python学习(十七) 爬取MM图片
这一篇巩固前几篇文章的学到的技术,利用urllib库爬取美女图片,其中采用了多线程,文件读写,
目录匹配,正则表达式解析,字符串拼接等知识,这些都是前文提到的,综合运用一下,写个爬虫
示例爬取美女图片。
先定义几个匹配规则和User_Agent
1234567 |
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'PATTERN1 = r'<div id="content">.*?<h2>(.*?)</h2>' PATTERN2 = r'<p><img src="(.*?)"'PATTERN2 = r'<p><img class=".*?src="(.*?)"'PATTERN3 = r'''<li class='next-page'><a target="_blank" href='(.*?)'>下一页'''PATTERN4 = r'^(.*)/'PATTERN5 = r'^.*/(.*?)$' |
读者可以根据不同网站的代码去修改这些规则,达到匹配一些网站的目的。
1定义抓图类
123456789 |
class GetMMPic(object): def __init__(self,path,httpstr): # 去除首位空格 path = path.strip() # 去除尾部 \ 符号 path = path.rstrip('\\') self.path = path self.url = httpstr self.user_agent = USER_AGENT
|
初始化构造函数中设置了路径和网络地址,以及请求的user_agent。
2封装信息请求和读取函数
12345678910111213141516171819 |
def requestData(self,url, user_agent): try: req = request.Request(url) req.add_header('User-Agent', user_agent) response = request.urlopen(req,timeout = 8) #bytes变为字符串 content = response.read().decode('utf-8') return content except error.URLError as e: if hasattr(e,'code'): print (e.code) if hasattr(e,'reason'): print (e.reason) except error.HTTPError as e: if hasattr(e,'code'): print(e.code) if hasattr(e,'reason'): print(e.reason) print('HTTPError!!!')
|
这个函数功能主要是请求url网络地址,加上user_agent后,获取数据,并且采用utf-8
编码方式解析。
3封装创建目录函数
1234567891011 |
def makedir(self,dirname): joinpath = os.path.join(self.path,dirname) print(joinpath) isExists = os.path.exists(joinpath) if isExists: print('目录已经存在\n') return None else: os.makedirs(joinpath) print('创建成功\n') return joinpath
|
该函数主要是完成在GMMPic类配置的路径下(默认是./),生成子目录,子目录的名字由
参数决定。简单地说就是要在当前目录下生成文件名对应的文件夹,保存不同的图片。
4 获取当前页面信息保存图片
1234567891011121314151617181920212223242526272829303132333435363738394041424344 |
def getPageData(self,httpstr): content = self.requestData(self.url, self.user_agent) namepattern = re.compile(PATTERN1,re.S) nameresult = re.search(namepattern, content) namestr = nameresult.group(1) dirpath = self.makedir(namestr) if not dirpath: print('目录已存在') return
picpattern = re.compile(PATTERN2,re.S)
lastpattern = re.compile(PATTERN5, re.S)
while(1): print('正在爬取%s........'%(namestr)) picitems = re.findall(picpattern,content) for item in picitems: picrs = re.search(lastpattern, item) picname = picrs.group(1) filedir = os.path.join(dirpath,picname) url = quote(item, safe = string.printable) try: req = request.Request(url) req.add_header('User-Agent',USER_AGENT) response = request.urlopen(req) picdata =response.read() with open(filedir,'wb') as file: file.write(picdata) except error.URLError as e: if hasattr(e,'code'): print (e.code) if hasattr(e,'reason'): print (e.reason) except error.HTTPError as e: if hasattr(e,'code'): print (e.code) if hasattr(e,'reason'): print (e.reason)
print('\n%s爬取成功.......'%(namestr)) break
|
getPageData()函数根据PATTERN2匹配页面符合条件的图片资源,根据PATTERN5取出图片名字(不含类型),
通过for循环一个一个保存。
运行程序,提示输入网址,
这里输入男人装某篇文章的地址,效果如下:
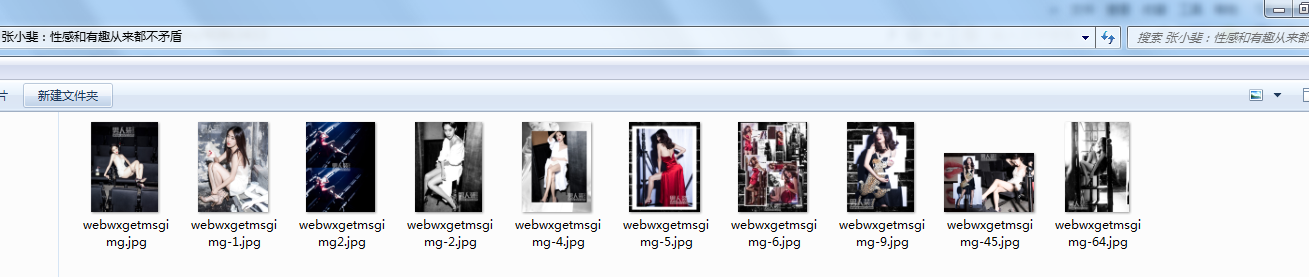
5 采用多线程提高并发能力
编写线程回调函数 workthread, 每个线程去爬不同的文章
1234567891011121314151617181920 |
def workthread(item, user_agent,path): strurl = 'http://yxpjw.club'+item[0] picname = item[1] print('正在爬取%s...........................\n' %(picname)) content = requestData(strurl,user_agent)
strurl2 = re.search(r'^(.*)/',strurl).group(0) print('https headers...............%s'%(strurl2)) #destname = os.path.join(path,picname+'.txt') #with open(destname, 'w',encoding='gbk') as file: #file.write(content) destdir = os.path.join(path,picname) os.makedirs(destdir) page = 1 while(1): content = getpagedata(content,destdir,page,strurl2) if not content: break page = page + 1 print('%s数据爬取成功!!!\n'%(picname))
|
开辟多个线程,去爬首页各个分栏,实现自动化抓图
1234567891011121314151617181920 |
def getDetailList(self,content): s2 = r'<h2><a target="_blank" href="(.*?)" title="(.*?)"' pattern =re.compile(s2 , re.S ) result = re.findall(pattern, content) with open('file.txt','w',encoding='gbk') as f: f.write(content)
if not result: print('匹配规则不适配..............')
threadsList=[] for item in result: t = threading.Thread(target = workthread, args=(item, self.user_agent, self.path)) threadsList.append(t) t.start()
for threadid in threadsList: threadid.join()
|
源码下载地址:
https://github.com/secondtonone1/python-
谢谢关注我的公众号:
![]()
转载于:https://www.cnblogs.com/secondtonone1/p/8086304.html
python学习(十七) 爬取MM图片相关推荐
- python 全自动化爬取必应图片
python 全自动化爬取必应图片 from selenium import webdriver import requests import time import re import urllib ...
- [python学习] 简单爬取维基百科程序语言消息盒
文章主要讲述如何通过Python爬取维基百科的消息盒(Infobox),主要是通过正则表达式和urllib实现:后面的文章可能会讲述通过BeautifulSoup实现爬取网页知识.由于这方面的文章还是 ...
- 方法教程 | Python爬虫:爬取风景图片
"突发奇想,给各位爬爬壁纸图片,话不多说,开始行动.如果文章对你有帮助,点赞,收藏." 一,知道爬取自己想要的壁纸图片网址 模型写出来 '''爬取网络图片1,要到主页面的 ...
- 利用python爬虫大量爬取网页图片
最近要进行一类图片的识别,因此需要大量图片,所以我用了python爬虫实现 一.爬取某一图片网站 主要参考:https://www.cnblogs.com/franklv/p/6829387.html ...
- Python网络爬虫——爬取网站图片小工具
最近初学python爬虫,就写了一个爬取网站图片的小工具,界面如下: 用到的包主要是爬虫常用的urllib,urllib2和图形界面用的Tkinter,完整代码如下: # -*- coding:utf ...
- python如何爬取图片_百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://5912119.blog.51cto.com/5902119/1771391 这一篇我想写写如何爬取百度图片的爬虫, ...
- Python爬虫——关键字爬取百度图片
在日常生活中,我们经常需要使用百度图片来搜索相关的图片资源.而如果需要大量获取特定关键字的图片资源,手动一个个下载无疑十分繁琐且费时费力.因此,本文将介绍如何通过Python爬虫技术,自动化地获取百度 ...
- Python爬虫——批量爬取微博图片(不使用cookie)
引言:刚开始我想要爬取微博的照片,但是发现网上大多数的blog都是需要一个cookie的东西,当时我很难得到,偶然翻到一个个人的技术博客: http://www.omegaxyz.com/2018/0 ...
- Python学习笔记-爬取B站电视剧《风犬少年的天空》弹幕并分析
爬取B站电视剧<风犬少年的天空>弹幕并分析 写在前面 开始! 简单分析一下弹幕数据 蠢并痛苦着的学习过程... 干(烂)货环节-------弹幕的获取与整理 关于cid的获取 关于弹幕上限 ...
最新文章
- Java方法,调用,static关键字
- 【Lv1-Lesson002】He and She
- python 线程池_老程序员的经验分享:Python 从业十年是种什么体验?
- CV Code | 本周新出计算机视觉开源代码汇总(南理SGE 和Intel的实时动作识别很吸引人)...
- 如何去除计算机的访问限制,访问限制达成,教你如何禁止别人访问你电脑的C盘...
- 如何选择使用字符串还是数字呢?
- Star Schema完全参考手册学习笔记七
- CISCO认证涨价了
- 华为手机有哪些功能关掉比较好?
- Elasticsearch模块功能之-索引分片分配(Index shard allocation)
- Atitit usrqbg1834 html的逻辑化流程化 规范标准化解决方案
- QT制作自定义进度条(圆环状)
- OpenGL ——安装和环境配置
- 3DMax导出FBX文件贴图丢失
- 浅谈大数据广告下个人隐私保护,开发者视角的广告原理
- 蒙古文输入法linux版,蒙古文输入法下载 德力海蒙古文输入法 V2.1.3 官方安装版(附使用手册) 下载-脚本之家...
- cidaemon.exe进程cpu使用率100%
- 两个高斯分布乘积的理论推导
- 计算机睡眠重启后无法识别网络,教您一招解决电脑休眠唤醒后无法使用USB键盘的操作方法...
- 2023年Python数据分析有什么好的课程推荐吗?
热门文章
- 再反转:21℃室温超导成果被美院士宣称复现!新实验基于原始样品,南大闻海虎再提3点质疑...
- 【离散数学】图论 通路与回路
- Matlab求微分方程的符号解1
- 虚拟无限--对虚拟机与虚拟化的简单整理
- 行指针与列指针的联系和区别
- html改变字母间距,css怎么调整字体间距?
- TogoID - 生物医学数据库ID转换工具
- Ubuntu pyinstaller 打包可执行文件时报错:... qt.qpa.plugin: Could not find the Qt platform plugin “xcb“ in “...
- Tapd需求或BUG 关联gitlib提交
- Comet OJ - Contest #5 A-E