知识表示模型汇总分析--Trans系列
作者:孙天祥
链接:https://zhuanlan.zhihu.com/p/43436288
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
因为还根据自己的理解补充了点儿内容,就标为原创了。下面是正文:
近年来,以深度学习为代表的表示学习迅速发展,在很多领域都取得了巨大进展。简而言之,表示学习将要描述的对象表示为低维稠密向量,这也被称为分布式表示,从而有效解决了数据稀疏问题,并且便于在低维语义空间中进行计算。将表示学习应用于知识图谱(Knowledge Graph, KG),即是知识表示学习。
在当前的主流知识库中,知识被存储为 的三元组形式,其中
表示头实体,
表示联系,
表示尾实体。知识表示学习的任务就是学习
的分布式表示(也被叫做知识图谱的嵌入表示(embedding))。
目前,知识表示学习方法从实现形式上可以分为两类:基于结构的方法和基于语义的方法。基于结构的嵌入表示方法包括TransE, TransH, TransR&CTransR, TransD等,这类方法从三元组的结构出发学习KG的实体和联系的表示;基于语义的嵌入表示方法包括NTN, SSP, DKRL等,这类方法从文本语义的角度出发学习KG的实体和联系的表示。
知识表示学习从发展来看可以分成两个阶段,以2013年Borders等人受Mikolov发现的语义空间中词向量的平移不变现象启发,从而提出了翻译模型(TransE)为分割。在TransE之前,有Structed Embedding, Semantic Matching Energy等模型,在TransE之后,人们在此基础上进行改进,依次提出了TransH, TransR, TransD等模型。接线来介绍基于TransE的改进模型。
作者:孙天祥
链接:https://zhuanlan.zhihu.com/p/43436288
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
TransE
论文:Translating Embeddings for Modeling Multi-relational Data. Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, Oksana Yakhnenko. NIPS 2013.
我们用 表示头实体向量,用
表示尾实体向量,用
表示关系向量,TransE模型的目标就是让
尽可能地等于
,即
。其评分函数为:
显然,对于正确的三元组,应该有较低的得分。在训练过程中,使用等级损失函数,这是因为在当前情况下我们没有就标签而言的监督,只有一对正确项 和不正确项
,我们的目的是让正确项的得分比不正确项高。这种情况出现在我们只有正例时,知识图谱就是这种情况,我们只知道正确的三元组(golden triplet),再通过破坏一个正例来生成负例。等级损失就适用于这种情况,因此我们定义损失函数:
上式中的 表示正例和负例得分的最小间隔(margin),实际使用时常取
.
博主注:
我们的目标是让f(h,t)最小,让f(h',t')最大。开始我觉得上面的公式不对,因为应该是取上式的极小值作为目标函数。后来想了想,上式仅仅是损失函数,表示的是总体损失。式中的max不是对目标函数取max,而是对于每一对正反例,取f(h,t)+v-f(h',t')和0中的最大值,以免出现负值。
避免出现负值的原因:如果某一项是负的,那么可以通过使得这个负值的模非常大,来使得整个公式的值是一个模非常大的负值。而这样显然不是我们想要的。这样仅仅使得某一项符合要求,并不是全局最优。
如果我自己设计一个公式,估计是不能想到这一点的。看来顶会论文的水平还是很高的,方法既新奇又滴水不漏。
事实上,将等级损失中的得分函数替换为样本被预测为某个类别的概率,则上式的形式与多分类情形下的hinge损失一致。
TransE采取的生成负例三元组的方法是,将正确的三元组的头实体、尾实体、关系三者之一随机替换为其他实体或关系,从而构成负例集合 ,这种方法称为均匀采样(与后面的伯努利采样相对比)。
在代码实现中,首先选取一个正例三元组 ,再从
中采样得到一个负例三元组
,然后分别计算正例得分
和负例得分
,若
,则梯度下降更新
.
显然,TransE模型在处理复杂关系建模(一对多、多对一、多对多关系)时会遇到困难,例如,对于一对多关系(美国,总统,奥巴马)和(美国,总统,特朗普),TransE模型会使得尾实体向量奥巴马和特朗普的表示非常相似。事实上,这是由于对于不同的关系 ,实体向量的表示总是相同的。
TransH
论文:Knowledge Graph Embedding by Translating on Hyperplanes. Zhen Wang, Jianwen Zhang, Jianlin Feng, Zheng Chen. AAAI 2014.
TransH方法由中山大学信科院冯剑琳团队和MSRA联合提出,克服了TransE模型的上述缺点,使得同一个实体向量在不同关系下有不同的表示。
TransH模型对于每一个关系 ,假设有一个对应的超平面(关系
落于该超平面上),其法向量为
,且有
. 关于超平面,可以参见这里。
类似于TransE模型的翻译在该超平面上进行,具体地,首先将头实体 和尾实体
投影到该超平面上得到
和
,即
博主注:
上述公式可以将h和t进行投影。以h为例,其中的wT*h是一个数,是将h投影到w方向的向量的模。后面再乘一个w是为了把这个标量变成矢量。这样的话,h与这个矢量的差就是h在超平面上的投影矢量。
进而,我们定义得分函数为
原文中贴出了一张图,很直观的说明了TranH的工作原理,以及和TransE的区别。
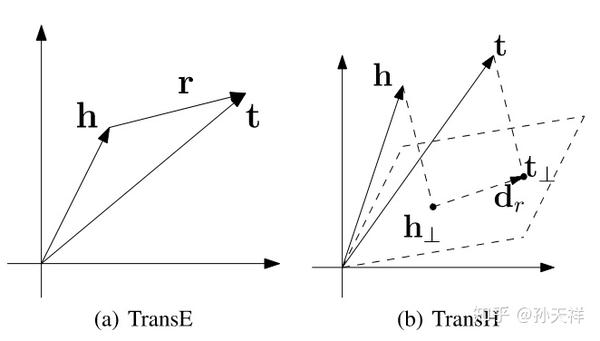
博主注:
考虑之前总统的例子,也就是一个一对多的问题。将关系表示成超平面后,这种问题得到了解决。如下图所示,如果分别用t和t‘表示两个总统,那么将三元组映射到超平面之后,t和t‘都能满足’(美国,总统,*)这个三元组。并且两个向量在向量空间还是不同的。多对一,多对多的情况也可以这样解决。
![]()
当然,投影后我们需要训练的参数就不止是实体和关系向量了。还得训练投影平面(其实就是每个关系对应的投影平面的法向量)。目标函数变为:
![]()
![]()
其中[]+表示的就是TransE公式中的max(*,0),即对于中括号中的值,返回0和它之间的最大值。
上式还得满足三个限制。其中,限制(1)保证每个向量的模都小于1。限制(2)是dr到wr的投影长度/dr的长度,这个值非常小,保证了dr确实在投影平面上。限制(3)规定投影平面的法向量的模为1,这样做是为了简化公式。否则这个公式的形式就会更为复杂。
虽然TransH模型使得同一实体在不同关系下通过投影有了不同的表示,但投影之后仍然处于原来的空间 中,这里
表示实体向量和关系向量均为
维。换言之,TransH模型假设实体和关系处于相同的语义空间中,这在一定程度上限制了它的表示能力。下面的TransR模型改进了这一缺陷,提高了模型的表示能力。
值得一提的是,在本篇论文中除了提出了TranH模型,另一贡献是提出了基于伯努利分布的采样方法。在原来的均匀采样中,容易将错误的负例引入到训练过程中来,例如,对于正例(美国,总统,奥巴马),随机替换奥巴马为罗斯福构成(美国,总统,罗斯福)作为负例,实际上由于罗斯福也是总统,这并不是一个负例。新的采样方法的动机是,对于一对多关系,我们以更大的概率来替换其头实体,对于多对一关系,我们以更大的概率来替换其尾实体。具体地,对于包含关系 的所有三元组,我们定义两个统计量:
1. : 平均每个头实体对应多少个尾实体
2. : 平均每个尾实体对应多少个头实体
进而,取伯努利分布的参数为 ,即以概率
替换三元组的头实体,以概率
替换三元组的尾实体。实际上,
反映了一对多关系的失衡程度。
博主注:
可以先忽略分母(分母是用来归一化的)。那么,tph表示一个头实体大概对应多少尾实体。这个值越大说明我们在构建负例时,固定头实体,随机选择尾实体的过程中越可能出错(一不小心就弄成正例了)。所以这时候我们应该替换头实体。因此归一化的tph就是替换头实体的概率。相似地,归一化的hpt就是替换尾实体的概率。
通过基于伯努利分布的采样,我们就降低了引入错误的负例的概率。在清华大学NLP组的开源代码KB2E中,同时提供了两种采样方式,bern表示伯努利采样,unif表示均匀采样。
TransR & CTransR
论文:Learning Entity and Relation Embeddings for Knowledge Graph Completion. Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, Xuan Zhu. AAAI 2015.
TransR
TransR模型是由清华大学NLP组(林衍凯、刘知远、孙茂松等)提出,TransR模型认为,不同的关系关注实体的不同属性(实体向量的不同维度),因此不同的关系应具有不同的语义空间。
TransH模型是为每个关系假定一超平面,将实体投影到这个超平面上进行翻译;而TransR模型是为每个关系假定一语义空间 ,将实体映射到这个语义空间上进行翻译。这里
表示关系向量的维度为
。
TransR模型可以形式化描述为
其中, . 约束条件为
的L2范数均不大于1.
CTransR
CTransR的意思是Cluster-based TransR. CTransR对于每一个特定的关系 ,首先根据实体对
进行AP聚类(一种不需要指定类别数的聚类方法),实际上是对实体对的差值向量
进行聚类,从而将关系
分解为更细粒度的子关系
,CTransR对每个
分别学习相应的向量表示。
形式化地,CTransR的得分函数可以描述为
上式中第二项使得 尽可能地接近
.
TransR & CTransR模型将原来的单个语义空间分离为实体空间和关系空间,提高了模型的表示能力,然而,TransR模型仍然存在一些缺点:
1. 在同一个关系 下,头、尾实体使用相同的投影矩阵
,而头、尾实体可能类型或属性相差很大;
2. 投影矩阵仅与关系有关;
3. 参数多,计算复杂度高。
TransD
论文:Knowledge Graph Embedding via Dynamic Mapping Matrix. Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, Jun Zhao. ACL 2015.
TransD模型由中科院自动化所NLPR中赵军、刘康组提出,一定程度上克服了TransR & CTransR的上述缺点。
CTransR模型相比于TransR模型,实际上就是考虑了同一个关系也有不同的类型,然而,实体也有不同的类型。举个例子,在FB15k中,有关系location.location.partially containedby,它可以表示山川大河被某个国家包含,也可以表示山川大河被某个城市/州包含,也可以表示国家被大洲包含,还可以表示地区被国家包含。由于实体有不同的类型,因而使用相同的映射矩阵是不合理的,而且,映射矩阵不应只与关系有关,还应与头尾实体有关。以上就是TransD模型的动机,这实际上是一个更细粒度的扩展模型,本质上还是由实体语义空间和关系语义空间两个空间构成。
具体地,对于一个三元组 ,分别定义对应的投影向量
,其中
表示投影(projection),再定义两个投影矩阵
来将实体从实体空间映射到关系空间。
这里, ,
表示单位阵,它的意思是说用单位阵来初始化投影矩阵。
Tips: 如果你检查过向量和矩阵的维度,可能会发现在TransD中,实体和关系向量均为列向量,而在前面的模型中实体和关系都是行向量。这里尊重了原文中的形式,并未在本文中做统一。
可见,在上式中,对头实体应用投影矩阵 ,它不仅与关系有关,还与头实体有关;对尾实体应用投影矩阵
,它也不仅与关系有关,还与尾实体有关。利用这两个投影矩阵,可以得到头实体和尾实体在关系空间的投影
从而得分函数为
对比
理论对比
显然,TransE是TransD的一个特例,当 且所有投影向量均为零时,TransD就退化为了TransE. 与TransH对比,显然需先令TransD的
,再分别写出TransH和TransD的实体投影后的向量:
因为 ,因此为便于格式上的对比,我们将TransD中的
写成上述形式。可见,当
时,TransD与TransH唯一的区别在于TransD中的投影向量不仅与关系有关,还与实体有关。
对比TransR模型,TransD为头实体和尾实体分别设置了投影矩阵,另外,注意到在TransD中公式经过展开之后没有矩阵-向量乘法操作,这相比于TransR模型降低了计算复杂度,更适用于大规模知识图谱的计算。
性能对比
评估不同知识表示学习方法的优劣的主要指标就是在知识图谱的一些典型任务上的表现,比如三元组分类(triplet classification)和链接预测(link prediction)。下面贴出在WordNet和Freebase中各模型在两任务上的表现,TransE, TransH, TransR, CTransR, TransD包括了使用bern和unif采样的结果。图片数据来源于TransD的论文。
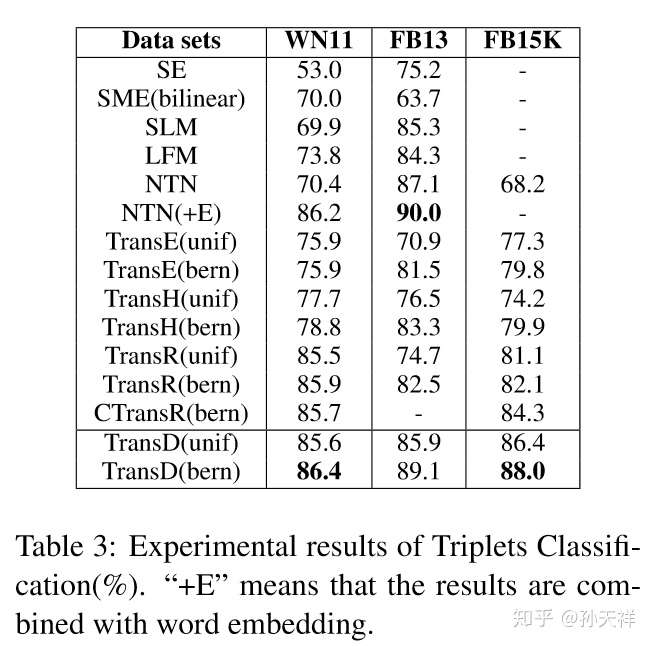
三元组分类结果对比
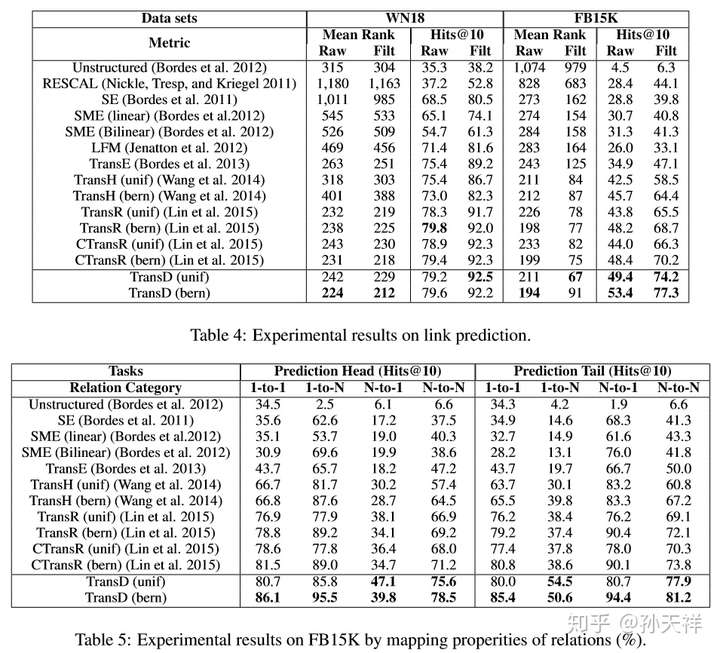
链接预测结果对比
知识表示模型汇总分析--Trans系列相关推荐
- 「二分类算法」提供银行精准营销解决方案(各个模型汇总分析)baseline
完整代码见 Github:「二分类算法」提供银行精准营销解决方案 赛事详情 1.比赛页面:「二分类算法」提供银行精准营销解决方案 2.数据与测评算法 训练集下载链接 测试集下载链接 字段说明 测评算法 ...
- 基于翻译模型(Trans系列)的知识表示学习
翻译模型(Trans) 解决问题:知识表示与推理 将实体向量表示(Embedding)在低维稠密向量空间中,然后进行计算和推理. 主要应用:triplet classification, link p ...
- OpenKE实现转移距离模型trans系列代码
OpenKE实现转移距离模型trans系列代码 前言 前段时间学习了知识图谱表示的转移距离模型trans系列大礼包,编辑这篇博客的起因是一个学妹找我要trans系列的代码,所以就在周日的下午来回忆一下 ...
- R语言survival包clogit函数构建条件logistic回归模型、summary函数查看模型汇总统计信息、通过似然比检验分析结果判断模型有无统计学意义
R语言survival包clogit函数构建条件logistic回归模型.summary函数查看模型汇总统计信息.通过似然比检验分析结果判断模型有无统计学意义 目录
- 基于知识图谱的表示学习——Trans系列算法介绍(一)
鉴于知识图谱的研究越来越多,所以在组会主讲上介绍了知识图谱表示学习的Trans系列方法,以下仅是本人对于此类方法的理解,请批评指正.Trans系列方法的源码均为公开代码,可以自行搜索. 背景介绍 知识 ...
- Trans系列文章解读
本系列,笔者转载搜狐(机器之心博主)的文章,如有侵权,联系笔者立即删除 -----------------------------分割线-------------------------------- ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之五
隐马尔科夫模型(Hidden Markov Models) 系列之五 介绍(introduction) 生成模式(Generating Patterns) 隐含模式(Hidden Patterns) ...
- android点击事件的优先级,Android事件体系全面总结+实践分析,系列篇
前言 在这一个月里,我利用闲余的时间看了下最近Android职业发展这块该怎么选择?这个问题各位大神的回答都非常透彻,相信对大家或多或少都在一定程度上有很大的帮助,今天在这里写这篇文章更多的是想以我开 ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之三
隐马尔科夫模型(Hidden Markov Models) 系列之三 介绍(introduction) 生成模式(Generating Patterns) 隐含模式(Hidden Patterns) ...
最新文章
- CVD-ALD前驱体材料
- swift笔记三 使用xcode
- validateJarFile jar not loaded. See Servlet Spec 2.3, section 9.7.2. Offending class: javax/servlet/
- 生成ssh key (Mac Linux )
- 【程序员眼中的统计学(12)】相关与回归:我的线条如何? (转)
- http协议 php,PHP中的http协议
- 学习C# - Hello,World!
- 操作系统 --- 线程与进程的比较
- webservice引用spring的bean
- MySQL之EXPLAIN(索引优化)
- ERROR in static/js/vendor.js from UglifyJs UUnexpected token: name (Dom7)
- string的基本用法
- 【NIO】dawn在buffer用法
- C语言课程设计——电影院订票系统
- 关于编译优化选项o3的问题
- java课程综合实训报告_Java ME综合实训报告
- 未来五年-不懂版权价值层次论你就落伍了!
- 修正逆解文章——六轴UR机械臂正逆运动学求解_MATLAB代码(标准DH参数表)
- 加州理工学院宋飏老师招收机器学习全奖博士生|2023秋季
- Linux 下查询日志