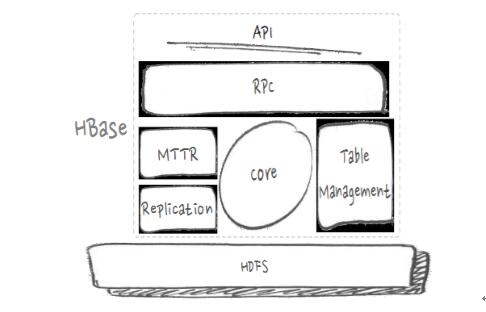
HBase的架构图
首先是API,一些应用程序编程接口。RPC,这里把远程过程调用协议分为客户端会发起访问与服务端来处理访问两部分。MTTR故障恢复、Replication数据复制、表处理等,这些都是分布式管理的范畴。中间Core是核心的数据处理流程部分,像写入、查询等,最底层是HDFS(分布式文件系统)。HBase在阿里搜索应用中遇到的问题和优化有很多,下面挑选近期比较重点的RPC的瓶颈和优化、异步与吞吐、GC与毛刺、IO隔离与优化、IO利用这五方面进行展开。
问题与优化一:RPC的瓶颈和优化
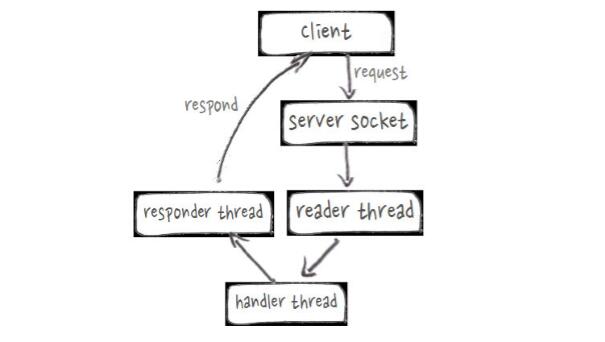
RPC Server线程模型
PPC服务端的实际问题是原有RpcServer线程模型效率较低,如上图,可以看到整个过程通常很快,但会由不同的线程来处理,效率非常低。基于Netty重写之后,可以更高效的复用线程,实现HBase RpcServer。使得RPC平均响应时间从0.92ms下降到0.25ms,吞吐能力提高接近2倍。
问题与优化二:异步与吞吐
RPC的客户端存在的实际问题是流式计算对于实时性的要求很高、分布式系统无法避免秒级毛刺、同步模式对毛刺敏感,吞吐存在瓶颈。优化手段就是基于netty实现non-blocking client,基于protobuf的non-blocking Stub/RpcCallback实现callback回调,当和flink集成后实测吞吐较同步模式提高2倍。
问题与优化三: GC与毛刺
如上图,这部分的实际问题是PCIe-SSD的高IO吞吐能力下,读cache的换入换出速率大幅提高、堆上的cache内存回收不及时,导致频繁的CMS gc甚至fullGC。优化手段是实现读路径E2E的offheap,使得Full和CMS gc频率降低200%以上、读吞吐提高20%以上。
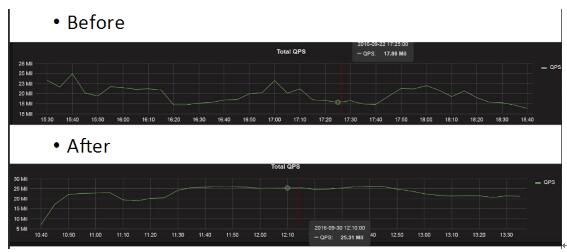
如上图,是线上的一个结果,QPS之前是17.86M,优化之后是25.31M。
问题与优化四: IO隔离与优化
HBase本身对IO非常敏感,磁盘打满会造成大量毛刺。在计算存储混合部署环境下,MapReduce作业产生的shuffle数据和HBase自身Flush/Compaction这两方面都是大IO来源。
如何规避这些影响呢?利用HDFS的Heterogeneous Storage功能,对WAL(write-ahead-log)和重要业务表的HFile使用ALL_SSD策略、普通业务表的HFile使用ONE_SSD策略,保证Bulkload支持指定storage policy。同时,确保MR临时数据目录(mapreduce.cluster.local.dir)只使用SATA盘。
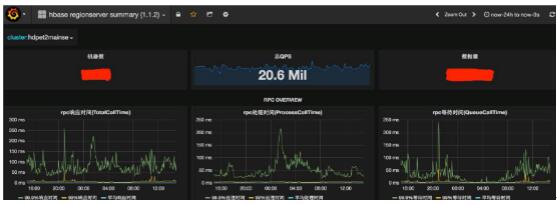
HBase集群IO隔离后的毛刺优化效果
对于HBase自身的IO带来的影响,采用Compaction限流、Flush限流和Per-CF flush三大手段。上图为线上效果,绿线从左到右分别是响应时间、处理时间和等待时间的p999数据,以响应时间为例,99.9%的请求不会超过250ms。
问题与优化五: IO利用
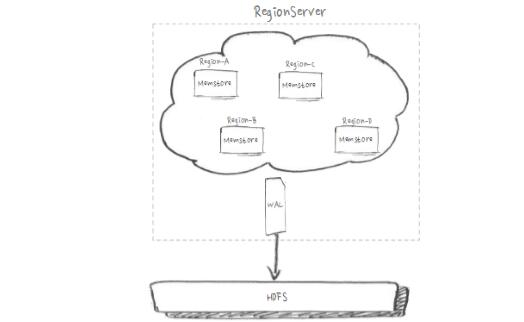
HDFS写3份副本、通用机型有12块HDD盘、SSD的IO能力远超HDD。如上图,实际问题是单WAL无法充分使用磁盘IO。
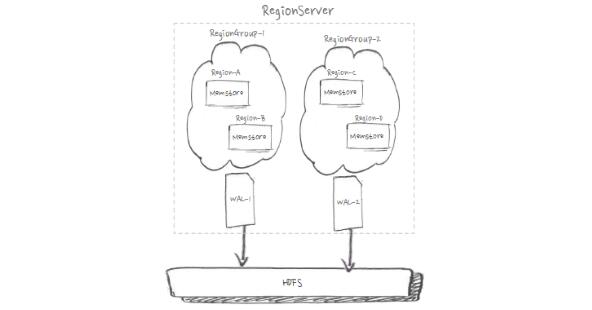
如上图,为了充分利用IO,我们可以通过合理映射对region进行分组,来实现多WAL。基于Namespace的WAL分组,支持App间IO隔离。从上线效果来看,全HDD盘下写吞吐提高20%,全SSD盘下写吞吐提高40%。线上写入平均响应延时从0.5ms下降到0.3ms。
开源&未来
为什么要拥抱开源?其一,试想如果大家做了优化都不拿出来,认为这是自己强于别人的优势,结果会怎样?如果大家把自己的优势都拿出来分享,得到的会是正向的反馈。其二, HBase的团队一般都比较小,人员流失会产生很大的损失。如把内容贡献给社区,代码的维护成本可以大大降低。开源一起做,比一个公司一个人做要好很多,所以我们要有贡献精神。
未来,一方面,阿里搜索会进一步把PPC服务端也做异步,把HBase内核用在流式计算、为HBase提供嵌入式的模式。另一方面,尝试更换HBase内核,用新的DB来替代,达到更高的性能
转载于:https://www.cnblogs.com/davidwang456/articles/8820568.html
HBase在阿里搜索中的应用实践相关推荐
- 大数据HBase在阿里搜索中的应用实践
HBase作为淘宝全网索引构建以及在线机器学习平台的核心存储系统,是阿里搜索基础架构的重要组成部分.本文我们将介绍HBase在阿里搜索的历史.规模,应用的场景以及在实际应用当中遇到的问题和优化. HB ...
- 【实践】文本相关性和知识蒸馏在知识蒸馏中的应用实践
今天给大家带来知乎搜索团队申站所做的分享<文本相关性和知识蒸馏在知乎搜索中的应用实践.pdf>,本次分享共包含如下四大部分: 1.知乎搜索文本相关性的演进: 2.BERT的应用和问题: 3 ...
- 首次公开!阿里搜索中台开发运维一体化实践
阿里妹导读:2015年底,阿里宣布启动阿里巴巴集团中台战略.战略定义为:构建符合DT时代的更具创新性.灵活性的"大中台.小前台"组织机制和业务机制.其中,前台作为一线业务,更敏捷更 ...
- HBase在大搜车金融业务中的应用实践
摘要: 2017云栖大会HBase专场,大搜车高级数据架构师申玉宝带来HBase在大搜车金融业务中的应用实践.本文主要从数据大屏开始谈起,进而分享了GPS风控实践,包括架构.聚集分析等,最后还分享了流 ...
- ML:阿里云计算平台之搜索推荐演讲分享《多场景智能推荐助力业务增长》、《阿里云智能推荐应用实践:PAI-EasyRec Framework》、《新一代数仓架构漫谈》
ML:阿里云计算平台之搜索推荐演讲分享<多场景智能推荐助力业务增长>.<阿里云智能推荐应用实践:PAI-EasyRec Framework>.<新一代数仓架构漫谈> ...
- 大数据时代的结构化存储-HBase在阿里的应用实践
前言 时间回到2011年,Hadoop作为新生事物,在阿里巴巴已经玩得风生水起,上千台规模的"云梯"是当时国内名声显赫的计算平台. 这一年,Hadoop的好兄弟HBase由毕玄大师 ...
- 美团搜索中NER技术的探索与实践
1. 背景 命名实体识别(Named Entity Recognition,简称NER),又称作"专名识别",是指识别文本中具有特定意义的实体,主要包括人名.地名.机构名.专有名词 ...
- hbase中为何不能向表中插入数据_生产环境使用HBase,你必须知道的最佳实践 | 百万人学AI...
叮咚-你被福利砸中了!现在起,「2020 AI开发者万人大会」299门票免费送!进入报名页面[2020 AI 开发者万人大会(线上直播门票)-IT培训直播-CSDN学院],点击"立即报名&q ...
- 美团搜索中查询改写技术的探索与实践
猜你喜欢 0.[免费下载]2022年1月热门报告盘点1.腾讯QQ信息流推荐业务实践2.小红书推荐中台实践3.微信视频号的实时推荐技术架构分享4.预训练模型在华为信息流推荐系统中的探索和应用5.腾讯PC ...
最新文章
- SILK 的 Delay Decision 和 Dither
- c#实现客户端程序自动下载更新(单独程序)
- 计算机word表格居中,word表格居中怎么弄
- python如何读取excel数据-使用Python读取电子表格中的数据
- Eclipse Class Decompiler---Java反编译插件
- Python的一些特殊用法总结
- linux 服务器 重新启动 慢,Linux系统启动缓慢解决方法[阮胜昌]
- 振臂高呼式的写作:谈肖亦农的《毛乌素绿色传奇》
- 如何将文件拷贝服务器上,如何将文件复制到云服务器上
- DataParallel 和 DistributedDataParallel 的区别和使用方法
- LVDS原理及设计指南
- gulp + webpack + sass 学习
- JavaScript学习(十一)—selected属性、checked属性、class属性的操作
- Java 异常的捕获与处理详解 (一)
- 做APP,从头到尾产品经理需要做什么?- 项目启动前
- .Net C# Lambda表达式
- 微信群裂变引流效果怎么样?微信社群引流怎么操作?
- Gartner数据库魔力象限2022:阿里领先、腾讯再次进入、华为退出
- github忘记邮箱找回办法
- Go开发之如何破解安装GoLand编译器?
热门文章
- android+模拟器皮肤,自定义android模拟器皮肤和键盘映射
- 简单计算器的设计java_(基于java的简易计算器的设计.doc
- spring boot第八讲
- matlab 连续显示,请教下MATLAB一个问题啊 我想检测一行数据里面出现连续出现0的次数,...
- 服务器安装系统时无法创建新的分区,重装系统出现“我们无法创建新的分区,也找不到现有的分区”...
- python的web抓取_python实现从web抓取文档的方法
- 鸿蒙os智慧屏体验,华为智慧屏首发体验!搭载鸿蒙OS+AI芯片,还有AI教你健身
- java 虚拟机的工作原理
- 异步任务下载apk文件并弹出对话框提示当前进度,文件下载结束后弹出安装界面
- python常见异常