(一)异常检测算法:Isolation Forest原理及其python代码应用
异常检测 (anomaly detection),又被称为“离群点检测” (outlier detection),是机器学习研究领域中跟现实紧密联系、有广泛应用需求的一类问题。但是,什么是异常,并没有标准答案,通常因具体应用场景而异。大多数文献对异常的定义虽然笼统,但其实暗含了认定“异常”的两个标准或者说假设:
- 异常数据跟样本中大多数数据不太一样。
- 异常数据在整体数据样本中占比比较小。
为了刻画异常数据的“不一样”,最直接的做法是利用各种统计的、距离的、密度的量化指标去描述数据样本跟其他样本的疏离程度。这是一类异常检测的方法,有时间我会整理。
而本篇介绍的算法孤立森林Isolation Forest (简称iForest)的想法要巧妙一些,它尝试直接去刻画数据的“疏离”(isolation)程度,而不借助其他量化指标。Isolation Forest 是无监督的算法,因为简单、高效,在学术界和工业界都有着不错的名声。
本篇博客先介绍iForest算法的原理,然后基于sklearn应用iForest算法,当然,当下最流行的Python异常检测工具库Python Outlier Detection(PyOD)我们也会提供一个简单的接口例子。
文章目录
- 一、算法介绍
- 1.1 iTree
- 1.1.1 训练过程
- 1.1.2 预测过程
- 1.2 iForest
- 1.3 算法应用
- 二、代码应用
- 2.1 sklearn:IsolationForest
- 2.2 PyOD:IsolationForest
- 参考文献:
一、算法介绍
1.1 iTree
1.1.1 训练过程
提到森林,自然少不了树,毕竟森林都是由树构成的,看iForest前,我们先来看看Isolation Tree(简称iTree)是怎么构成的,iTree是一种随机二叉树,每个节点要么有两个孩子,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
随机选择一个属性Attr;
随机选择该属性的一个值Value;
根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子;
然后递归的构造左女儿和右女儿,直到满足以下条件:
- 传入的数据集只有一条记录或者多条一样的记录;
- 树的高度达到了限定高度
下图是iTree的训练过程
1.1.2 预测过程
iTree构建好了后,就可以对数据进行预测,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点。
这里解释下,为什么异常点会很快被划分到叶子节点。
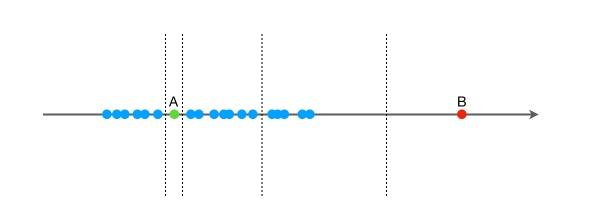
我们先用一个简单的例子来说明iForest的基本想法。假设现在有一组一维数据(如下图所示,可以认为是一个特征),我们要对这组数据进行随机切分,希望可以把点 AAA 和点 BBB 单独切分出来。具体的,我们先在特征的最大值和最小值之间随机选择一个值 xxx,然后按照 <x<x<x 和 >=x>=x>=x 可以把数据分成左右两组。然后,在这两组数据中分别重复这个步骤,直到数据不可再分。显然,点 BBB 跟其他数据比较疏离,可能用很少的次数就可以把它切分出来(这里涉及到停止条件,即叶子节点的样本只有1个了,已经不能再分了);点 AAA 跟其他数据点聚在一起,可能需要更多的次数才能把它切分出来。
我们把数据从一维扩展到两维。同样的,我们沿着两个坐标轴进行随机切分,尝试把下图中的点A′A'A′和点B′B'B′分别切分出来。我们先随机选择一个特征维度,在这个特征的最大值和最小值之间随机选择一个值,按照跟特征值的大小关系将数据进行左右切分。然后,在左右两组数据中,我们重复上述步骤,再随机的按某个特征维度的取值把数据进行细分,直到无法细分,即:只剩下一个数据点,或者剩下的数据全部相同。跟先前的例子类似,直观上,点B′B'B′跟其他数据点比较疏离,可能只需要很少的几次操作就可以将它细分出来;点A′A'A′需要的切分次数可能会更多一些。
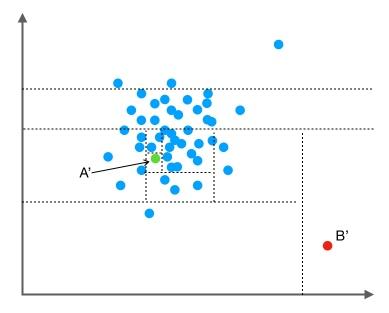
以上,就可以知道iForest算法的初衷了。
我们继续回到iTree的预测过程中:假设,要预测的样本为xxx, iTree 的训练样本中同样落在 xxx 所在叶子节点的样本数为 T.sizeT.sizeT.size,则数据 xxx 在这棵 iTree 上的路径长度 h(x)h(x)h(x),可以用下面这个公式计算xxx在 iTree 中的路径长度:
h(x)=e+C(T.size)h(x)=e+C(T.size) h(x)=e+C(T.size)
公式中,eee 表示数据 xxx 从 iTree 的根节点到叶节点过程中经过的边的数目,C(T.size)C(T.size)C(T.size) 可以认为是一个修正值,它表示在一棵用 T.sizeT.sizeT.size 条样本数据构建的二叉树的平均路径长度。一般的,C(n)C(n)C(n) 的计算公式如下:
c(n)=2H(n−1)−(2(n−1)n)c(n) = 2H(n − 1) − (\frac{2(n − 1)}{n}) c(n)=2H(n−1)−(n2(n−1))
其中 H(k)=ln(k)+ξH(k) = ln(k) + \xiH(k)=ln(k)+ξ,ξ\xiξ为欧拉常数。
假设训练一棵iTree的样本数目为ψ\psiψ,则xxx在这颗树iTree的异常指数为
s(x,ψ)=2(−h(x)c(ψ))s(x,\psi) = 2^{(-\frac{h(x)}{c(\psi)})} s(x,ψ)=2(−c(ψ)h(x))
从异常分值的公式看,s(x,ψ)s(x,\psi)s(x,ψ)取值范围为[0,1][0,1][0,1],可以看到,如果h(x)h(x)h(x)越小,则s(x,ψ)s(x,\psi)s(x,ψ)越接近1,如果h(x)h(x)h(x)越大,则s(x,ψ)s(x,\psi)s(x,ψ)越接近0.5.
如果数据 xxx 在多棵 iTree 中的平均路径长度越短,得分越接近 1,表明数据 xxx 越异常;如果数据 xxx 在多棵 iTree 中的平均路径长度越长,得分越接近 0,表示数据 xxx 越正常;如果数据 xxx 在多棵 iTree 中的平均路径长度接近整体均值,则打分会在 0.5 附近。
1.2 iForest
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含nnn条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一部分数据集去构造每一棵树,保证不同树之间的差异性,采样的数据量ψ\psiψ不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,明确越大还会造成计算时间的上的浪费。这是论文中的原图:
左边是原始数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之后,异常样本和正常样本可以明显的分开。
除了限制采样大小以外,还要给每棵iTree设置最大高度l=ceiling(log2ψ)l=ceiling(log_2^\psi)l=ceiling(log2ψ),这是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高先看iForest的伪代码:
当然,iForest是由多颗iTree构成的,自然iForest异常分值的公式也需要改变:
s(x,ψ)=2(−E(h(x))c(ψ))s(x,\psi) = 2^{(-\frac{E(h(x))}{c(\psi)})} s(x,ψ)=2(−c(ψ)E(h(x)))
公式中,E(h(x))E(h(x))E(h(x))表示数据 xxx 在多棵 iTree 的路径长度的均值,ψ\psiψ 表示单棵 iTree 的训练样本的样本数,c(ψ)c(\psi)c(ψ) 表示用ψ\psiψ条数据构建的二叉树的平均路径长度,它在这里主要用来做归一化。
从异常分值的公式看,如果数据 xxx 在多棵 iTree 中的平均路径长度越短,得分越接近 1,表明数据 xxx 越异常;如果数据 xxx 在多棵 iTree 中的平均路径长度越长,得分越接近 0,表示数据 xxx 越正常;如果数据 xxx 在多棵 iTree 中的平均路径长度接近整体均值,则打分会在 0.5 附近。
1.3 算法应用
iForest算法主要有两个参数:一个是二叉树的个数;另一个是训练单棵 iTree 时候抽取样本的数目。实验表明,当设定为 100 棵树,抽样样本数为 256 条的时候,iForest在大多数情况下就已经可以取得不错的效果。这也体现了算法的简单、高效。
Isolation Forest 是无监督的异常检测算法,在实际应用时,并不需要标签。需要注意的是:(1)如果训练样本中异常样本的比例比较高,违背了先前提到的异常检测的基本假设,可能最终的效果会受影响;(2)异常检测跟具体的应用场景紧密相关,算法检测出的“异常”不一定是我们实际想要的。比如,在识别虚假交易时,异常的交易未必就是虚假的交易。所以,在特征选择时,可能需要过滤不太相关的特征,以免识别出一些不太相关的“异常”。
二、代码应用
2.1 sklearn:IsolationForest
sklearn提供了ensemble.IsolationForest模块实现了Isolation Forest算法。
函数体如下:
class sklearn.ensemble.IsolationForest(n_estimators=100, max_samples=’auto’, contamination=’legacy’, max_features=1.0, bootstrap=False, n_jobs=None, behaviour=’old’, random_state=None, verbose=0)
几个主要参数介绍:
- n_estimators : int, optional (default=100) 森林中树的颗数
- max_samples : int or float, optional (default=”auto”) 对每棵树,样本个数或比例
- contamination : float in (0., 0.5), optional (default=0.1) 这是最关键的参数,用户设置样本中异常点的比例
- max_features : int or float, optional (default=1.0) 对每棵树,特征个数或比例
几个主要函数介绍:
- fit(X): Fit estimator.(无监督)
- predict(X):返回值:+1 表示正常样本, -1表示异常样本。
- decision_function(X):返回样本的异常评分。 值越小表示越有可能是异常样本。
下面是一个完整的代码,来自参考文献4。
#!/usr/bin/python
# -*- coding:utf-8 -*-import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from scipy import statsrng = np.random.RandomState(42)# 构造训练样本
n_samples = 200 #样本总数
outliers_fraction = 0.25 #异常样本比例
n_inliers = int((1. - outliers_fraction) * n_samples)
n_outliers = int(outliers_fraction * n_samples)X = 0.3 * rng.randn(n_inliers // 2, 2)
X_train = np.r_[X + 2, X - 2] #正常样本
X_train = np.r_[X_train, np.random.uniform(low=-6, high=6, size=(n_outliers, 2))] #正常样本加上异常样本# fit the model
clf = IsolationForest(max_samples=n_samples, random_state=rng, contamination=outliers_fraction)
clf.fit(X_train)
# y_pred_train = clf.predict(X_train)
scores_pred = clf.decision_function(X_train)
threshold = stats.scoreatpercentile(scores_pred, 100 * outliers_fraction) #根据训练样本中异常样本比例,得到阈值,用于绘图# plot the line, the samples, and the nearest vectors to the plane
xx, yy = np.meshgrid(np.linspace(-7, 7, 50), np.linspace(-7, 7, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.title("IsolationForest")
# plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), threshold, 7), cmap=plt.cm.Blues_r) #绘制异常点区域,值从最小的到阈值的那部分
a = plt.contour(xx, yy, Z, levels=[threshold], linewidths=2, colors='red') #绘制异常点区域和正常点区域的边界
plt.contourf(xx, yy, Z, levels=[threshold, Z.max()], colors='palevioletred') #绘制正常点区域,值从阈值到最大的那部分b = plt.scatter(X_train[:-n_outliers, 0], X_train[:-n_outliers, 1], c='white',s=20, edgecolor='k')
c = plt.scatter(X_train[-n_outliers:, 0], X_train[-n_outliers:, 1], c='black',s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-7, 7))
plt.ylim((-7, 7))
plt.legend([a.collections[0], b, c],['learned decision function', 'true inliers', 'true outliers'],loc="upper left")
plt.show()
2.2 PyOD:IsolationForest
在PyOD的官方github中有专门的例子,链接如下。
参考文献:
【1】F. T. Liu, K. M. Ting and Z. H. Zhou,Isolation-based Anomaly Detection,TKDD,2011
【2】机器学习-异常检测算法(一):Isolation Forest
【3】异常检测算法–Isolation Forest
【4】异常检测(二)——IsolationForest
(一)异常检测算法:Isolation Forest原理及其python代码应用相关推荐
- 异常检测算法--Isolation Forest
异常检测算法--Isolation Forest 参考文章: (1)异常检测算法--Isolation Forest (2)https://www.cnblogs.com/fengfenggirl/p ...
- 白话异常检测算法Isolation Forest
前言 好久没讲算法了,今天分享一个异常点检测算法Isolation Forest.之前也是没听说过这个算法,中文名叫孤立森林,听客户讲了就顺便查了下这个算法的论文,感觉还是非常有用滴. 论文地址:ht ...
- 【异常检测】Isolation forest 的spark 分布式实现
[异常检测]Isolation forest 的spark 分布式实现 参考文章: (1)[异常检测]Isolation forest 的spark 分布式实现 (2)https://www.cnbl ...
- Python机器学习笔记:异常点检测算法——Isolation Forest
Python机器学习笔记:异常点检测算法--Isolation Forest 参考文章: (1)Python机器学习笔记:异常点检测算法--Isolation Forest (2)https://ww ...
- 【异常检测】isolation forest
一.算法原理 1.1 适用场景 1.孤立森林算法主要针对的是连续型结构化数据中的异常点. 2.异常数据占总样本量的比例很小. 3.异常点的特征值与正常点的差异很大. 为了刻画异常数据的"不一 ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- 四类异常检测算法综述:Isolation Forest、LOF、PCA及DAGMM
异常检测(Anomaly detection)问题是机器学习算法的一个常见应用.这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题.本文总结了四种机器 ...
- 孤立森林(isolation):一个最频繁使用的异常检测算法
孤立森林(isolation Forest)算法,2008年由刘飞.周志华等提出,算法不借助类似距离.密度等指标去描述样本与其他样本的差异,而是直接去刻画所谓的疏离程度(isolation),因此该算 ...
- 孤立森林异常检测算法原理和实战(附代码)
孤立森林(isolation Forest)算法,2008年由刘飞.周志华等提出,算法不借助类似距离.密度等指标去描述样本与其他样本的差异,而是直接去刻画所谓的疏离程度(isolation),因此该算 ...
最新文章
- ASP.NET页面之间传递值的几种方式
- wpf prism IRegionManager 和IRegionViewRegistry
- 服务器升级中不能修改,windows10下更新服务器为何改不了了
- CodeForces - 165E Compatible Numbers(SOSdp)
- spark java8 scala_在 Ubuntu16.04 中搭建 Spark 单机开发环境 (JDK + Scala + Spark)
- 管理员信息模块php,管理员模块功能代码
- Jmeter系列之接口自动化实战
- WPF跨程序集共享样式(跨程序集隔离样式和代码)
- LCP 13. 寻宝
- One Switch 让你的 Mac 也能拥有控制中心
- AttributeError lxml.etree Element object has no attribute get_attribute
- 关于DNF的多媒体包NPK文件的那些事儿(7) - IMGV5
- 返回上一页,ajax读出来的数据丢失。
- 主流浏览器发展史及其内核初探
- 青龙面板搭建及记录踩过的坑
- 作业二:词云制作 使用软件wordart
- Linux 计算机网络从零到一开始构建 必看
- Linux 命令学习 -重置root密码
- 数据库中,把角色的权限授权给用户总是报错,角色名附近有语法错误的原因
- Qt入门开发__贪吃蛇小游戏
热门文章
- android 获取alertdialog的view,Android AlertDialog使用
- python json转字符串_在python中将json转换为字符串
- Qt Quik是什么?
- 做副业赚钱,这几个热门自媒体平台收益超多
- SF-40/385/4PY智能浪涌 浪涌后备保护器SCB 智能浪涌 浪涌保护器
- C++基础编程题(50)求一元二次方程式的实根,如果方程没有实根,则输出有关警告信息。
- r53500u和i58265u哪个好
- 联想扬天V15(i5 8265U/8GB/256GB/MX110)电脑 Hackintosh 黑苹果efi引导文件
- python discuz论坛帖子_Python + Selenium 入门之Discuz论坛实例
- 多线程一,什么是多线程,创建多线程的几种方式