特征工程之特征缩放特征编码
机器学习入门系列(2)–如何构建一个完整的机器学习项目,第五篇!
该系列的前四篇文章:
- 机器学习入门系列(2)–如何构建一个完整的机器学习项目(一)
- 机器学习数据集的获取和测试集的构建方法
- 特征工程之数据预处理(上)
- 特征工程之数据预处理(下)
本篇文章会继续介绍特征工程的内容,这次会介绍特征缩放和特征编码,前者主要是归一化和正则化,用于消除量纲关系的影响,后者包括了序号编码、独热编码等,主要是处理类别型、文本型以及连续型特征。
3.2 特征缩放
特征缩放主要分为两种方法,归一化和正则化。
3.2.1 归一化
- 归一化(Normalization),也称为标准化,这里不仅仅是对特征,实际上对于原始数据也可以进行归一化处理,它是将特征(或者数据)都缩放到一个指定的大致相同的数值区间内。
- 归一化的两个原因:
- 某些算法要求样本数据或特征的数值具有零均值和单位方差;
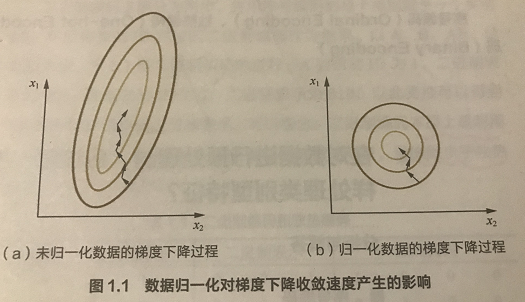
- 为了消除样本数据或者特征之间的量纲影响,即消除数量级的影响。如下图所示是包含两个属性的目标函数的等高线
- 数量级的差异将导致量级较大的属性占据主导地位。从下图左看到量级较大的属性会让椭圆的等高线压缩为直线,使得目标函数仅依赖于该属性。
- 数量级的差异会导致迭代收敛速度减慢。原始的特征进行梯度下降时,每一步梯度的方向会偏离最小值(等高线中心点)的方向,迭代次数较多,且学习率必须非常小,否则非常容易引起宽幅震荡。但经过标准化后,每一步梯度的方向都几乎指向最小值(等高线中心点)的方向,迭代次数较少。
- 所有依赖于样本距离的算法对于数据的数量级都非常敏感。比如 KNN 算法需要计算距离当前样本最近的 k 个样本,当属性的量级不同,选择的最近的 k 个样本也会不同。
- 常用的两种归一化方法:
- 线性函数归一化(Min-Max Scaling)。它对原始数据进行线性变换,使得结果映射到
[0,1]的范围,实现对原始数据的等比缩放,公式如下:
Xnorm=X−XminXmax−XminX_{norm}=\frac{X-X_{min}}{X_{max}-X_{min}} Xnorm=Xmax−XminX−Xmin
其中 X 是原始数据,Xmax,XminX_{max}, X_{min}Xmax,Xmin分别表示数据最大值和最小值。
- 零均值归一化(Z-Score Normalization)。它会将原始数据映射到均值为 0,标准差为 1 的分布上。假设原始特征的均值是μ\muμ、方差是σ\sigmaσ,则公式如下:
z=x−μσz = \frac{x-\mu}{\sigma} z=σx−μ
- 如果数据集分为训练集、验证集、测试集,那么三个数据集都采用相同的归一化参数,数值都是通过训练集计算得到,即上述两种方法中分别需要的数据最大值、最小值,方差和均值都是通过训练集计算得到(这个做法类似于深度学习中批归一化,BN的实现做法)。
- 归一化不是万能的,实际应用中,通过梯度下降法求解的模型是需要归一化的,这包括线性回归、逻辑回归、支持向量机、神经网络等模型。但决策树模型不需要,以 C4.5 算法为例,决策树在分裂结点时候主要依据数据集 D 关于特征 x 的信息增益比,而信息增益比和特征是否经过归一化是无关的,归一化不会改变样本在特征 x 上的信息增益。
3.2.2 正则化
- 正则化是将样本或者特征的某个范数(如 L1、L2 范数)缩放到单位 1。
假设数据集为:
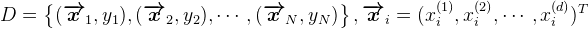
对样本首先计算 Lp 范数,得到:
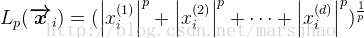
正则化后的结果是:每个属性值除以其 Lp 范数
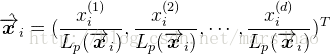
正则化的过程是针对单个样本的,对每个样本将它缩放到单位范数。
归一化是针对单个属性的,需要用到所有样本在该属性上的值。
通常如果使用二次型(如点积)或者其他核方法计算两个样本之间的相似性时,该方法会很有用。
3.3 特征编码
3.3.1 序号编码(Ordinal Encoding)
定义:序号编码一般用于处理类别间具有大小关系的数据。
比如成绩,可以分为高、中、低三个档次,并且存在“高>中>低”的大小关系,那么序号编码可以对这三个档次进行如下编码:高表示为 3,中表示为 2,低表示为 1,这样转换后依然保留了大小关系。
3.3.2 独热编码(One-hot Encoding)
定义:独热编码通常用于处理类别间不具有大小关系的特征。
独热编码是采用 N 位状态位来对 N 个可能的取值进行编码。比如血型,一共有 4 个取值(A、B、AB 以及 O 型),那么独热编码会将血型转换为一个 4 维稀疏向量,分别表示上述四种血型为:
- A型:(1,0,0,0)
- B型:(0,1,0,0)
- AB型:(0,0,1,0)
- O型:(0,0,0,1)
独热编码的优点有以下几个:
- 能够处理非数值属性。比如血型、性别等
- 一定程度上扩充了特征。
- 编码后的向量是稀疏向量,只有一位是 1,其他都是 0,可以利用向量的稀疏来节省存储空间。
- 能够处理缺失值。当所有位都是 0,表示发生了缺失。此时可以采用处理缺失值提到的高维映射方法,用第 N+1 位来表示缺失值。
当然,独热编码也存在一些缺点:
1.高维度特征会带来以下几个方面问题:
- KNN 算法中,高维空间下两点之间的距离很难得到有效的衡量;
- 逻辑回归模型中,参数的数量会随着维度的增高而增加,导致模型复杂,出现过拟合问题;
- 通常只有部分维度是对分类、预测有帮助,需要借助特征选择来降低维度。
2.决策树模型不推荐对离散特征进行独热编码,有以下两个主要原因:
产生样本切分不平衡问题,此时切分增益会非常小。
比如对血型做独热编码操作,那么对每个特征
是否 A 型、是否 B 型、是否 AB 型、是否 O 型,会有少量样本是 1 ,大量样本是 0。这种划分的增益非常小,因为拆分之后:
较小的那个拆分样本集,它占总样本的比例太小。无论增益多大,乘以该比例之后几乎可以忽略。
较大的那个拆分样本集,它几乎就是原始的样本集,增益几乎为零。
影响决策树的学习。
决策树依赖的是数据的统计信息。而独热码编码会把数据切分到零散的小空间上。在这些零散的小空间上,统计信息是不准确的,学习效果变差。
本质是因为独热编码之后的特征的表达能力较差。该特征的预测能力被人为的拆分成多份,每一份与其他特征竞争最优划分点都失败。最终该特征得到的重要性会比实际值低。
3.3.3 二进制编码(Binary Encoding)
二进制编码主要分为两步:
- 先采用序号编码给每个类别赋予一个类别 ID;
- 接着将类别 ID 对应的二进制编码作为结果。
继续以血型为例子,如下表所示:
| 血型 | 类别 ID | 二进制表示 | 独热编码 |
|---|---|---|---|
| A | 1 | 0 0 1 | 1 0 0 0 |
| B | 2 | 0 1 0 | 0 1 0 0 |
| AB | 3 | 0 1 1 | 0 0 1 0 |
| O | 4 | 1 0 0 | 0 0 0 1 |
从上表可以知道,二进制编码本质上是利用二进制对类别 ID 进行哈希映射,最终得到 0/1 特征向量,并且特征维度小于独热编码,更加节省存储空间。
3.3.4 二元化
定义:特征二元化就是将数值型的属性转换为布尔型的属性。通常用于假设属性取值分布是伯努利分布的情形。
特征二元化的算法比较简单。对属性 j 指定一个阈值 m。
- 如果样本在属性
j上的值大于等于m, 则二元化后为 1; - 如果样本在属性
j上的值小于m,则二元化为 0
根据上述定义,m 是一个关键的超参数,它的取值需要结合模型和具体的任务来选择。
3.3.5 离散化
定义:顾名思义,离散化就是将连续的数值属性转换为离散的数值属性。
那么什么时候需要采用特征离散化呢?
这背后就是需要采用“海量离散特征+简单模型”,还是“少量连续特征+复杂模型”的做法了。
- 对于线性模型,通常使用“海量离散特征+简单模型”。
- 优点:模型简单
- 缺点:特征工程比较困难,但一旦有成功的经验就可以推广,并且可以很多人并行研究。
- 对于非线性模型(比如深度学习),通常使用“少量连续特征+复杂模型”。
- 优点:不需要复杂的特征工程
- 缺点:模型复杂
分桶
1.离散化的常用方法是分桶:
- 将所有样本在连续的数值属性
j的取值从小到大排列 a0,a1,...,aN{a_0, a_1, ..., a_N}a0,a1,...,aN 。 - 然后从小到大依次选择分桶边界b1,b2,...,bMb_1, b_2, ..., b_Mb1,b2,...,bM 。其中:
M为分桶的数量,它是一个超参数,需要人工指定。- 每个桶的大小bk+1−bkb_{k+1}-b_kbk+1−bk 也是一个超参数,需要人工指定。
- 给定属性
j的取值aia_iai,对其进行分桶:- 如果ai<b1a_i < b_1ai<b1,则分桶编号是 0。分桶后的属性的取值为 0;
- 如果bk≤ai≤bk+1b_k \le a_i \le b_{k+1}bk≤ai≤bk+1,则分桶编号是
k。分桶后的属性取值是k; - 如果 ai≥bMa_i \ge b_Mai≥bM, 则分桶编号是
M。分桶后的属性取值是M。
2.分桶的数量和边界通常需要人工指定。一般有两种方法:
- 根据业务领域的经验来指定。如:对年收入进行分桶时,根据 2017 年全国居民人均可支配收入约为 2.6 万元,可以选择桶的数量为5。其中:
- 收入小于 1.3 万元(人均的 0.5 倍),则为分桶 0 。
- 年收入在 1.3 万元 ~5.2 万元(人均的 0.5~2 倍),则为分桶 1 。
- 年收入在 5.3 万元~26 万元(人均的 2 倍~10 倍),则为分桶 2 。
- 年收入在 26 万元~260 万元(人均的 10 倍~100 倍),则为分桶 3 。
- 年收入超过 260 万元,则为分桶 4 。
- 根据模型指定。根据具体任务来训练分桶之后的数据集,通过超参数搜索来确定最优的分桶数量和分桶边界。
3.选择分桶大小时,有一些经验指导:
分桶大小必须足够小,使得桶内的属性取值变化对样本标记的影响基本在一个不大的范围。
即不能出现这样的情况:单个分桶的内部,样本标记输出变化很大。
分桶大小必须足够大,使每个桶内都有足够的样本。
如果桶内样本太少,则随机性太大,不具有统计意义上的说服力。
每个桶内的样本尽量分布均匀。
特性
1.在工业界很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列 0/1 的离散特征。
其优势有:
离散化之后得到的稀疏向量,内积乘法运算速度更快,计算结果方便存储。
离散化之后的特征对于异常数据具有很强的鲁棒性。
如:销售额作为特征,当销售额在
[30,100)之间时,为1,否则为 0。如果未离散化,则一个异常值 10000 会给模型造成很大的干扰。由于其数值较大,它对权重的学习影响较大。逻辑回归属于广义线性模型,表达能力受限,只能描述线性关系。特征离散化之后,相当于引入了非线性,提升模型的表达能力,增强拟合能力。
假设某个连续特征
j,它离散化为M个 0/1 特征 j1,j2,...,jMj_1, j_2, ..., j_Mj1,j2,...,jM 。则:$w_j * x_j -> w_{j1} * x_{j1}^+ w_{j2} * x_{j2}^+ …+w_{jM} * x_{jM}^` $。其中 xj1‘,xj2‘,...,xjM‘x_{j1}^`,x_{j2}^`,..., x_{jM}^`xj1‘,xj2‘,...,xjM‘ 是离散化之后的新的特征,它们的取值空间都是 {0, 1}。
上式右侧是一个分段线性映射,其表达能力更强。
离散化之后可以进行特征交叉。假设有连续特征
j,离散化为N个 0/1 特征;连续特征k,离散化为M个 0/1 特征,则分别进行离散化之后引入了N+M个特征。假设离散化时,并不是独立进行离散化,而是特征
j,k联合进行离散化,则可以得到N*M个组合特征。这会进一步引入非线性,提高模型表达能力。离散化之后,模型会更稳定。
如对销售额进行离散化,
[30,100)作为一个区间。当销售额在40左右浮动时,并不会影响它离散化后的特征的值。但是处于区间连接处的值要小心处理,另外如何划分区间也是需要仔细处理。
2.特征离散化简化了逻辑回归模型,同时降低模型过拟合的风险。
能够对抗过拟合的原因:经过特征离散化之后,模型不再拟合特征的具体值,而是拟合特征的某个概念。因此能够对抗数据的扰动,更具有鲁棒性。
另外它使得模型要拟合的值大幅度降低,也降低了模型的复杂度。
小结
特征缩放是非常常用的方法,特别是归一化处理特征数据,对于利用梯度下降来训练学习模型参数的算法,有助于提高训练收敛的速度;而特征编码,特别是独热编码,也常用于对结构化数据的数据预处理。
参考:
- 《百面机器学习》第一章 特征工程
- https://blog.csdn.net/dream_angel_z/article/details/49388733#commentBox
- https://www.cnblogs.com/sherial/archive/2018/03/07/8522405.html
- https://gofisher.github.io/2018/06/22/数据预处理/
- https://gofisher.github.io/2018/06/20/数据探索/
- https://juejin.im/post/5b6a44f55188251aa8294b8c
- https://www.zhihu.com/question/47716840
- http://www.huaxiaozhuan.com/统计学习/chapters/8_feature_selection.html
欢迎关注我的微信公众号–机器学习与计算机视觉,或者扫描下方的二维码,大家一起交流,学习和进步!

往期精彩推荐
机器学习系列
- 机器学习入门系列(1)–机器学习概览
- 机器学习入门系列(2)–如何构建一个完整的机器学习项目(一)
- 机器学习数据集的获取和测试集的构建方法
- 特征工程之数据预处理(上)
- 特征工程之数据预处理(下)
数学学习笔记
- 程序员的数学笔记1–进制转换
- 程序员的数学笔记2–余数
- 程序员的数学笔记3–迭代法
Github项目 & 资源教程推荐
- [Github 项目推荐] 一个更好阅读和查找论文的网站
- [资源分享] TensorFlow 官方中文版教程来了
- 必读的AI和深度学习博客
- [教程]一份简单易懂的 TensorFlow 教程
- [资源]推荐一些Python书籍和教程,入门和进阶的都有!
特征工程之特征缩放特征编码相关推荐
- 机器学习特征工程之特征缩放+无量纲化:数据标准化(StandardScaler)
机器学习特征工程之特征缩放+无量纲化:数据标准化(StandardScaler) 在Andrew Ng的机器学习课程里面,讲到使用梯度下降的时候应当进行特征缩放(Feature Scaling).进行 ...
- 机器学习特征工程之特征缩放+无量纲化:最小最大缩放(MinMaxScaler)
机器学习特征工程之特征缩放+无量纲化:最小最大缩放(MinMaxScaler) 在Andrew Ng的机器学习课程里面,讲到使用梯度下降的时候应当进行特征缩放(Feature Scaling).进行缩 ...
- 机器学习特征工程之特征缩放+无量纲化:最大绝对值缩放(MaxAbsScaler)
机器学习特征工程之特征缩放+无量纲化:最大绝对值缩放(MaxAbsScaler) 在Andrew Ng的机器学习课程里面,讲到使用梯度下降的时候应当进行特征缩放(Feature Scaling).进行 ...
- AI基础:特征工程-文本特征处理
0.导语 特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用. 在此之前,我已经写了以下几篇AI基础的快速入门,本篇文章讲解特征工程基础第三部 ...
- AI基础:特征工程-数字特征处理
0.导语 特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用. 在此之前,我已经写了以下几篇AI基础的快速入门,本篇文章讲解特征工程基础第二部 ...
- ML之FE:数据处理—特征工程之特征三化(标准化【四大数据类型(数值型/类别型/字符串型/时间型)】、归一化、向量化)简介、代码实现、案例应用之详细攻略
ML之FE:数据处理-特征工程之特征三化(标准化[四大数据类型(数值型/类别型/字符串型/时间型)].归一化.向量化)简介.代码实现.案例应用之详细攻略 目录 真正意义的标准化与归一化 1.标准化/Z ...
- ML之FE:利用FE特征工程(单个特征及其与标签关系的可视化)对RentListingInquries(Kaggle竞赛)数据集实现房屋感兴趣程度的多分类预测
ML之FE:利用FE特征工程(单个特征及其与标签关系的可视化)对RentListingInquries(Kaggle竞赛)数据集实现房屋感兴趣程度的多分类预测 目录 输出结果 设计思路 核心代码 输出 ...
- 【特征工程】特征工程技术与方法
引言 在之前学习机器学习技术中,很少关注特征工程(Feature Engineering),然而,单纯学习机器学习的算法流程,可能仍然不会使用这些算法,尤其是应用到实际问题的时候,常常不知道怎么提取特 ...
- 机器学习项目实战-能源利用率 Part-3(特征工程与特征筛选)
博主前期相关的博客可见下: 机器学习项目实战-能源利用率 Part-1(数据清洗) 机器学习项目实战-能源利用率 Part-2(探索性数据分析) 这部分进行的特征工程与特征筛选. 三 特征工程与特征筛 ...
- 线性稀疏自编码机_特征工程之特征缩放amp;特征编码
机器学习入门系列(2)--如何构建一个完整的机器学习项目,第五篇! 本篇文章会继续介绍特征工程的内容,这次会介绍特征缩放和特征编码,前者主要是归一化和正则化,用于消除量纲关系的影响,后者包括了序号编码 ...
最新文章
- 订单管理之获取订单表表列表数据
- 《Java程序员,上班那点事儿》目录
- kubelet创建容器的步骤
- ubuntu 15.04 下的 nvidia(待续)
- PHP数据结构之三 线性表中的单链表的PHP实现
- 施一公:优秀博士如何养成
- Oracle二三事之 12c 可插拔数据库PDB
- sql语句的执行过程和优化
- 当大家都不理解你的时候,就是你成就的捷径
- Practical JAVA(三)关于final
- 【2018百度之星程序设计大赛初赛】degree
- RemoteDesktopManager和微软远程桌面管理器RDCman
- 【动画演示软件】Focusky教程 | 加入 配音/录音/字幕
- VR全景智慧城市虚拟现实三维的发展
- mysql优化-Explain工具介绍
- 电脑副业能做什么?一台电脑能做的副业
- 基于Go语言Iris+Xorm的OA办公系统
- vue的侦听器,过滤器和过度动画的了解
- Random image cropping and patching (RICAP)
- 使用redis incr处理并发,存在死锁问题
热门文章
- 标杆徐2018 Linux自动化运维实战,标杆徐2018 Linux自动化运维系列⑦: SaltStack自动化配置管理实战...
- 荣新linux培训,51CTO博客-专业IT技术博客创作平台-技术成就梦想
- Oracle adviser,Oracle10g SQL tune adviser
- 语言语法糖_【c#】几种常用语法糖
- cocos2dx libevent简介和使用
- [vim]vim 插件汇总
- [react] React Hooks帮我们解决了哪些问题?
- React开发(253):react项目理解 ant design ancher锚点
- React开发(158):ant design级联回显 直接传入数组
- 前端学习(3303):函数组件组件子组件useRef聚焦