vmstat详细解读
vmstat详细解读
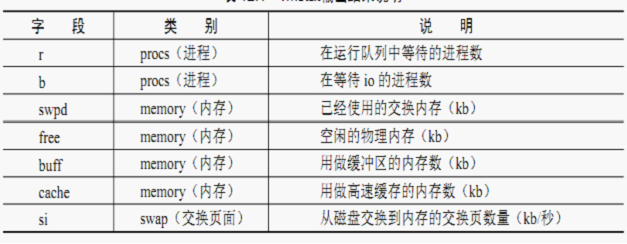
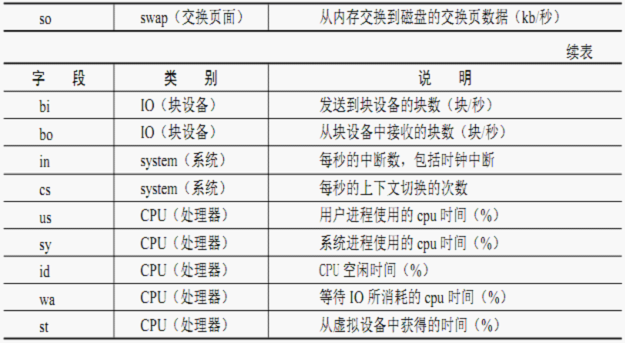
一、解读内存
二、解读CPU
1. 运行队列
2. CPU使用率
3. 上下文切换
三、系统监控的实验
实例一,大量的算术运算
实例二,大量的系统调用
实例三,大量的io操作
实例四:大量的占用内存
实例五:又一个大量分配内存例子
四、vmstat用法
1. 查看系统已经fork了多少次
2. 查看内存的active和inactive
3. 查看内存使用的详细信息
4. 查看磁盘的读/写
一、 解读内存
Linux系统的内存分为物理内存和虚拟内存两种。物理内存是真实的,也就是物理内存条上的内存。而虚拟内存则是采用硬盘空间补充物理内存,将暂时不使用的内存页写到硬盘上以腾出更多的物理内存让有需要的进程使用。当这些已被腾出的内存页需要再次使用时才从硬盘(虚拟内存)中读回内存。这一切对于用户来说是透明的。通常对Linux系统来说,虚拟内存就是swap分区。
vmstat(VirtualMeomoryStatistics,虚拟内存统计)是Linux中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU等的整体情况进行监视。
NAME
vmstat - Report virtual memory statistics
SYNOPSIS
vmstat [-a] [-n] [delay [ count]]
vmstat [-f] [-s] [-m]
vmstat [-S unit]
vmstat [-d]
vmstat [-D]
vmstat [-p disk partition]
vmstat [-V]
参数解读:
要以5秒为时间间隔,连续收集10次性能数据,命令如下:
root@debian6:~# vmstat 3 10
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 772804 41964 175320 0 32 5 143 22 14 0 0 99 0
0 0 0 772796 41964 175320 0 0 0 0 24 14 0 0 100 0
0 0 0 772796 41964 175320 0 0 0 0 22 15 0 0 100 0
0 0 0 772796 41964 175320 0 0 0 0 29 16 0 0 100 0
0 0 0 772796 41964 175320 0 0 0 0 52 36 0 0 100 0
0 0 0 772796 41964 175320 0 0 0 0 46 21 0 0 100 0
0 0 0 772780 41964 175320 0 0 0 0 51 50 1 0 99 0
0 0 0 772780 41964 175320 0 0 0 0 48 25 0 0 100 0
0 0 0 772780 41964 175320 0 0 0 0 43 19 0 1 99 0
0 0 0 772780 41964 175320 0 0 0 0 36 18 0 0 100 0
参数解读:
对于内存监控,需要关心的指标包括:swpd、free、buff、cache、si和so,尤其需要重视的是free、si和so。很多人都会认为系统的空闲内存(free)少就代表系统性能有问题,其实并不是这样的,这还要结合si和so(内存和磁盘的页面交换)两个指标进行分析。正常来说,当物理内存能满足系统需要的话(也就是说物理内存能足以存放所有进程的数据),那么物理内存和磁盘(虚拟内存)是不应该存在频繁的页面交换操作的,只有当物理内存不能满足需要时系统才会把内存中的数据交换到磁盘中。而由于磁盘的性能是比内存慢很多的,所以如果存在大量的页面交换,那么系统的性能必然会受到很大影响。
二、 解读CPU
在Linux系统中监控CPU的性能主要关注3个指标:运行队列、CPU使用率和上下
文切换,理解这3个指标的概念和原理对于发现和处理CPU性能问题有很大的帮助。
1. 运行队列
每个CPU都会维护一个运行队列,调度器会不断地轮询让队列中的进程运行,直到进程运行完毕将其由队列中删除。如果CPU过载,就会出现调度器跟不上系统要求,导致运行队列中等待运行的进程越来越多。正常来说,每个CPU的运行队列不要超过3,如果是双核CPU就不要超过6。
2. CPU使用率
CPU使用率一般可以分为一下几个部分。
a. 用户进程:运行用户进程所占用的CPU时间的百分比。
b. 系统进程:运行系统进程和中断所占用的CPU的时间百分比。
c. 等待IO:因为IO等待而使CPU处于idle状态的时间百分比。
d. 空闲:CPU处于空闲状态的时间百分比。
如果CPU的空闲率长期低于10%,那么表示CPU的资源已经非常紧张,应该考虑进程优化或添加更多地CPU。“等待IO”表示CPU因等待IO资源而被迫处于空闲状态,这时候的CPU并没有处于运算状态,而是被白白浪费了,所以“等待IO应该越小越好。”
3. 上下文切换
通过CPU时间轮询的方法,Linux能够支持多任务同时运行。对于普通的CPU,内核会调度和执行这些进程,每个进程都会被分配CPU时间片并运行。当一个进程用完时间片或者被更高优先级的进程抢占时间块后,它会被转到CPU的等待运行队列中,同时让其他进程在CPU上运行。这个进程切换的过程被称为上下文切换。过多的山下文切换会造成系统的很大的开销。
实例解读:
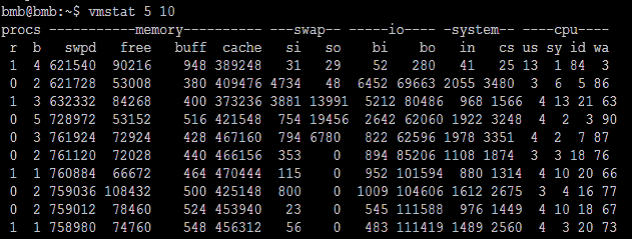
CPU状态的监控指标主要有以下几个参数获得:
r:在运行队列中等待的进程数。
b:在等待IO的进程数。
cs:每秒的上下文切换的次数。
us:用户进程使用的CPU时间(%)。
sy:系统进程使用的CPU时间(%)。
id:CPU空闲时间(%)。
wa:等待IO所消耗的CPU时间(%)。
由上面的命令输出中可以看到:
1. IO等待的CPU时间(wa)非常高,而实际运行用户和系统进程的CPU时间却不高。
2. 存在等待IO的进程(b>0)。
由此可以得出结论:系统目前CPU使用率高是由于IO等待所造成的,并非由于CPU资源不足。用户应检查系统中正在进行IO操作的进程,并进行调整和优化。
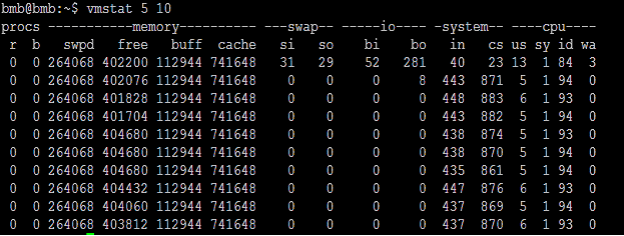
正常的CPU状态图,可以与上图作比较:
三、系统监控的实验:
实例一,大量的算术运算
本程序会进入一个死循环,不断的进行求平方根的操作,模拟大量的算术运算的环境.
测试源程序如下:
- #include <stdio.h>
- #include <math.h>
- #include <unistd.h>
- #include <stdlib.h>
- void
- run_status(void)
- {
- double pi = M_PI;
- double pisqrt;
- long i;
- while(1){
- pisqrt = sqrt(pi);
- }
- }
- int
- main (void)
- {
- run_status();
- exit(EXIT_SUCCESS);
- }
gcc run.c -o run -lm
./run&
运行:
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772300 42420 175356 0 31 5 138 22 14 0 0 99 0
1 0 0 772292 42420 175356 0 0 0 0 45 22 5 0 95 0
1 0 0 772284 42420 175356 0 0 0 0 276 15 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 298 12 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 273 11 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 278 16 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 276 14 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 275 16 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 284 14 99 1 0 0
1 0 0 772284 42420 175356 0 0 0 0 285 14 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 281 13 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 270 18 100 0 0 0
0 0 0 772292 42420 175356 0 0 0 0 51 28 4 0 96 0
0 0 0 772292 42420 175356 0 0 0 0 25 11 0 0 100 0
由于不断地在做算术运算,从上面可以看出:
1. r表示在运行队列中等待的进程数,上面的数据表示r=1,一直有进程在等待,
2. in表示每秒的中断数,包括时钟中断,运行队列中有等待的进程(看参数r的值),中断数in就上来了
3. us表示用户进程使用的cpu时间,随着r=1,用户的cpu占用时间直接达到了100%
4. id表示cpu的空闲时间,一开始的时候id很高,达到95%,后来程序开始跑,cpu一直处于繁忙状态(看参数r,us的值),id就一直为0,等程序终止,id就是上去了
实例二,大量的系统调用
本脚本会进入一个死循环,不断的执行cd命令,从而模拟大量系统调用的环境
测试脚本如下:
- #!/bin/bash
- while (true)
- do
- cd ;
- done
chmod +x loop.sh
./loop.sh
运行:
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772300 42500 175364 0 30 5 136 22 14 0 0 99 0
0 0 0 772300 42500 175364 0 0 0 0 27 14 0 0 100 0
1 0 0 772220 42500 175364 0 0 0 0 213 2482 6 70 24 0
1 0 0 772204 42500 175364 0 0 0 0 283 3298 8 92 0 0
1 0 0 772204 42500 175364 0 0 0 0 281 3343 5 95 0 0
1 0 0 772204 42500 175364 0 0 0 0 283 3381 5 95 0 0
1 0 0 772204 42500 175364 0 0 0 0 271 3362 8 92 0 0
1 0 0 772204 42508 175356 0 0 0 12 267 3359 8 92 0 0
0 0 0 772276 42508 175364 0 0 0 0 253 2883 8 76 16 0
0 0 0 772276 42508 175364 0 0 0 0 29 12 0 0 100 0
0 0 0 772276 42508 175364 0 0 0 0 39 18 0 0 100 0
随着程序不断调用cd命令,运行队列有等待的进程r(看参数r),每秒的中断数in(看参数in),下文切换的次数cs骤然提高(看参数cs),系统占用的cpu时间sy(看参数sy)也不断提高,cpu空闲时间id(看参数id)一直为0。
当程序终止的时候,r,in,cs,sy数据都下来了,id上去了,表示系统已经空闲下来了。
实例三,大量的io操作
a.
我们用dd命令,从/dev/zero读数据,写入到/tmp/data文件中,如下:
dd if=/dev/zero of=/tmp/data bs=1M count=1000
运行:
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772176 42564 175352 0 30 5 134 23 14 0 0 99 0
0 0 0 772176 42564 175352 0 0 0 0 35 15 0 1 99 0
1 0 0 687220 42564 257976 0 0 4 0 181 23 0 55 45 0
1 0 0 545356 42564 397552 0 0 12 142664 667 246 0 100 0 0
1 0 0 400276 42564 540208 0 0 0 147424 576 228 0 100 0 0
1 0 0 254948 42564 683216 0 0 0 173268 625 242 0 100 0 0
1 0 0 110364 42564 825140 0 0 0 136864 477 71 0 100 0 0
2 0 0 15400 11384 950396 0 0 0 140976 531 585 0 100 0 0
0 0 0 15028 11388 952236 0 0 12 199253 638 611 0 76 21 3
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 911284 11392 69752 0 30 5 143 23 14 0 0 99 0
0 0 0 911284 11392 69752 0 0 0 0 33 15 1 0 99 0
1 0 0 827704 11396 152232 0 0 60 0 98 27 0 24 74 2
1 0 0 304424 11396 667096 0 0 0 520604 1336 710 0 100 0 0
0 0 0 17564 11380 952288 0 0 8 417144 1166 874 0 97 3 0
0 0 0 17572 11380 952288 0 0 0 0 34 10 0 0 100 0
0 0 0 17572 11380 952288 0 0 0 0 38 19 0 0 100 0
root@debian6:~# dd if=/dev/zero of=/mnt/date1 bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 6.31404 s, 166 MB/s
root@debian6:~# dd if=/dev/zero of=/mnt/data1 bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 2.19338 s, 478 MB/s
1. bo写数据到磁盘的速率,bi是从磁盘读的速度
2. dd不断的向磁盘写入数据,所以bo的值会骤然提高,而cpu的wait数值也变高,说明由于大量的IO操作,系统的瓶径出现IO设备上
3. 由于对文件系统的写入操作,cache也从175352KB提高到了952236KB,又由于大量的写中断调用,in的值也从35提高到638,上下文切换cs的值从23到了611
b.
接下来我们还用dd命令,这回从/tmp/data文件读,写到/dev/null文件中,如下:
dd if=/tmp/test1 of=/dev/null bs=1M
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 15568 11444 972748 0 25 11 135 23 14 0 0 100 0
0 0 0 15568 11444 972760 0 0 0 0 16 13 0 0 100 0
1 1 0 14692 11444 973084 0 0 46396 0 432 687 0 13 57 30
1 1 0 14568 11444 973228 0 0 129152 0 1103 1917 0 22 0 78
1 1 0 18720 11444 968460 0 0 130432 0 1107 1982 0 25 0 75
1 1 0 18592 11444 968620 0 0 110720 0 950 1568 0 24 0 76
0 2 0 15908 11452 971440 0 0 58124 0 584 940 1 12 0 87
1 1 0 15304 11464 972408 0 0 90060 0 840 1410 1 20 0 79
0 1 0 18280 11464 969456 0 0 138368 0 1183 2138 0 27 0 73
0 1 0 13444 11464 974304 0 0 127744 0 1079 1972 0 19 0 81
0 1 0 16792 11456 970940 0 0 131712 0 1104 2075 0 21 0 79
0 1 0 17536 11464 970188 0 0 134400 68 1124 2146 0 11 0 89
0 1 0 15428 11464 972348 0 0 125056 0 1031 1975 0 11 0 89
1 0 0 17040 11448 970720 0 0 317696 0 2662 1100 0 60 0 40
1 0 0 18796 11448 968312 0 0 452224 0 3798 241 0 99 0 1
1 0 0 16668 11448 971124 0 0 457472 0 3832 236 0 100 0 0
root@debian6:~# dd if=/mnt/data1 of=/dev/null bs=1M
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 5.1614 s, 203 MB/s
1. dd不断的从/tmp/data磁盘文件中读取数据,所以bi的值会骤然变高,最后我们看到b(在等待io的进程)也由0变成了1甚至到2
2. dd读的时候,in中断数和cs上下文切换很高,还有就是等待IO所消耗的cpu时间wa相当高
3. 因此,这时的性能瓶颈在读上面,有程序在发生大量读的请求。
实例四:大量的占用内存
本程序会不断分配内存,直到系统崩溃
- #include <stdio.h>
- #include <string.h>
- #include <stdlib.h>
- int main (int argc, char *argv[])
- {
- void *ptr;
- int n = 0;
- while (1){
- ptr = malloc(0x100000);
- if (ptr == NULL)
- break;
- memset(ptr, 1, 0x100000);
- printf("malloced %d MB\n", ++n);
- }
- pause();
- }
gcc callmem.c -o callmem
./callmem
运行:
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 880944 70656 51692 0 0 125 13 27 35 0 2 97 1
0 0 0 880944 70656 51692 0 0 0 0 17 12 0 0 100 0
1 0 0 733344 70656 51692 0 0 0 0 259 339 2 52 46 0
1 0 0 312240 70656 51692 0 0 0 0 484 674 2 98 0 0
1 0 0 152776 70656 51692 0 0 0 0 417 469 0 100 0 0
0 2 0 12396 68868 45748 0 0 0 0 410 444 1 97 0 2
1 0 652 605960 60932 39120 0 908 0 908 141 130 0 34 0 66
0 0 524 903632 60932 39136 0 0 0 0 32 14 0 3 97 0
0 0 524 903632 60932 39136 0 0 0 0 13 8 0 0 100 0
0 0 524 903632 60932 39136 0 0 0 0 13 9 0 0 100 0
0 0 524 903632 60932 39136 32 0 32 0 14 12 0 0 99 1
0 0 524 903632 60932 39136 0 0 0 0 15 18 0 0 100 0
0 0 524 903632 60932 39140 0 0 0 0 26 8 0 0 100 0
0 0 524 903632 60932 39140 0 0 0 0 20 7 0 0 100 0
0 0 524 903632 60932 39140 0 0 0 0 18 9 0 0 100 0
0 0 524 903632 60932 39140 0 0 0 0 17 19 0 0 100 0
0 0 524 903632 60932 39140 0 0 0 0 17 12 0 0 100 0
注:我们看到cache迅速减少,而swpd迅速增加,这是因为系统为了分配给新的程序,而从cache(文件系统缓存)回收空间,当空间依然不足时,会用到swap空间.
而于此同时,si/so也会增加,尤其是so,而swap属于磁盘空间,所以bo也会增加
实例五:又一个大量分配内存例子
我们这个例子为了说明active/inactivte的作用,
源程序如下:
- #include <stdio.h>
- #include <string.h>
- #include <stdlib.h>
- #include <unistd.h>
- int
- main (int argc, char *argv[])
- {
- if (argc != 2)
- exit (0);
- size_t mb = strtoul(argv[1],NULL,0);
- size_t nbytes = mb * 0x100000;
- char *ptr = (char *) malloc(nbytes);
- if (ptr == NULL){
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- size_t i;
- const size_t stride = sysconf(_SC_PAGE_SIZE);
- for (i = 0;i < nbytes; i+= stride) {
- ptr[i] = 0;
- }
- printf("allocated %d mb\n", mb);
- pause();
- return 0;
- }
gcc act.c -o act -lrt
./act 100
运行:
root@debian6:~# vmstat -a 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free inact active si so bi bo in cs us sy id wa
0 0 0 951608 36652 31324 0 0 141 8 33 56 0 2 96 1
0 0 0 951608 36652 31324 0 0 0 0 19 8 0 0 100 0
1 0 0 868320 36652 114576 0 0 0 0 168 19 0 60 40 0
1 0 0 849100 36652 133836 0 0 0 0 47 18 0 11 89 0
0 0 0 849100 36652 133836 0 0 0 0 17 8 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 0 21 10 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 0 8 8 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 12 17 15 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 64 29 18 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 0 17 9 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 0 22 12 0 0 100 0
0 0 0 849100 36652 133836 0 0 0 0 14 9 0 0 100 0
注:程序运行时系统给它分配了100MB的内存,所以此时的active从31324kb变到了133836kb.
四、vmstat用法:
1. 查看系统已经fork了多少次
vmstat -f
1872 forks
注:这个数据是从/proc/stat中的processes字段里取得的.
2. 查看内存的active和inactive
vmstat -a
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free inact active si so bi bo in cs us sy id wa st
0 0 0 361952 80536 48396 5 140 255 441 1031 87 6 8 85 1 0
注:inact和active的数据来自于/proc/meminfo.
3. 查看内存使用的详细信息
root@debian6:~# vmstat -s
1034420 K total memory
82936 K used memory
31332 K active memory
36644 K inactive memory
951484 K free memory
6752 K buffer memory
48792 K swap cache
901112 K total swap
0 K used swap
901112 K free swap
112 non-nice user cpu ticks
0 nice user cpu ticks
922 system cpu ticks
55744 idle cpu ticks
412 IO-wait cpu ticks
4 IRQ cpu ticks
3 softirq cpu ticks
0 stolen cpu ticks
55352 pages paged in
3308 pages paged out
0 pages swapped in
0 pages swapped out
15183 interrupts
22959 CPU context switches
1345730699 boot time
1867 forks
注:这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat.
4. 查看磁盘的读/写
root@debian6:~# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
fd0 0 0 0 0 0 0 0 0 0 0
sda 2716 658 109318 16784 382 475 6872 7988 0 8
sdb 114 350 954 32 0 0 0 0 0 0
sr0 58 0 464 20 0 0 0 0 0 0
loop0 0 0 0 0 0 0 0 0 0 0
loop1 0 0 0 0 0 0 0 0 0 0
loop2 0 0 0 0 0 0 0 0 0 0
loop3 0 0 0 0 0 0 0 0 0 0
loop4 0 0 0 0 0 0 0 0 0 0
loop5 0 0 0 0 0 0 0 0 0 0
loop6 0 0 0 0 0 0 0 0 0 0
loop7 0 0 0 0 0 0 0 0 0 0
注:这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
查看/dev/sda1磁盘的读/写
root@debian6:~# vmstat -p /dev/sda1
sda1 reads read sectors writes requested writes
2564 107866 397 7120
注:这些信息主要来自于/proc/diskstats
reads:来自于这个分区的读的次数.
read sectors:来自于这个分区的读扇区的次数.
writes:来自于这个分区的写的次数.
requested writes:来自于这个分区的写请求次数.
参考文献:
http://home.lupaworld.com/home-space-uid-56821-do-blog-id-233122.html
注:这里面的很多实例都是从ckhitler哪里参考过来的,多写ckhitler兄。
转载于:https://blog.51cto.com/bmbwolf/971021
vmstat详细解读相关推荐
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- VINS-mono详细解读与实现
VINS-mono详细解读 VINS-mono详细解读 前言 Vins-mono是香港科技大学开源的一个VIO算法,https://github.com/HKUST-Aerial-Robotics/V ...
- R回归模型输出结果详细解读:summary、call、residuals、Coefficients、Assessing Model Fit
R回归模型输出结果详细解读:summary.call.residuals.Coefficients.Assessing Model Fit 目录 R回归模型输出结果详细解读:summary.call. ...
- MemCache超详细解读
MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高 ...
- CSS 详细解读定位属性 position 以及参数
Css 详细解读定位属性 position 以及参数 position 定位属性,是CSS中非常重要的属性.除了文档流布局,就是定位布局了.本来我对这个问题没有放在心上,毕竟写了这么多年的css,对p ...
- MemCache详细解读
MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高 ...
- 直播 | 腾讯天衍实验室张子恒:详细解读天衍实验室知识图谱对齐技术
「AI Drive」是由 PaperWeekly 和 biendata 共同发起的学术直播间,旨在帮助更多的青年学者宣传其最新科研成果.我们一直认为,单向地输出知识并不是一个最好的方式,而有效地反馈和 ...
- Madgwick算法详细解读
Madgwick算法详细解读 极品巧克力 前言 接上一篇文章<Google Cardboard的九轴融合算法>. Madgwick算法是另外一种九轴融合的方法,广泛应用在旋翼飞行器上,效果 ...
- Transformer详细解读与预测实例记录
文章目录 Transformer详细解读与预测实例记录 1.位置编码 1)输入部分: 2)位置编码部分: 2.多头注意力机制 1)基本注意力机制 2)transformer中的注意力 3.残差和Lay ...
最新文章
- 一些关于流量和带宽的知识
- WSS 扩展文件夹的属性--如何给文件夹添加扩展字段
- animation in Jquery used in ui5
- asynchttpclient 超时_DNF:95更新前还能免费获得一件超时空装备?但这个任务一定完成...
- pre1-flink理论-批处理与流处理+简单示例
- Python特殊函数
- eclipse安装java web插件
- 23种设计模式之门面模式
- python使用的编辑器_我用过的最好的python编辑器PyScripter
- 人工智能(10)---机器学习知识体系篇(初级篇,中级篇,高级篇)
- java.lang.Runtime.availableProcessors返回可用处理器的Java虚拟机的数量
- Java基础篇:重新温习不一样的数组
- 一文曝光字节跳动薪资职级,资深开发的收入你意想不到~
- 热核特征(heat kernel signature,HKS)简单解释(附可运行代码)
- Swift复数计算器
- python3 爬虫入门 简单爬取京东商品名称案例 详细笔记说明
- Tensorflow
- 编程求一个9位的整数,数字由1-9构成,每个数字只能出现一次。并且这个整数的前一位能被1整除,前两位能被2整除, ......以此类推,前九位能被9整除。
- 利用SWFTools工具将pdf转换成swf
- 模拟苹果验证服务器,[原创]苹果 gsa 服务器login 算法