python中令人惊艳的小众数据科学库
Python是门很神奇的语言,历经时间和实践检验,受到开发者和数据科学家一致好评,目前已经是全世界发展最好的编程语言之一。简单易用,完整而庞大的第三方库生态圈,使得Python成为编程小白和高级工程师的首选。
在本文中,我们会分享不同于市面上的python数据科学库(如numpy、padnas、scikit-learn、matplotlib等),尽管这些库很棒,但是其他还有一些不为人知,但同样优秀的库需要我们去探索去学习。
1. Wget
从网络上获取数据被认为是数据科学家的必备基本技能,而Wget是一套非交互的基于命令行的文件下载库。ta支持HTTP、HTTPS和FTP协议,也支持使用IP代理。因为ta是非交互的,即使用户未登录,ta也可以在后台运行。所以下次如果你想从网络上下载一个页面,Wget可以帮到你哦。
安装
pip isntall wget
用例
import wgeturl = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'filename = wget.download(url)
Run and output
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'
2. Pendulum
对于大多数python用户来说处理时期(时间)数据是一件令人抓狂的事情,好在Pendulum专为你而来。它是python内置时间类的良好备选方案,更多内容可查看官方文档 https://pendulum.eustace.io/docs/
安装
pip install pendulum
用例
import pendulumdt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
Run and output
3
3.imbalanced-learn
常见的机器学习分类算法都默认输入的数据是均衡数据,即假设训练集数据有A和B两个类别,A和B数据量大体相当。如果A和B数据量差别巨大,那么训练的效果会不理想。在实际收集和整理的数据,其实绝大多数是非均衡数据,这对于机器学习分类算法真的是个很大的问题。好在有imbalanced-learn库可以很好的解决这个问题。该库兼容scikit-learn,并且是作为scikit-learn-contrib项目的一部分。当你再遇到非均衡数据,记得试试它哦!
安装
pip install -U imbalanced-learn
#或者
conda install -c conda-forge imbalanced-learn
该库有高质量的文档 http://imbalanced-learn.org/en/stable,目前该库支持scikit-learn、keras、tensorflow库
4. FlashText
在NLP任务重经常会遇到替换指代同一个意思的多个词语,或者从句子中抽取关键词。通常我们一般的做法是使用正则表达式来完成这些脏活累活,但如果要操作的词语数量达到几千上万,使用正则这种方法就会变得很麻烦。FlashText库是基于FlashText算法,该库的最强大之处在于程序运行时间不受操作词语数量影响,即运行时间与操作的词汇数量无关。 因此特别适合应用到 python文本分析 中去。
4.1 安装
pip install flashtext
4.2 用例
4.2.1 抽取关键词
我们都知道 Big Apple 指代纽约。所以抽取纽约这个城市词时候,我们要考虑到相同意思的不同词语。
from flashtext import KeywordProcessor#设置关键词处理器
keyword_processor = KeywordProcessor()#设置关键词及其近义词
keyword_processor.add_keyword('Big Apple', 'New York') #遇到Big Apple就会识别为New York
keyword_processor.add_keyword('Bay Area')keywords_found = keyword_processor.extract_keywords("I love Big Apple and Bay Area.")keywords_found
Run and output
['New York', 'Bay Area']
4.2.2 替换关键词
我们也经常需要将原始文本进行处理,比如将New Delhi(新德里)替换为NCR region(国家首都区)
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
Run and output
'I love New York and NCR region.'
想了解更多,请查看FlastText官方文档
https://flashtext.readthedocs.io/en/latest/#
5. Fuzzywuzzy
这个库的名字就有点怪,但ta拥有强大的字符串匹配功能。可以轻松实现字符串比较比率(comparison ratios),分词比率(token ratios)等操作。它还可以方便地匹配保存在不同数据库中的记录。
安装
pip install fuzzywuzzy
用例
from fuzzywuzzy import fuzz
from fuzzywuzzy import process # Simple Ratio print(fuzz.ratio("this is a test", "this is a test!")) # Partial Ratio print(fuzz.partial_ratio("this is a test", "this is a test!")) Run and output!
97
100
更多有趣的例子可见 fuzzywuzzy库github账号 https://github.com/seatgeek/fuzzywuzzy
6.PyFlux/PyFTS.
在机器学习领域中经常遇到时间序列分析这种问题。PyFlux是专门为解决时间序列问题而开发的python库。这个库提供了很多现代时间序列算法,单不仅仅限于ARIMA、GARCH和VAR这三种模型。简而言之,PyFlux为我们分析时间序列数据提供了可能,你值得拥有。
安装
pip install pyflux
PyFlux用例可查看该库的文档 https://pyflux.readthedocs.io/en/latest/index.html
类似的时间序列库还有PyFTS, 教程链接
https://towardsdatascience.com/a-short-tutorial-on-fuzzy-time-series-dcc6d4eb1b15
文档链接
https://pyfts.github.io/pyFTS/.
7.Ipyvolume
数据科学中一个重要的部分就是分析结果的展示与交流,而良好的视觉传达是很有优势的。IPyvolume是3D可视化库,可以以最小的初始化设置就能在jupyter notebook中使用。做一个恰当的类比:matplotlib的imshow是2d数组,而IPyvolume的volshow是3d数组。
安装
pip install ipyvolume
#或者
conda install -c conda-forge ipyvolume
用例
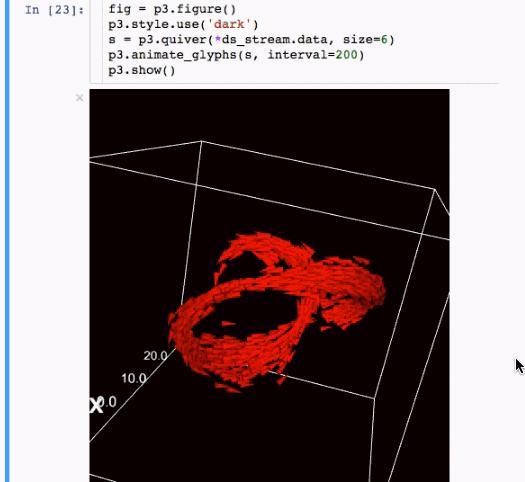
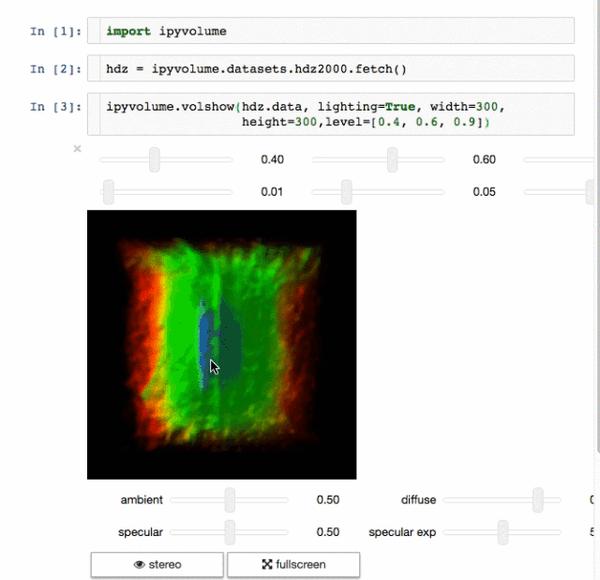
8. Dash
Dash是用来为开发web应用的高生产率工具库,该库基于Flask、Plotly.js和React.js,不需要懂javascript只用python就能让我们制作出美美的的UI元素,如下来列表、滑动条和图表。这些应用可以在浏览器中渲染,具体文档可查看 https://dash.plot.ly/
安装
pip install dash==0.29.0
pip install dash-html-components==0.13.2 #Dash库的HTML组件
pip install dash-core-components==0.36.0 #Dash库核心组件
pip install dash-table==3.1.3 #交互数据库表单(新)
用例
下面是一个下拉式菜单,可以选择股票代码的pandas Dataframe数据类型作为输入,渲染成动态交互的折线图
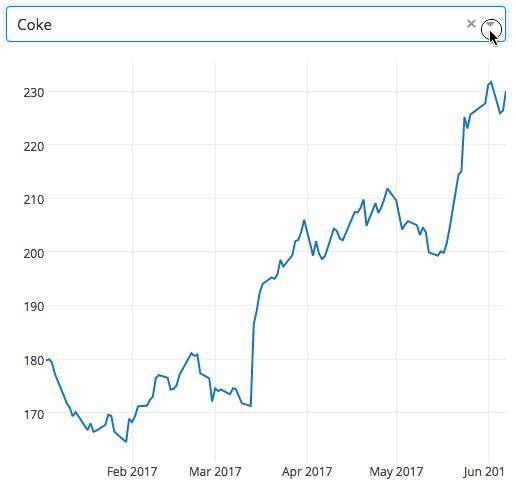
9. Gym
Gym是一个可以开发强化学习算法的工具包。 它兼容数值计算库,如TensorFlow或Theano。我们可以据此设计出强化学习算法,这些环境(测试问题)有公开的接口,允许我们写出通用的算法。
安装
pip install gym
用例
比如研究探月飞行器着落月球,科学家需要考虑如何才能准确着落到某个位置,并且保证安全降落。这就需要用到gym来做强化学习,学到规律
转载于:https://www.cnblogs.com/qingdeng123/p/10574619.html
python中令人惊艳的小众数据科学库相关推荐
- Python中非常有用的三个数据科学库
如果你从事数据科学研究有一段时间了,那么pandas, scikit-learn seaborn和matplotlib这些库你都应该非常的熟悉. 如果您想要扩展您的视野,学习一些更少见但同样有用的库. ...
- 【AI训练新手记:如何通过ChatGPT生成令人惊艳的文案!】
[我]:我是一名Youtuber,工作内容是写吸引人的youtube脚本,并拍摄上传,我的领域是技术型频道,请你告诉我10个chatgpt相关的吸引人的选题 [ChatGPT]:当然,下面是10个有关 ...
- bash 判断 os 版本_专家:鸿蒙OS初登手机令人惊艳,但全面商用至少还要2年
鸿蒙 OS 迈入成熟,第一部正式搭载的手机是华为 P50? 华为手机销量持续下滑,鸿蒙现在登陆手机是个坏消息吗? 专家:鸿蒙 OS 初登手机令人惊艳,但全面商用至少还要 2 年 即使鸿蒙(Harmon ...
- iPad 上有哪些实用得令人惊艳的 App?
http://www.zhihu.com/question/22678622 宋玖,俗世一粒微尘! 陈广兴.OPEN曹.吕归尘 等人赞同 ipad上没有自带的计算机吧 这个就是个计算器,而且它厉害在于 ...
- b是python文件二进制打开_如何在Python中打开和显示原始二进制数据?
'rb'模式允许您从Python中的文件读取原始二进制数据:with open(filename, 'rb') as file: raw_binary_data = file.read() type( ...
- python读取json数据格式问题_浅谈Python中的异常和JSON读写数据的实现
异常可以防止出现一些不友好的信息返回给用户,有助于提升程序的可用性,在java中通过try ... catch ... finally来处理异常,在Python中通过try ... except .. ...
- 网友鸿蒙谷歌的Android,华为鸿蒙OS已经确认更名?新名字更加令人惊艳!网友:过目难忘...
原标题:华为鸿蒙OS已经确认更名?新名字更加令人惊艳!网友:过目难忘 众所周知,在移动端的主流系统,目前就只有Android和iOS两大系统,但是无一例外的Android和iOS都是美国企业的产品,但 ...
- Python中通过索引名称提取数据loc()函数Python中通过行和列下标提取数据iloc()函数
[小白从小学Python.C.Java] [Python全国计算机等级考试] [Python数据分析考试必会题] ● 标题与摘要 Python中通过索引名称提取数据 loc()函数 Python中通过 ...
- 在python中创建Excel文件并写入数据
来源:<在python中创建Excel文件并写入数据> python中的包xlwt和xlsxwriter都是比较方便创建excel文件并写入数据的. xlwt中: 通过xlwt.Workb ...
最新文章
- QLattice:你不知道的新的机器学习模型
- Windows Phone 8开发环境搭建介绍
- uni-app文档需要注意细节点
- Python sqlalchemy orm 多对多外键关联
- Java实现文件夹打包
- js获取session_学习后端鉴权系列: 基于Cookie, Session认证
- 老题新理解-在话winform之间的窗体传值
- 函数开始处的MOV EDI, EDI的作用
- ASEMI低压差线性稳压器AMS1117详解
- Ubuntu16安装搜狗拼音输入法
- java 繁体转简体_如何用java将繁体字转为简体字
- 怎么获得MIUI12系统的root权限
- FLAGS 作用及用法
- 游戏语音SDK解决回声消除的方案
- [圣诞大礼]Macintosh苹果机精品游戏合集
- link js重构心得
- Pads Logic 、AD转Orcad
- php博饼,2018博饼html5
- 在哪把iphone的计算机,iphone备份在哪?iPhone备份方法
- creator 跳跃弧线_(转)CocosCreator零基础制作游戏《极限跳跃》一、游戏分析