生成式对抗网络(GAN)相关问题汇总(较全面)
今年暑假在北京大学参加了一个月的人工智能DeeCamp训练营培训,期间实践课题是:基于文本的图像生成,用到了各种GAN网络对比试验结果。当时只是想着实验各种GAN看效果,对于每一个GAN都有什么改进一知半解。接下来还要指导一篇基于GAN的水下图像生成本科生毕设,现在整理一下网上的资源,慢慢学习。
0. GAN简介
GAN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布,如果用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。G, D的主要功能是:
- G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点.(纳什均衡(Nash equilibrium)及经典案例)
GAN网络训练流程图如下:
![]()
1. GAN相关问题
在Quora上的两个问题,Ian Goodfellow(GAN的发明人)都做了解答。
原问题1:What is the advantage of generative adversarial networks compared with other generative models?
原链接:GAN与其他生成模型相比有什么优势
生成对抗网络相比其他生成模型的优点?
Ian Goodfellow回答:
—————————————————————————————————–
相比其他所有模型,我认为
- 从实际结果来看,GAN看起来能产生更好的生成样本
- GAN框架可以训练任何生成网络(理论上,然而在实践中,很难使用增强学习去训练有离散输出的生成器),大多数其他架构需要生成器有一些特定的函数形式,就像输出层必须是高斯化的. 另外所有其他框架需要生成器整个都是非零权值(put non-zero mass everywhere),然而,GANs可以学习到一个只在靠近真实数据的地方(神经网络层)产生样本点的模型( GANs can learn models that generate points only on a thin manifold that goes near the data.)
- 没有必要遵循任何种类的因子分解去设计模型,所有的生成器和鉴别器都可以正常工作
- 相比PixelRNN, GAN生成采样的运行时间更短,GANs一次产生一个样本,然而PixelRNNs需要一个像素一个像素的去产生样本;
- 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
- 相比深度玻尔兹曼机, GANs没有变分下界,也没有棘手的配分函数,样本是一次生成的,而不是重复的应用马尔科夫链来生成的
- 相比GSNs, GANs产生的样本是一次生成的,而不是重复的应用马尔科夫链来生成的;
- 相比NICE和Real NVE,GANs没有对潜在变量(生成器的输入值)的大小进行限制;
说实话, 我认为其他的方法也都是很了不起的,他们相比GANs也有相应的优势.
—————————————————————————————————–
原问题2: What are the pros and cons of using generative adversarial networks (a type of neural network)?
原链接:GANs的优缺点是什么?,
生成对抗网络(一种神经网络)的优缺点是什么?
It is known that facebook has developed a means of generating realistic-looking images via a neural network. They used “GAN” aka “generative adversarial networks”. Could this be applied generation of other things, such as audio waveform via RNN? Why or why not?
facebook基于神经网络开发了一种可以生成现实图片的方法,他们使用GAN,又叫做生成对抗网络,它能应用到其他事物的生成吗,例如通过RNN生成音频波形,可以吗?为什么?
Ian Goodfellow回答:
—————————————————————————————————–
优势
- GANs是一种以半监督方式训练分类器的方法,可以参考我们的NIPS paper和相应代码.在你没有很多带标签的训练集的时候,你可以不做任何修改的直接使用我们的代码,通常这是因为你没有太多标记样本.我最近也成功的使用这份代码与谷歌大脑部门在深度学习的隐私方面合写了一篇论文
- GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据.
- GANs不需要蒙特卡洛估计来训练网络,人们经常抱怨GANs训练不稳定,很难训练,但是他们比训练依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼机简单多了.因为蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中.GANs起码在ImageNet上训练后可以学习去画一些以假乱真的狗
- 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊.
- 相比非线性ICA(NICE, Real NVE等,),GANs不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的.
- 相比玻尔兹曼机和GSNs,GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次.
劣势
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多.
- 它很难去学习生成离散的数据,就像文本
- 相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素, 你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值,我在伯克利大学的课堂上前二十分钟讲到了这个问题.课程链接,油管视频,请自带梯子~
待解决问题:
GAN网络输入图像为什么要求是64*64?
2. 一些GAN网络介绍
1) GAN(2014)
Paper:https://arxiv.org/abs/1406.2661
最初Goodfellow提出GAN思想的那篇论文。
网络结构:
- 判别网络D(discriminative)。一个分类器。二分类,用来判别真假。
- 生成网络G(generative)。用来生成“逼真”样本。 输出一个向量,dim跟真实图片一致。
GAN的表达式
- 固定G,maxV(G,D) ) ,即训练D,让D具有更好的辨别能力。
- 固定D,minmaxV(G,D),即训练G,让G生成的样本和真实样本的分布更接近。
怎么训练?
一、交替训练。
- 固定G时,训练D;
(公式1)
转化成最小形式:
- 固定D时,训练G。 可以设置超参数k, 表示训练k次D,再训练一次G.
min(公式2)
二、最优判别器D为:
令 关于D(x)的导数为0,得:
其中,Pr(x) 和 Pg(x) 表示真样本和假样本的比例。比如0.5, 0.5
化简得最优判别器为:
即:如果Pr(x) = Pg(x),说明该样本真假样本各一半,此时最优判别器给出的概率是0.5。
看到这,有个疑问,为什么概率是0.5还是最优判别器?
因为,分不出真假,最优的判别就是0.5 。最坏的判别是:假的被判别是真,真的被判别是假。
loss公式分析
1,首先看D的loss.
它其实就是普通的交叉熵,特殊点是:它这里是将真样本的label设置为1, 将假样本的label设置为0.
- 对于m个真样本(都是label=1),根据交叉熵损失函数:
,由于都是y=1,所以就是
.其中D(xi)表示p(y=1)的概率。
- 对于m个假样本。同理,它的
.
2,再看G的loss
网络G的目标是让网络D分辨不清,准确说,就是让label=0的假样本,被D认为是真(lable=1).
也就是说,对于假样本,d(x)=1时(被认为是真)loss最小,d(x)=0时loss最大。
所以,loss_g=log(1−D(xi)) ,与D网络的 lossf 相反。
网络G 的loss的改进
这里将网络G的loss从:
(公式2)
变为:
(公式3)
为什么这么改进?
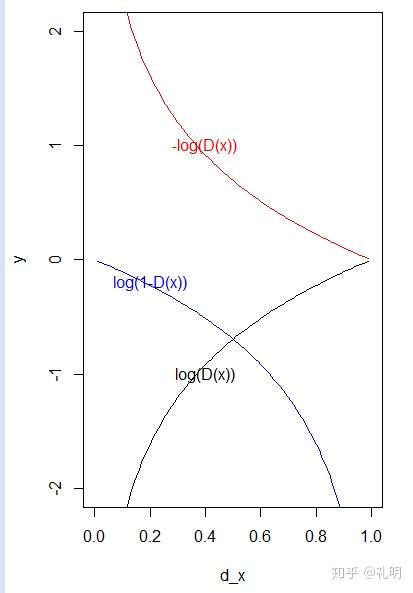
从下图可以看到:
- 在D(x)接近于0的时候,log(1−D(x))的梯度非常的小。在训练的初期,D模型是很容易区分出“假图片”的,也就是“假图片”的D(x)=0,这会导致G网络的梯度变化十分的缓慢。
- −log(D(x)) 和log(1−D(x)) 趋势是一样的,都是递减的,但是变化是“先快后慢“, 所以,G的loss 换成 :−log(D(x))
2) DCGAN(2016)
Deep Convolutional Generative Adversarial Networks。
paper:http://arxiv.org/abs/1511.06434
DCGAN是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。
论文的主要贡献是:
- 为GAN的训练提供了一个很好的网络拓扑结构。
- 表明生成的特征具有向量的计算特性。
![]()
DCGAN的生成器网络结构如上图所示,相较原始的GAN,DCGAN几乎完全使用了卷积层代替全链接层,判别器几乎是和生成器对称的,从上图中我们可以看到,整个网络没有pooling层和上采样层的存在,实际上是使用了带步长(fractional-strided)的卷积代替了上采样,以增加训练的稳定性。
DCGAN能改进GAN训练稳定的原因主要有:
- 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层。
- 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)
- 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh
- 使用adam优化器训练,并且学习率最好是0.0002
DCGAN虽然有很好的架构,但是对GAN训练稳定性来说是治标不治本,没有从根本上解决问题,而且训练的时候仍需要小心的平衡G,D的训练进程,往往是训练一个多次,训练另一个一次。
3) WGAN(2017)
Paper:https://arxiv.org/abs/1701.07875
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,WGAN对GAN的改进主要有:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
- 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam,但是就我目前来说,训练GAN时,我还是adam用的多一些。
从上面看来,WGAN好像在代码上很好实现,基本上在原始GAN的代码上不用更改什么,但是它的作用是巨大的
- WGAN理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。
- 解决了模式崩溃的(collapse mode)问题,生成结果多样性更丰富。
- 对GAN的训练提供了一个指标,此指标数值越小,表示GAN训练的越差,反之越好。可以说之前训练GAN完全就和买彩票一样,训练好了算你中奖,没中奖也不要气馁,多买几注吧。
有关GAN和WGAN的解释,可以参考链接:https://zhuanlan.zhihu.com/p/25071913
总的来说,GAN中交叉熵(JS散度)不适合衡量生成数据分布和真实数据分布的距离,如果通过优化JS散度训练GAN会导致找不到正确的优化目标,所以,WGAN提出使用wassertein距离作为优化方式训练GAN,但是数学上和真正代码实现上还是有区别的,使用Wasserteion距离需要满足很强的连续性条件—lipschitz连续性,为了满足这个条件,作者使用了将权重限制到一个范围的方式强制满足lipschitz连续性,但是这也造成了隐患,接下来会详细说。另外说实话,虽然理论证明很漂亮,但是实际上训练起来,以及生成结果并没有期待的那么好。
注:Lipschitz限制是在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数K,通过权重值限制的方式保证了权重参数的有界性,间接限制了其梯度信息。
4) WGAN-GP(2017)
Paper:https://arxiv.org/abs/1704.00028
WGAN-GP是WGAN之后的改进版,主要还是改进了连续性限制的条件,因为,作者也发现将权重剪切到一定范围之后,比如剪切到[-0.01,+0.01]后,发生了这样的情况,如下图左边表示。
![]()
发现大多数的权重都在-0.01 和0.01上,这就意味了网络的大部分权重只有两个可能数,对于深度神经网络来说不能充分发挥深度神经网络的拟合能力,简直是极大的浪费。并且,也发现强制剪切权重容易导致梯度消失或者梯度爆炸,梯度消失很好理解,就是权重得不到更新信息,梯度爆炸就是更新过猛了,权重每次更新都变化很大,很容易导致训练不稳定。梯度消失与梯度爆炸原因均在于剪切范围的选择,选择过小的话会导致梯度消失,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会发生梯度爆炸 。为了解决这个问题,并且找一个合适的方式满足lipschitz连续性条件,作者提出了使用梯度惩罚(gradient penalty)的方式以满足此连续性条件,其结果如上图右边所示。
梯度惩罚就是既然Lipschitz限制是要求判别器的梯度不超过K,那么可以通过建立一个损失函数来满足这个要求,即先求出判别器的梯度d(D(x)),然后建立与K之间的二范数就可以实现一个简单的损失函数设计。但是注意到D的梯度的数值空间是整个样本空间,对于图片(既包含了真实数据集也包含了生成出的图片集)这样的数据集来说,维度及其高,显然是及其不适合的计算的。作者提出没必要对整个数据集(真的和生成的)做采样,只要从每一批次的样本中采样就可以了,比如可以产生一个随机数,在生成数据和真实数据上做一个插值
![]()
于是就算解决了在整个样本空间上采样的麻烦。
所以WGAN-GP的贡献是:
- 提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题。
- 比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本
- 提供稳定的GAN训练方式,几乎不需要怎么调参,成功训练多种针对图片生成和语言模型的GAN架构
但是论文提出,由于是对每个batch中的每一个样本都做了梯度惩罚(随机数的维度是(batchsize,1)),因此判别器中不能使用batch norm,但是可以使用其他的normalization方法,比如Layer Normalization、Weight Normalization和Instance Normalization,论文中使用了Layer Normalization,weight normalization效果也是可以的。实验可以发现WGAN-GP完爆其他GAN。
5) LSGAN(2017)
最小二乘GAN,全称是Least Squares Generative Adversarial Networks
Paper:https://arxiv.org/abs/1611.04076
LSGAN原理:
其实原理部分可以一句话概括,即使用了最小二乘损失函数代替了GAN的损失函数。
但是就这样的改变,缓解了GAN训练不稳定和生成图像质量差多样性不足的问题。
事实上,作者认为使用JS散度并不能拉近真实分布和生成分布之间的距离,使用最小二乘可以将图像的分布尽可能的接近决策边界,其损失函数定义如下:
![]()
其中作者设置a=c=1,b=0
论文里还是给了一些数学推导与证明,感兴趣的可以去看看
6) BEGAN(2017)
Paper:https://arxiv.org/abs/1703.10717
BEGAN的主要贡献:
- 提出了一种新的简单强大GAN,使用标准的训练方式,不加训练trick也能很快且稳定的收敛
- 对于GAN中G,D的能力的平衡提出了一种均衡的概念(GAN的理论基础就是goodfellow理论上证明了GAN均衡点的存在,但是一直没有一个准确的衡量指标说明GAN的均衡程度)
- 提出了一种收敛程度的估计,这个机制只在WGAN中出现过。作者在论文中也提到,他们的灵感来自于WGAN,在此之前只有wgan做到了
- 提出了一种收敛程度的估计,这个机制只在WGAN中出现过。作者在论文中也提到,他们的灵感来自于WGAN
先说说BEGAN的主要原理,BEGAN和其他GAN不一样,这里的D使用的是auto-encoder结构,就是下面这种,D的输入是图片,输出是经过编码解码后的图片,
![]()
以往的GAN以及其变种都是希望生成器生成的数据分布尽可能的接近真实数据的分布,当生成数据分布等同于真实数据分布时,我们就确定生成器G经过训练可以生成和真实数据分布相同的样本,即获得了生成足以以假乱真数据的能力,所以从这一点出发,研究者们设计了各种损失函数去令G的生成数据分布尽可能接近真实数据分布。BEGAN代替了这种估计概率分布方法,它不直接去估计生成分布Pg与真实分布Px的差距,进而设计合理的损失函数拉近他们之间的距离,而是估计分布的误差之间的距离,作者认为只要分布的的误差分布相近的话,也可以认为这些分布是相近的。即如果我们认为两个人非常相似,又发现这两人中的第二个人和第三个人很相似,那么我们就完全可以说第一个人和第三个人长的很像。
注:所有GAN的代码可在GitHub搜到,下面是一个GAN的zone地址:
https://github.com/hindupuravinash/the-gan-zoo
讲了这么多,2018年Google新的研究表明,这些GAN都差不多,Google研究原文:https://arxiv.org/abs/1711.10337
参考网址&推荐阅读
带你进入GAN(一)原始GAN
DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN原理总结及对比
生成对抗网络(GAN)相比传统训练方法有什么优势?
深入浅出 GAN·原理篇文字版(完整)| 干货(推荐)
生成式对抗网络(GAN)相关问题汇总(较全面)相关推荐
- 王飞跃教授:生成式对抗网络GAN的研究进展与展望
本次汇报的主要内容包括GAN的提出背景.GAN的理论与实现模型.发展以及我们所做的工作,即GAN与平行智能. 生成式对抗网络GAN GAN是Goodfellow在2014年提出来的一种思想,是一种比 ...
- 《生成式对抗网络GAN的研究进展与展望》论文笔记
本文主要是对论文:王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(3): 321-332. 进行总结. 相关博客地址: ...
- 生成式对抗网络GAN模型搭建
生成式对抗网络GAN模型搭建 目录 一.理论部分 1.GAN基本原理介绍 2.对KL散度的理解 3.模块导入命令 二.编程实现 1.加载所需要的模块和库,设定展示图片函数以及其他对图像预处理函数 1) ...
- 如何用 TensorFlow 实现生成式对抗网络(GAN)
我们来研究一下生成式对抗网络 GAN,并且用 TensorFlow 代码实现. 自从 Ian Goodfellow 在 14 年发表了 论文 Generative Adversarial Nets 以 ...
- 简述生成式对抗网络 GAN
本文主要阐述了对生成式对抗网络的理解,首先谈到了什么是对抗样本,以及它与对抗网络的关系,然后解释了对抗网络的每个组成部分,再结合算法流程和代码实现来解释具体是如何实现并执行这个算法的,最后通过给出一个 ...
- 深度学习之生成式对抗网络 GAN(Generative Adversarial Networks)
一.GAN介绍 生成式对抗网络GAN(Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一.它源于2014年发表的论文:& ...
- 生成式对抗网络GAN(一)—基于python实现
基于python实现生成式对抗网络GAN 构建和训练一个生成对抗网络(GAN) ,使其可以生成数字(0-9)的手写图像. 学习目标 从零开始构建GAN的生成器和判别器. 创建GAN的生成器和判别器的损 ...
- 深度学习之生成式对抗网络GAN
一.GAN介绍 生成式对抗网络GAN(Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一.模型通过框架中(至少)两个模块 ...
- 生成式对抗网络(GAN, Generaitive Adversarial Networks)总结
最近要做有关图像生成的工作-也是小白,今天简单学习一些有关GAN的基础知识,很浅,入个门,大神勿喷. GAN目前确实是在深度学习领域最热门,最有前景的方向之一.近几年有关于GAN的论文非常非常之多,从 ...
- Github | 深度神经网络(DNN)与生成式对抗网络(GAN)模型总览
点上方蓝字计算机视觉联盟获取更多干货 在右上方 ··· 设为星标 ★,与你不见不散 编辑:Sophia 计算机视觉联盟 报道 | 公众号 CVLianMeng 转载于 :https://githu ...
最新文章
- dockerfile kafka
- MYSQL连接一段时间不操作后出现异常的解决方案
- BZOJ 2134: 单选错位
- 自动化运维之–Cobbler
- c语言加减乘除运算代码_科协推文 || 走进C语言
- 一张图学会python高清图-一张图让你学会Python
- springboot整合哨兵模式连接redis
- 回归分析什么时候取对数_技术派|SPSS数据分析心得小结及心得分享!必备收藏...
- java echarts 饼图_饼图 | ECharts 数据可视化实验室
- Java内存模型(Java并发编程的艺术整理)
- css背景透明 字体不透明
- php实现鼠标悬停显示下拉菜单,jquery实现鼠标滑过显示二级下拉菜单效果
- JS如何删除节点和所有子节点
- 学习java的培训学校
- Sangoma7 (FreePBX)安装后局域网使用eyebeam登陆403错误
- 【无限互联】iOS开发视频教程—1.iPhone开发概述——必看
- (STM32)从零开始的RT-Thread之旅--SPI驱动ST7735(2)
- 设计一个安全的排队系统的思考
- php 熊掌号api,关于熊掌号资源提交功能API接口解读
- springBoot实现http代理ip