hadoop Federation搭建
组网说明:
hadoop1.localdomain 192.168.11.81(namenode)
hadoop2.localdomain 192.168.11.82(namenode)
hadoop3.localdomain 192.168.11.83(datanode)
hadoop4.localdomain 192.168.11.84(datanode)
hadoop5.localdomain 192.168.11.85(datanode)
第一步:卸载openjdk
rpm -qa |grep java
#查看已经安装的与java相关的包
rpm -e java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e tzdata-java-2013g-1.el6.noarch
#################################################################
第二步:禁用IPV6
echo net.ipv6.conf.all.disable_ipv6=1 >>/etc/sysctl.conf
echo "alias net-pf-10 off" >>/etc/modprobe.d/dist.conf
echo "alias ipv6 off" >>/etc/modprobe.d/dist.conf
reboot
##########################################################
第三步:解压hadoop压缩包
把压缩包导入到/usr目录
cd /usr
tar -zxvf hadoop--642.4.0.tar.gz
把目录重命名为hadoop
mv hadoop--642.4.0 hadoop
安装jdk1.7,把安装包导入到/usr目录
cd /usr
rpm -ivh jdk-7u71-linux-x64.rpm
####################################################################
第四步:设置JAVA&HADOOP环境变量
vi /etc/profile
#set java environment
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export HADOOP_PREFIX=/usr/hadoop/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#set hadoop environment
export HADOOP_HOME=/usr/hadoop/
export PATH=$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin/
#使配置生效
source /etc/profile
或者重启服务器,也会重新加载该配置
################################################
第五步:创建hdfs需要的目录
mkdir -p /home/hadoop/dfs/name
mkdir -p /home/hadoop/dfs/data
##############################
第六步:java enviromnet追加到hadoop环境变量配置文件中
echo export JAVA_HOME=/usr/java/jdk1.7.0_71/ >>/usr/hadoop/etc/hadoop/hadoop-env.sh
echo export JAVA_HOME=/usr/java/jdk1.7.0_71/ >>/usr/hadoop/etc/hadoop/yarn-env.sh
####################################################################################
第七步:免ssh key,可以只在namenode上,因为一般情况下,由namenode控制datanode
略,查看相关配置手册
####################
第八步:编辑datanode配置文件,只在namenode上
[root@hadoop1 hadoop]# pwd
/usr/hadoop/etc/hadoop
[root@hadoop1 hadoop]# more slaves
hadoop3.localdomain
hadoop4.localdomain
hadoop5.localdomain
########################################
[root@hadoop1 hadoop]# more core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1.localdomain:8020</value>
</property>
#
# <property>
# <name>fs.defaultFS</name>
# <value>viewfs://nsX</value>
# </property>
#
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
###########################################
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
###############################
<property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hadoop1.localdomain:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>hadoop1.localdomain:50070</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>hadoop1.localdomain:50080</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hadoop2.localdomain:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>hadoop2.localdomain:50070</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>hadoop2.localdomain:50080</value>
</property>
#################################
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1.localdomain:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1.localdomain:19888</value>
</property>
###########################
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1.localdomain:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1.localdomain:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1.localdomain:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1.localdomain:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1.localdomain:8088</value>
</property>
#############################
1、在hadoop1上,把hadoop所在文件夹拷贝到其他节点上,不用更改配置
scp /usr/hadoop hadoop2:/usr/
scp /usr/hadoop hadoop3:/usr/
scp /usr/hadoop hadoop4:/usr/
scp /usr/hadoop hadoop5:/usr/
2、格式化namenode,两个namenode都要格式化,切clusterid
hdfs namenode -format -clusterId MyHadoopCluster
MyHadoopCluster是以字符串的形式
3、每次格式化namenode之前,要删除缓存
rm -rf /home/hadoop/dfs/data/*
rm -rf /home/hadoop/dfs/name/*
4、
开启
start-all.sh
关闭
stop-all.sh
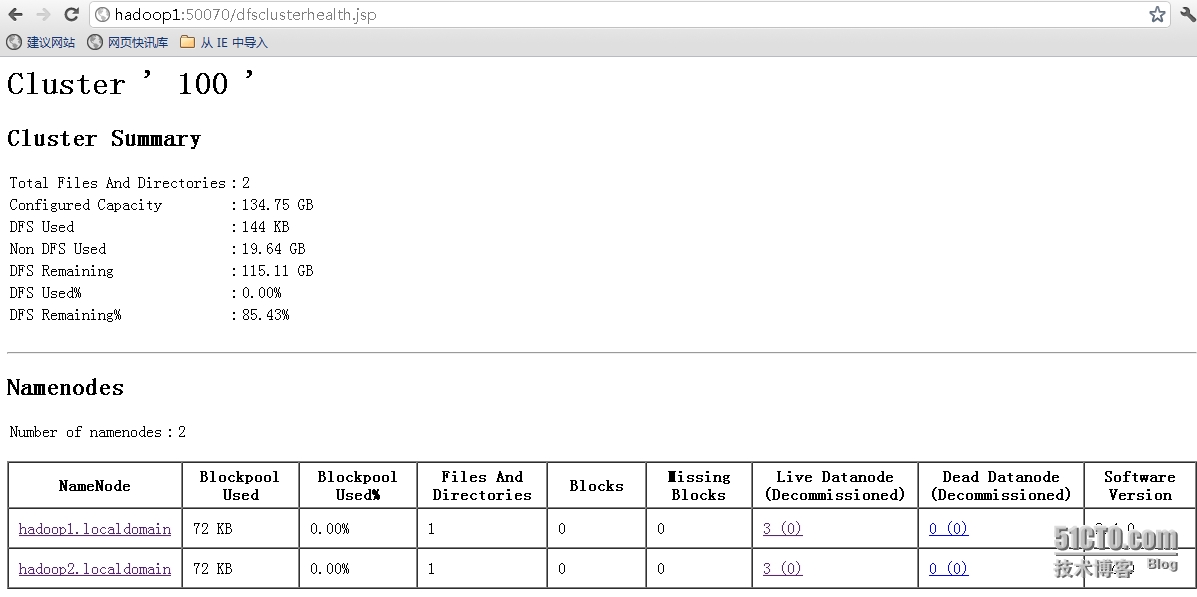
访问方式:
http://hadoop1.localdomain:50070/dfsclusterhealth.jsp
http://hadoop1.localdomain:50070/dfshealth.jsp
http://hadoop1.localdomain:50070/dfshealth.html#tab-overview
http://hadoop1.localdomain:8088/cluster/nodes
参考阅读:
http://hadoop.apache.org/docs/r2.2.0/hadoop-project-dist/hadoop-hdfs/Federation.html
http://zh.hortonworks.com/blog/an-introduction-to-hdfs-federation/
转载于:https://blog.51cto.com/zqxiang/1589556
hadoop Federation搭建相关推荐
- GitChat·大数据 | 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文: 史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末彩蛋] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- 转 史上最详细的Hadoop环境搭建
转载的文章,请告知侵删.本人只是做个记录,一面以后找不到. 前言 Hadoop在大数据技术体系中的地位至关重要,Hadoop是大数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在大数据技 ...
- hadoop分布式搭建
hadoop分布式搭建 一.首先是搞好master 1.创建用户组 groupadd hadoop 添加一个组 useradd hadoop -g hadoop 添加用户 2.jdk的安装 这里安 ...
- Hadoop环境搭建教学(二)完全分布式集群搭建;
Hadoop环境搭建教学(一)运行环境,集群规划介绍: 文章目录 安装三台 CentOS 7系统 一.X-Shell的准备工作 二.基本工具安装 三.关闭防火墙 四.修改Host文件 五.3.4.4 ...
- Hadoop环境搭建教学(一)运行环境,集群规划介绍;
文章目录 前言 一.Hadoop的三种运行环境 二.集群规划 三.需要的基本软件安装 下期见 前言 Hadoop的运行环境可以是在Windows上,也可以在linux上,但在Windows上运行效率很 ...
- Hadoop环境搭建(二)CentOS7的下载与安装
Hadoop环境搭建(一) VMware Workstation安装 与 网络配置 1. CentOS7的下载 https://wiki.centos.org/Download 2. CentOS7安 ...
- Hadoop的搭建,VmwareWorkstation 16pro + Ubuntu18.04.1
文章目录 前言 一.VmwareWorkstation 16pro安装Ubuntu18.04.1 二.Ubuntu的基础配置 1.设置国内镜像源 2.下载安装Vmware Tools 三.安装Hado ...
- hadoop window 搭建
hadoop 原理参考:用 Hadoop 进行分布式并行编程 官方中文文档:http://hadoop.apache.org/core/docs/r0.18.2/cn/index.html 1. 首先 ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 状况,我们知道这是一个以店铺为维度的切分,非常适合目前的在 ...
最新文章
- python写文件读文件-Python 实例:读写文件
- 2016年 第7届 蓝桥杯 Java B组 省赛解析及总结
- Sql日期时间格式转换
- 基于Xml 的IOC 容器-载入<property>的子元素
- C++:16---强制类型转换和类型转换
- 32 MM配置-采购-采购订单-定义编码范围
- block创建时出现Typedef redefinition with different types错误
- 刨根问底(二):从INode客户端看如何培养兴趣 (续)
- 算法: 唯一路径62. Unique Paths
- 1024献礼,全栈工程师进击
- 小葵花妈妈课堂开课了:《Runnable、Callable、Future、RunnableFuture、FutureTask 源码分析》
- Pandas中常见的20多种数据筛选方法,116张图详解 | 图解Pandas-图文第8篇
- 在Oracle中,如何定时清理INACTIVE状态的会话?
- SCSS 中这些实用技巧,你可能还不知道!
- 网络流(最大流和最小费用流)
- 信息检索中的度量precison@k,recall@k,f1@k,MRR,ap,map,CG, DCG,NDCG
- m3u8手机批量转码_python+ffmpeg,批量转换手机中的m3u8文件
- 使用AForge设置摄像头参数
- mysql汉字一二三四排序_文件夹名称有汉字一二三四五等,如何按数字大小顺序排列?...
- Android安装更新 apk,适用于android6.0及以上安卓版本。