如何为你的回归问题选择最合适的机器学习算法?
当我们要解决任意一种机器学习问题时,都需要选择合适的算法。在机器学习中存在一种“没有免费的午餐”定律,即没有一款机器学习模型可以解决所有问题。不同的机器学习算法表现取决于数据的大小和结构。所以,除非用传统的试错法实验,否则我们没有明确的方法证明某种选择是对的。
但是,每种机器学习算法都有各自的有缺点,这也能让我们在选择时有所参考。虽然一种算法不能通用,但每个算法都有一些特征,能让人快速选择并调整参数。接下来,我们大致浏览几种常见的用于回归问题的机器学习算法,并根据它们的优点和缺点总结出在什么情况下可以使用。
线性和多项式回归
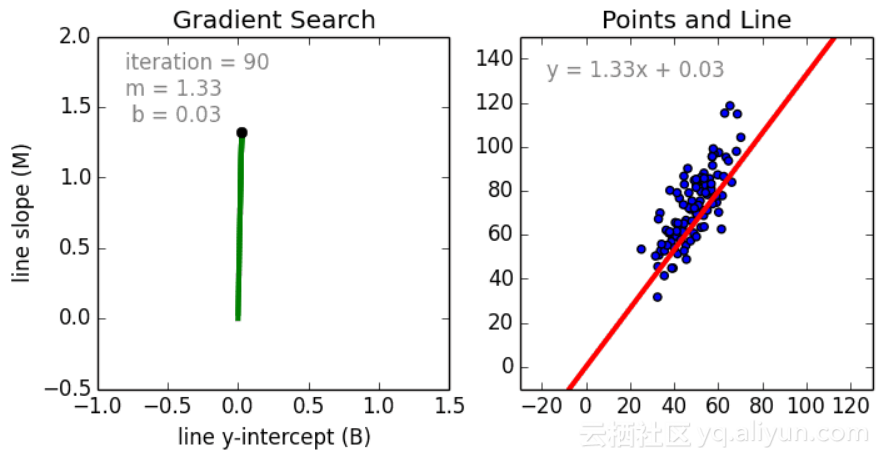
首先是简单的情况,单一变量的线性回归是用于表示单一输入自变量和因变量之间的关系的模型。多变量线性回归更常见,其中模型是表示多个输入自变量和输出因变量之间的关系。模型保持线性是因为输出是输入变量的线性结合。
第三种行间情况称为多项式回归,这里的模型是特征向量的非线性结合,即向量是指数变量,sin、cos等等。这种情况需要考虑数据和输出之间的关系,回归模型可以用随机梯度下降训练。
优点:
● 建模速度快,在模型结构不复杂并且数据较少的情况下很有用。
● 线性回归易于理解,在商业决策时很有价值。
缺点:
● 对非线性数据来说,多项式回归在设计时有难度,因为在这种情况下必须了解数据结构和特征变量之间的关系。
● 综上,遇到复杂数据时,这些模型的表现就不理想了。
神经网络
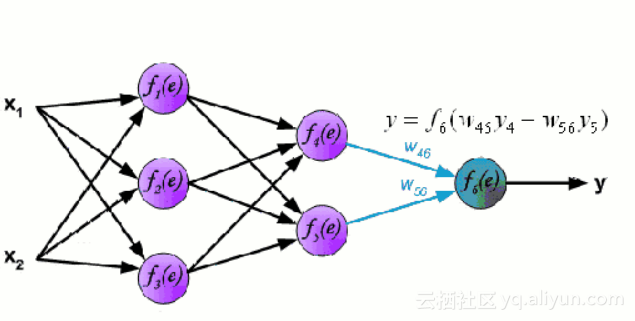
神经网络包含了许多互相连接的节点,称为神经元。输入的特征变量经过这些神经元后变成多变量的线性组合,与各个特征变量相乘的值称为权重。之后在这一线性结合上应用非线性,使得神经网络可以对复杂的非线性关系建模。神经网络可以有多个图层,一层的输出会传递到下一层。在输出时,通常不会应用非线性。神经网络用随机梯度下降和反向传播算法训练。
优点:
● 由于神经网络有很多层(所以就有很多参数),同时是非线性的,它们能高效地对复杂的非线性关系进行建模。
● 通常我们不用担心神经网络中的数据,它们在学习任何特征向量关系时都很灵活。
● 研究表明,单单增加神经网络的训练数据,不论是新数据还是对原始数据进行增强,都会提高网络性能。
缺点:
● 由于模型的复杂性,它们不容易被理解。
● 训练时可能有难度,同时需要大量计算力、仔细地调参并且设置好学习速率。
● 它们需要大量数据才能达到较高的性能,与其他机器学习相比,在小数据集上通常表现更优。
回归树和随机森林
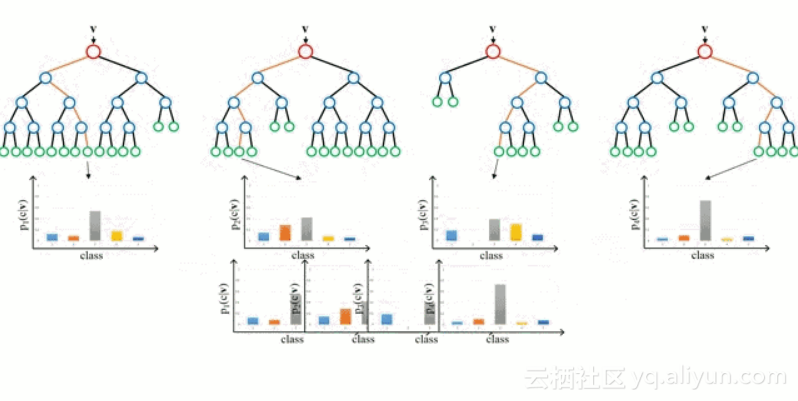
首先从基本情况开始,决策树是一种直观的模型,决策者需要在每个节点进行选择,从而穿过整个“树”。树形归纳是将一组训练样本作为输入,决定哪些从哪些属性分割数据,不断重复这一过程,知道所有训练样本都被归类。在构建树时,我们的目标是用数据分割创建最纯粹的子节点。纯粹性是通过信息增益的概念来衡量的。在实际中,这是通过比较熵或区分当前数据集中的单一样本和所需信息量与当前数据需要进一步区分所需要的信息量。
随机森林是决策树的简单集成,即是输入向量经过多个决策树的过程。对于回归,所有树的输出值是平均的;对于分类,最终要用投票策略决定。
优点:
● 对复杂、高度非线性的关系非常实用。它们通常能达到非常高的表现性能,比多项式回归更好。
● 易于使用理解。虽然最后的训练模型会学会很多复杂的关系,但是训练过程中的决策边界易于理解。
缺点:
● 由于训练决策树的本质,它们更易于过度拟合。一个完整的决策树模型会非常复杂,并包含很多不必要的结构。虽然有时通过“修剪”和与更大的随机森林结合可以减轻这一状况。
● 利用更大的随机森林,可以达到更好地效果,但同时会拖慢速度,需要更多内存。
这就是三种算法的优缺点总结。希望你觉得有用!
原文发布时间为:2018-09-9
本文作者:George Seif
本文来自云栖社区合作伙伴“深度学习自然语言处理”,了解相关信息可以关注“深度学习自然语言处理”。
如何为你的回归问题选择最合适的机器学习算法?相关推荐
- Py之scikit-learn:机器学习sklearn库的简介、六大基本功能介绍(数据预处理/数据降维/模型选择/分类/回归/聚类)、安装、使用方法(实际问题中如何选择最合适的机器学习算法)之详细攻略
Py之scikit-learn:机器学习sklearn库的简介(组件/版本迭代).六大基本功能介绍(数据预处理/数据降维/模型选择/分类/回归/聚类).安装.使用方法(实际问题中如何选择最合适的机器学 ...
- 残差平方和ssr的计算公式为_如何为你的回归问题选择最合适的机器学习方法?...
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 转自 | AI算法之心(公众号ID:AIHeartForYou) 作者 | 何从庆 什么是回归呢?回归 ...
- 如何为回归问题选择最合适的机器学习方法?
作者 | 何从庆 本文经授权转载自 AI算法之心(id:AIHeartForYou) 在目前的机器学习领域中,最常见的三种任务就是:回归分析.分类分析.聚类分析.在之前的文章中,我曾写过一篇<1 ...
- 如何为你的回归问题选择最合适的机器学习方法?
本文作者:何从庆 在目前的机器学习领域中,最常见的三种任务就是:回归分析.分类分析.聚类分析.在之前的文章中,我曾写过一篇<15分钟带你入门sklearn与机器学习--分类算法篇>.那么什 ...
- 入门 | 如何为你的回归问题选择最合适的机器学习方法?
点击"小詹学Python","星标"或"置顶" 关键时刻,第一时间送达 本文转载自"AI算法之心" 在目前的机器学习领域 ...
- 初学者如何选择合适的机器学习算法(附算法速查表)
来源:机器之心 参与:黄小天.蒋思源.吴攀 校对:谭佳瑶 本文长度为4000字,建议阅读6分钟 本文针对算法的选择为你提供一些参考意见. 本文主要的目标读者是机器学习爱好者或数据科学的初学者,以及对学 ...
- logistic回归 简介_从零实现机器学习算法(四)Logistic回归
1. Logistic回归简介 Logistic回归是统计学中的经典分类算法,其原理为计算Logistic分布下的条件概率 选择条件概率大的一方为预测类别.以二分类为例,二项Logistic回归模型的 ...
- 如何为回归问题,选择最合适的机器学习方法?
在目前的机器学习领域中,最常见的三种任务就是:回归分析.分类分析.聚类分析.在之前的文章中,我曾写过一篇<sklearn 与分类算法>.那么什么是回归呢? 回归分析是一种预测性的建模技术, ...
- 在实际项目中,如何选择合适的机器学习模型?
https://blog.csdn.net/gitchat/article/details/78913235 本文来自作者 chen_h 在 GitChat 上分享 「在实际项目中,如何选择合适的机器 ...
最新文章
- 创建分区表+分区表的分类+创建散列分区表+查看散列分区表分区中的数据+创建列表分区表+查看列表分区表分区中的数据...
- 【NOI2013】向量内积
- Stackoverflow的见解:投票最多的是Spring 4问题
- 【大总结1】数据结构与传统算法总结
- BugkuCTF-MISC题zip伪加密
- Linux 7 关闭、禁用防火墙服务
- list control 应用(转载)
- HTML5 Audio标签API整理(一)
- python queue 生产者 消费者_生产者、消费者模型---Queue类
- 【每日算法Day 67】经典面试题:手动开根号,你知道几种方法?
- mysql的执行局计划
- 交换机VLAN工作模式介绍
- dns服务器对网速有影响吗,更换DNS服务器可以提高网速吗?
- 解读SOA平台---概念分析
- 最新淘汰服务器cpu,2019 最新 至强 Xeon E3服务器系列 CPU天梯图
- 爱企查与天眼查也来啦~
- nios ii小实验——SDRAM读写
- JAVA前端修改密码,Java Web版SVN 配置管理工具 2.0 (远道建立仓库,修改密码,设置权限,支持apache等)...
- JSP项目常见问题解决方案
- 计算机网络技术的研究现状,计算机网络技术发展研究