spearman相关性_Spearman的相关性及其在机器学习中的意义
spearman相关性
This article is about correlation and its implication in the machine learning. In my previous article, I have discussed Pearson’s correlation coefficient and later we have written a code to show the usefulness of finding Pearson’s correlation coefficient. Well, you must be thinking that why is there a need to use Spearman's correlation when we already have Pearson’s correlation to find out the correlation between the feature values and the target values? The answer is that "Pearson’s correlation works fine only with the linear relationships whereas Spearman's correlation works well even with the non-linear relationships".
本文介绍了相关性及其在机器学习中的含义。 在上一篇文章中,我讨论了Pearson的相关系数 ,后来我们编写了代码以显示找到Pearson的相关系数的有用性。 好吧,您必须考虑一下, 当我们已经有了Pearson的相关性以找出特征值与目标值之间的相关性时 , 为什么需要使用Spearman的相关性? 答案是“皮尔逊相关仅适用于线性关系,而斯皮尔曼相关甚至适用于非线性关系” 。
Another advantage of using Spearman’s correlation is that since it uses ranks to find the correlation values, therefore, this correlation well suited for continuous as well as discrete datasets.
使用Spearman相关性的另一个优点是,由于它使用秩来查找相关值,因此,此相关性非常适合于连续数据集和离散数据集。

Image source: https://digensia.files.wordpress.com/2012/04/s1.png
图片来源: https : //digensia.files.wordpress.com/2012/04/s1.png
Here, the the value of dican be calculated as X-Y where X= feature values and Y= target values.
在这里,dican的值可以计算为XY ,其中X =特征值 , Y =目标值 。
The Dataset used can be downloaded from here: headbrain4.CSV
可以从此处下载使用的数据集: headbrain4.CSV
Since we have used the continuous dataset. i.e. the same dataset used for Pearson’s correlation, you will not be able to observe much of a difference between the Pearson and Spearman correlation, you can download any discrete dataset and you’ll see the difference.
由于我们使用了连续数据集。 也就是说,与用于Pearson相关的数据集相同,您将无法观察到Pearson和Spearman相关之间的很大差异,您可以下载任何离散的数据集,然后看到差异。
So now, let us see how we can use Spearman's correlation in our machine learning program using python programming:
现在,让我们看看如何使用python编程在我们的机器学习程序中使用Spearman的相关性:
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 29 22:21:12 2018
@author: Raunak Goswami
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#reading the data
"""
here the directory of my code and the headbrain4.csv
file is same make sure both the files are stored in
the same folder or directory
"""
data=pd.read_csv('headbrain4.csv')
#this will show the first five records of the whole data
data.head()
#this will create a variable w which has the feature values i.e Gender
w=data.iloc[:,0:1].values
#this will create a variable x which has the feature values i.e Age Range
y=data.iloc[:,1:2].values
#this will create a variable x which has the feature values i.e head size
x=data.iloc[:,2:3].values
#this will create a variable y which has the target value i.e brain weight
z=data.iloc[:,3:4].values
print(round(data['Gender'].corr(data['Brain Weight(grams)'],method='spearman')))
plt.scatter(w,z,c='red')
plt.title('scattered graph for Spearman correlation between Gender and brainweight' )
plt.xlabel('Gender')
plt.ylabel('brain weight')
plt.show()
print(round(data['Age Range'].corr(data['Brain Weight(grams)'],method='spearman')))
plt.scatter(x,z,c='red')
plt.title('scattered graph for Spearman correlation between age and brainweight' )
plt.xlabel('age range')
plt.ylabel('brain weight')
plt.show()
print(round((data['Head Size(cm^3)'].corr(data['Brain Weight(grams)'],method='spearman'))))
plt.scatter(x,z,c='red')
plt.title('scattered graph for Spearman correlation between head size and brainweight' )
plt.xlabel('head size')
plt.ylabel('brain weight')
plt.show()
data.info()
data['Head Size(cm^3)'].corr(data['Brain Weight(grams)'])
k1=data.corr(method='spearman')
print("The table for all possible values of spearman's coeffecients is as follows")
print(k1)
After you run your code in Spyder tool provided by anaconda distribution just go to your variable explorer and search for the variable named as k1 and double-click to see the values in that variable and you’ll see something like this:
在anaconda发行版提供的Spyder工具中运行代码后,转到变量资源管理器并搜索名为k1的变量,然后双击以查看该变量中的值,您将看到类似以下内容:
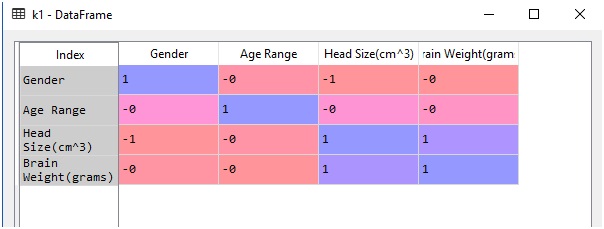
Here,1 signifies a perfect correlation,0 is for no correlation and -1 signifies a negative correlation.
此处,1表示完全相关,0表示没有相关,-1表示负相关。
As you look carefully, you will see that the value of the correlation between brain weight and head size is always 1. If you remember were getting a similar value of correlation in Pearson’s correlation
仔细观察,您会发现大脑重量和头部大小之间的相关性值始终为1。如果您记得在皮尔森相关性中获得了相似的相关性值
Now, just go to the ipython console you will see some self-explanatory scattered graphs, in case you are having any trouble understanding those graphs just have a look at my previous article about Pearson’s correlation and its implication in machine learning and you’ll get to know.
现在,只要转到ipython控制台,您将看到一些不言自明的分散图,以防万一您无法理解这些图,请看一下我以前关于Pearson的相关性及其在机器学习中的含义的文章,您将获得要知道。
This was all for today guys hope you liked it if you have any queries just drop a comment below and I would be happy to help you.
今天,这就是全部,如果您有任何疑问,希望您喜欢它,只需在下面发表评论,我们将竭诚为您服务。
翻译自: https://www.includehelp.com/ml-ai/spearmans-correlation-and-its-implication-in-machine-learning.aspx
spearman相关性
spearman相关性_Spearman的相关性及其在机器学习中的意义相关推荐
- 皮尔逊相关性_皮尔逊的相关性及其在机器学习中的意义
皮尔逊相关性 Today we would be using a statistical concept i.e. Pearson's correlation to help us understan ...
- 相关性分析热点图_高分文章中物种与代谢物相关性热图是怎么画的?
测序行业的蓬勃发展,带来微生物组学日新月异的变化.目前,单一组学的文章不断"贬值",前沿研究的目光从单一组学逐步拓展至多组学对贯穿分析,即结合多个组学的分析角度,从多个层面阐述生物 ...
- R多变量相关性分析及相关性可视化
R多变量相关性分析及相关性可视化 目录 R多变量相关性分析及相关性可视化 多变量相关性计算
- Python绘制传统相关性矩阵/下三角相关性矩阵/重点相关性矩阵
数据科学最重要的技能之一就是数据可视化,在数据建模过程中,我们比较关心数据之间的相关性,而观察数据相关性我们使用最多的技能之一就是相关性矩阵.数据相关性矩阵可以让我们对数据之间的关联关系有更为直观的理 ...
- 业界大盘点!文本相关性在搜广推三大场景中的应用!
卷友们好,我是rumor. NLP最赚钱的落地莫属搜索.广告.推荐三大场景了,今天我们就向钱看,来了解下作为NLP算法工程师,怎样在互联网最主要的三个场景里发光发热,同时蹭得一份业绩. 搜广推这三个场 ...
- 业界大盘点!文本相关性在搜广推三大场景中的应用
卷友们好,我是rumor. NLP最赚钱的落地莫属搜索.广告.推荐三大场景了,今天我们就向钱看,来了解下作为NLP算法工程师,怎样在互联网最主要的三个场景里发光发热,同时蹭得一份业绩. 注:欢迎初入N ...
- R语言相关性分析和相关性分析可视化常用方法汇总
本次,介绍一下相关性分析以及相关性分析可视化常用方法. 0. 相关数据 library(learnasreml) library(tidyverse) data(fm) str(fm)dd = fm ...
- R语言相关性分析函数和相关性检验函数
目录 1. 相关性分析函数 2. 相关性检验函数 1. 相关性分析函数 我们用cor函数来计算两组数据的相关系数,结果越靠近1,正相关性越强,越靠近-1,负相关性越强 > cor(state.x ...
- 机器学习集群_机器学习中的多合一集群技术在无监督学习中应该了解
机器学习集群 Clustering algorithms are a powerful technique for machine learning on unsupervised data. The ...
最新文章
- Tomcat:Connection reset by peer: socket write error
- 腻害了!同事写了个隐藏 Bug,我排查了 3 天才解决问题!
- 构建局域网的病毒防护体系
- 多个iis的进程w3wp
- Tomcat5.5 配置mysql数据库连接池
- 廖雪峰Python教程-笔记
- mysql不要放docker,Docker从入门到放弃
- Meteor:用户账号管理添加密码和微博weibo账号系统支持
- Android9.0编译系统原理
- 爱创课堂每日一题第四十八天- html5有哪些新特性、移除了那些元素?
- web开发中多线程下载文件
- 一键跳转添加QQ好友 点击链接直接跳转到QQ好友页面如何实现
- python拟合泊松分布_Python Numpy泊松分布
- 制作的excel表格如何放到微信公众平台文章中?
- 浙江独立学院计算机专业排名2015,2018中国独立学院排行榜发布,浙江这所独立学院独占鳌头!...
- Can't change container ID of fragment
- 阿里云服务器linux切换到root 用户,修改root密码
- 免费集装箱号识别API免费集装箱信息识别,中国人工智能企业CIMCAI集装箱识别云服务全球4千企业用户,中国人工智能企业智慧港航
- python中获取职位信息
- Apache Flink Meetup 8.7 深圳站,企业实践 + 1.14 新特性预览