Redis 和 I/O 多路复用
最近在看 UNIX 网络编程并研究了一下 Redis 的实现,感觉 Redis 的源代码十分适合阅读和分析,其中 I/O 多路复用(mutiplexing)部分的实现非常干净和优雅,在这里想对这部分的内容进行简单的整理。
几种 I/O 模型
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
Blocking I/O
先来看一下传统的阻塞 I/O 模型到底是如何工作的:当使用 read 或者 write 对某一个文件描述符(File Descriptor 以下简称 FD)进行读写时,如果当前 FD 不可读或不可写,整个 Redis 服务就不会对其它的操作作出响应,导致整个服务不可用。
这也就是传统意义上的,也就是我们在编程中使用最多的阻塞模型:

阻塞模型虽然开发中非常常见也非常易于理解,但是由于它会影响其他 FD 对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型。
I/O 多路复用
虽然还有很多其它的 I/O 模型,但是在这里都不会具体介绍。
阻塞式的 I/O 模型并不能满足这里的需求,我们需要一种效率更高的 I/O 模型来支撑 Redis 的多个客户(redis-cli),这里涉及的就是 I/O 多路复用模型了:
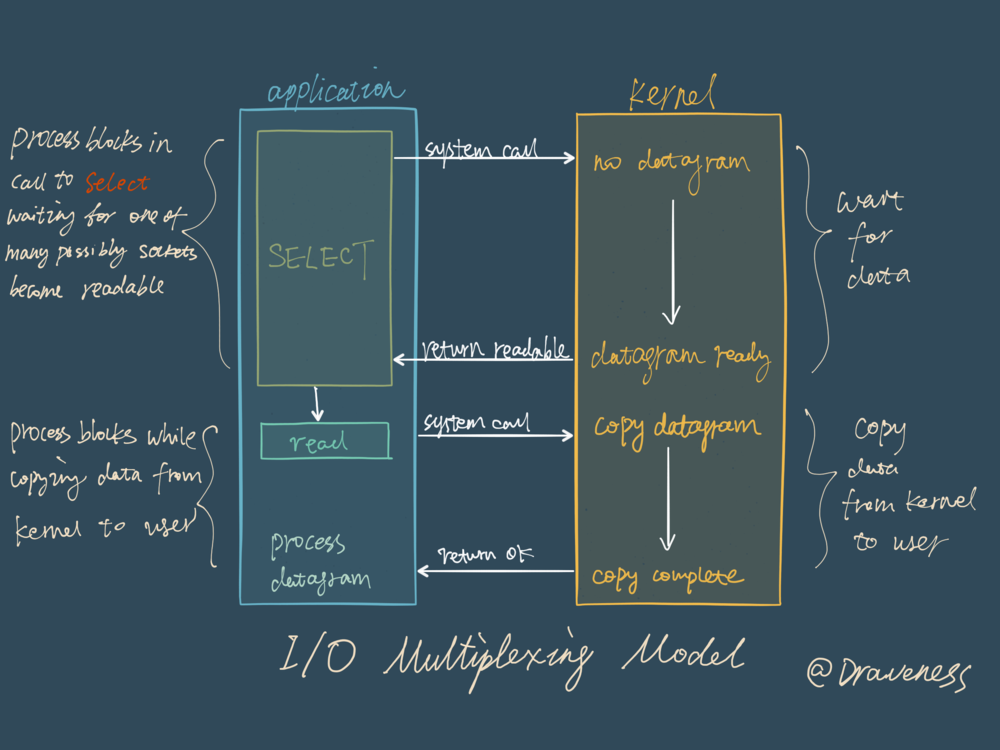
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
关于
select的具体使用方法,在网络上资料很多,这里就不过多展开介绍了;与此同时也有其它的 I/O 多路复用函数
epoll/kqueue/evport,它们相比select性能更优秀,同时也能支撑更多的服务。
Reactor 设计模式
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
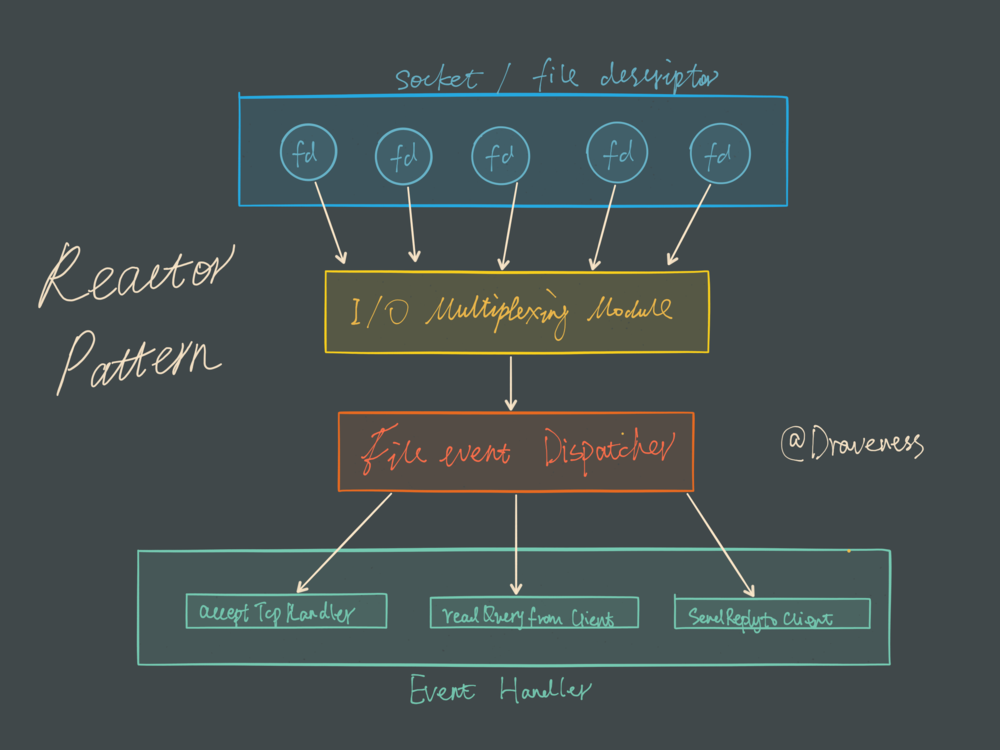
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口。
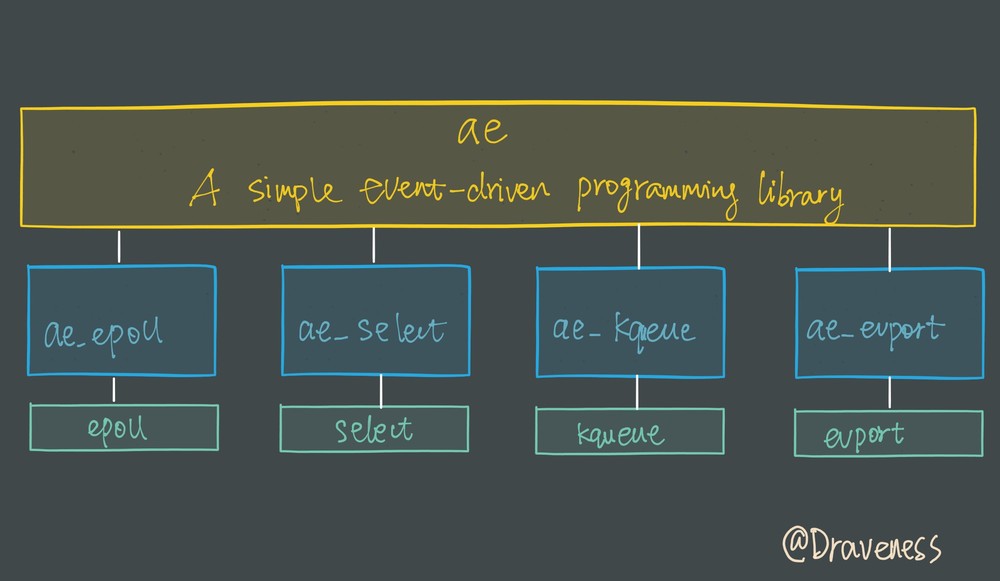
在这里我们简单介绍 Redis 是如何包装 select 和 epoll 的,简要了解该模块的功能,整个 I/O 多路复用模块抹平了不同平台上 I/O 多路复用函数的差异性,提供了相同的接口:
static int aeApiCreate(aeEventLoop *eventLoop)static int aeApiResize(aeEventLoop *eventLoop, int setsize)static void aeApiFree(aeEventLoop *eventLoop)static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
同时,因为各个函数所需要的参数不同,我们在每一个子模块内部通过一个 aeApiState 来存储需要的上下文信息:
// select
typedef struct aeApiState {fd_set rfds, wfds;fd_set _rfds, _wfds;
} aeApiState;// epoll
typedef struct aeApiState {int epfd;struct epoll_event *events;
} aeApiState;这些上下文信息会存储在 eventLoop 的 void *state 中,不会暴露到上层,只在当前子模块中使用。
封装 select 函数
select可以监控 FD 的可读、可写以及出现错误的情况。
在介绍 I/O 多路复用模块如何对 select 函数封装之前,先来看一下 select 函数使用的大致流程:
int fd = /* file descriptor */fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds)for ( ; ; ) {select(fd+1, &rfds, NULL, NULL, NULL);if (FD_ISSET(fd, &rfds)) {/* file descriptor `fd` becomes readable */}
}- 初始化一个可读的
fd_set集合,保存需要监控可读性的 FD; - 使用
FD_SET将fd加入rfds; - 调用
select方法监控rfds中的 FD 是否可读; - 当
select返回时,检查 FD 的状态并完成对应的操作。
而在 Redis 的 ae_select 文件中代码的组织顺序也是差不多的,首先在 aeApiCreate 函数中初始化 rfds 和 wfds:
static int aeApiCreate(aeEventLoop *eventLoop) {aeApiState *state = zmalloc(sizeof(aeApiState));if (!state) return -1;FD_ZERO(&state->rfds);FD_ZERO(&state->wfds);eventLoop->apidata = state;return 0;
}而 aeApiAddEvent 和 aeApiDelEvent 会通过 FD_SET 和 FD_CLR 修改 fd_set 中对应 FD 的标志位:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {aeApiState *state = eventLoop->apidata;if (mask & AE_READABLE) FD_SET(fd,&state->rfds);if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds);return 0;
}整个 ae_select 子模块中最重要的函数就是 aeApiPoll,它是实际调用 select 函数的部分,其作用就是在 I/O 多路复用函数返回时,将对应的 FD 加入 aeEventLoop 的 fired 数组中,并返回事件的个数:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {aeApiState *state = eventLoop->apidata;int retval, j, numevents = 0;memcpy(&state->_rfds,&state->rfds,sizeof(fd_set));memcpy(&state->_wfds,&state->wfds,sizeof(fd_set));retval = select(eventLoop->maxfd+1,&state->_rfds,&state->_wfds,NULL,tvp);if (retval > 0) {for (j = 0; j <= eventLoop->maxfd; j++) {int mask = 0;aeFileEvent *fe = &eventLoop->events[j];if (fe->mask == AE_NONE) continue;if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds))mask |= AE_READABLE;if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds))mask |= AE_WRITABLE;eventLoop->fired[numevents].fd = j;eventLoop->fired[numevents].mask = mask;numevents++;}}return numevents;
}封装 epoll 函数
Redis 对 epoll 的封装其实也是类似的,使用 epoll_create 创建 epoll 中使用的 epfd:
static int aeApiCreate(aeEventLoop *eventLoop) {aeApiState *state = zmalloc(sizeof(aeApiState));if (!state) return -1;state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);if (!state->events) {zfree(state);return -1;}state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */if (state->epfd == -1) {zfree(state->events);zfree(state);return -1;}eventLoop->apidata = state;return 0;
}在 aeApiAddEvent 中使用 epoll_ctl 向 epfd 中添加需要监控的 FD 以及监听的事件:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {aeApiState *state = eventLoop->apidata;struct epoll_event ee = {0}; /* avoid valgrind warning *//* If the fd was already monitored for some event, we need a MOD* operation. Otherwise we need an ADD operation. */int op = eventLoop->events[fd].mask == AE_NONE ?EPOLL_CTL_ADD : EPOLL_CTL_MOD;ee.events = 0;mask |= eventLoop->events[fd].mask; /* Merge old events */if (mask & AE_READABLE) ee.events |= EPOLLIN;if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;ee.data.fd = fd;if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;return 0;
}由于 epoll 相比 select 机制略有不同,在 epoll_wait 函数返回时并不需要遍历所有的 FD 查看读写情况;在 epoll_wait 函数返回时会提供一个 epoll_event 数组:
typedef union epoll_data {void *ptr;int fd; /* 文件描述符 */uint32_t u32;uint64_t u64;
} epoll_data_t;struct epoll_event {uint32_t events; /* Epoll 事件 */epoll_data_t data;
};其中保存了发生的
epoll事件(EPOLLIN、EPOLLOUT、EPOLLERR和EPOLLHUP)以及发生该事件的 FD。
aeApiPoll 函数只需要将 epoll_event 数组中存储的信息加入 eventLoop 的 fired 数组中,将信息传递给上层模块:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {aeApiState *state = eventLoop->apidata;int retval, numevents = 0;retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);if (retval > 0) {int j;numevents = retval;for (j = 0; j < numevents; j++) {int mask = 0;struct epoll_event *e = state->events+j;if (e->events & EPOLLIN) mask |= AE_READABLE;if (e->events & EPOLLOUT) mask |= AE_WRITABLE;if (e->events & EPOLLERR) mask |= AE_WRITABLE;if (e->events & EPOLLHUP) mask |= AE_WRITABLE;eventLoop->fired[j].fd = e->data.fd;eventLoop->fired[j].mask = mask;}}return numevents;
}子模块的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块:
#ifdef HAVE_EVPORT #include "ae_evport.c" #else#ifdef HAVE_EPOLL#include "ae_epoll.c"#else#ifdef HAVE_KQUEUE#include "ae_kqueue.c"#else#include "ae_select.c"#endif#endif #endif
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
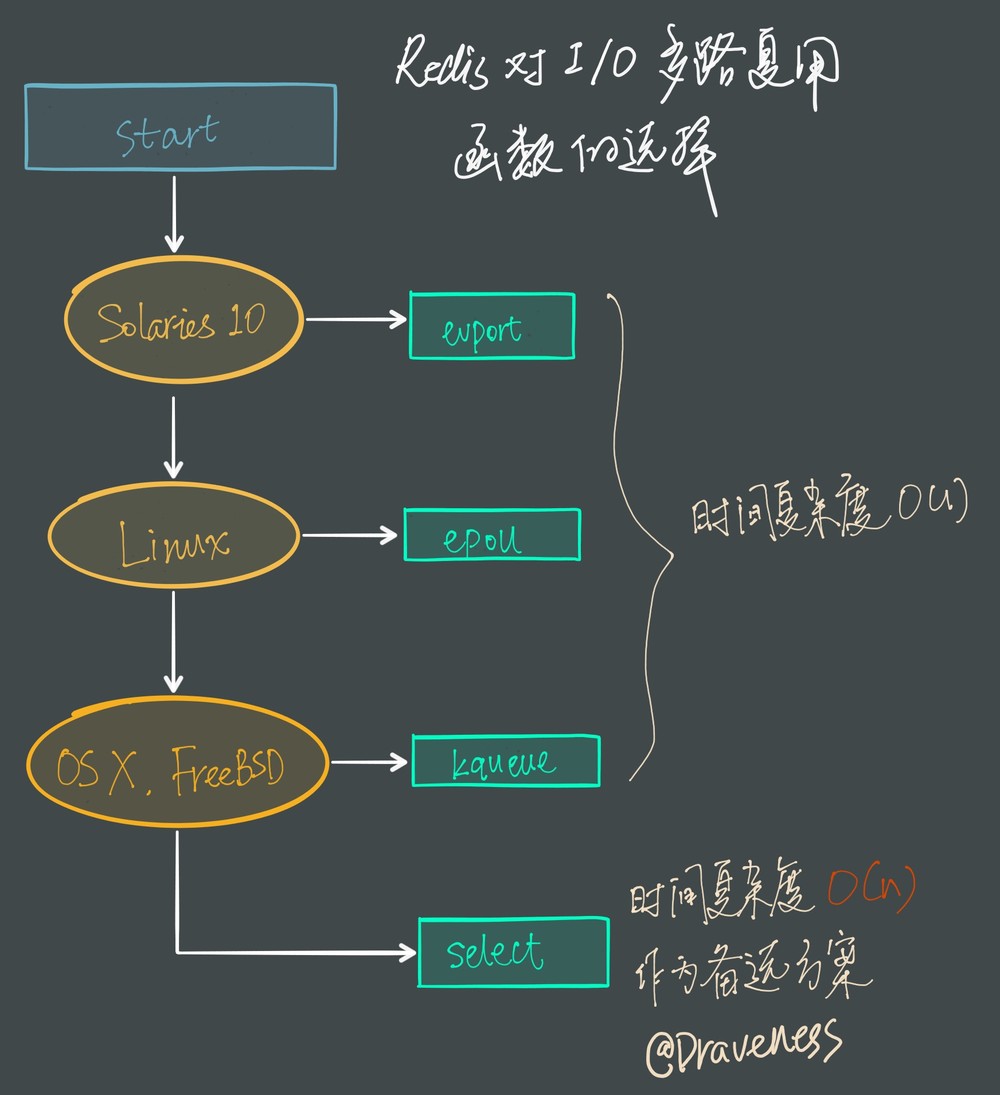
Redis 会优先选择时间复杂度为 $O(1)$ 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 $O(n)$,并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
总结
Redis 对于 I/O 多路复用模块的设计非常简洁,通过宏保证了 I/O 多路复用模块在不同平台上都有着优异的性能,将不同的 I/O 多路复用函数封装成相同的 API 提供给上层使用。
整个模块使 Redis 能以单进程运行的同时服务成千上万个文件描述符,避免了由于多进程应用的引入导致代码实现复杂度的提升,减少了出错的可能性。
Reference
- Select-Man-Pages
- Reactor-Pattern
- epoll vs kqueue
https://draveness.me/redis-io-multiplexing
Redis 和 I/O 多路复用相关推荐
- 面试官:说说Redis之I/O多路复用模型实现原理
你知道的越多,不知道的就越多,业余的像一棵小草! 成功路上并不拥挤,因为坚持的人不多. 编辑:业余草 blog.csdn.net/Seky_fei 推荐:https://www.xttblog.com ...
- redis的多路复用是什么鬼
有没有人和我一样, 自打知道了redis, 就一直听说什么redis单线程, 使用了多路复用等等. 天真的我以为多路复用是redis实现的技术. 今天才发现, 我被自己骗了, 多路复用是系统来实现的. ...
- 为什么单线程的Redis却能支撑高并发? ---------- I/O 多路复用
几种 I/O 模型 为什么 Redis 中要使用 I/O 多路复用这种技术呢?首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的. 但是由于读写操作等待用户输入或输出都是阻塞的,所以 ...
- redis的多路复用原理
redis服务端对于命令的处理是单线程的,但是在I/O层面却可以同时面对多个客户端并发的提供服务,并发到内部单线程的转化通过多路复用框架实现 一个IO操作的完整流程是数据请求先从用户态到内核态,也就是 ...
- Redis IO多路复用理解
IO多路复用在Redis中的应用 Redis 服务器是一个事件驱动程序, 服务器处理的事件分为时间事件和文件事件两类. 文件事件:Redis主进程中,主要处理客户端的连接请求与相应. 时间事件:for ...
- 面霸:Redis 为什么这么快?
以下文章来源方志朋的博客,回复"666"获面试宝典 Redis 为什么这么快? 很多人只知道是 K/V NoSQl 内存数据库,单线程--这都是没有全面理解 Redis 导致无法继 ...
- 高并发存储番外篇:Redis套路,一网打尽
本文内容提要 Redis为什么这么快 1.1. 数据结构SDS的妙用 1.2. 性能优良的事件模型驱动 1.3. 基于内存的操作 Redis为什么这么靠谱 2.1. AOF持久化 2.2. RDB持久 ...
- Redis 核心篇:唯快不破的秘密
" 天下武功,无坚不摧,唯快不破! " 学习一个技术,通常只接触了零散的技术点,没有在脑海里建立一个完整的知识框架和架构体系,没有系统观.这样会很吃力,而且会出现一看好像自己会,过 ...
- 为什么Redis要比Memcached更火?
作者:Kaito 链接:kaito-kidd.com/2020/06/28/redis-vs-memcached/ 前言 我们都知道,Redis和Memcached都是内存数据库,它们的访问速度非常之 ...
最新文章
- 【ACM】CODE[VS] 2806(DFS)
- WPF学习笔记——设置ListBox选中项的背景颜色
- Agile Use Cases in Four Steps
- 移动前端的一些必备知识
- halcon算子翻译——deserialize_measure
- android 多线程编程
- 赵栋 201771010137 《面向对象程序设计(java)》第二周学习总结
- 【解决】联想拯救者/MT7921网卡 ubuntu里 wifi/蓝牙 无法识别连接
- HAA2018A_音频功放规格书_V1.2
- 计算机博士美国高校雅思要求,雅思8分成功申堪萨斯大学博士(助研全奖)
- 2021有什么好的入耳式耳机推荐?耳机热销性价比牌子排行榜单推荐!
- 视频教程-excel提高效率的实用技巧-Office/WPS
- 如何设计游戏中的道具功能(二)
- [英语竞赛] 知识整理
- 采用Java编写一个软件,100以内的口算题,加减运算,运算结果位于[0,100]区间内,要求自动生成题库,实现自动判分,自动生成成绩,并且有图形化CUI界面
- Java泛型的重要目的:别让猫别站在狗队里
- Chrome浏览器如何设置中文翻译
- flask 发送新浪邮箱邮件
- word转换成excel导致身份证错乱的解决办法
- 《洋妞》万像电影节揽四奖 或打造同名综艺节目