分类器模型评价指标之ROC曲线
来源:分类器模型评价指标
An introduction to ROC analysis
Spark mllib 自带了许多机器学习算法,它能够用来进行模型的训练和预测。当使用这些算法来构建模型的时候,我们需要一些指标来评估这些模型的性能,这取决于应用和和其要求的性能。Spark mllib 也提供一套指标用来评估这些机器学习模型。
具体的机器学习算法归入更广泛类型的机器学习应用,例如:分类,回归,聚类等等,每一种类型都很好的建立了性能评估指标。本节主要分享分类器模型评价指标。
ROC曲线
ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣 。ROC曲线怎么来的呢,我们来看经典的混淆矩阵:
![]()
(1)真正类(True Positive , TP):被模型预测为正类的正样本
(3)假负类(False Negative , FN):被模型预测为负类的正样本
(4)真负类(True Negative , TN):被模型预测为负类的负样本
(1)真正类率(True Positive Rate , TPR)【灵敏度(sensitivity)】: TPR = TP /(TP + FN) ,即正样本预测结果数/正样本实际数
(2)假负类率(False Negative Rate , FNR) : FNR = FN /(TP + FN) ,即被预测为负的正样本结果数/正样本实际数
(3)假正类率(False Positive Rate , FPR) : FPR = FP /(FP + TN) ,即被预测为正的负样本结果数/负样本实际数
(4)真负类率(True Negative Rate , TNR)【特指度(specificity)】: TNR = TN /(TN + FP) ,即负样本预测结果数/负样本实际数

需要提前说明的是,我们这里只讨论二值分类器。对于分类器,或者说分类算法,评价指标主要有accuracy,precision,recall,F-score,以及我们今天要讨论的ROC和AUC。下图是一个ROC曲线的示例。

正如我们在这个ROC曲线的示例图中看到的那样,ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。下图中详细说明了FPR和TPR是如何定义的。

接下来我们考虑ROC曲线图中的四个点和一条线。第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。Wow,这是一个完美的分类器,它将所有的样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。类似的,第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
下面考虑ROC曲线图中的虚线y=x上的点。这条对角线上的点其实表示的是一个采用随机猜测策略的分类器的结果,例如(0.5,0.5),表示该分类器随机对于一半的样本猜测其为正样本,另外一半的样本为负样本。
如何画ROC曲线
对于一个特定的分类器和测试数据集,显然只能得到一个分类结果,即一组FPR和TPR结果,而要得到一个曲线,我们实际上需要一系列FPR和TPR的值,这又是如何得到的呢?我们先来看一下Wikipedia上对ROC曲线的定义:
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied.
问题在于“as its discrimination threashold is varied”。如何理解这里的“discrimination threashold”呢?我们忽略了分类器的一个重要功能“概率输出”,即表示分类器认为某个样本具有多大的概率属于正样本(或负样本)。通过更深入地了解各个分类器的内部机理,我们总能想办法得到一种概率输出。通常来说,是将一个实数范围通过某个变换映射到(0,1)区间。
假如我们已经得到了所有样本的概率输出(属于正样本的概率),现在的问题是如何改变“discrimination threashold”?我们根据每个测试样本属于正样本的概率值从大到小排序。下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。

接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:

当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
其实,我们并不一定要得到每个测试样本是正样本的概率值,只要得到这个分类器对该测试样本的“评分值”即可(评分值并不一定在(0,1)区间)。评分越高,表示分类器越肯定地认为这个测试样本是正样本,而且同时使用各个评分值作为threshold。我认为将评分值转化为概率更易于理解一些。
AUC指标
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
在了解了ROC曲线的构造过程后,编写代码实现并不是一件困难的事情。相比自己编写代码,有时候阅读其他人的代码收获更多,当然过程也更痛苦些。在此推荐scikit-learn中关于计算AUC的代码。
AUC含义是什么
那么AUC值的含义是什么呢?根据(Fawcett, 2006),AUC的值的含义是: > The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
这句话有些绕,我尝试解释一下:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
以下示例三种AUC值(曲线下面积):
![]()
AUC的物理意义
假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
AUC的计算方法
第一种方法:计算出ROC曲线下面的面积,就是AUC的值。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。计算的精度与阈值的精度有关。
第二种方法:一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test(秩和检验)是等价的。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)。
第三种方法:实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
公式解释:
1、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1
2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
为什么使用ROC曲线
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线5的对比:

在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
其他评估指标
Informedness = Sensitivity + Specificity - 1 |
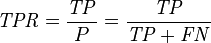

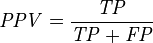

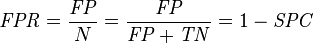
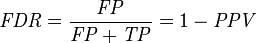
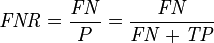


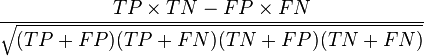
在机器学习,模式识别中,我们做分类的时候,会用到一些指标来评判算法的优劣,最常用的就是识别率,简单来说,就是
这里的 Npre表示预测对的样本数,Ntotal表示测试集总的样本数。
识别率有的时候过于简单, 不能全面反应算法的性能,除了识别率,还有一些常用的指标,就是我们要介绍的
F1-score, recall, precision.
在介绍这些概念之前,我们先来看一个二分类的问题,给定一组训练集:
这里假定 yi=1 对应正样本,yi=0 对应负样本。假设我们建立了一个分类模型 H, 对每一个输入的样本 xi 会输出一个预测值 H(xi), 那么将预测值 H(xi) 与样本对应的实际值yi做比较,会得到以下四种情况:
| H(xi)=1,yi=1 |
|---|
| H(xi)=1,yi=0 |
| H(xi)=0,yi=1 |
| H(xi)=0,yi=0 |
第一种情况,预测为正,实际也为正,我们称为 true positive (TP),第二种情况,预测为正,实际为负,我们称为 false positive (FP),第三种情况,预测为负,实际为正,称为false negative (FN),最后一种情况,预测为负,实际也为负,称为 true negative (TN),每一个样本只可能属于这四种情况中的某一种,不会有其它的可能。
很显然,给定一个测试集,我们可以得到如下的关系:
如果我们定义一个测试集中,正样本个数为P, 负样本个数为N, 那么我们可以知道:P=TP+FN,N=TN+FP
所以,我们常用的识别率 acc 其实就等于
,
进一步,我们可以定义 recall ,precision, F1-score 如下所示:
可以看到,recall 体现了分类模型H对正样本的识别能力,recall 越高,说明模型对正样本的识别能力越强,precision 体现了模型对负样本的区分能力,precision越高,说明模型对负样本的区分能力越强。F1-score 是两者的综合。F1-score 越高,说明分类模型越稳健。
比如我们常见的雷达预警系统,我们需要对雷达信号进行分析,判断这个信号是飞行器(正样本)还是噪声 (负样本), 很显然,我们希望系统既能准确的捕捉到飞行器信号,也可以有效地区分噪声信号。所以就要同时权衡recall 和 precision这两个指标,如果我们把所有信号都判断为飞行器,那 recall 可以达到1,但是precision将会变得很低(假设两种信号的样本数接近),可能就在 0.5 左右,那F1-score 也不会很高。
有的时候,我们对recall 与 precision 赋予不同的权重,表示对分类模型的偏好:
可以看到,当 β=1,那么Fβ就退回到F1了,β 其实反映了模型分类能力的偏好,β>1 的时候,precision的权重更大,为了提高Fβ,我们希望precision 越小,而recall 应该越大,说明模型更偏好于提升recall,意味着模型更看重对正样本的识别能力; 而 β<1 的时候,recall 的权重更大,因此,我们希望recall越小,而precision越大,模型更偏好于提升precision,意味着模型更看重对负样本的区分能力。
举例:以下程序片段说明了spark lr加载数据集,训练二元分类模型,使用不同的评估指标进行评估。
- importorg.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
- importorg.apache.spark.mllib.evaluation.BinaryClassificationMetrics
- importorg.apache.spark.mllib.regression.LabeledPoint
- importorg.apache.spark.mllib.util.MLUtils
- // Load training data in LIBSVM format
- val data=MLUtils.loadLibSVMFile(sc,"data/mllib/sample_binary_classification_data.txt")
- // Split data into training (60%) and test (40%)
- val Array(training, test)= data.randomSplit(Array(0.6,0.4), seed =11L)
- training.cache()
- // Run training algorithm to build the model
- val model=newLogisticRegressionWithLBFGS()
- .setNumClasses(2)
- .run(training)
- // Clear the prediction threshold so the model will return probabilities
- model.clearThreshold
- // Compute raw scores on the test set
- val predictionAndLabels= test.map{caseLabeledPoint(label, features)=>
- val prediction = model.predict(features)
- (prediction, label)
- }
- // Instantiate metrics object
- val metrics = newBinaryClassificationMetrics(predictionAndLabels)
- // Precision by threshold
- val precision = metrics.precisionByThreshold
- precision.foreach{case(t, p)=>
- println(s"Threshold: $t, Precision: $p")
- }
- // Recall by threshold
- val recall = metrics.recallByThreshold
- recall.foreach{case(t, r)=>
- println(s"Threshold: $t, Recall: $r")
- }
- // Precision-Recall Curve
- val PRC = metrics.pr
- // F-measure
- val f1Score = metrics.fMeasureByThreshold
- f1Score.foreach{case(t, f)=>
- println(s"Threshold: $t, F-score: $f, Beta = 1")
- }
- val beta = 0.5
- val fScore = metrics.fMeasureByThreshold(beta)
- f1Score.foreach{case(t, f)=>
- println(s"Threshold: $t, F-score: $f, Beta = 0.5")
- }
- // AUPRC
- val auPRC = metrics.areaUnderPR
- println("Area under precision-recall curve = "+ auPRC)
- // Compute thresholds used in ROC and PR curves
- val thresholds = precision.map(_._1)
- // ROC Curve
- val roc = metrics.roc
- // AUROC
- val auROC = metrics.areaUnderROC
- println("Area under ROC = "+ auROC)
Refer
http://blog.csdn.net/justdoithai/article/details/51213367
http://f.dataguru.cn/thread-659637-1-1.html
http://www.cnblogs.com/who-a/p/5499539.html
http://blog.csdn.net/u011263983/article/details/51924891
https://en.wikipedia.org/wiki/Receiver_operating_characteristic
https://en.wikipedia.org/wiki/F1_score
分类器模型评价指标之ROC曲线相关推荐
- 机器学习分类模型评价指标之ROC 曲线、 ROC 的 AUC 、 ROI 和 KS
前文回顾: 机器学习模型评价指标之混淆矩阵 机器学习模型评价指标之Accuracy.Precision.Recall.F-Score.P-R Curve.AUC.AP 和 mAP 图裂的话请参考:ht ...
- matlab绘制贝叶斯曲线,Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
原文链接:http://tecdat.cn/?p=15508 绘制ROC曲线通过Logistic回归进行分类 加载样本数据.load fisheriris通过使用与versicolor和virgini ...
- 使用R构建Xgboost模型并绘制ROC曲线
使用R构建Xgboost模型并绘制ROC曲线 xgboost算法论文全称为<XGBoost: A Scalable Tree Boosting System>,由陈天奇于2016年发表的, ...
- Ubuntu 下使用 FDDB 测试人脸检测模型并生成 ROC 曲线,详细步骤
原 Ubuntu 下使用 FDDB 测试人脸检测模型并生成 ROC 曲线 2018年08月01日 20:18:44 Xing_yb 阅读数:101 标签: FDDB 人脸检测 模型测试 ROC 曲线 ...
- 数学建模学习(2)—— 客户流失预警模型案例评估 ROC曲线与KS曲线(2022.7.19)
昨天晚上做了个梦,梦到被老师臭骂了一顿,可以说当时把我直接吓醒了,醒过来后,惊叹一声,还好是个梦.在上个笔记中学习了逻辑回归的运用,这节课再来看一看对模型评估的方法. 文章目录 目录 文章目录 一.R ...
- 构造matlab决策树分类器,Matlab建立逻辑回归,决策树,SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线...
尽管对于较高的阈值,SVM可以产生更好的ROC值,但逻辑回归通常更擅长区分不良雷达收益与良好雷达.朴素贝叶斯的ROC曲线通常低于其他两个ROC曲线,这表明样本内性能比其他两个分类器方法差. 比较所 ...
- 机器学习分类器模型评价指标
分类器评价指标主要有: 1,Accuracy 2,Precision 3,Recall 4,F1 score 5,ROC 曲线 6,AUC 7,PR 曲线 混淆矩阵 混淆矩阵是监督学习中的一种可视化工 ...
- 模型评价指标之ROC、AUC和GAUC
模型优劣的评价有完整的评价指标,通过这些指标我们可以评判出该模型的性能,同时可以比对不同模型进行择优,下面我们从混淆模型开始,学习通过ROC曲线.AUC以及GAUC来对普通分类模型以及推荐模型的评判. ...
- 机器学习 模型评估指标 - ROC曲线和AUC值
机器学习算法-随机森林初探(1) 随机森林拖了这么久,终于到实战了.先分享很多套用于机器学习的多种癌症表达数据集 https://file.biolab.si/biolab/supp/bi-cance ...
最新文章
- Docker学习(七)-----Docker安装nginx
- echarts 图标高度自适应_echarts图表盒子大小变化后,图表无法自适应
- 缓存穿透、缓存并发、缓存失效之思路变迁
- 修改Static控件的字体颜色
- linux下python脚本判断目录和文件是否存在
- 9008线刷_小米红米手机新机9008模式怎么进入?小米线刷救砖模式
- Visio 与 Access 2007 的集成应用
- select、poll、epoll的区别
- Linux下Nginx安装
- win32学习之 --------GDI使用 代码记录
- 编码之Base64编码
- 云服务器安全配置开放哪些端口
- 智商高的人情商都低?這個人來告訴你
- 慎用windows EFS文件加密
- bzoj 3772: 精神污染 (主席树+dfs序)
- android 左右分栏联动布局,自定义页面分栏布局
- [2009][note]构成理想导体超材料的有源THz欺骗表面等离子激元开关——
- Debian备份与还原
- File文件的属性设置
- 【管理学知识】决策模型10-10-10法则(加油吧,少年!)
热门文章
- 《麦肯锡意识》前言 解决问题的战略模型-思维导图
- mac 连接windows远程桌面软件Parallels Client
- Proteus VSM Studio汇编 + 蜂鸣器播放谱曲八月桂花香
- AD域帐号批量查询锁定帐号,批量解锁域帐号
- 中望CAD的引线标注格式怎么改_没想到啊,原来CAD命令还可以这样学习
- JAVA 如何使用延迟
- 高德地图-初始化的时候获取行政区边界和中心点
- 大爱伟业协同办公系统项目的感想
- Struts2通配符映射/Struts action name=/*/* method={2} class=com.jxc.action.{1}Action result
- 山东大学nlp实验--词向量