爬取李子柒微博评论并分析
爬取李子柒微博评论并分析
微博主要分为网页端、手机端和移动端。微博网页版反爬太厉害,因此选择爬取手机端。
微博手机端地址:https://m.weibo.cn
1 需求
爬取李子柒微博中视频的评论信息,并做词频分析。
词频分析:http://cloud.niucodata.com/
2 方法
2.1 运行环境
- 运行平台: Windows
- Python版本: Python3.7
- IDE: PyCharm
2.2 爬取数据
首先要先找到自己的cookie,认识手机微博端的数据是如何进行加载的。手机微博是使用Ajax动态加载数据。这里以李子柒置顶视频为例,地址为:https://m.weibo.cn/detail/4206005635846050
在开发者工具下,network-xdr下找到以下信息:
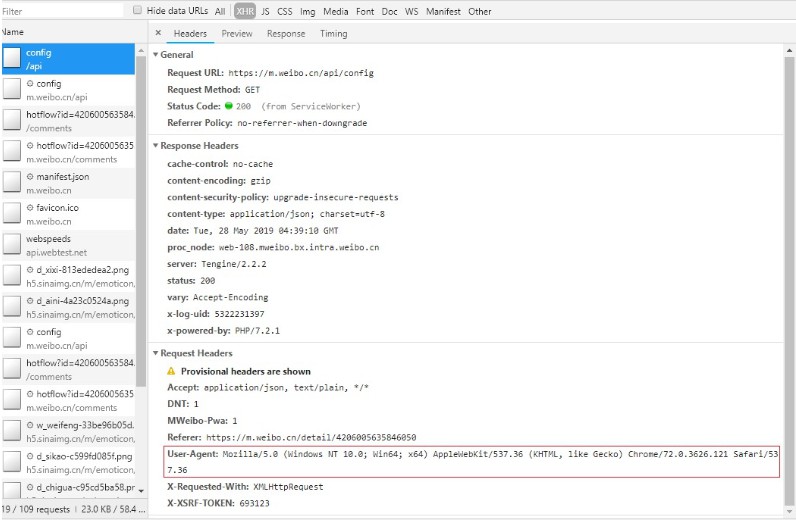
此外,还需要对比request url的组成,找出翻页规律:
Request URL: https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id_type=0``Request URL: https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id=849522136223909&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id=168099804860905&max_id_type=0
经过对比发现,翻页时的两个关键信息为max_id和max_id_type,只要找到这两个信息,就可以对url进行拼接,从而实现多次爬取。这两个信息可以在之前返回的json文件中的preview找到。
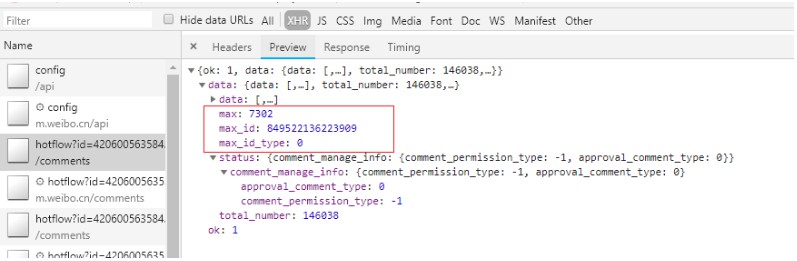
接下来是爬虫程序的设计:
``
# -*- coding: utf-8 -*-import requests
import time
import os
import csv
import sys
import json
from bs4 import BeautifulSoup
import importlib
importlib.reload(sys)# 要爬取热评的起始url
url = 'https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id='
# cookie UA要换成自己的
headers = {'Cookie': '','Referer': 'https://m.weibo.cn/detail/4206005635846050','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36','X-Requested-With': 'XMLHttpRequest'
}def get_page(max_id, id_type):params = {'max_id': max_id,'max_id_type': id_type}try:r = requests.get(url, params=params, headers=headers)if r.status_code == 200:return r.json()except requests.ConnectionError as e:print('error', e.args)def parse_page(jsondata):if jsondata:items = jsondata.get('data')item_max_id = {}item_max_id['max_id'] = items['max_id']item_max_id['max_id_type'] = items['max_id_type']return item_max_iddef write_csv(jsondata):datas = jsondata.get('data').get('data')for data in datas:created_at = data.get("created_at")like_count = data.get("like_count")source = data.get("source")floor_number = data.get("floor_number")username = data.get("user").get("screen_name")comment = data.get("text")comment = BeautifulSoup(comment, 'lxml').get_text()writer.writerow([username, created_at, like_count, floor_number, source,json.dumps(comment, ensure_ascii=False)])# 存为csv
path = os.getcwd() + "/weiboComments.csv"
csvfile = open(path, 'w',encoding = 'utf-8')
writer = csv.writer(csvfile)
writer.writerow(['Usename', 'Time', 'Like_count', 'Floor_number', 'Sourse', 'Comments'])maxpage = 50 #爬取的数量
m_id = 0
id_type = 0
for page in range(0, maxpage):print(page)jsondata = get_page(m_id, id_type)write_csv(jsondata)results = parse_page(jsondata)time.sleep(1)m_id = results['max_id']id_type = results['max_id_type']
2.3 数据清洗与处理
按照上述代码分别得到五个数据集,但是得到的数据集充满噪声,要对该数据进行清洗,由于本文得到的评论数据已经较为干净,因此主要处理stop word、标点符号和表情符即可。为了简化工作,先用文本整理器软件对空值进行删除。
停词表采用的是哈工大停词表。
爬取李子柒微博评论并分析相关推荐
- python爬取微博评论并做词频分析_爬取李子柒微博评论并分析
爬取李子柒微博评论并分析 微博主要分为网页端.手机端和移动端.微博网页版反爬太厉害,因此选择爬取手机端. 1 需求 爬取李子柒微博中视频的评论信息,并做词频分析. 2 方法 2.1 运行环境 运行平台 ...
- Pyppeteer爬取移动端微博评论区简单案例
在简单学习了Pyppeteer之后,就想利用其来实现一个爬取实战来巩固知识,也是为了做点东西,让学的东西不那么空洞. 然后选取了微博评论区进行爬取. 但是在复制网页端的微博的节点的Selector并进 ...
- 阿凡达时隔十年重映,王者归来还是炒冷饭?Python爬取上千条评论并分析
[CSDN 编者按]<阿凡达>十年后再次重映,果不其然话题量十足,可能这就是神级影片的召唤力吧.在怀旧的氛围中,我们得以重新审阅这部曾经的现象级.划时代的作品. 作者 | 刘早起 ...
- 爬取携程景点评论数据【最新方法】,分析AJAX实现页数跳转的爬取方法
本文仅供技术学习使用,欢迎转载,转载请注明出处 因为朋友参加数学建模,需要景点数据,而我刚好懂一点点,就帮他写爬虫代码.在网上搜索到一些爬虫方法,但在获取景点ID时,发现现在携程的Request Pa ...
- python爬取网易云音乐评论并进行可视化分析
2019独角兽企业重金招聘Python工程师标准>>> 前言 今天为大家一个爬取网易云音乐评论的Python案例,并用Python的第三方库来进行可视化分析,生成图表样式,可以清晰地 ...
- python爬取客流数据_Python爬取南京地铁微博发布客流数据并进行分析
Python爬取南京地铁微博发布客流数据并进行分析 之前在网上看到了分析北京地铁客流数据的开源项目,就想试着分析一下南京地铁的客流数据,可是找了很久没有找到可以获得南京地铁客流数据的接口,就去南京地铁 ...
- Python爬取南京地铁微博发布客流数据并进行分析
Python爬取南京地铁微博发布客流数据并进行分析 之前在网上看到了分析北京地铁客流数据的开源项目,就想试着分析一下南京地铁的客流数据,可是找了很久没有找到可以获得南京地铁客流数据的接口,就去南京地铁 ...
- python爬取网易云音乐评论分析_python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comme ...
- python爬携程景区评论_python爬取携程景点评论信息
python爬取携程景点评论信息 今天要分析的网站是携程网,获取景点的用户评论,评论信息通过json返回API,页面是这个样子的 按下F12之后,F5刷新一下 具体需要URL Request的方式为P ...
最新文章
- GitHub 热门:机器学习 100 天!
- 【转】如何单独编译Android源代码中的模块--不错
- 用虚拟机学linux,虚拟机上学习Linux运维?学linux有什么用
- 数据库表字段命名规则
- tomcat实现多端口、多域名访问
- NoClassDefFoundError: org/mybatis/logging/LoggerFactory
- Jmeter笔记(5)线程组执行顺序
- Mac OS系统版本与XCode版本的关系
- stream of java_Java 8 新特性-Stream更优雅的处理集合入门
- mysql shell可视化_shell编程系列24--shell操作数据库实战之利用shell脚本将文本数据导入到mysql中...
- 设计模式学习笔记之装饰者模式
- 【iOS】NSNotification 常用方法
- 中国大陆省市区县三级、四级菜单数据整理
- Ubuntu 18.04 安装 Wine
- RuntimeWarning: invalid value encountered in arccos
- loadrunner—集合点rendezvous
- Confluence 摘要(Excerpt)宏
- Android ScrollView滚动区高度和子LinearLayout的layout_marginTop的关系
- 浏览器调取摄像头人脸抓拍实现
- python中sklearn实现决策树及模型评估_sklearn实现决策树