TFIDF算法Java实现
一、算法简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘中常用的加权技术。TF-IDF的概念被公认为信息检索中最重要的发明。在搜索、文献分类和其他相关领域有着广泛的应用。其具体应用包括关键词提取、文本相似度、自动摘要。
TF-IDF的主要思想是如果某个词在一篇文章中出现的频率TF很高,而且在语料库中的其他文章中出现的频率很低,那么认为这个词对于这篇文章而言,携带的信息很多,也就越重要。因此词的重要性与词在文章中出现的频率成正比,与其在整个语料库中出现的频率成反比
词频(term frequency,TF)指的是某一个给定的词语在给定文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 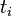 来说,它的重要性可表示为:
来说,它的重要性可表示为:

以上式子中 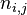 是该词 在文件
是该词 在文件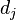 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文档频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中
- |D|:语料库中的文件总数
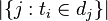 :包含词语的文件数目(即
:包含词语的文件数目(即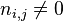 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用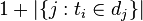
然后
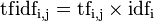
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
二、Java实现
package com.zqs.tfidf;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;/*** TFIDF算法Java实现* @author tianyunzqs**/
public class TFIDF implements Serializable {private static final long serialVersionUID = -1944746523865028204L;// 存放所有词汇public static Set<String> vocab = new LinkedHashSet<String>();// 单词 -idfpublic Map<String, Double> word_idf = new HashMap<String, Double>();/*** 训练样本的tfidf值,也即训练tfidf模型* @param raw_data 训练数据,如:[[我们 是 中国 的公民], [我们 是 炎黄之孙]](token为空格)* @param token 单词之间分隔符* @return 训练数据对应的tfidf数据列表*/public List<List<Double>> get_tfidf(List<String> raw_data, String token) {List<List<Double>> res = new ArrayList<List<Double>>();Map<String, Set<Integer>> word_docs = new HashMap<String, Set<Integer>>();Map<Integer, List<String>> doc_words = new HashMap<Integer, List<String>>();int doc_num = 0;for(String text : raw_data) {doc_num++;String[] words = text.split(token);doc_words.put(doc_num, Arrays.asList(words));for(String word : words) {vocab.add(word);if(word_docs.containsKey(word)) {word_docs.get(word).add(doc_num);} else {Set<Integer> docs = new HashSet<Integer>();docs.add(doc_num);word_docs.put(word, docs);}}}// 计算并存储每个word的idf值for(String word : vocab) {int doc_n = 0;if(word_docs.containsKey(word)) {doc_n = word_docs.get(word).size();}double idf = doc_words.size()*1.0 / (doc_n + 1);word_idf.put(word, idf);}// 计算每篇doc中,vocab中每个word的tfidf值for(Entry<Integer, List<String>> e : doc_words.entrySet()) {List<Double> tmp = new ArrayList<Double>();for(String word : vocab) {int word_n = Collections.frequency(e.getValue(), word);double tf = word_n*1.0 / e.getValue().size();double idf = word_idf.get(word);double tfidf = tf * idf;tmp.add(tfidf);}res.add(tmp);}return res;}/*** 计算测试样本的tfidf值* @param raw_data 测试数据* @param token 单词之间的分隔符* @return 测试数据的tfidf值*/public List<List<Double>> get_tfidf4test(List<String> raw_data, String token) {List<List<Double>> text_tfidf = new ArrayList<List<Double>>();for(String text : raw_data) {String[] words = text.split(token);List<String> words_list = Arrays.asList(words);List<Double> tmp = new ArrayList<Double>();for(String word : vocab) {int word_n = Collections.frequency(words_list, word);double tf = word_n*1.0 / words.length;double tfidf = tf * word_idf.get(word);tmp.add(tfidf);}text_tfidf.add(tmp);}return text_tfidf;}/*** 序列化保存tfidf模型* @param path 模型路径*/public void save_model(String path) {try {ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(path));oos.writeObject(this);oos.flush();oos.close();} catch (IOException e) {e.printStackTrace();}}/*** 导出tfidf模型* @param path 模型路径* @return 训练好的TFIDF模型*/public TFIDF load_model(String path) {try {ObjectInputStream in = new ObjectInputStream(new FileInputStream(path));TFIDF tfidf = (TFIDF) in.readObject();in.close();return tfidf;} catch (IOException ee){ee.printStackTrace();} catch (ClassNotFoundException e){e.printStackTrace();}return null;}public static void main(String[] args) {TFIDF tfidf = new TFIDF();List<String> res = new ArrayList<String>();res.add("我们 是 中国人");res.add("他们 是 美国人");res.add("你们 来自 哪里 呢 最 无论 不管 the 中国人");List<List<Double>> a = tfidf.get_tfidf(res, " ");System.out.println(vocab);for(List<Double> e : a) {System.out.println(e);}List<String> res2 = new ArrayList<String>();res2.add("我们 是 中国 公民");res2.add("我们 是 中国 的 公民");List<List<Double>> b = tfidf.get_tfidf4test(res2, " ");System.out.println(vocab);for(List<Double> e : b) {System.out.println(e);}}
}
参考资料:
1、https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin
2、吴军. 数学之美[M]. 北京:人民邮电出版社, 2014
3、http://www.cnblogs.com/chenny7/p/4002368.html
4、http://blog.csdn.net/sangyongjia/article/details/52440063
TFIDF算法Java实现相关推荐
- Hanlp分词实例:Java实现TFIDF算法
2019独角兽企业重金招聘Python工程师标准>>> 算法介绍 最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理. 关于TFIDF算法的介绍可以参考这篇 ...
- java hanlp分词_Hanlp分词实例:Java实现TFIDF算法
算法介绍 最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理. 关于TFIDF算法的介绍可以参考这篇博客http://www.ruanyifeng.com/blog/2013 ...
- Data Mining Machine Learning 之文本预处理 文档关键值权值Java TF-IDF算法实现 (四)
IDF weighting(Inverse Document Frequency)** 逆文档频率权重 Suppose a token t IDF(t) = log(ND/NDt) ND表示 the ...
- 《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
本节书摘来自华章计算机<Hadoop与大数据挖掘>一书中的第2章,第2.6节,作者 张良均 樊哲 位文超 刘名军 许国杰 周龙 焦正升,更多章节内容可以访问云栖社区"华章计算机& ...
- TF-IDF的java实现(权重排序,可用来处理大数据集)
TFIDF的主要思想 程序使用 程序结果 TFIDF的主要思想 TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力 ...
- tfidf处理代码_Java实现TFIDF算法代码分享
算法介绍 概念 TF-IDF(term frequencyCinverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术.TF-IDF是一种统计方法,用以评估一字词 ...
- bm25算法Java代码_搜索引擎相关度算法 -BM25 JAVA实现
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法. 它的出现主要是解决TF-IDF算法中 TF的影响可无限增大的不足,本质上 BM25是基于TF-IDF并做了改 ...
- 推特雪花算法 java实现
2019独角兽企业重金招聘Python工程师标准>>> package twiter.snowflake;/*** twitter的snowflake算法 -- java实现*/ p ...
- TF-IDF算法原理介绍
参考文章链接1 参考文章链接2 TF-IDF算法代码实战
- 数据挖掘:基于TF-IDF算法的数据集选取优化
前言: 此前在做一个关于文本分类的小调研.本人使用的是基于朴素贝叶斯的文本分类算法,关于朴素贝叶斯的文本分类更多的内容,请参见<数据挖掘:基于朴素贝叶斯分类算法的文本分类实践>. 不过在做 ...
最新文章
- 物联网技术的发展历史及关键技术
- CV之ICG:计算机视觉之图像标题生成(Image Caption Generator)算法的简介、使用方法、案例应用之详细攻略
- linux的vi命令详解,Linux上Vi命令详解
- c语言goto语句用法_C语言的9种控制结构
- mysql配置主从时报错及处理
- pytorch---模型加载与保存(5)使用在不同模型参数下的热启动模式
- RxJava:concat(连接)、 concatDelayError、 concatEager的使用
- 奥斯汀页眉怎么设置_Word页眉横线怎么去掉与页眉页脚如何设置删除,含首页、奇数偶数页、横纵向页不同及第一页与最后一页不要页...
- Opencv 提取水平 垂直线,去除杂线,提取对象
- 冒泡排序--咕噜咕噜
- 【JavaWeb篇】快速上手Tomcat|实战项目详解
- Linux下Intel集成显卡驱动安装
- 清华应届程序员同时被5家公司录取,晒出工资,网友:羡慕
- 禁止vite打包时将rgba转为16进制
- 部落动物:关于男人、女人和两性文化的心理学
- 【20保研】暨南大学关于举办2019年优秀大学生暑期学术夏令营活动的公告
- CoolHash数据库的产品宣言(Fourinone4.0版)
- 【原创】VMware安装没有引导的Ghost镜像,超级详细,步步讲解
- 【C#】TODO的作用
- 移动大数据助力南京智慧旅游升级