【产品环境】使用ELK搭建日志系统
为什么80%的码农都做不了架构师?>>> 
随着业务不断完善与发展,日志的重要性稳步上升。我们需要从日志中排查错误,以及分析用户行为,为业务发展提供参考意见。因此,需要一套专门的日志系统帮助我们收集、分析、处理日志。
以前我曾经写过一个logstash的blog: http://my.oschina.net/abcfy2/blog/372138 ,版本比较低,但是logstash的配置没变过。此篇blog将比上述blog更详尽一些,扩展到产品环境搭建完整的日志系统,但是logstash本身的配置不多做介绍,因为旧Blog已经介绍的比较详细了。
本篇Blog主要介绍我们目前使用的日志系统的总体架构和部分配置。Kibana的使用暂时不在本篇Blog的覆盖范围之内,以后也许会单独写一篇kibana的使用,读者也可以参考饶琛琳的《ELK stack权威指南》一书的相关章节。
本篇Blog的内容也并非自己独自完成,关于log4j 1.2部分的配置和使用是开发同事共同探究实现的。
最后要说的一点是,日志系统的实现并不只是运维的工作,开发也需要配合,规范日志格式,规范项目埋点,便于排查问题。最后归结与一点,要有执行力,要有人推动,不能随随便便的打日志,更不允许产品环境有乱七八糟的println这种调试方式的日志输出。
关于ELK
ELK Stack指代三个独立的组件: Elasticsearch,Logstash,Kibana。这三个独立的组件组合使用,可以形成一套完整的日志解决方案。目前这三个产品先后归于Elastic.co公司旗下,该公司围绕Elasticsearch这个核心产品逐步打造一整套生态环境,使得ELK Stack这套架构日益成熟,而且周边也逐步开始完善。
其中,Logstash的作用是处理日志,将日志解析为JSON格式进行传递。Elasticsearch的作用是数据库,将最终解析的结果存库,用于日后查询与分析使用。Kibana是Elasticsearch的dashboard,用于图形化展示elasticsearch数据库的查询结果。这三个组件搭配使用,将十分灵活,有以下几个优点(以下内容节选自饶琛琳的《ELK stack权威指南》一书,感谢作者的努力):
- 处理方式灵活。Elasticsearch是实时全文索引,不需要像Storm那样预先编程才能使用。
- 配置简易上手。Elasticsearch全部采用JSON接口,Logstash是Ruby DSL设计,都是目前业界最通用的配置语法设计。
- 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到百亿级数据查询的秒级响应。
- 集群线性扩展。不管是Elasticsearch集群还是Logstash集群都是可以线性扩展的。
- 前端操作炫丽。Kibana界面上,只需点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表盘。
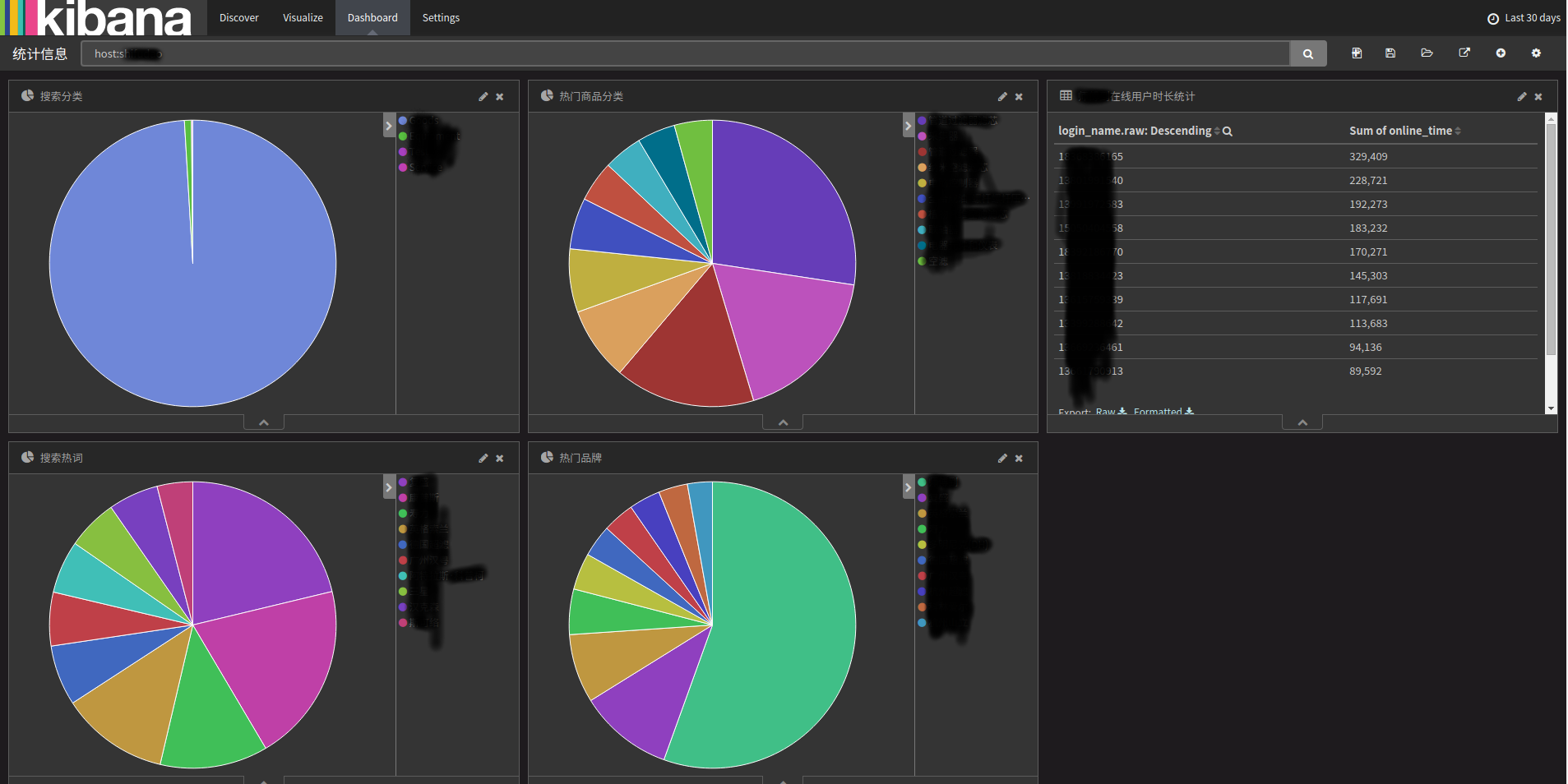
Kibana的可视化效果:
Logstash的处理流程
其中,ELK的灵活性得益于Logstash的插件式设计,而且插件之间都是松耦合(通过JSON事件交互,接口统一)。数据流在Logstash会经过三个阶段: Input -> Filter -> Output,而且Filter可以无限制串联,形成流式处理,甚至可以干脆没有。这三个阶段既可以在单节点上完成,也可以直接Output到其他节点上,分布处理与卸载压力。整个Logstash的基本流程图如下:

Logstash的数据处理过程描述如下:
- 进入Logstash的数据流,会被解析成一条一条的JSON记录。每一条JSON在Logstash中称为一个事件(event)。
- Logstash对每条事件记录可以使用
Filter进行处理,如筛选,简单聚合(如Multiline插件将多行JAVA堆栈异常聚合为一个事件),编解码(如将unix时间戳转为时间字符串,将k1=v1,k2=v2这种kv格式解析为{k1:v1, k2:v2}这种JSON格式,正则解析文本日志等),执行Ruby代码等等,并且Filter可以无限制串联。此过程可直接跳过,即不对事件做任何处理。 - 通过Output插件,将解析处理过的数据输出到指定目标,如RDB,TCP/UDP端口,Elasticsearch,消息队列,文件等等,只要有对应插件的支持,就可以输出到对应的目标中。
整个Logstash的ruby DSL配置语法看起来像这样:
input {插件名1 {# 插件相关配置属性}插件名2 {# 插件相关配置属性}... SNIP ...插件名3 {# 插件相关配置属性}
}filter {插件名1 {# 插件相关配置属性}插件名2 {# 插件相关配置属性}... SNIP ...插件名3 {# 插件相关配置属性}
}output {插件名1 {# 插件相关配置属性}插件名2 {# 插件相关配置属性}... SNIP ...插件名3 {# 插件相关配置属性}
}
举个例子,比如存储于日志文件中的某http access log日志:
55.3.244.1 GET /index.html 15824 0.043
经过了Logstash的inputs-file插件,输入成为Logstash的一个事件,在Logstash会变成这样(以rubydebug格式显示):
{"message" => "55.3.244.1 GET /index.html 15824 0.043","@version" => "1","@timestamp" => "2016-03-01T03:37:33.081Z","host" => "fengyu-Vostro-3900"
}
日志本身内容会存放在message这个field中,除此之外还会加上一些元数据,如host,@timestamp等。
加上filters-grok这个Filter进行正则解析处理,解析message这个field(详细配置参考filters-grok的文档),最终将该事件解析成如下的事件:
{"message" => "55.3.244.1 GET /index.html 15824 0.043","@version" => "1","@timestamp" => "2016-03-01T03:51:03.914Z","host" => "fengyu-Vostro-3900","client" => "55.3.244.1","method" => "GET","request" => "/index.html","bytes" => "15824","duration" => "0.043"
}
最后,通过outputs-elasticsearch这个output插件,将解析过的日志推送至Elasticsearch数据库中存储。
通过elasticsearch中的各种查询方式,即可按照自己的需求展示这些数据了。
Logstash的这种设计,可以很容易进行线性扩展,比如不做filter处理,直接output到其他logstash实例的input端,将处理分散在不同的节点上。最极端的情况,甚至可以扩展成这个架构,兼顾HA(High Availability)与HP(High Performance):

三个logstash实例互为冗余,将解析的结果推送至消息队列,由另一个logstash实例将日志从消息队列取出,推送至elasticsearch集群中。
架构设计
整个日志数据流的模型图:
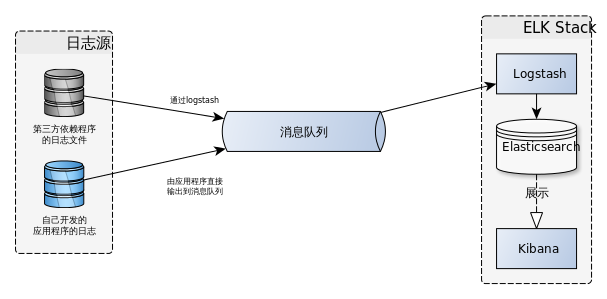
每台服务器上部署有我们自己开发的应用程序,以及这些应用程序的第三方依赖服务项(如数据库,web服务器等)。
因此日志源主要有两种: 自己开发的应用程序的日志,依赖的第三方软件的日志。
我们自己开发的程序,直接将日志以JSON格式写入消息队列中。第三方服务大部分无法直接将日志写入消息队列中,而是输出为日志文件,这种日志源通过logstash的filters-grok插件,解析日志文件后推送至消息队列中。
需要收集的第三方依赖的日志,以及收集哪些日志,详见文档末的附录。
消息队列使用kafka + zookeeper的方式实现。日志专用的消息队列部署在日志服务器中。
注: 如果日志量比较小的话,可以没必要这么复杂,比如省略掉
kafka这个消息队列,日志服务器也无需部署logstash,直接在应用服务器上用logstash将解析过的log推送至日志服务器上的es数据库中。
安全问题:
所有服务尽可能只对内网ip暴露(通过防火墙实现),减少对外暴露的服务,并且以低权限账户运行。跨节点的服务(如mongodb复制集,kafka+zookeeper,postgresql集群等)连接一律采用SSL双向认证的方案,提高安全性。
详细配置参考文档末附录的内容。
解决方案
根据上述描述,我们需要搭建一台日志服务器,安装ELK与日志专用的消息队列。
应用程序产生的日志直接推送至日志服务器的消息队列中,经过logstash的处理最终推送至elasticsearch中,在kibana上进行展示。
可以在logstash的Filter上定义报警规则,当日志有严重的错误时Output邮件报警。
部署方案
服务器上应用程序列表如图所示:
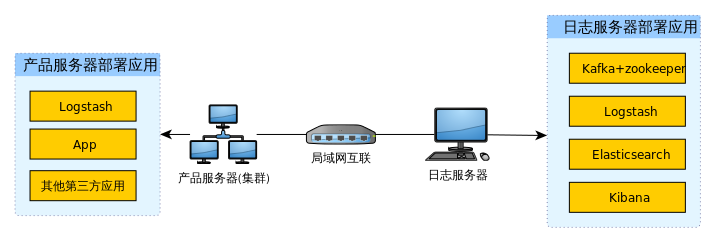
多台产品服务器上,每台服务器分别部署有应用程序和logstash,其他第三方服务按照需要组成集群(如postgresql集群,mongodb复制集等)。日志服务器上部署完整的ELK Stack和Kafka+Zookeeper。
- 日志信息由应用程序生成时,直接写入日志服务器的kafka队列中。相关规范与配置参考文档末的附录内容。
- 由第三方依赖程序产生的log,通常以文件形式存储在产品服务器上。通过产品服务器的logstash解析日志文件后,推送至日志服务器的kafka。需要收集的日志列表参考文档末的附录。
- 日志统一输出到
logs这个TOPIC中。 - 日志服务器的logstash负责从日志服务器的kafka队列中取出日志信息,推送至elasticsearch储存,同时做报警规则,遇到需要报警的日志通过邮件方式报警。kibana作为elasticsearch的dashboard使用,对es数据库存储的内容进行可视化展示。
扩展问题
此架构在扩展上将即为便利,共有三个可扩展的点:
- 通过消息队列将外部依赖解耦,使得横向扩展很容易,如果日志解析负载较高,可以利用消息队列,在别的节点上进行解析后推送至es数据库。甚至借助于Hadoop,Spark这样的大数据处理引擎去解析。
- 如果存储容量成为一个问题,可以选择hdfs,ceph这种分布式存储解决方案,分散数据存储容量,也可以使用增加elasticsearch分片节点解决这个问题。
- 如果elasticsearch存储效率成为了瓶颈,可以选择增加elasticsearch分片集群节点解决这个问题。
这些扩展方案均可在无需原程序改动的条件下进行扩展。
部署步骤
单节点部署
推荐使用elastic.co的仓库(RHEL/CentOS和Ubuntu/Debian仓库为官方维护):
- Elasticsearch地址: https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-repositories.html
- Logstash地址: https://www.elastic.co/guide/en/logstash/current/package-repositories.html
- Kibana地址: https://www.elastic.co/guide/en/logstash/current/package-repositories.html
推荐使用清华大学镜像仓库,我的issue已经被tuna接受,国内安装速度会快许多(官方仓库在S3上,所以你懂的)。tuna镜像地址: http://mirrors.tuna.tsinghua.edu.cn/ELK/
按照官方文档的步骤,安装之后根据需要定制配置,启动服务,启用开机自启动即可。
包管理器安装的logstash,启动配置存放于/etc/logstash/conf.d/,这个目录一开始是空的,自己将logstash的配置文件以.conf结尾扔到这个目录后,即可使用service logstash start启动服务,日志存放于/var/log/logstash/。logstash的配置文件可以拆分成多个.conf文件,以规范配置,比如input.conf,filter.conf,output.conf。
特别注意: logstash可以在一个目录下存放多个
.conf文件,logstash内部会将多个.conf文件合并为一个大的配置文件,合并的顺序为文件名顺序。所以特别注意你的filter配置,如果多个配置文件都有filter配置,特别注意filter的加载次序!否则会搞乱你的配置。如果你的filter只针对某个应用的日志使用,那么推荐你使用if [type] == "appname" { filter配置 }这种方式限制住你的filter的作用范围。
批量部署
我用的是salt,产品环境Ubuntu Server 14.04 LTS,当然你也可以使用其他类似的工具,如puppet,chef,ansible等等。
salt的logstash这个state的目录结构如下:
$ tree /srv/salt/logstash/
/srv/salt/logstash/
├── config
│ ├── logagent
│ │ ├── 00_log4j.conf
│ │ ├── 01_vertx.conf
│ │ ├── 02_mongod.conf
│ │ ├── 03_postgresql.conf
│ │ ├── 04_nginx.conf
│ │ └── 99_output.conf
│ └── logserver
│ └── logserver.conf
└── init.sls
$ cat /srv/salt/logstash/init.sls
logstash_repo:pkgrepo.managed:- name: deb http://mirrors.tuna.tsinghua.edu.cn/ELK/apt/logstash/2.3/ stable main- file: /etc/apt/sources.list.d/logstash.list- key_url: https://packages.elastic.co/GPG-KEY-elasticsearch- clean_file: Truelogstash:pkg.latest:- require:- pkgrepo: logstash_repologstash_grains:grains.list_present:- name: roles- value: logstashlogstash-config:file.recurse:- name: /etc/logstash/conf.d{% if 'logserver' in grains.get('roles', '') %}- source: salt://logstash/config/logserver/{% else %}- source: salt://logstash/config/logagent/{% endif %}- clean: True- makedirs: True- template: jinja{% if 'postgresql' in grains.get('roles', '') %}
logstash-user:group.present:- name: adm- addusers: - "logstash"
{% endif %}logstash-service:service.running:- name: logstash- enable: True- watch:- pkg: logstash- file: logstash-config
最终推送到/etc/logstash/conf.d/目录下的文件为00_log4j.conf,01_vertx.conf,02_mongod.conf,03_postgresql.conf,04_nginx.conf,99_output.conf,这样命名是为了按照自己预期的文件顺序叠加input,filter,output配置,而不会造成混乱。有关00_log4j.conf的配置内容参考博客开头提供的旧的blog,这里基本没大改过。
测试用例
为了演示这套架构的流程与效果,所以将这套架构最小化,将产品服务器的应用与日志服务器的应用全部部署在一个节点上测试。
日志文件数据源以Nginx的access log为例,使用logstash将nginx access log中的内容推送至kafka队列中,另一个logstash实例从kafka将nginx的log取出存入elasticsearch中。
自己开发的应用程序直接按照上述日志规范打印日志进入kafka,由logstash从kafka中取出应用程序的日志,推送至elasticsearch中。
日志文件用例
修改Nginx的配置文件,使之打印出JSON格式的access log,配置方法见附录内容。 access log内容如下:
{"@timestamp":"2016-03-03T13:11:03+08:00","host":"sinoiot-172-16-250-3","clientip":"172.16.1.34","size":191,"responsetime":0.000,"http_host":"172.16.250.3","url":"/mirror/","xff":"-","referer":"-","agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36","status":200}
{"@timestamp":"2016-03-03T13:11:03+08:00","host":"sinoiot-172-16-250-3","clientip":"172.16.1.34","size":0,"responsetime":0.000,"http_host":"172.16.250.3","url":"/favicon.ico","xff":"-","referer":"http://172.16.250.3/mirror/","agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36","status":204}
...
模拟产品环境的Logstash的配置文件如下所示:
input {file {path => "/var/log/nginx/access.log"codec => jsontype => "nginx"tags => "access"}
}output {# stdout这个output插件仅作为调试阶段使用,用于将处理过的结果打印在终端# 真实产品环境不需要这个outputstdout {codec => "rubydebug"}kafka {topic_id => "logs"bootstrap_servers => "172.16.250.10:9092" # 真实产品环境需要修改对应的kafka集群列表}
}
启动logstash,将会看到终端上显示解析过的事件:
{"@timestamp" => "2016-03-03T05:11:03.000Z","host" => "sinoiot-172-16-250-3","clientip" => "172.16.1.34","size" => 191,"responsetime" => 0.0,"http_host" => "172.16.250.3","url" => "/mirror/","xff" => "-","referer" => "-","agent" => "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36","status" => 200,"@version" => "1","path" => "/var/log/nginx/access.log","type" => "nginx","tags" => [[0] "access"]
}
{"@timestamp" => "2016-03-03T05:11:03.000Z","host" => "sinoiot-172-16-250-3","clientip" => "172.16.1.34","size" => 0,"responsetime" => 0.0,"http_host" => "172.16.250.3","url" => "/favicon.ico","xff" => "-","referer" => "http://172.16.250.3/mirror/","agent" => "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36","status" => 204,"@version" => "1","path" => "/var/log/nginx/access.log","type" => "nginx","tags" => [[0] "access"]
}
从kafka队列中的logs这个topic获取日志信息,将看到下列内容:
$ bin/kafka-console-consumer.sh --zookeeper 172.16.250.10:2181 --topic logs --from-beginning
{"@timestamp":"2016-03-03T05:12:21.000Z","host":"sinoiot-172-16-250-3","clientip":"218.75.124.3","size":162,"responsetime":0.000,"http_host":"218.75.124.3","url":"/mirror/packages.elastic.co/elasticsearch/2.x/debian/dists/stable/main/i18n/Translation-en","xff":"-","referer":"-","agent":"Debian APT-HTTP/1.3 (1.0.1ubuntu2)","status":404,"@version":"1","path":"/var/log/nginx/access.log","type":"nginx","tags":["access"]}
{"@timestamp":"2016-03-03T05:12:21.000Z","host":"sinoiot-172-16-250-3","clientip":"218.75.124.3","size":162,"responsetime":0.000,"http_host":"218.75.124.3","url":"/mirror/packages.elastic.co/kibana/4.4/debian/dists/stable/main/i18n/Translation-en_US","xff":"-","referer":"-","agent":"Debian APT-HTTP/1.3 (1.0.1ubuntu2)","status":404,"@version":"1","path":"/var/log/nginx/access.log","type":"nginx","tags":["access"]}
证明logstash已经将解析过的事件推送至kafka队列中。
由于消息队列中存储的日志都是解析过的,所以日志服务器上的配置就简单多了,只需要通过logstash将kafka中的日志推送至elasticsearch存储即可。
日志服务器的logstash配置就简单的多(真实产品环境下需要配置email filter插件,用于邮件报警)。
模拟日志服务器的logstash配置:
input {kafka {topic_id => "logs"zk_connect => "172.16.250.10:2181" # 真实产品环境替换为对应的zookeeper集群列表}
}output {elasticsearch {codec => json}# 产品环境调试完毕,不需要stdout这个output pluginstdout {codec => "rubydebug"}# 产品环境需要邮件报警的话,加入email output# if 报警条件 {# email {# # email output插件的配置# }#}
}
最后,在kibana中将看到如下的效果: 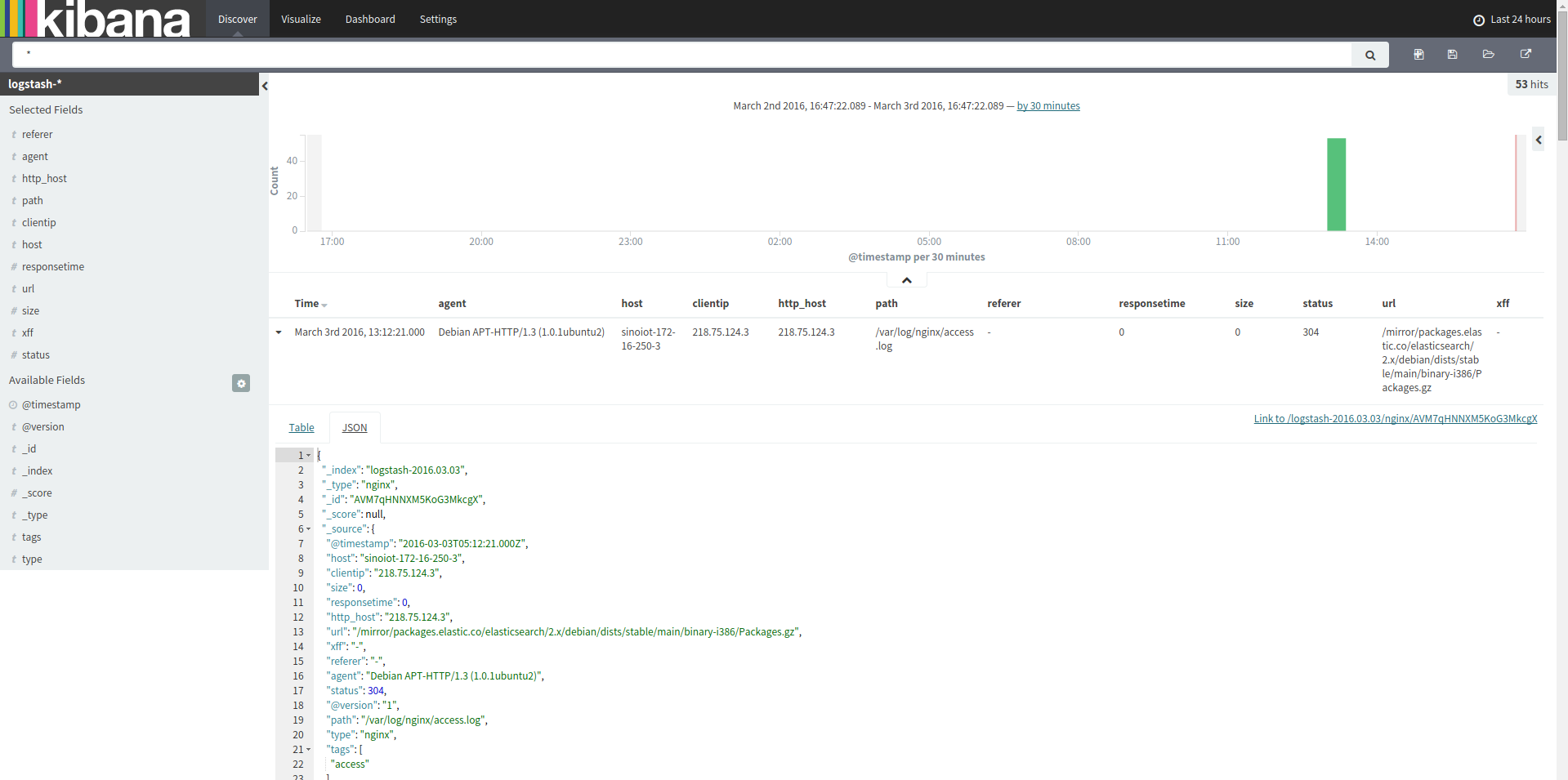
应用程序日志
自己开发的应用程序直接按照JSON格式推送至Kafka消息队列中,因此不需要通过logstash output kafka这种方式。log4j 1.2版本需要手工格式化成JSON,log4j 2.x版本提供了JSON appender,不过目前来看log4j 1.x版本依旧占据主流。输出到kafka的配置参考附录。
由于推送的topic_id是一样的,因此日志服务器中的logstash配置也无需修改。
从kafka队列中取出log,看看格式:
$ bin/kafka-console-consumer.sh --zookeeper 172.16.250.10:2181 --topic logs --from-beginning
{"@timestamp":"2016-03-03T17:03:32.772+08:00","host":"172.16.1.4","type":"rtds","loglevel":"INFO","classname":"hawkeyes.rtds.MainVerticle","logdetail":{"a":1,"b":2}}
{"@timestamp":"2016-03-03T17:03:32.773+08:00","host":"172.16.1.4","type":"rtds","loglevel":"DEBUG","classname":"hawkeyes.rtds.MainVerticle","logdetail":{"c":1,"d":2}}
{"@timestamp":"2016-03-03T17:03:32.813+08:00","host":"172.16.1.4","type":"rtds","loglevel":"ERROR","classname":"hawkeyes.rtds.MainVerticle","logdetail":{"errormsg":" java.math.BigDecimal.divide(Unknown Source)\n org.codehaus.groovy.runtime.typehandling.BigDecimalMath.divideImpl(BigDecimalMath.java:68)\n org.codehaus.groovy.runtime.typehandling.IntegerMath.divideImpl(IntegerMath.java:49)\n org.codehaus.groovy.runtime.dgmimpl.NumberNumberDiv$NumberNumber.invoke(NumberNumberDiv.java:323)\n org.codehaus.groovy.runtime.callsite.PojoMetaMethodSite.call(PojoMetaMethodSite.java:56)\n org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:48)\n org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:113)\n org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:125)\n hawkeyes.rtds.MainVerticle.test(MainVerticle.groovy:69)\n hawkeyes.rtds.MainVerticle.deployInStandaloneMode(MainVerticle.groovy:63)\n sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)\n sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)\n java.lang.reflect.Method.invoke(Unknown Source)\n org.codehaus.groovy.reflection.CachedMethod.invoke(CachedMethod.java:93)\n groovy.lang.MetaMethod.doMethodInvoke(MetaMethod.java:325)\n groovy.lang.MetaClassImpl.invokeMethod(MetaClassImpl.java:1210)\n groovy.lang.MetaClassImpl.invokeMethod(MetaClassImpl.java:1077)\n groovy.lang.MetaClassImpl.invokeMethod(MetaClassImpl.java:1019)\n groovy.lang.Closure.call(Closure.java:426)\n groovy.lang.Closure.call(Closure.java:420)\n java_util_concurrent_Callable$call.call(Unknown Source)\n org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:48)\n org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:113)\n org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:117)\n hawkeyes.rtds.MainVerticle.start(MainVerticle.groovy:30)\n io.vertx.lang.groovy.GroovyVerticle.start(GroovyVerticle.groovy:64)\n io.vertx.lang.groovy.GroovyVerticle$1.start(GroovyVerticle.groovy:93)\n io.vertx.core.impl.DeploymentManager.lambda$doDeploy$159(DeploymentManager.java:429)\n io.vertx.core.impl.ContextImpl.lambda$wrapTask$16(ContextImpl.java:335)\n io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:358)\n io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357)\n io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:112)\n java.lang.Thread.run(Unknown Source)\n"}}
{"@timestamp":"2016-03-03T17:03:32.814+08:00","host":"172.16.1.4","type":"rtds","loglevel":"INFO","classname":"hawkeyes.rtds.MainVerticle","logdetail":{"a":1,"b":2}}
{"@timestamp":"2016-03-03T17:03:32.814+08:00","host":"172.16.1.4","type":"rtds","loglevel":"DEBUG","classname":"hawkeyes.rtds.MainVerticle","logdetail":{"c":1,"d":2}}
最终在kibana中展示的效果如图: 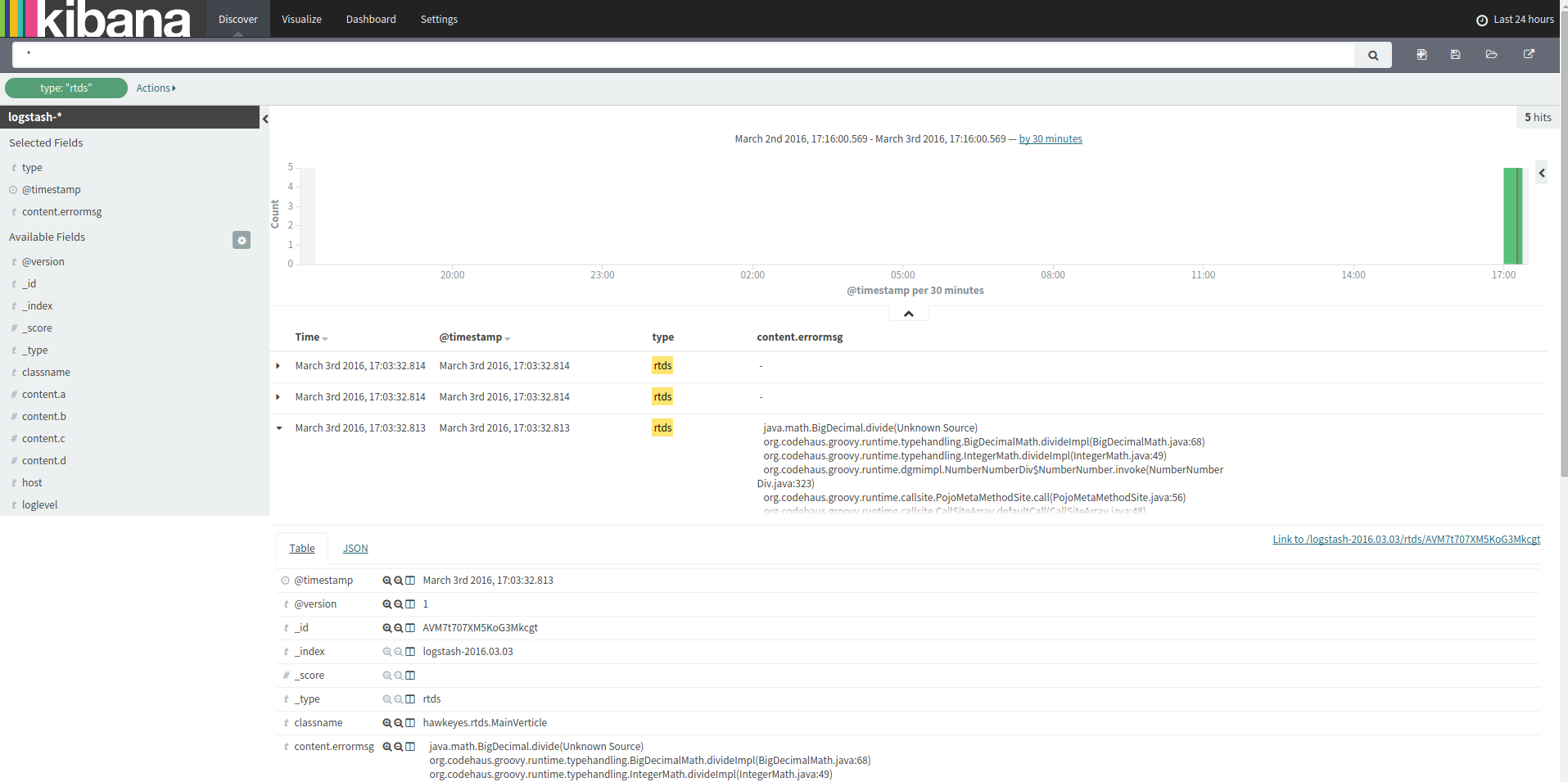
总结
ELK这套架构的设计由于其外部组件的松耦合性,几乎可以满足各种规模日志收集,组合消息队列,更是带来了弹性伸缩的可能性。
这套架构的引入,将对今后日志的收集管理提供便利,通过日志提供的数据,也便于业务跟踪。而且此架构在未来也容易扩展。
此架构涉及到的组件也相对较多,需要有一定的维护量。数据分析时不但需要有规范化的数据结构,也需要熟悉elasticsearch的聚合表达式,需要一些专业知识与学习成本。
附录
附录一 应用程序log输出到Kafka的方法
修改log4j.properties文件,配置kafka appender即可将log内容输入到kafka消息队列中。
log4j.logger.hawkeyes.rtds=INFO, Kafka
log4j.appender.Kafka=org.apache.kafka.log4jappender.KafkaLog4jAppender
log4j.appender.Kafka.layout=org.apache.log4j.EnhancedPatternLayout
log4j.appender.Kafka.layout.ConversionPattern=%m
log4j.appender.Kafka.brokerList=127.0.0.1:9092
log4j.appender.Kafka.topic=logs
log4j.appender.Kafka.requiredNumAcks=1
LOG4J主要由三大组件组成:
- Logger: 决定什么日志信息应该被输出、什么日志信息应该被忽略;
- Appender: 指定日志信息应该输出到什么地方, 这些地方可以是控制台、文件、网络设备;
- Layout: 指定日志信息的输出格式;
按照原来配置log4j.rootLogger=DEBUG, Kafka这使程序中所有日志都会向Kafka中写入。但KafkaLog4jAppender在初始化时,本身会打印log,它在获取logger对象时又会继续创建KafkaLog4jAppender,新的KafkaLog4jAppender又会打log, 这就成了死循环,因此定义了一个输出范围log4j.category.hawkeyes.rtds=INFO, Kafka,所有hawkeyes.rtds包下的类才会向kafka消息队列中输出,这不会影响KafkaLog4jAppender中log输出。
附录二 应用程序动态调整日志级别的实现方法
为满足不重启程序就能修改日志级别的需求,可以使用log4j的动态改变log输出级别的功能。
动态修改loglevel原理
改变Logger中level属性即可。
参考代码:
def rtdsLogger = Logger.getLogger("hawkeyes.rtds")
rtdsLogger.setLevel(Level.toLevel("info"))
然后将这种方法进行封装,对外提供一个可以操作的api即可(如REST api)。
附录三 部分相关服务的配置参考
Nginx输出JSON格式的log配置方法
编辑/etc/nginx/nginx.conf配置文件,加入以下内容:
log_format json '{"@timestamp":"$time_iso8601",''"host":"$hostname",''"clientip":"$remote_addr",''"size":$body_bytes_sent,''"responsetime":$request_time,''"http_host":"$host",''"url":"$uri",''"xff":"$http_x_forwarded_for",''"referer":"$http_referer",''"agent":"$http_user_agent",''"status":$status}';access_log /var/log/nginx/access.log json;
删掉原来默认的配置行access_log /var/log/nginx/access.log。重启nginx,之后nginx的access log文件/var/log/nginx/access.log将以json_lines的格式打印日志。
以上配置参考了饶琛琳的《ELK stack权威指南》的相关章节
Zookeeper相关配置参考
Zookeeper集群配置范例:
需要改动的文件有两个。在zookeeper的配置目录中
myid: 这个文件的内容修改为一个正整数,要求每个节点的数值不同zoo.cfg: 修改server.${id}=${ip}:2888:3888。这个id和myid中的数字一一对应,后面的ip是节点的ip(注意不要使用环回ip,必须是能被其他节点访问到的ip,也可以是域名)。参考范例:
server.1=172.16.250.10:2888:3888
server.2=172.16.250.13:2888:3888
server.3=172.16.250.14:2888:3888
Zookeeper启用SSL双向认证: //TODO
Kafka相关配置参考
Kafka集群配置范例:
修改config目录下的主配置文件server.properties。关键的几个配置参数如下:
broker.id=1
advertised.host.name=172.16.250.10
zookeeper.connect=172.16.250.10:2181,172.16.250.13:2181,172.16.250.14:2181
broker.id: 同zookeeper集群配置,每个节点的id均为不重复的正整数。advertised.host.name: 同zookeeper的集群配置,设置为能被其他节点访问到的ip或域名(该选项默认为系统主机名,不用hosts或dns基本无法被其他节点访问到)。zookeeper.connect: 为zookeeper集群列表,格式为ip:port。多个节点使用,分割。
Kafka启用SSL双向认证: //TODO
Logstash配置参考
产品服务器的logstash将日志从文件取出,格式化后推送至日志服务器的Kafka中:
input {file {path => "/path/to/log/file" # 日志文件路径type => "app" # 应用名,如nginx,postgresql等... SNIP ... # 这里根据不同的文件格式可能需要做不同处理}
}filter {# filter这里主要是grok正则,nginx配置JSON日志格式后不需要grok解析grok {... SNIP ...}
}output {kafka {topic_id => "logs"bootstrap_servers => "kafka" # 真实产品环境需要修改对应的kafka集群列表... SINP ...}
}
日志服务器logstash从kafka消息队列中取出对应的日志消息,推送至elasticsearch存储。 日志报警规则在日志服务器指定,便于修改报警规则。
input {kafka {zk_connect => "zookeeper_cluster:2181"topic_id => "logs"... SNIP ...}
}filter {# 这里详细指定邮件报警规则if "email_alert" in [tags] {email {... SNIP ...}}
}output {elasticsearch {... SNIP ...}
}
参考文献
- ELKstack 中文指南: https://www.gitbook.com/book/chenryn/kibana-guide-cn/details
- Logstash官方文档: https://www.elastic.co/guide/en/logstash/2.2/index.html
- Kafka官方文档集群配置: http://kafka.apache.org/documentation.html#quickstart_multibroker
- Zookeeper官方文档集群配置: https://zookeeper.apache.org/doc/r3.3.2/zookeeperAdmin.html#sc_zkMulitServerSetup
转载于:https://my.oschina.net/abcfy2/blog/703158
【产品环境】使用ELK搭建日志系统相关推荐
- 2018年ElasticSearch6.2.2教程ELK搭建日志采集分析系统(教程详情)
章节一 2018年 ELK课程计划和效果演示 1.课程安排和效果演示 简介:课程介绍和主要知识点说明,ES搜索接口演示,部署的ELK项目演示 es: localhost:9200 kibana htt ...
- 使用ELK搭建日志收集和分析系统
搭建日志收集和分析系统需要以下步骤: 安装Java运行环境 ELK是基于Java开发的,因此需要在服务器上安装Java运行环境 安装Elasticsearch Elasticsearch是ELK的核心 ...
- ELK+kafka日志系统搭建-实战
日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠 ...
- ELK 搭建日志分析系统 + Zipkin服务链路追踪整合
一.需求描述 在分布式系统中,日志跟踪是一件很令程序员头疼的问题,在遇到生产问题时,如果是多节点需要打开多节点服务器去跟踪问题,如果下游也是多节点且调用多个服务,那就更麻烦,再者,如果没有分布式链路, ...
- RabbitMQ + ELK 搭建日志平台
CentOS下使用ELK套件搭建日志分析和监控平台 2015年01月30日 17:32:29 i_chips 阅读数:24252 https://blog.csdn.net/i_chips/artic ...
- 初识ELK(日志系统)
1.ELK是Elasticsearch.Logstash. Kibana三大开源框架首字母大写简称.在市面上也被称之为Elastic Stack. 其中Elasticsearch是一个基于Lucene ...
- Spring Boot + ELK搭建日志监控框架
Spring Boot + ELK搭建日志监控框架 准备ELK三件套 Elasticsearch+Logstash+Kibana 下载地址:https://www.elastic.co/cn/ ...
- 快速搭建日志系统——ELK STACK
什么是ELK STACK ELK Stack是Elasticserach.Logstash.Kibana三种工具组合而成的一个日志解决方案.ELK可以将我们的系统日志.访问日志.运行日志.错误日志等进 ...
- 使用XLog、Spring-Boot、And-Design-Pro搭建日志系统
一.前言:移动端为什么要三方日志系统 日志系统用于记录用户行为和数据以及崩溃时的线程调用栈,以帮助程序员解决问题,优化用户体验. iOS系统就有自带Crash收集应用程序"ReportCra ...
最新文章
- wlop一张多少钱_50etf期权交易一张合约多少钱?
- 流量枯竭的时代,小程序创下“神话”,打造全新商业生态!
- 学计算机应该了解什么软件,大学计算机软件业生应该学什么.doc
- C++函数声明和定义
- 违反Apache 2.0许可证再分发被指控,火山引擎回应
- 使用Junit参数在更短的时间内编写更好的单元测试
- Java8新特性总结 - 4.方法引用
- Handler深入(分析源码,手写一套Handler)
- 一、网络知识 1.计算机网络原理
- 质量与效率并重,测试左移助力块存储技术研发
- 手机文件传云服务器失败怎么回事,为什么百度云上传不了文件 百度云无法上传文件原因解决办法...
- 初学linux用哪个发行版本,初学者学习Linux选择哪个发行版本合适?
- 记录origin画图遇到的问题及其软件bug解决
- Gitlab备份和恢复操作记录
- (java)Climbing Stairs
- 基于WPS开放平台 WPS文件转PDF开发指南
- word目录中页码没有向右对齐的解决方法
- Robocup2D入门笔记(2)——环境的配置与安装
- 2022年莆田市高新技术企业申报奖励补贴,高企认定条件以及申报材料汇总
- java面试题(一)java面试题集合