恶意url_预测URL的恶意
恶意url
In this article, we walk through developing a simple feature set representation for identifying malicious URLs. We will create feature vectors for URLs and use these to develop a classification model for identifying malicious URLs. To evaluate how good the features are in separating malicious URLs from benign URLs, we build a Decision-Tree based machine learning model to predict the maliciousness of a given URL.
在本文中,我们将逐步开发一种用于识别恶意URL的简单功能集表示形式。 我们将为URL创建特征向量,并使用它们来开发用于识别恶意URL的分类模型。 为了评估功能在将恶意URL与良性URL分离方面的优势,我们构建了基于决策树的机器学习模型来预测给定URL的恶意性。
Malicious websites are well-known threats in cybersecurity. They act as an efficient tool for propagating viruses, worms, and other types of malicious codes online and are responsible for over 60% of most cyber attacks. Malicious URLs can be delivered via email links, text messages, browser pop-ups, page advertisements, etc. These URLs may be links to dodgy websites or most likely have embedded ‘downloadables’. These embedded downloads can be spy-wares, key-loggers, viruses, worms, etc. As such it has become a priority for cyber defenders to detect and mitigate the spread of malicious codes within their networks promptly. Various techniques for malicious URL detectors have previously relied mainly on URL blacklisting or signature blacklisting. Most of these techniques offer ‘after-the-fact’ solutions. To improve the timeliness and abstraction of malicious URL detection methods, machine learning techniques are increasingly being accepted.
恶意网站是网络安全中众所周知的威胁。 它们是在线传播病毒,蠕虫和其他类型的恶意代码的有效工具,并负责大多数网络攻击的60%以上。 恶意URL可以通过电子邮件链接,文本消息,浏览器弹出窗口,页面广告等进行传递。这些URL可能是指向不可靠网站的链接,或者最有可能嵌入了“可下载内容”。 这些嵌入式下载可以是间谍软件,按键记录程序,病毒,蠕虫等。因此,网络防御者应优先考虑立即检测并缓解恶意代码在网络中的传播。 恶意URL检测器的各种技术以前主要依靠URL黑名单或签名黑名单。 这些技术大多数都提供“事后”解决方案。 为了提高恶意URL检测方法的及时性和抽象性,越来越多地接受机器学习技术。
To develop a machine learning model, we need a feature extraction framework for featurizing URLs or converting URLs into feature vectors. In this article, We will collect samples of known malicious URLs and known benign URLs. We then develop a fingerprinting framework and extract a given set of M features for all URLs in the sample. We test the usefulness of these features in separating malicious URLs from benign URLs by developing a simple predictive model with these features. Finally, we measure the model’s ability to predict the maliciousness of URLs as the effectiveness of the features in separating malicious URLs from benign URLs.
要开发机器学习模型,我们需要一个特征提取框架,用于特征化URL或将URL转换为特征向量。 在本文中,我们将收集已知恶意URL和已知良性URL的样本。 然后,我们开发一个指纹识别框架,并为示例中的所有URL提取给定的M个功能集。 通过开发具有这些功能的简单预测模型,我们测试了这些功能在区分恶意URL和良性URL方面的有用性。 最后,我们测量模型预测URL恶意性的能力,作为功能将恶意URL与良性URL分离的功能的有效性。
The image below is an overview of the methodological process in this article.
下图是本文方法论过程的概述。
数据 (The Data)
We collected data from two sources: Alexa Top 1000 sites and phishtank.com. 1000 assumed benign URLs were crawled from Alexa top 1000 websites and 1000 suspected malicious URLs were crawled from phishtank.com. Due to virustotal API limit rates, we randomly sample 500 assumed benign URLs and 500 assumed malicious URLs. The URLs were then scanned through virustotal. URLs with 0 malicious detections were labeled as benign (b_urlX) and URLs with at least 8 detections were labeled as malicious (m_urlX). we dumped the JSON results of each scan in corresponding files ‘b_urlX.json’, ‘m_urlX.json’. You can find these files here.
我们从两个来源收集数据:Alexa前1000个网站和phishtank.com。 从Alexa排名前1000的网站中爬取了1000个假定的良性URL,并从phishtank.com中爬取了1000个可疑恶意URL。 由于API的病毒总数限制率,我们随机抽取了500个假定的良性URL和500个假定的恶意URL。 然后通过virustotal扫描URL。 具有0次恶意检测的URL被标记为良性(b_urlX),具有至少8次检测的URL被标记为恶意(m_urlX)。 我们将每次扫描的JSON结果转储到相应的文件“ b_urlX.json”,“ m_urlX.json”中。 您可以在这里找到这些文件。
from requests import getfrom os import listdirimport pandas as pdimport numpy as npfrom pandas.io.json import json_normalizeimport seaborn as snsimport matplotlib.pyplot as pltimport mathfrom datetime import datetimeplt.rcParams["figure.figsize"] = (20,20)处理API速率限制和IP阻止 (Handling API Rate Limits and IP Blocking)
To confirm that malicious URLs in the sample are malicious, we need to send multiple requests to VirusTotal. VirustTotal provides aggregated results from multiple virus scan engines. Also, we pass URLs through (Shodan)[shodan.io]. Shodan is a search engine for all devices connected to the internet providing service-based features of the URL’s server. VirusTotal and Shodan currently have API rate limits of 4 requests per minute and at least 10,000 requests per month respectively per API key. While the number of URL requests for the data fell within the Shodan API request limits, VirusTotal proved a little more difficult. This is addressed by creating several VT API Keys (be kind, 4 at most) and randomly sampling them in each request. In addition to limits on the number of API requests, sending multiple requests within a short period will lead to IP blocking from VT and Shodan servers. We write a small crawler to get the latest set of elite IP addresses from https://free-proxy-list.net/ and create a new proxy-list on each request given the very short lifespan of free proxies. In addition to IP pooling, we use Python’s FakeUserAgent library to switch User-Agents on each request.
为了确认样本中的恶意URL是恶意的,我们需要向VirusTotal发送多个请求。 VirustTotal提供来自多个病毒扫描引擎的汇总结果。 另外,我们通过(Shodan)[shodan.io]传递URL。 Shodan是一个搜索引擎,它用于连接到Internet的所有设备,提供URL服务器的基于服务的功能。 VirusTotal和Shodan目前对API速率的限制是每分钟每分钟4个请求,每个API密钥每月分别至少有10,000个请求。 尽管对数据的URL请求数量在Shodan API请求限制之内,但VirusTotal却被证明有点困难。 通过创建几个VT API密钥(最多为4个)并在每个请求中随机采样它们,可以解决此问题。 除了限制API请求的数量外,在短时间内发送多个请求还会导致VT和Shodan服务器的IP阻塞。 我们编写了一个小型搜寻器,以从https://free-proxy-list.net/获取最新的精英IP地址集,并在给定免费代理的使用寿命非常短的情况下,针对每个请求创建一个新的代理列表。 除了IP池外,我们还使用Python的FakeUserAgent库在每个请求上切换User-Agent。
Finally, For each request, we can send 16 requests per minute as opposed to the previous 4, with a new proxy and user agent. Each request has the following request parameters:
最后,对于每个请求,我们可以使用新的代理和用户代理,每分钟发送16个请求,而之前的请求为4个。 每个请求具有以下请求参数:
- 1 VirusTotal Key: Sample from VT API keys pool.
1 VirusTotal Key:VT API密钥池中的样本。 - 1 Shodan Key: Sample from Shodan API keys pool.
1 Shodan密钥:Shodan API密钥池中的示例。 1 IP: Send a request to https://free-proxy-list.net/ to get the latest free elite proxy.
1个IP:向https://free-proxy-list.net/发送请求以获取最新的免费精英代理。
- 1 User-Agent: Sample useable user agents from Python’s (Fake User-Agent)[https://pypi.org/project/fake-useragent/]
1个User-Agent:来自Python的示例用户代理(虚假User-Agent)[https://pypi.org/project/fake-useragent/]
The scanning from Shodan and VT produced the following dataset. From shodan, we extract the following features:
Shodan和VT的扫描产生了以下数据集 。 从shodan中,我们提取了以下功能:
- numServices: Total number of services (open ports) running on the host
numServices:主机上运行的服务总数(开放端口) - robotstxt: Is the site has robots txt enabled
robotstxt:网站是否启用了robots txt
## This gets elite proxy from https://pypi.org/project/fake-useragent/ on every requestclass Pooling(object): def __init__(self): self.proxies_url = '' '''returns a list of currently available elite proxies''' def proxy_pool(self, url = 'https://free-proxy-list.net/'): pq, proxies = get_page(url), [] tr = pq('table#proxylisttable.table tbody tr') rows = [j.text() for j in [PyQuery(i)('td') for i in tr]] rows = [i for i in rows if 'elite' in i] for row in rows: row = row.split() data = {} data['ip'] = row[0] data['port'] = row[1] data['country'] = row[3] data['proxy'] = { 'http' :'http://{}:{}'.format(data['ip'], data['port']), 'https' :'https://{}:{}'.format(data['ip'], data['port']) } proxies.append(data) return choice(proxies) '''return a random list of user agents''' def ua_pool(self): ua = UserAgent() chromes = ua.data['browsers']['chrome'][5:40] shuffle(chromes) return choice(chromes)The final dataset after scanning is available here. You can download this data and run your analysis.
扫描后的最终数据集可在此处获得 。 您可以下载此数据并运行分析。
指纹URL(用于恶意软件URL检测的特征URL) (Fingerprinting URLS (Featurizing URLs for Malware URL Detection))
The goal is to extract URL characteristics that are important in separating malicious URLs from good URLs. First, let’s look at the relevant parts in the structure of a URL.
目的是提取URL特征,这些特征对于将恶意URL与良好URL分开至关重要。 首先,让我们看一下URL结构中的相关部分。

A URL (short for Uniform Resource Locator) is a reference that specifies the location of a web resource on a computer network and a mechanism for retrieving it. The URL is made up of different components as shown in the figure below. The protocol or scheme specifies how (or what is needed for) information is to be transferred. The hostname is a human-readable unique reference of the computer’s IP address on the computer network. The Domain Name Service (DNS) naming hierarchy maps an IP address to a hostname. Compromised URLs are used to perpetrate cyber-attacks online. These attacks may be in any or more forms of phishing emails, spam emails, and drive-by downloads.
URL(统一资源定位符的缩写)是一个引用,用于指定Web资源在计算机网络上的位置以及用于检索该资源的机制。 URL由不同的组件组成,如下图所示。 该协议或方案指定如何(或需要什么)信息进行传输。 主机名是计算机网络上计算机IP地址的人类可读的唯一引用。 域名服务(DNS)命名层次结构将IP地址映射到主机名。 受损的URL用于在线进行网络攻击。 这些攻击可能以网络钓鱼电子邮件,垃圾邮件和偷渡式下载的任何或更多形式出现。
Regarding domains, owners buy domains that people find easier to remember. Owners would normally want names that are specific to a brand, product, or service which they are delivering. This part (the domain)of the URL cannot be changed once set. Malicious domain owners may opt for multiple cheap domain names for example ‘xsertyh.com’.
关于域名,所有者购买人们容易记住的域名。 所有者通常希望使用特定于他们所提供的品牌,产品或服务的名称。 网址的此部分(域)一旦设置就无法更改。 恶意域名所有者可能会选择多个廉价域名,例如“ xsertyh.com”。
The free URL parameters are parts of a URL that can be changed to create new URLs. These include directory names, file paths, and URL parameters. These free URL parameters are usually manipulated by attackers to create new URLs, embed malicious codes and propagate them.
可用的URL参数是URL的一部分,可以更改以创建新的URL。 其中包括目录名称,文件路径和URL参数。 这些免费的URL参数通常由攻击者操纵以创建新的URL,嵌入恶意代码并传播它们。
There are many techniques for malicious URL detection, two main techniques being a) Blacklisting Techniques, and b) Machine Learning Techniques. Blacklisting involves maintaining a database of known malicious domains and comparing the hostname of a new URL to hostnames in that database. This has an ‘after-the-fact’ problem. It will be unable to detect new and unseen malicious URL, which will only be added to the blacklist after it has been observed as malicious from a victim. Machine learning approaches, on the other hand, provide a predictive approach that is generalizable across platforms and independent of prior knowledge of known signatures. Given a sample of malicious and benign malware samples, ML techniques will extract features of known good and bad URLs and generalize these features to identify new and unseen good or bad URLs.
有许多用于恶意URL检测的技术,其中两项主要技术是a)黑名单技术和b)机器学习技术。 黑名单包括维护已知恶意域的数据库,并将新URL的主机名与该数据库中的主机名进行比较。 这有一个“事后”问题。 它将无法检测到新的和看不见的恶意URL,只有在被受害者视为恶意URL后,该URL才会添加到黑名单中。 另一方面,机器学习方法提供了一种预测性方法,该方法可跨平台通用并且独立于已知签名的先验知识。 给定一个恶意和良性恶意软件样本示例,机器学习技术将提取已知的好和坏URL的功能,并将这些功能概括化以识别新的和看不见的好或坏URL。
The URL fingerprinting process targets 3 types of URL features:
URL指纹识别过程针对3种类型的URL功能:
- URL String Characteristics: Features derived from the URL string itself.
URL字符串特征:从URL字符串本身派生的功能。 - URL Domain Characteristics: Domain characteristics of the URLs domain. These include whois information and shodan information.
URL域特征:URL域的域特征。 这些信息包括Whois信息和Shodan信息。 - Page Content Characteristics: Features extracted from the URL’s page (if any)
页面内容特征:从URL页面提取的特征(如果有)
A summary of all features extracted are shown in the table below:
下表中列出了提取的所有功能的摘要:
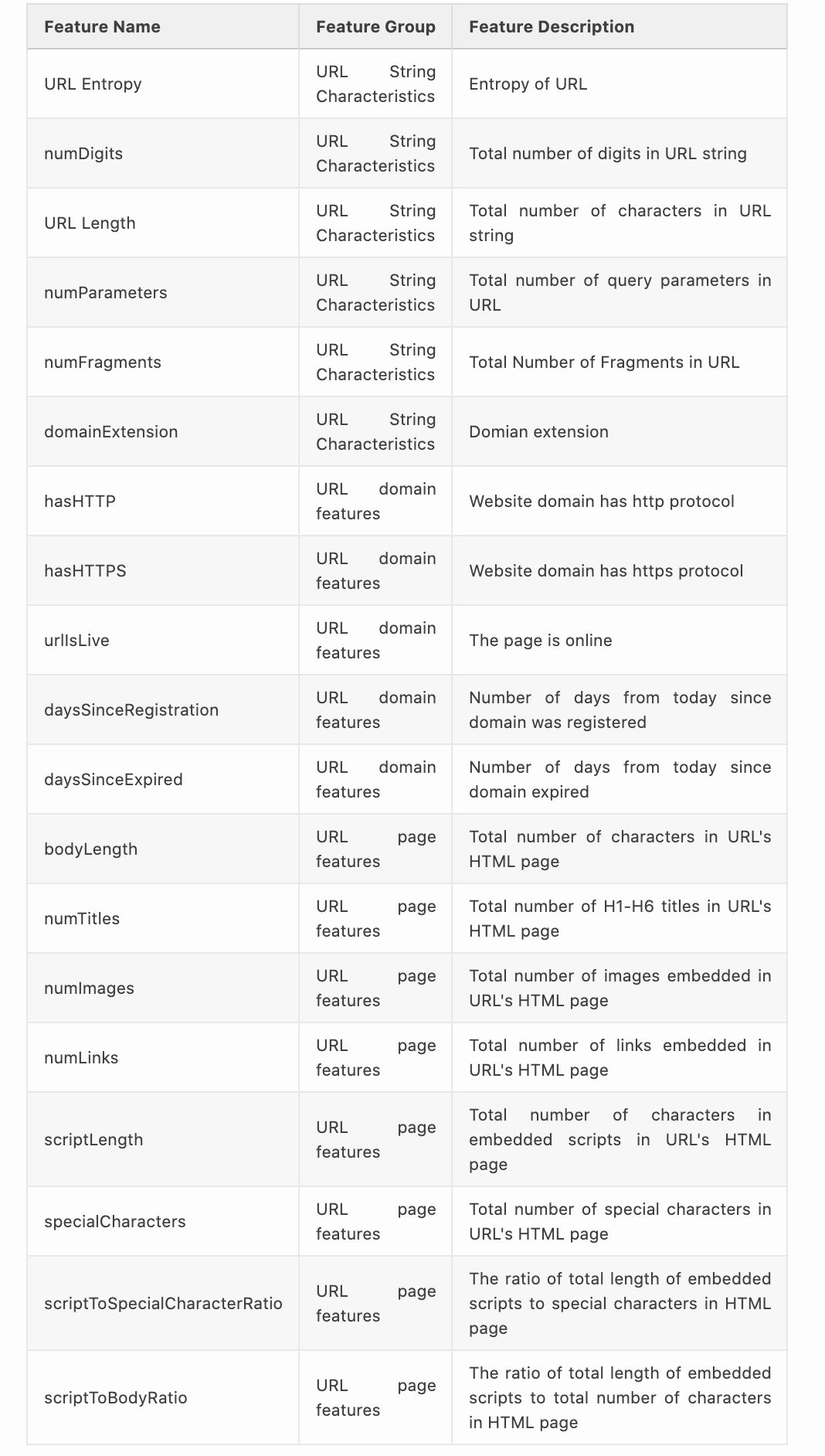
# This creates a feature vector from a URLclass UrlFeaturizer(object): def __init__(self, url): self.url = url self.domain = url.split('//')[-1].split('/')[0] self.today = datetime.now()
try: self.whois = whois.query(self.domain).__dict__ except: self.whois = None
try: self.response = get(self.url) self.pq = PyQuery(self.response.text) except: self.response = None self.pq = None
## URL string Features def entropy(self): string = self.url.strip() prob = [float(string.count(c)) / len(string) for c in dict.fromkeys(list(string))] entropy = sum([(p * math.log(p) / math.log(2.0)) for p in prob]) return entropy
def numDigits(self): digits = [i for i in self.url if i.isdigit()] return len(digits)
def urlLength(self): return len(self.url)
def numParameters(self): params = self.url.split('&') return len(params) - 1
def numFragments(self): fragments = self.url.split('#') return len(fragments) - 1
def numSubDomains(self): subdomains = self.url.split('http')[-1].split('//')[-1].split('/') return len(subdomains)-1
def domainExtension(self): ext = self.url.split('.')[-1].split('/')[0] return ext
## URL domain features def hasHttp(self): return 'http:' in self.url def hasHttps(self): return 'https:' in self.url def urlIsLive(self): return self.response == 200
def daysSinceRegistration(self): if self.whois and self.whois['creation_date']: diff = self.today - self.whois['creation_date'] diff = str(diff).split(' days')[0] return diff else: return 0 def daysSinceExpiration(self): if self.whois and self.whois['expiration_date']: diff = self.whois['expiration_date'] - self.today diff = str(diff).split(' days')[0] return diff else: return 0
## URL Page Features def bodyLength(self): if self.pq is not None: return len(self.pq('html').text()) if self.urlIsLive else 0 else: return 0 def numTitles(self): if self.pq is not None: titles = ['h{}'.format(i) for i in range(7)] titles = [self.pq(i).items() for i in titles] return len([item for s in titles for item in s]) else: return 0 def numImages(self): if self.pq is not None: return len([i for i in self.pq('img').items()]) else: return 0 def numLinks(self): if self.pq is not None: return len([i for i in self.pq('a').items()]) else: return 0
def scriptLength(self): if self.pq is not None: return len(self.pq('script').text()) else: return 0
def specialCharacters(self): if self.pq is not None: bodyText = self.pq('html').text() schars = [i for i in bodyText if not i.isdigit() and not i.isalpha()] return len(schars) else: return 0
def scriptToSpecialCharsRatio(self): if self.pq is not None: sscr = self.scriptLength()/self.specialCharacters else: sscr = 0 return sscr
def scriptTobodyRatio(self): if self.pq is not None: sbr = self.scriptLength()/self.bodyLength else: sbr = 0 return sbr
def bodyToSpecialCharRatio(self): if self.pq is not None: bscr = self.specialCharacters()/self.bodyLength else: bscr = 0 return bscr
def run(self): data = {} data['entropy'] = self.entropy() data['numDigits'] = self.numDigits() data['urlLength'] = self.urlLength() data['numParams'] = self.numParameters() data['hasHttp'] = self.hasHttp() data['hasHttps'] = self.hasHttps() data['urlIsLive'] = self.urlIsLive() data['bodyLength'] = self.bodyLength() data['numTitles'] = self.numTitles() data['numImages'] = self.numImages() data['numLinks'] = self.numLinks() data['scriptLength'] = self.scriptLength() data['specialChars'] = self.specialCharacters() data['ext'] = self.domainExtension() data['dsr'] = self.daysSinceRegistration() data['dse'] = self.daysSinceExpiration() data['sscr'] = self.scriptToSpecialCharsRatio() data['sbr'] = self.scriptTobodyRatio() data['bscr'] = self.bodyToSpecialCharRatio() return dataRunning the script above produces the following data with 23 features. We will separate integers, booleans, and object column names into separate lists for easier data access.
运行上面的脚本会生成具有23个功能的以下数据。 我们将整数,布尔值和对象列名称分成单独的列表,以简化数据访问。
objects = [i for i in data.columns if 'object' in str(data.dtypes[i])]booleans = [i for i in data.columns if 'bool' in str(data.dtypes[i])]ints = [i for i in data.columns if 'int' in str(data.dtypes[i]) or 'float' in str(data.dtypes[i])]删除高度相关的功能 (Removing Highly Correlated Features)
The most linear analysis assumes non-multicollinearity between predictor variables i.e pairs of predictor features must not be correlated. The intuition behind this assumption is that there is no additional information added to a model with multiple correlated features as the same information is captured by one of the features.
最线性的分析假定了预测变量之间的非多重共线性,即,预测特征对之间必须不相关。 该假设背后的直觉是,没有将附加信息添加到具有多个相关特征的模型中,因为其中一个特征捕获了相同的信息。
Multi-correlated features are also indicative of redundant features in the data and dropping them is a good first step for data dimension reduction. By removing correlated features (and only keeping, one of the groups of observed correlated features), we can address the issues of feature redundancy and collinearity between predictors.
多重关联的特征还指示数据中的冗余特征,将其删除是减少数据维度的良好第一步。 通过删除相关特征(并且仅保留观察到的相关特征组之一),我们可以解决预测变量之间的特征冗余和共线性问题。
Let’s create a simple correlation grid to observe the correlation between the derived features for malicious and benign URL and remove one or more of highly correlated features.
让我们创建一个简单的关联网格,以观察恶意和良性URL的衍生功能之间的关联,并删除一个或多个高度关联的功能。
corr = data[ints+booleans].corr()# Generate a mask for the upper trianglemask = np.triu(np.ones_like(corr, dtype=np.bool))# Set up the matplotlib figuref, ax = plt.subplots(figsize=(20, 15))# Generate a custom diverging colormapcmap = sns.diverging_palette(220, 10, as_cmap=True)# Draw the heatmap with the mask and correct aspect ratiosns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0, square=True, linewidths=.5, cbar_kws={"shrink": .5}, annot=True)
However, we do not want to remove all correlated variables-only those with a very strong correlation that do not add extra information to the model. For this, we define a certain ‘threshold’ (0.7) for positive and negative correlation observed.
但是,我们不希望删除所有相关变量,而只删除那些具有很强相关性且不会向模型添加额外信息的变量。 为此,我们为观察到的正相关和负相关定义了某个“阈值”(0.7)。
We see that most of the highly correlated features are negatively correlated. For example, there is a 0.56 negative correlation coefficient between the number of characters in a URL and the entropy of the URL which suggests that shorter URLs have
我们看到大多数高度相关的特征是负相关的。 例如,URL中的字符数与URL的熵之间存在0.56的负相关系数,这表明较短的URL具有
Here we will create a function to identify and drop one of multiple correlated features.
在这里,我们将创建一个函数来识别和删除多个相关特征之一。
def dropMultiCorrelated(cormat, threshold): ## Define threshold to remove pairs of features with correlation coefficient greater than 0.7 or -0.7 threshold = 0.7 # Select upper triangle of correlation matrix upper = cormat.abs().where(np.triu(np.ones(cormat.shape), k=1).astype(np.bool)) # Find index of feature columns with correlation greater than threshold to_drop = [column for column in upper.columns if any(upper[column] > threshold)] for d in to_drop: print("Dropping {}....".format(d)) return to_dropdata2 = data[corr.columns].drop(dropMultiCorrelated(corr, 0.7), axis=1)Dropping urlLength....Dropping scriptLength....Dropping specialChars....Dropping bscr....Dropping hasHttps....预测URL的恶意(决策树) (Predicting Maliciousness of URLs (Decision Trees))
Modeling builds a blueprint for explaining data, from previously observed patterns in the data. Modeling is often predictive in that it tries to use this developed ‘blueprint’ in predicting the values of future or new observations based on what it has observed in the past.
建模会根据数据中先前观察到的模式构建用于解释数据的蓝图。 建模通常是可预测的,因为它会尝试使用已开发的“蓝图”根据过去的观测结果预测未来或新观测值。
Based on the extracted features, we want the best predictive model that tells us if an unseen URL is malicious or benign. Therefore, we seek a unique combination of useful features to accurately separate malicious from benign URLs. We will go through two stages, feature selection, where we select only features useful in predicting the target variable and modeling with decision trees to develop a predictive model for malicious and benign URLs.
基于提取的功能,我们需要最佳的预测模型,该模型可以告诉我们看不见的URL是恶意的还是良性的。 因此,我们寻求有用功能的独特组合,以准确区分恶意URL和良性URL。 我们将经历两个阶段,即特征选择,在此阶段中,我们仅选择对预测目标变量有用的特征以及使用决策树建模以开发恶意和良性URL的预测模型。
功能选择 (Feature Selection)
What variables are most useful in identifying a URL as ‘malicious’ or ‘benign’? Computationally, we can automatically select what variables are most useful by testing which ones ‘improves’ or ‘fails to improve’ the overall performance of the prediction model. This process is called ‘Feature Selection’. Feature selection also serves the purpose of reducing the dimension of data, addressing issues of computational complexity and model performance. The goal of feature selection is to obtain a useful subset of the original data that is predictive of the target feature in such a way that useful information is not lost (considering all predictors together). Although feature selection goes beyond simple correlation elimination, for this article, we limit our feature selection method simply retaining these features. Let’s create a subset of the original data that contain only uncorrelated features.
哪些变量在将URL标识为“恶意”或“良性”时最有用? 通过计算,我们可以通过测试哪些变量“改善”或“未能改善”预测模型的整体性能来自动选择最有用的变量。 此过程称为“功能选择”。 特征选择还用于减小数据量,解决计算复杂性和模型性能的问题。 特征选择的目的是以不丢失有用信息(将所有预测变量都考虑在内)的方式获得可预测目标特征的原始数据的有用子集。 尽管特征选择超出了简单的相关性消除,但在本文中,我们限制了仅保留这些特征的特征选择方法。 让我们创建仅包含不相关功能的原始数据的子集。
predictor_columns = data2.columnsd = data2[predictor_columns]x, y = d[predictor_columns], data['vt_class']We keep only features that are unique in their contribution to the model. We can now start developing the model with 70% of the original sample and these 14 features. We will keep 30% of the sample to evaluate the model’s performance on new data.
我们仅保留对模型的贡献独特的特征。 现在,我们可以使用原始样本的70%和这14个功能来开发模型。 我们将保留30%的样本,以根据新数据评估模型的性能。
- numServices
numServices - entropy
熵 - numDigits
numDigits - numParams
numParams - bodyLength
体长 - numTitles
numTitles - numImages
numImages - numLinks
numLinks - dsr
数码单反相机 - dse
dse - sscr
sscr - sbr
sbr - robots
机器人 - hasHttp
hasHttp
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 100)决策树 (Decision Trees)
from sklearn import treefrom sklearn.metrics import accuracy_scorefrom sklearn.externals.six import StringIO from IPython.display import Image from sklearn.tree import export_graphvizimport pydotplusThere are multiple machine learning algorithms (classification) algorithms that can be applied to identifying malicious URLs. After converting URLs to a representative feature vector, we model the ‘malicious URL identification problem’ as a binary classification problem. A binary classification model trains a predictive model for a class with only two outcomes ‘Malicious’ and ‘Benign’. Batch learning algorithms are machine learning algorithms that work under the following assumptions:
有多种机器学习算法(分类)算法可用于识别恶意URL。 将URL转换为代表性特征向量后,我们将“恶意URL识别问题”建模为二进制分类问题。 二进制分类模型为只有两个结果“恶意”和“良性”的班级训练预测模型。 批处理学习算法是在以下假设下工作的机器学习算法:
- the entire training data is available before model development and
- the entire training data is available before model development and
- the target variable is known before the model training task.
- the target variable is known before the model training task.
Batch algorithms are ideal and effective in that they are explainable discriminative learning models that use simple loss minimization between training data points. Decision trees are one such batch learning algorithms in machine learning.
批处理算法是理想且有效的方法,因为它们是可解释的判别性学习模型,该模型使用训练数据点之间的简单损失最小化。 决策树就是这样一种机器学习中的批量学习算法。
In decision analysis, a decision tree is a visual representation of a model’s decision-making process to arrive at certain conclusions. The basic idea behind decision trees is an attempt to understand what factors influence class membership or why a data point belongs to a class label. A decision tree explicitly shows the conditions on which class members are made. Therefore they are a visual representation of the decision-making process.
在决策分析中,决策树是模型决策过程的直观表示,可以得出某些结论。 决策树背后的基本思想是试图了解哪些因素影响类成员资格或数据点为何属于类标签。 决策树明确显示了创建类成员的条件。 因此,它们是决策过程的直观表示。
Decision tree builds predictive models by breaking down the data set into smaller and smaller parts. The decision to split a subset is based on maximizing the information gain or minimizing information loss from splitting. Starting with the root node (the purest feature with no uncertainty), the tree is formed by creating various leaf nodes based on the purity of the subset.
决策树通过将数据集分解为越来越小的部分来构建预测模型。 分割子集的决定基于最大化信息增益或最小化来自分割的信息损失。 从根节点(没有不确定性的最纯特征)开始,通过基于子集的纯度创建各种叶节点来形成树。
In this case, the decision tree will explain class boundaries for each feature to classify a URL as malicious or benign. There are two main factors to consider when building a decision tree:
在这种情况下,决策树将解释每个功能的类边界,以将URL分类为恶意或良性。 构建决策树时,需要考虑两个主要因素:
- a) What criteria to use in splitting or creating leaf nodes and- b) tree pruning to control how long a tree is allowed to grow to control the risk of over-fitting.
- a) What criteria to use in splitting or creating leaf nodes and- b) tree pruning to control how long a tree is allowed to grow to control the risk of over-fitting.
The criterion parameter of the decision tree algorithm specifies what criteria (Gini or entropy) to control for while the max_depth parameter controls how far the tree is allowed to grow. Gini measurement is the probability of a random sample being classified incorrectly if we randomly pick a label according to the distribution in a branch. Entropy is a measurement of information (or rather lack thereof).
决策树算法的标准参数指定要控制的标准(Gini或熵),而max_depth参数则控制允许树增长多远。 基尼系数测量是如果我们根据分支中的分布随机选择标签,则随机样本被错误分类的概率。 熵是信息(或缺乏信息)的度量。
Unfortunately, since there is no prior knowledge of the right combination of criteria and tree depth, we would have to iteratively test for the optimal values of these two parameters. We test a max_depth for 50 iterations for both criteria and visualize the model accuracy scores.
不幸的是,由于没有关于标准和树深度的正确组合的先验知识,我们将不得不迭代测试这两个参数的最佳值。 我们针对两个标准测试了50次迭代的max_depth,并可视化了模型的准确性得分。
maxd, gini, entropy = [], [], []for i in range(1,50): ### dtree = tree.DecisionTreeClassifier(criterion='gini', max_depth=i) dtree.fit(X_train, y_train) pred = dtree.predict(X_test) gini.append(accuracy_score(y_test, pred))
#### dtree = tree.DecisionTreeClassifier(criterion='entropy', max_depth=i) dtree.fit(X_train, y_train) pred = dtree.predict(X_test) entropy.append(accuracy_score(y_test, pred))
#### maxd.append(i) ####d = pd.DataFrame({'gini':pd.Series(gini), 'entropy':pd.Series(entropy), 'max_depth':pd.Series(maxd)})# visualizing changes in parametersplt.plot('max_depth','gini', data=d, label='Gini Index')plt.plot('max_depth','entropy', data=d, label='Entropy')plt.xlabel('Max Depth')plt.ylabel('Accuracy')plt.legend()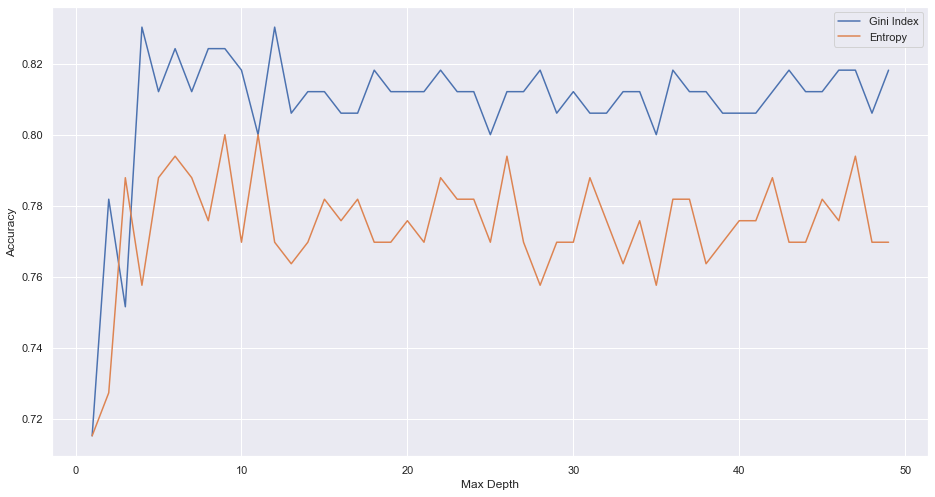
It seems the best model is the simplest one with the Gini index and a max depth of 4 with 84% out of sample accuracy. Also, maximizing the entropy does not seem to produce good results suggesting that new parameters added to the model do not necessarily give new information but may produce improved node probability purity. So we can fit and visualize the tree with max_depth = 4 and Gini criteria to identify which features are most important in separating malicious and benign URLs.
似乎最好的模型是最简单的模型,具有基尼系数,最大深度为4,样本精度为84%。 同样,最大化熵似乎并不会产生好的结果,这表明添加到模型中的新参数不一定提供新信息,而是可以提高节点概率纯度。 因此,我们可以使用max_depth = 4和基尼标准来拟合和可视化树,以识别哪些功能在分离恶意URL和良性URL中最重要。
Build the model….
建立模型…。
###create decision tree classifier objectDT = tree.DecisionTreeClassifier(criterion="gini", max_depth=4)##fit decision tree model with training dataDT.fit(X_train, y_train)##test data predictionDT_expost_preds = DT.predict(X_test)Visualize the tree …
可视化树…
dot_data = StringIO()export_graphviz(DT, out_file=dot_data, filled=True, rounded=True, special_characters=True,feature_names=X_train.columns, class_names=DT.classes_)graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png())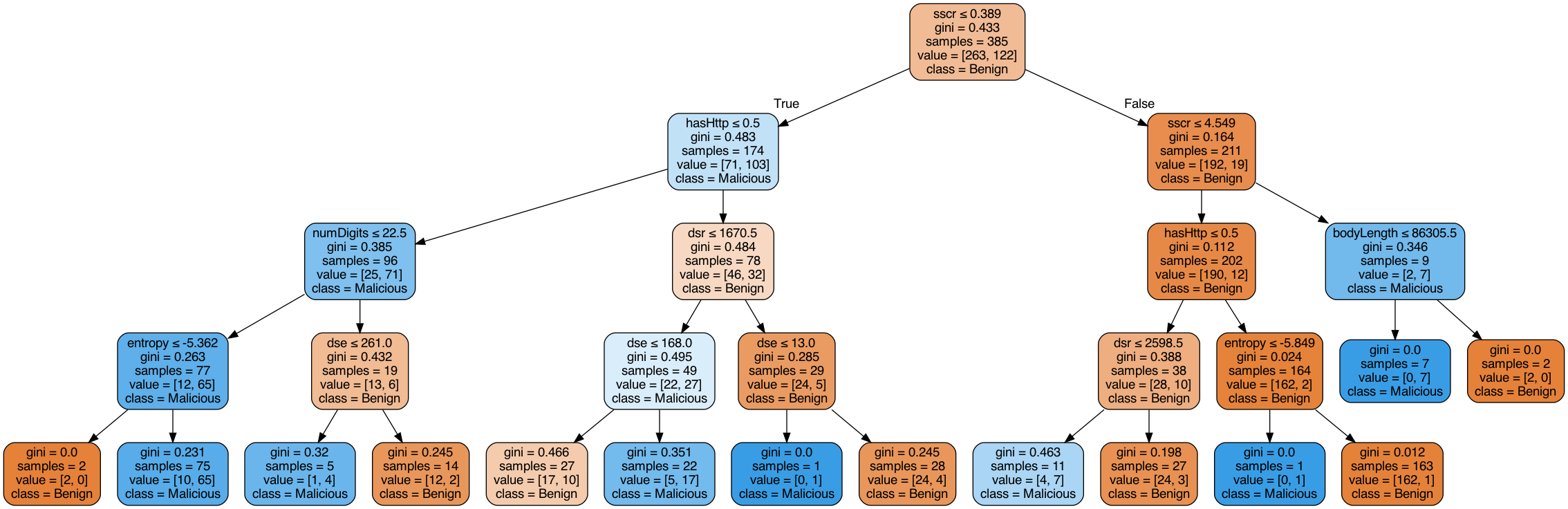
The accuracy of prediction models is very sensitive to parameter tuning of the max_depth (tree pruning) and split quality criteria (node splitting). This also helps in achieving the simplest parsimonious model that prevents over-fitting and performs just as well on unseen data. These parameters are specific to different data problems and it is good practice to test a combination of different parameter values.
预测模型的准确性对max_depth的参数调整(树修剪)和分割质量标准(节点分割)非常敏感。 这也有助于实现最简单的简约模型,该模型可以防止过度拟合并在看不见的数据上表现出色。 这些参数特定于不同的数据问题,并且优良作法是测试不同参数值的组合。
The model shows that malicious URLs have a lower script to special character ratio (sscr) and URL characters that are relatively more ‘ordered’ or more monotonous. Additionally, malicious URLs may have domains that have expired somewhere between 5–9 months ago. We also know of issues of ‘malvertising’ where scammers take ownership of expired legitimate domains to distribute downloadable malicious codes. Finally, probably the most distinguishing feature of benign URLs is longevity. They seem to moderate script to special character ratio in HTML body content with longer domain lifetime of 4–8 years.
该模型表明,恶意URL的脚本与特殊字符比率(sscr)较低,而URL字符则相对“有序”或更单调。 此外,恶意URL可能具有5-9个月前过期的域名。 我们还知道“恶意”问题,骗子会骗取过期合法域的所有权来分发可下载的恶意代码。 最后,良性URL的最大特色可能是寿命。 他们似乎在HTML正文内容中适度地调整了脚本与特殊字符的比例,具有更长的4-8年的域生存期。
翻译自: https://towardsdatascience.com/predicting-the-maliciousness-of-urls-24e12067be5
恶意url
相关文章:
- 图片上传流程前端上传文件后端保存文件并返回图片地址
- 技术解读|RRBS测序中因酶切人为引入碱基问题
- 01-【浏览器】chrome浏览器收藏夹(书签)的导出与导入
- 如何将WIN10自带浏览器Microsoft Edge中的书签导出
- 360浏览器html位置,win7系统查看360浏览器收藏夹位置的操作方法
- 浏览器收藏夹(书签)导入导出
- edge如何导入html文件收藏夹,win10系统edge浏览器收藏夹导入/导出的操作方法
- Edge的收藏夹内容导出导入转移
- 360浏览器怎么导入html,如何将360浏览器收藏网页导入到火狐浏览器中
- 将favdb转换成html,360浏览器收藏夹使用小记
- 360浏览器收藏夹导出问题终极解决方案
- 360html收藏夹,360浏览器的收藏夹如何保存?360浏览器收藏夹备份方法
- 导出收藏到html是什么意思,详细说明如何导出浏览器的收藏夹
- edge如何导入html文件收藏夹,Edge浏览器如何导入导出收藏夹(目录位置)
- 计算机收藏夹位于哪个磁盘,电脑浏览器收藏夹保存在哪里
- 360浏览器怎么导入html,360浏览器收藏夹导入/导出方法详解
- 收藏夹导出至html,分享win7电脑中三种导出浏览器收藏夹地址方法
- chrome浏览器收藏夹(书签)的导出与导入
- IE浏览器如何导入导出收藏夹
- 浏览器的收藏夹的导入导出
- 微信小程序转码机器人搭建方法,可爱猫,vml机器人插件
- 微信小程序使用mock.js
- 微信视频气泡 android,变变微信聊天气泡
- 龙之谷2微信哪个服务器,龙之谷2微信区
- 程序员微信名昵称_数据分析告诉你,微信里好友们的昵称,也是一门很深的学问...
- 可爱猫python_安装 · 【可爱猫】 微信机器人的 http插件 · 看云
- 可爱猫+python3+Flask+aiohttp简单搭建微信机器人
- 测试集和训练集8:2切分
- 积分激活大数据生态圈 堪比虚拟货币
- 机上WiFi 万米高空不断线
恶意url_预测URL的恶意相关推荐
- 利用MLAI判定未知恶意程序——里面提到ssl恶意加密流检测使用N个payload CNN + 字节分布包长等特征综合判定...
利用ML&AI判定未知恶意程序 导语:0x01.前言 在上一篇ML&AI如何在云态势感知产品中落地中介绍了,为什么我们要预测未知恶意程序,传统的安全产品已经无法满足现有的安全态势.那么 ...
- [系统安全] 三十一.恶意代码检测(1)恶意代码攻击溯源及恶意样本分析
您可能之前看到过我写的类似文章,为什么还要重复撰写呢?只是想更好地帮助初学者了解病毒逆向分析和系统安全,更加成体系且不破坏之前的系列.因此,我重新开设了这个专栏,准备系统整理和深入学习系统安全.逆向分 ...
- 恶意代码分析实战 8 恶意代码行为
8.1 Lab 11-01 代码分析 首先使用strings进行分析. Gina是在 msgina.dll中的. 很多有关资源的函数. 关于注册表的函数. 使用ResourceHacker查看. 发现 ...
- Bitdefender 查询域名和url是否恶意
Bitdefender在国内感觉文档还是比较少,都没怎么看到,今天公司给了个api要求把文件中的域名或者url给筛选出恶意与非恶意了,文档中只写了两种语言的例子,python和php,我这里就使用py ...
- 恶意代码分析实战 11 恶意代码的网络特征
11.1 Lab14-01 问题 恶意代码使用了哪些网络库?它们的优势是什么? 使用WireShark进行动态分析. 使用另外的机器进行分析对比可知,User-Agent不是硬编码. 请求的URL值得 ...
- 使用机器学习检测TLS 恶意加密流——业界调研***有开源的数据集,包括恶意证书的,以及恶意tls pcap报文***...
2018 年的文章, Using deep neural networks to hunt malicious TLS certificates from:https://techxplore.com ...
- android 恶意广告,CheckPoint:Android恶意广告软件SimBad被下载近1.5亿次
文章来源:cnBeta.COM 原文链接: https://m.cnbeta.com/wap/view/827257.htm 安全企业 CheckPoint 最新报告称,谷歌 Play 商店中的 20 ...
- 恶意代码检测c语言,恶意代码检测分析软件
恶意代码辅助分析工具最新版,这款就是刚被优化的代码检测软件,最大的用处的就是帮助你们检测自己电脑中的恶意代码,从而让你们一直拥有安全稳定的环境. 软件简介: 可以分析出系统里恶意代码的软件,免受电脑受 ...
- php 恶意上传,如何防止恶意文件上传到我的服务器上?(检查文件类型)?
我的问题是避免用户在我的web服务器上上传恶意文件. 我在linux环境(debian)上工作. 实际上,上传是通过以下代码通过php处理的:function checkFile($nomeFile, ...
最新文章
- WindowsPhone基础琐碎总结-----数据绑定(一)
- objdump and readelf
- Linux统计某个文件夹下的文件个数、目录个数
- xshell下载mysql到本地文件_在Xshell中上传下载文件到本地(linux中从多次ssh登录的dbserver里面的文件夹)-Go语言中文社区...
- Windows 下 修改 Anaconda3 jupyter 默认启动目录
- 使用onnx包将pth文件转换为onnx文件
- android jni 返值
- LNMP1.3 一键配置环境,简单方便
- 预览docx_Windows-快速预览文件-QuickLook
- 如何用xml 描述目录结构_如何用英语描述人物外表
- 数学建模、统计学之方差分析
- linux用户名不在sudoers,如何修复“用户名不在sudoers文件中。这个事件将报告“在Ubuntu...
- 学术会议查询 边缘计算_我设计了可以预测边缘性的“学术不诚实”的AI系统(SMART课堂)...
- lj245a引脚功能图_干货|教你如何看懂单片机时序图
- 简述hdfs工作原理_HDFS 原理简述
- switch交换的vlan三种模式详解
- matlab gui图标,matlab GUI
- (前端发邮件)vue中使用smtp.js发送邮件
- windbg命令解释
- 2019牛客暑期多校9H:Cutting Bamboos【主席树+二分】