CS224N NLP
附大佬的笔记:
github.com/LooperXX/LooperXX.github.io.git
文章目录
- Abbreviation
- Lecture 1 - Introduction and Word Vectors
- NLP
- Word2vec
- Use two vector in one word: centor word context word.
- softmax function
- Train the model: gradient descent
- Show some achievement with code(5640-h0516)
- QA
- Lecture 2 Word Vectors,Word Senses,and Neural Classifiers
- Bag models (0245)
- Gradient descent (0600)
- stochastic gradient descent SGD TOBELM (0920)
- more details of word2vec(1400)
- SG use center to predict context
- SGNS negative sampling [ToBLO]
- CBOW opposite.
- Why use two vectors(1500)
- Why not capture co-occurrence counts directly?(2337)
- SVD(3230) [ToL]
- Count based vs direct prediction
- Encoing meaning components in vector differences(3948)
- GloVe (4313)
- How to evaluate word vectors Intrinsic vs. extrinsic(4756)
- Analogy evaluation and hyperparameters (intrinsic)(5515)
- Word vector distances and their correlation with human judgements(5640)
- Data shows that 300 dimensional word vector is good(5536)
- The objective function for the GloVe model and What log-bilinear means(5739)
- Word senses and word sense ambiguity(h0353)
- Lecture 3 Gradients by hand(matric calculus) and algorithmically(the backpropagation algorithm) all the math details of doing nerual net learning
- Need to be learn again, it is not totally understanded.
- Named Entity Recognition(0530)
- Simple NER (0636)
- How the sample model run (0836)
- update equation(1220)
- jacobian(1811)
- Chain Rule(2015)
- do one example step (2650)
- image-20220214193417520
- Reusing Computation(3402)
- ds/dw
- Forward and backward propagation(5000)
- An example(5507)
- Compute all gradients at once (h0005)
- Back-prop in general computation graph(h0800)[ToL]
- Automatic Differentiation(h1346)
- Manual Gradient checking : Numeric Gradient(h1900)
- Lecture 4 Dependency Parsing
- Two views of linguistic structure
- Constituency = phrase structure grammar = context-free grammars(CFGs)(0331)
- Dependency structure(1449)
- Why do we need sentence structure?(2205)
- Prepositional phrase attachment ambiguity.(2422)
- San Jose cops kill man with knife
- Coordination scope ambiguity(3614)
- Adjectival/Adverbial Modifier Ambiguity(3755)
- Verb Phrase(VP) attachment ambiguity(4404)
- Dependency Grammar and Dependency structure(4355)
- Will add a fake ROOT for handy
- Dependency Grammar history(4742)
- The rise of annotated data Universal Dependency tree(5100)
- Tree bank(5400)
- how to build parser with dependency(5738)
- Dependency Parsing
- Projectivity(h0416)
- Methods of Dependency Parsing(h0521)
- Greedy transition-based parsing(h0621)
- Basic transition-based dependency parser (h0808)
- MaltParser(h1351)[ToL]
- Evaluation of Dependency Parsing (h1845)[ToL]
- Lecture-5 Languages models and Recurrent Neural Networks(RNNs)
- A neural dependency parser(0624)
- Distributed Representations(0945)
- Deep Learning Classifier are non-linear classifiers(1210)
- Simple feed-forward neural network multi-class classifier (1621)
- Neural Dependency Parser Model Architecture(1730)
- Graph-based dependency parsers (2044)
- Regularization && Overfitting (2529)
- Dropout (3100)[ToL]
- Vectorization(3333)
- Non-linearities (4000)
- Parameter Initialization (4357)
- Optimizers(4617)
- Learning Rates(4810)
- Language Modeling (5036)
- n-gram Language Models(5356)
- Sparsity Problems (5922)
- Storage Problems(h0117)
- How to build a neural language model(h0609)
- A fixed-window neural Language Model(h1100)
- Recurrent Neural Network (RNN)(h1250)
- A Simple RNN Language Model(h1430)
- Lecture 6 Simple and LSTM Recurrent Neural Networks.
- The Simple RNN Language Model (0310)
- Training an RNN Language Model (0818)
- Teacher Forcing
- Evaluating Language Models (2447)[ToL]
- Language Model is a system that predicts the next word(3130)
- Other use of RNN(3229)
- Tag for word
- Used for classification(3420)
- Used to Language encoder module (3500)
- Used to generate text (3600)
- Problems with Vanishing and Exploding Gradients(3750)[IMPORTANT]
- Why This is a problem (4400)
- Long Short Term Memory RNNS(LSTMS)(5000)[ToL]
- Bidirectional RNN (h2000)
- Lecture-7 Translation, Seq2Seq, Attention
- Machine Translation(0245)
- What do you need (1200)
- Decoding for SMT(1748)
- What is Neural Machine Translation(NMT)(2130)
- Seq2seq is more than MT(2600)
- (2732)[ToL]
- Multi-layer RNNs(3323)
- Greedy decoding(4000)
- Exhaustive search decoding(4200)
- beam search decoding(4400)
- How do we evaluate Machine Translation(5550)
- BLEU
- NMT perhaps the biggest success story of NLP Deep Learning(h00000)
- Attention(h1300)
- Lecture 8 Final Projects; Practical Tips
- Sequence to Sequence with attention(0235)
- Attention: in equations(0800)
- there are several attention variants(1500)
- Attention is a general Deep Learning technique(2240)
- Final Project(3000)
- Lecture-9 Self- Attention and Transformers
- Issues with recurrent models (0434)
- Linear interaction distance
- Lack of parallelizability(0723)
- If not recurrence
- Word window models aggregate local contexts (1031)
- Attention(1406)
- Self-Attention(1638)
- Self-attention as an nlp building block(2222)
- Fix the first self-attention problem
- sequence order (2423)
- Position representation vector through sinusoids(2624)
- Sinusoidal position representations(2730)
- Position representation vector from scratch(2830)
- Adding nonlinearities in self-attention(2953)
- Barriers and solutions for Self-Attention as building block(2945)
- The transformer encoder-decoder(3638)
- key query value(4000)
- Multi-headed attention (4322)
- Residual connections(4723)
- Layer normalization(5045)
- Scaled fot product(5415)
- Lecture 10 - Transformers and Pretraining
- Word structure and subword models(0300)
- The byte-pair encoding(0659)
- Motivating word meaning and context(1556)
- Pretraining whole models(2000)
- this model haven't met overfitting now, you can save some data to test it.(2811)
- transformers for encoding and decoding (3030)
- Pretraining through language modeling(3400)
- Stochastic gradient descent and pretrain/finetune(3740)
- Model pretraining has three ways (4021)
- Decoder(4300)
- Generative Pretrained Transformer(GPT) (4818)
- GPT2(5400)
- Pretraining Encoding(5545)
- (Bert)(5654)
- Bidirectional encoder representations from transformers(h0100)
- Limitations of pretrained encoders(h0900)
- Extensions of BERT(h1000)
- Pretraining Encoder-Decoder (h1200)
- T5(h1500)
- GPT3(h1800)
- Lecture 11 Question Answering
- What is question answering(0414)
- Beyond textual QA problems(1100)
- Reading comprehension(1223)
- Standord question answering dataset (1815)
- Neural models for reading comprehension(2428)
- LSTM-based vs BERT models (2713)
- BiDAF(3200)
- Encoding(3200)
- Attention(3400)
- Modeling and output layers(4640)
- BERT for reading comprehension (5227)
- Comparisons between BiDAF and BERT models(2734)
- Can we design better pre-training objectives(h0000)
- open domain question answering(h1000)
- DPR(H1400)
- DensePhrase:Demo(h1800)
- Lecture 12 - Natural Language Generation[ToL]
- What is neural language generation?(0300)
- Components of NLG Systems(0845)
- Basic of natural language generation(0916)
- A look at a single step(1024)
- then select and train(1115)
- Decoding(1317)
- Greedy methods(1432)
- Greedy methods get repetitive(1545)
- why do repetition happen(1613)
- How can we reduce repetition (1824)[ToL]
- People is not always choose the greedy methods(1930)
- Time to get random: Sampling(2047)
- Decoding : Top-k sampling(2100)
- Issues with Top-k sampling(2339)
- Decoding: Top-p(nucleus)sampling(2421)
- Scaling randomness: Softmax temperature (2500)[ToL]
- improving decoding: re-balancing distributions(2710)
- Backpropagation-based distribution re-balancing(3027)
- Improving Decoding: Re-ranking(3300)[ToL]
- Decoding: Takeaways(3540)
- Training NLG models(4114)
- Maximum Likelihood Training(4200)
- Unlikelihood Training(4427)[ToL]
- Exposure Bias(4513)[ToL]
- Exposure Bias Solutions(4645)
- Reinforce Basics(4900)
- Reward Estimation(5020)
- reinforce's dark side(5300)
- Training: Takeways(5423)
- Evaluating NLG Systems(5613)
- Types of evaluation methods for text generation(5734)
- Content Overlap metrics(5800)
- A simple failure case(5900)
- Semantic overlap metrics(h0100)
- Model-based metrics(h0120)
- word distance functions(h0234)
- Beyond word matching(h0350)
- Human evaluations(h0433)
- Issues(h0700)
- Takeways(h0912)
- Ethical Considerations(h1025)
- Lecture 13 - Coreference Resolution
- What is Coreference Resolution?(0604)
- Applications (1712)
- Coreference Resolution in Two steps(1947)
- Mention Detection(2049)
- Not quite so simple(2255)
- Avoiding a traditional pipeline system(2811)
- Onto Coreference! First, some linguistics (3035)
- not all anaphoric relations are coreferential (3349)
- Anaphora vs Cataphora(3610)
- Taking stock (3801)
- Four kinds of coreference Models(4018)
- Traditional pronominal anaphora resolution:Hobbs's naive algorithm(4130)
- Knowledge-based Pronominal Coreference(4820)
- Coreference Models: Mention Pair(5624)
- Mention Pair Test Time(5800)
- Disadvantage(5953)
- Coreference Models: Mention Ranking(h0050)
- Convolutional Neural Nets(h0341)
- What is convolution anyway?(h0452)
- End-to-End Neural Coref Model(h1206)
- Conclusion (h2017)
- Lecture 14 - T5 and Large Language Models
- T5 with a task prefix(0800)
- Others
- STSB
- Summarize
- T5 change little from original transformer(1300)
- what should my pre-training data set be?(1325)
- Then is how to train from a start(1659)
- pretrain(1805)
- choose the model(2412)
- pre-training objective(2629)
- different structure of data source(2822)
- Multi task learning (3443)
- close the gap between multi-task training and this pre-training followed by separate fine tuning(3621)
- What if it happens there are four times computes as much as before (3737)
- Overview(3840)
- What about all of the other languages?(mT5)(4735)
- XTREME (5000)
- How much knowledge does a language model pick up during pre-training?(5225)
- Salient span masking (5631)
- Do large language models memorize their training data(h0100)
- Can we close the gap between large and small models by improving the transformer architecture(h1010)
- QA(h1915)
- Lecture 15 - Add Knowledge to Language Models
- Recap: LM(0232)
- What does a language model know?(0423)
- The importance of know ledge-aware language models(0700)
- Query traditional knowledge bases(0750)
- Query language models as knowledge bases(0955)
- Compare and disadvantage(1010)
- Techniques to add knowledge to LMs(130)
- Add pretrained embeddings(1403)
- Aside: What is entity linking?(1516)
- Method 1: Add pretrained entity embeddings(1815)
- How to we incorporate pretrained entity embeddings from a different embedding space?(2000)
- ERNIE: Enhanced language representation with informative entities(2143)
- strengths & remaining challenges(2610)
- Jointly learn to link entities with KnowBERT(2958)
- Use an external memory(3140)
- KGLM(3355)
- Local knowledge and full knowledge
- When should the model use the external knowledge(3600)
- Compare to the others(4334)
- More recent takes: Nearest Neighbor Language Models(kNN-LM)(4730)
- Modify the training data(5230)
- WKLM(5458)
- Learn inductive biases through masking(5811)
- Salient span masking(5927)
- Recap(h0053)
- Evaluating knowledge in LMS(h0211)
- LAMA(h0250)
- The limitations (h0650)
- LAMA_UnHelpful Names(LAMA-UHN)
- Developing better prompts to query knowledge in LMS
- Knowledge-driven downstream tasks(h1253)
- Relation extraction performance on TACED(h1400)
- Entity typing performance on Open Entuty
- Recap: Evaluating knowledge in LMs(h1600)
- Other exciting progress & what's next?(h1652)
- Lecture 17 - Model Analysis and Explanation
- Motivation
- what are our models doing(0415)
- how do we make tomorrow's model?(0515)
- What biases are built into model?(0700)
- how do we make in the following 25years(0800)
- Model analysis at varying levels of abstraction(0904)
- Model evaluation as model analysis(1117)
- Model evaluation as model analysis in natural language inference(1344)
- What if the model is simple using heuristics to get good accuracy?(1558)
- Language models as linguistic test subjects(2023)
- Careful test sets as unit test suites: CheckListing(3230)
- Fitting the dataset vs learning the task(3500)
- Knowledge evaluation as model analysis(3642)
- Input influence: does my model really use long-distance context?(3822)
- Prediction explanations: what in the input led to this output?(4054)
- Prediction explanations: simple saliency maps(4230)
- Explanation by input reduction (4607)
- Analyzing models by breaking them(5106)
- Are models robust to noise in their input?(5518)
- Analysis of "interpretable" architecture components(5719)
- Probing: supervised analysis of neural networks(h0408)
- Emergent simple structure in neural networks(h1019)
- Probing: tress simply recoverable from BERT representations(h1136)
- Final thoughts on probing and correlation studies(h1341)
- Recasting model tweaks and ablations as analysis(h1406)
- Ablation analysis: do we need all these attension heads?(h1445)
- What's the right layer order for a transformer?(h1537)
- Parting thoughts(h1612)
- Lecture 18 - Future of NLP + Deep Learning
- General Representation Learning Recipe(0312)
- Large Language Models and GPT-3(0358)
- Large Language models and GPT-3(0514)
- What's new about GPT-3
- There are three lessons left, They will be finished in the review when I come back from Lee.
Abbreviation
| - | - |
|---|---|
| [ToL] | To learn |
| [ToLM] | To learn more |
| [ToLO] | To learn optionally |
| (0501) | 05 min 01s |
| (h0501) | 1 hour 05 min 01s |
| (hh0501) | 2 hour 05 min 01s |
Lecture 1 - Introduction and Word Vectors
![]()
NLP
Convert one-hot encoding to distributed representitions
Ont hot can’t represent the relation between word vectors,it is too big
Word2vec
Ignore the position of word of context

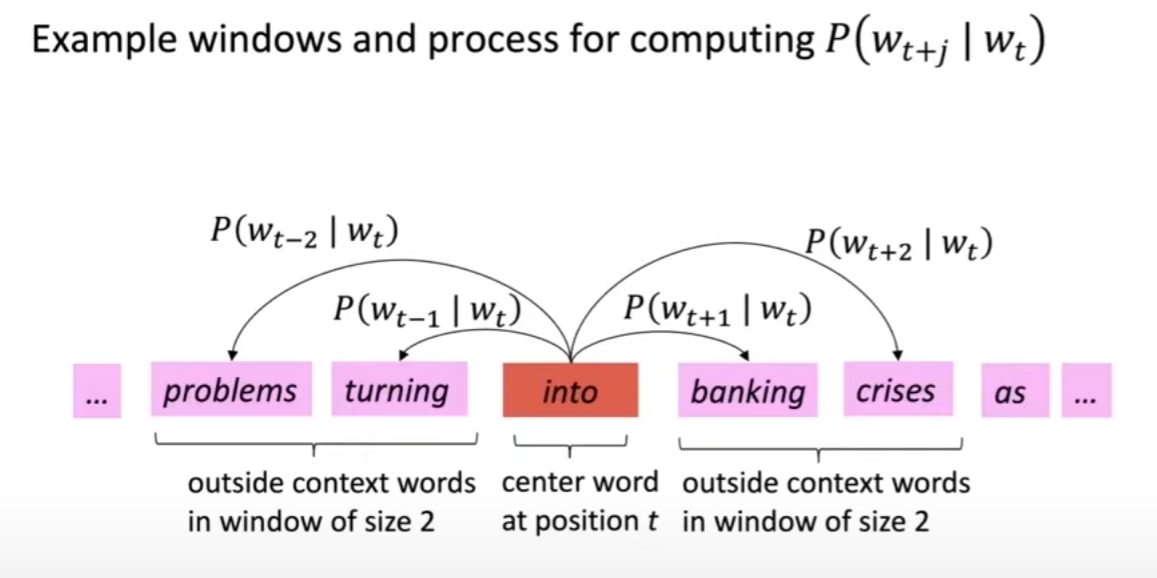
Use two vector in one word: centor word context word.
softmax function

![]()
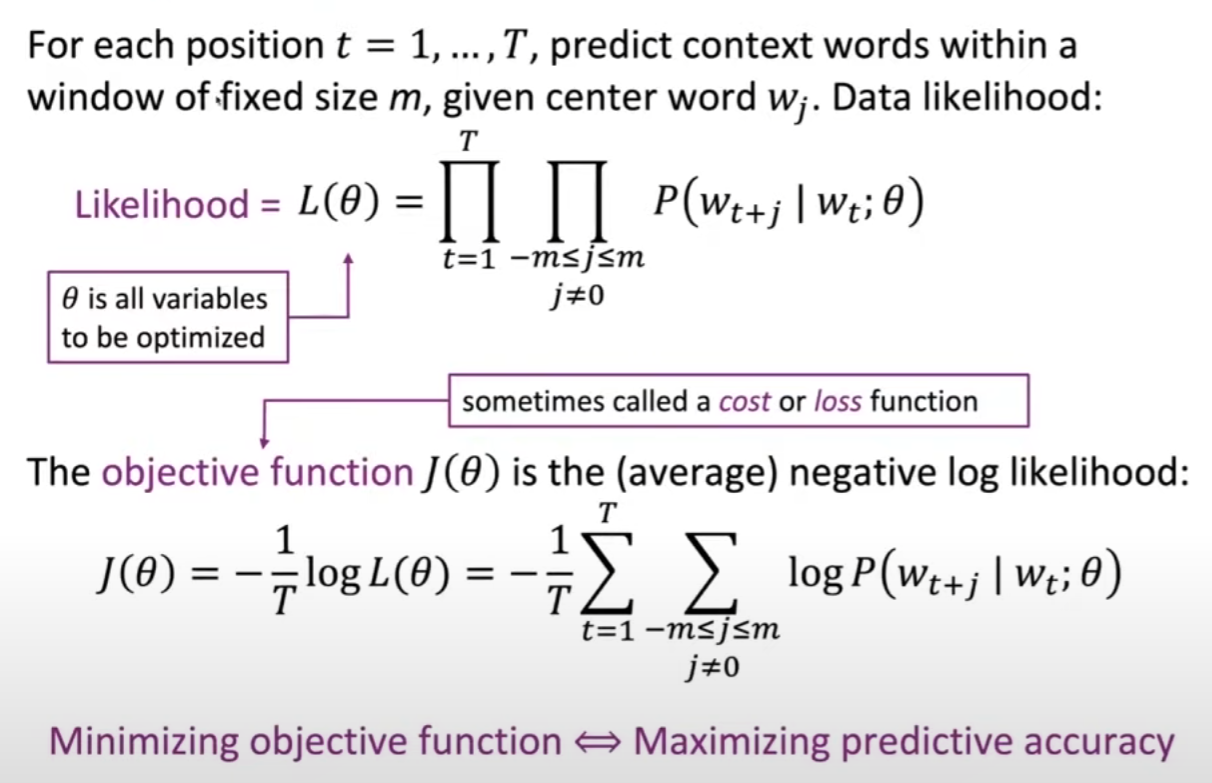
Train the model: gradient descent
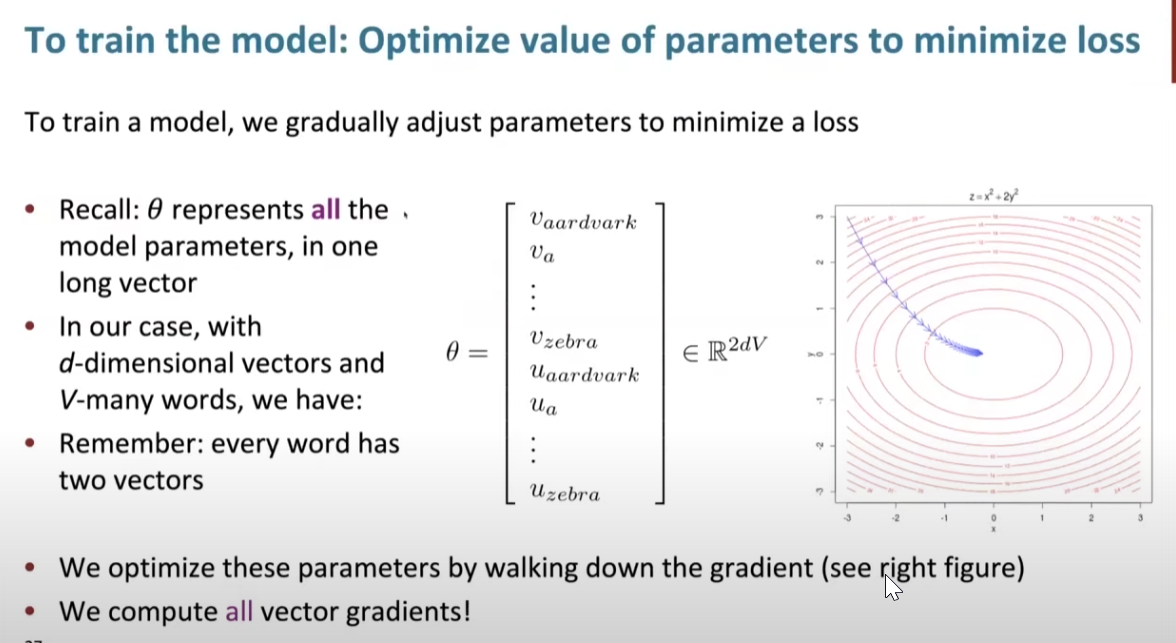
There is a term to calculate the gradient descent. (39:50-56:40)
result is :![]()
ToL
Review derivation and the following especially.
![]()
Show some achievement with code(5640-h0516)
- We can do vector addition, subtraction, multiplication and division, etc.
QA
Why are there center word and context word(h0650)
To avoid one vector dot product himself in some situation???
Even synonyms can be merged into a vector(h1215)
Which is different from lee ,He says synonyms use different.
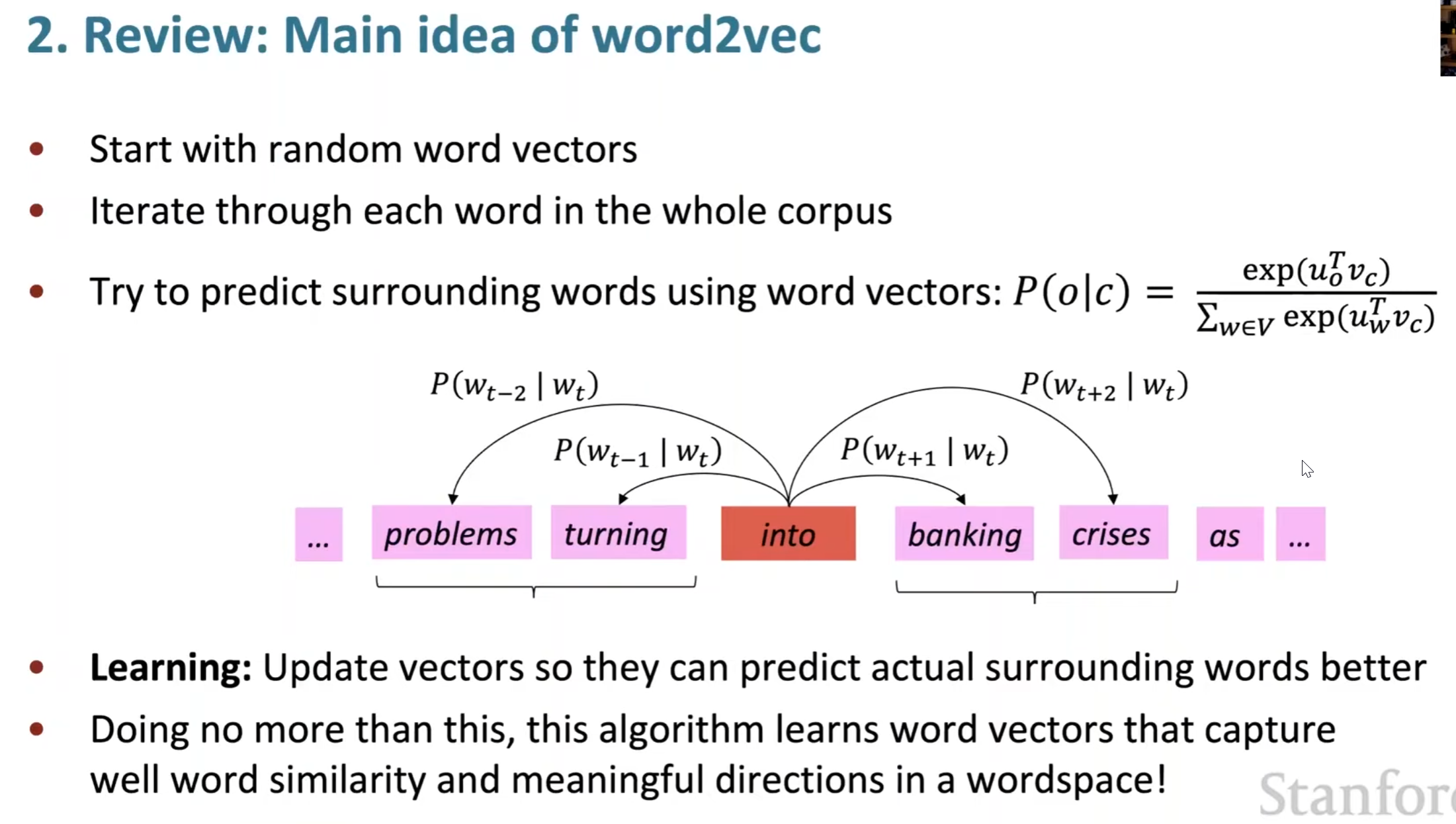
Lecture 2 Word Vectors,Word Senses,and Neural Classifiers
![]()
Bag models (0245)
The model makes the same predictions at each position.
Gradient descent (0600)
Not usually use because of the big calculation.
step size: not too big nor too small

stochastic gradient descent SGD TOBELM (0920)
Take part of the corpus
billion faster.
Maybe even get better result.
But it is stochastic, either you need sparse matrix update operations to only update certain rows of full embedding matrices U and V, or you need to keep around a hash for vectors.(1344)ToL
more details of word2vec(1400)
![]()
SG use center to predict context
SGNS negative sampling [ToBLO]
use logistic function instead of softmax and take sampling of corpus
CBOW opposite.

Why use two vectors(1500)
Sometime it will dot product with itself.

[ToL]
The first one is positive word and the last is negative word (2800)
negative word is being sampled cause the center word will turn up on other occasions, when it does, there will have other sampling, and it will learn step by step.
Why not capture co-occurrence counts directly?(2337)
![]()
SVD(3230) [ToL]
https://zhuanlan.zhihu.com/p/29846048
use svd to get lower dimensional representations for words
 (3451)
(3451)
Count based vs direct prediction
 (3900)
(3900)
Encoing meaning components in vector differences(3948)
This is to make addition subtraction available for word vectors.
![]()
GloVe (4313)

let dot product minus log of the co-occurrence
How to evaluate word vectors Intrinsic vs. extrinsic(4756)

Analogy evaluation and hyperparameters (intrinsic)(5515)
Word vector distances and their correlation with human judgements(5640)
Data shows that 300 dimensional word vector is good(5536)
The objective function for the GloVe model and What log-bilinear means(5739)
Word senses and word sense ambiguity(h0353)
One word different mean different vector.
then a word can be the sum of them all

It will work good but not bad (h1200)
the vector is so sparse that you can separate out different senses (h1402)
Lecture 3 Gradients by hand(matric calculus) and algorithmically(the backpropagation algorithm) all the math details of doing nerual net learning
![]()
Need to be learn again, it is not totally understanded.
Named Entity Recognition(0530)
![]()
Simple NER (0636)
![]()
How the sample model run (0836)
![]()
update equation(1220)
![]()
jacobian(1811)
![]()
Chain Rule(2015)

![]()
do one example step (2650)
hadamard product ToL
Reusing Computation(3402)

ds/dw


Forward and backward propagation(5000)
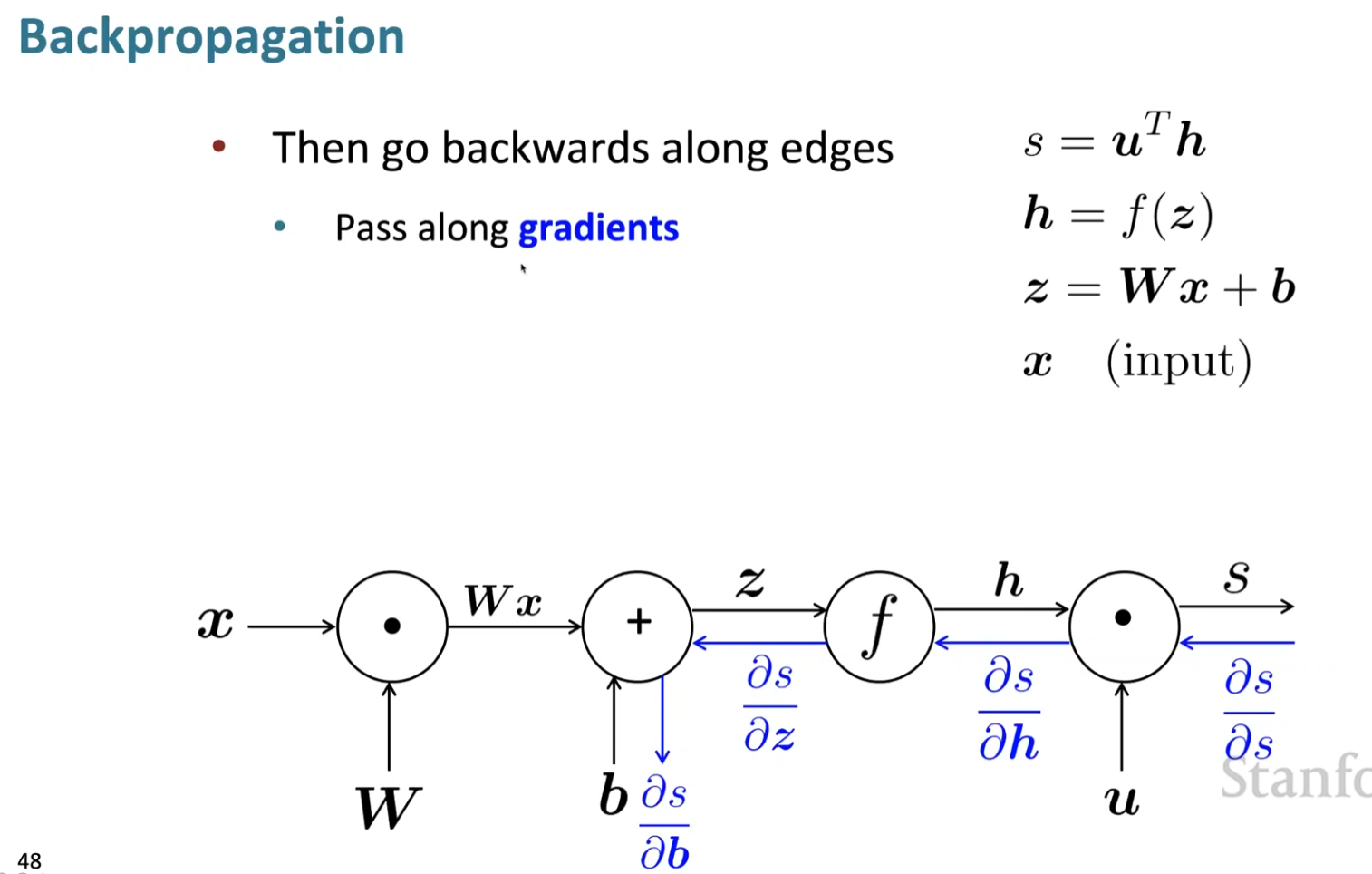
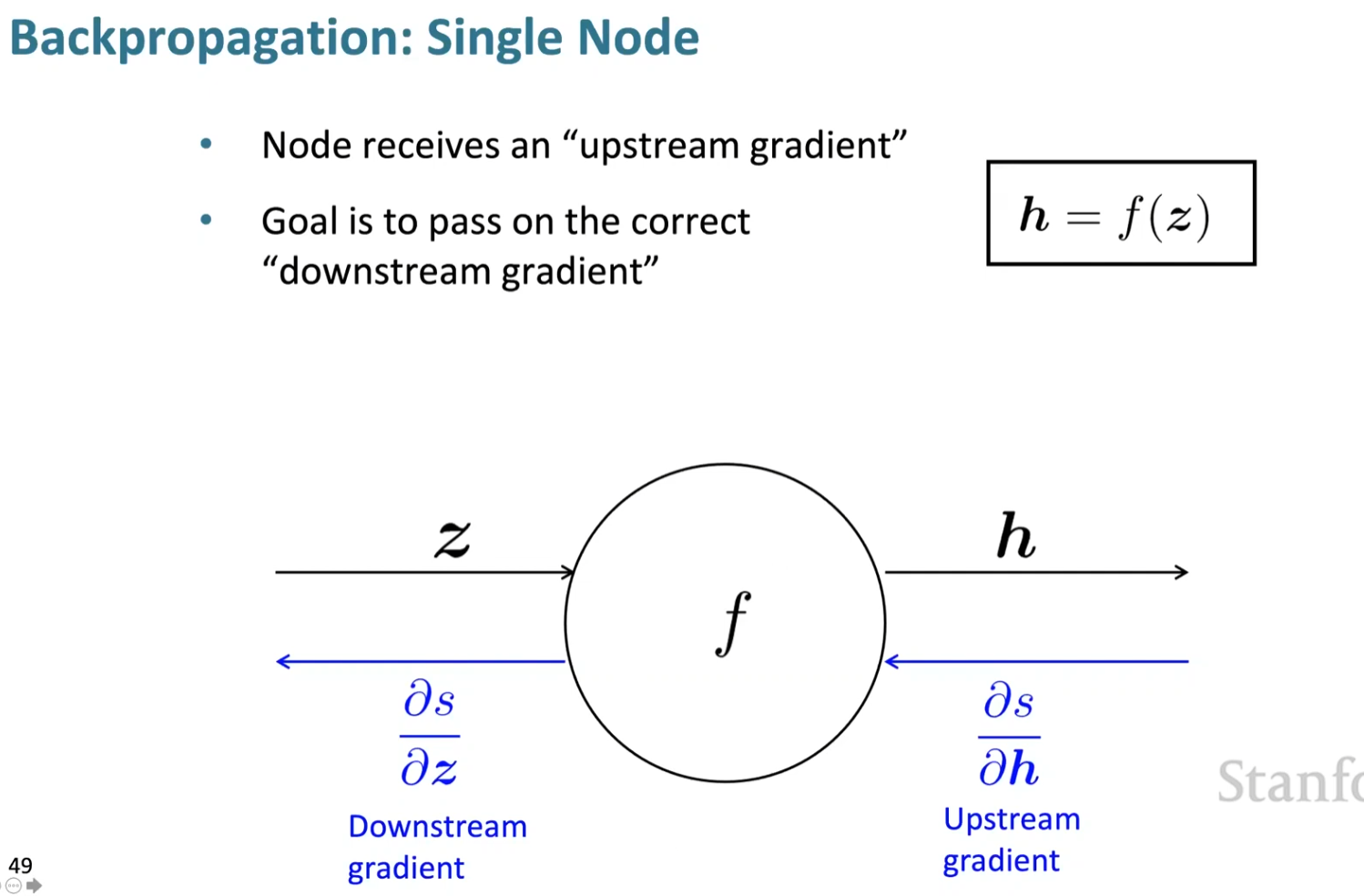
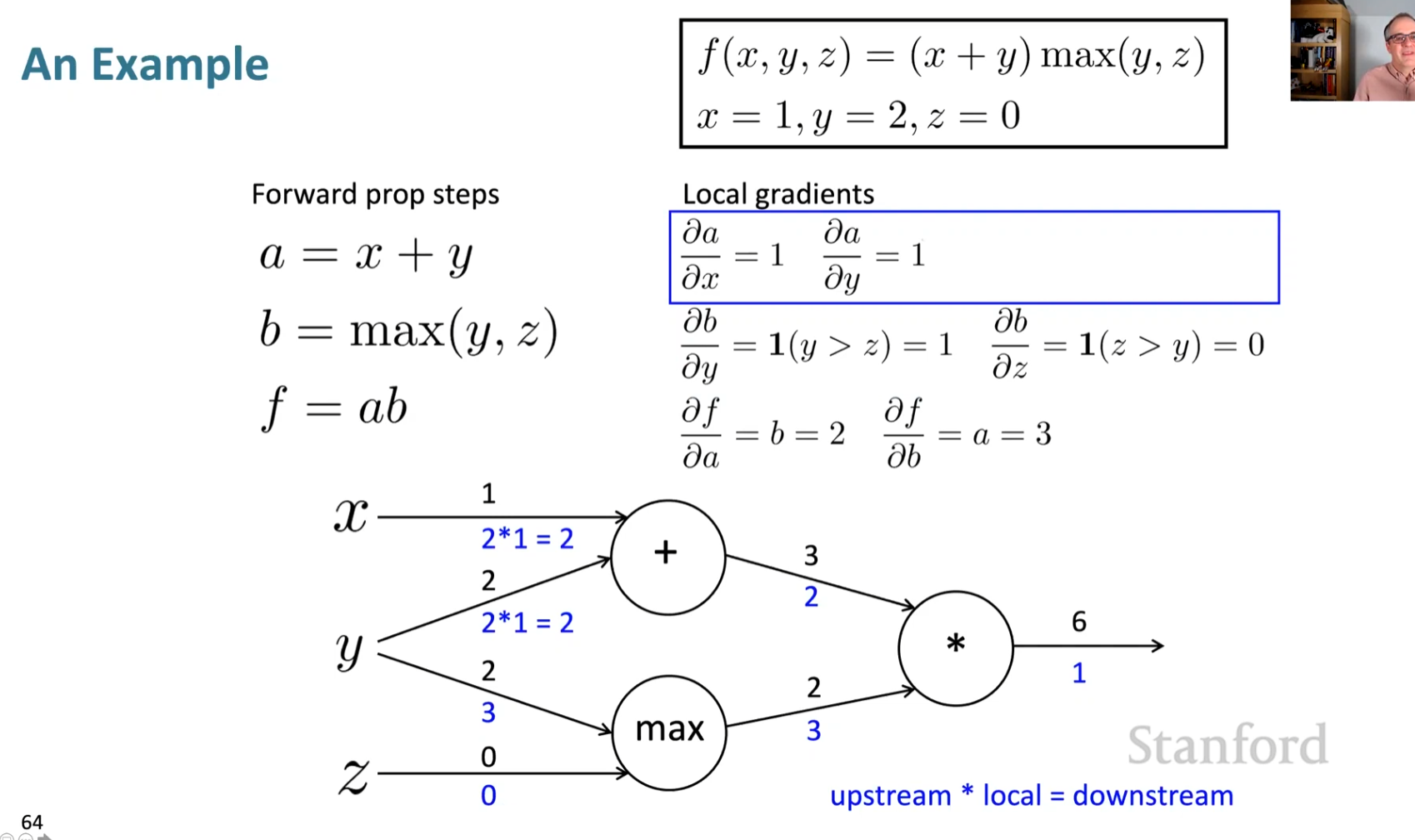
An example(5507)
a = x+y
b = max(y,z)
f = ab
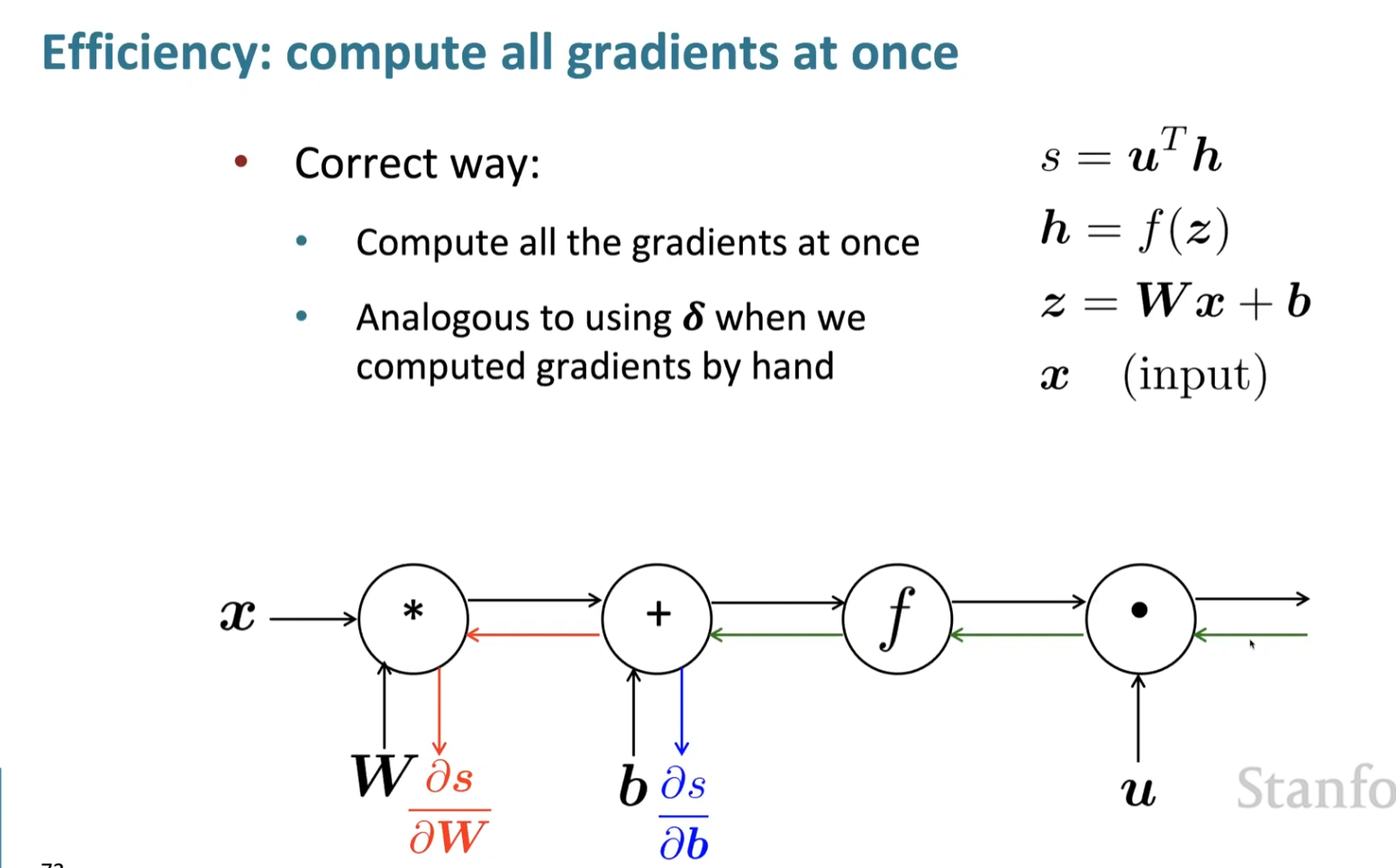
Compute all gradients at once (h0005)
Back-prop in general computation graph(h0800)[ToL]
![]()
Automatic Differentiation(h1346)
Many tools can calculate automaticly.![]()
Manual Gradient checking : Numeric Gradient(h1900)

Lecture 4 Dependency Parsing
![]()
Two views of linguistic structure
Constituency = phrase structure grammar = context-free grammars(CFGs)(0331)
Phrase structure organizes words into nested constituents
![]()
Dependency structure(1449)
Dependency structure shows which words depend on (modify, attach to,or are arguments of)
![]()
Why do we need sentence structure?(2205)
Can not express meaning by just one word.
![]()
Prepositional phrase attachment ambiguity.(2422)
There is some sentence to show it:
San Jose cops kill man with knife
Scientists count whales from space
The board approved [its acquisition] [by Royal Trustco Ltd.] [of Toronto] [for $27 a share] [at its monthly meeting].
Coordination scope ambiguity(3614)
**Shuttle veteran and longtime NASA executive Fred Gregory appointed to board **
Doctor: No heart, cognitive issues
Adjectival/Adverbial Modifier Ambiguity(3755)
Students get [first hand job] experience Students get first [hand job] experience
Verb Phrase(VP) attachment ambiguity(4404)
Mutilated body washes up on Rio beach to be used for Olympics beach volleyball.
![]()
Dependency Grammar and Dependency structure(4355)
![]()
Will add a fake ROOT for handy
Dependency Grammar history(4742)
![]()
The rise of annotated data Universal Dependency tree(5100)
![]()
Tree bank(5400)
Its too slow to write a grammar by hand but its still worth,cause it can used in another place but not only nlp .
how to build parser with dependency(5738)
![]()
Dependency Parsing
![]()
Projectivity(h0416)
![]()
Methods of Dependency Parsing(h0521)
![]()
Greedy transition-based parsing(h0621)
Basic transition-based dependency parser (h0808)
![]()
[root] I ate fish
[root I ate] fish
[root ate] fish
[root ate fish]
[root ate]
[root]
MaltParser(h1351)[ToL]
![]()
Evaluation of Dependency Parsing (h1845)[ToL]
![]()
Lecture-5 Languages models and Recurrent Neural Networks(RNNs)
![]()
A neural dependency parser(0624)
![]()
Distributed Representations(0945)
![]()
Deep Learning Classifier are non-linear classifiers(1210)
![]()
Deep Learning Classifier’s non-linear classifiers:
![]()
Simple feed-forward neural network multi-class classifier (1621)
![]()
Neural Dependency Parser Model Architecture(1730)
![]()
Graph-based dependency parsers (2044)
![]()
Regularization && Overfitting (2529)
![]()
Dropout (3100)[ToL]
![]()
Vectorization(3333)
![]()
Non-linearities (4000)
![]()
Parameter Initialization (4357)
![]()
Optimizers(4617)
![]()
Learning Rates(4810)
It can be slow as the learning go on.
![]()
Language Modeling (5036)
![]()
n-gram Language Models(5356)


Sparsity Problems (5922)
Many situation didn’t occur so it will be zero
![]()
Storage Problems(h0117)
How to build a neural language model(h0609)
![]()
A fixed-window neural Language Model(h1100)
![]()
Recurrent Neural Network (RNN)(h1250)
x1 -> y1
Wx1 x2 -> y1
![]()
A Simple RNN Language Model(h1430)
![]()

Lecture 6 Simple and LSTM Recurrent Neural Networks.
![]()
![]()
The Simple RNN Language Model (0310)
![]()
Training an RNN Language Model (0818)
RNN takes more time.
Teacher Forcing
penalize when dont take its advise
![]()
![]()
![]()
But how do we get the answer?
![]()
![]()
Evaluating Language Models (2447)[ToL]
![]()
Language Model is a system that predicts the next word(3130)
![]()
Other use of RNN(3229)
Tag for word
![]()
Used for classification(3420)
![]()
Used to Language encoder module (3500)
![]()
Used to generate text (3600)
![]()
Problems with Vanishing and Exploding Gradients(3750)[IMPORTANT]
![]()
[ToL]
![]()
Why This is a problem (4400)
![]()
![]()
![]()
We can give him a limit.
![]()
Long Short Term Memory RNNS(LSTMS)(5000)[ToL]
![]()
![]()
![]()
![]()
Bidirectional RNN (h2000)
We need information from the word after
![]()
Lecture-7 Translation, Seq2Seq, Attention
![]()
Machine Translation(0245)
![]()
What do you need (1200)
you need parallel corpus,Then you need alignment
Decoding for SMT(1748)
Try many possible sequences.
![]()
What is Neural Machine Translation(NMT)(2130)
Neural Machine Translation(NMT) is a way to do Machine Translation with a single end-to-end neural net work.
The neural network architecture is called sequence-to-sequence model(aka seq2seq) and it involves RNNs
![]()
Seq2seq is more than MT(2600)
![]()
(2732)[ToL]
Multi-layer RNNs(3323)
![]()
Lower-level basic meaning
Higher-level overall meaning
![]()
Greedy decoding(4000)
![]()
Exhaustive search decoding(4200)
![]()
beam search decoding(4400)
![]()
![]()
![]()
![]()
![]()
How do we evaluate Machine Translation(5550)
BLEU
![]()
NMT perhaps the biggest success story of NLP Deep Learning(h00000)
Attention(h1300)
![]()
![]()
Lecture 8 Final Projects; Practical Tips
![]()
Sequence to Sequence with attention(0235)
![]()
Attention: in equations(0800)
![]()
![]()
there are several attention variants(1500)
![]()
Attention is a general Deep Learning technique(2240)
![]()
Final Project(3000)
Lecture-9 Self- Attention and Transformers
Issues with recurrent models (0434)
Linear interaction distance
Sometimes it is too far too learn from the words.
![]()
Lack of parallelizability(0723)
GPU can count parallelizable but RNN lacks that.
![]()
If not recurrence
Word window models aggregate local contexts (1031)
![]()
Attention(1406)
![]()
Self-Attention(1638)
![]()
Self-attention as an nlp building block(2222)
![]()
Fix the first self-attention problem
sequence order (2423)
![]()
Position representation vector through sinusoids(2624)
Sinusoidal position representations(2730)
Position representation vector from scratch(2830)
![]()
Adding nonlinearities in self-attention(2953)
Barriers and solutions for Self-Attention as building block(2945)
![]()
![]()
(3040)
![]()
(3428)
![]()
The transformer encoder-decoder(3638)
![]()
[ToL]
![]()
key query value(4000)
![]()
![]()
Multi-headed attention (4322)
(4450)
![]()
![]()
Residual connections(4723)
![]()
Layer normalization(5045)
![]()
Scaled fot product(5415)
Lecture 10 - Transformers and Pretraining
![]()
Word structure and subword models(0300)
transform transformerify
taaaasty
![]()
The byte-pair encoding(0659)
Subwords model learn the structure of word. The byte-pair between it and dont learn structure.
(0943)
![]()
![]()
Motivating word meaning and context(1556)
![]()
Pretraining whole models(2000)
![]()
Wordv2vec dont consider context but we can use LSTM to achieve that.
Mask some data and pretrain the model with them.
this model haven’t met overfitting now, you can save some data to test it.(2811)
transformers for encoding and decoding (3030)
Pretraining through language modeling(3400)
![]()
![]()
Stochastic gradient descent and pretrain/finetune(3740)
Model pretraining has three ways (4021)
![]()
Decoder can see the history, the Encoder can also the future.
Encoder-Decoder maybe is the better.
Decoder(4300)
![]()
![]()
Generative Pretrained Transformer(GPT) (4818)
![]()
![]()
GPT2(5400)
![]()
Pretraining Encoding(5545)
(Bert)(5654)
![]()
![]()
Bert will mask some words, ask what have I mask
Bidirectional encoder representations from transformers(h0100)
[ToL]
![]()
![]()
Limitations of pretrained encoders(h0900)
![]()
Extensions of BERT(h1000)
![]()
Pretraining Encoder-Decoder (h1200)
T5(h1500)
The model even dont know how many words are masked
![]()
![]()
In the pretraining the model learned a lot, but it is not always good
GPT3(h1800)
![]()
![]()
Lecture 11 Question Answering
![]()
What is question answering(0414)
![]()
![]()
There are lots of practical applications(0629)
Beyond textual QA problems(1100)
Reading comprehension(1223)
![]()
They are useful for many practical applications
Reading comprehension is an important tested for evaluating how well computer systems understand human language
Standord question answering dataset (1815)
![]()
Neural models for reading comprehension(2428)
![]()
LSTM-based vs BERT models (2713)
![]()
![]()
BiDAF(3200)
![]()
Encoding(3200)
![]()
Attention(3400)
![]()
![]()
Modeling and output layers(4640)
![]()
![]()
BERT for reading comprehension (5227)
![]()
Comparisons between BiDAF and BERT models(2734)
![]()
Can we design better pre-training objectives(h0000)
![]()
open domain question answering(h1000)
![]()
![]()
![]()
DPR(H1400)
![]()
![]()
![]()
DensePhrase:Demo(h1800)
Lecture 12 - Natural Language Generation[ToL]
![]()
What is neural language generation?(0300)
![]()
Mache Translate
Dialogue Systems //siri
Summarization
Visual Description
Creative Generation //story
Components of NLG Systems(0845)
Basic of natural language generation(0916)
![]()
A look at a single step(1024)
![]()
then select and train(1115)
teacher forcing need to be leaned
![]()
Decoding(1317)
![]()
Greedy methods(1432)
![]()
Greedy methods get repetitive(1545)
![]()
why do repetition happen(1613)
![]()
How can we reduce repetition (1824)[ToL]
![]()
People is not always choose the greedy methods(1930)
![]()
Time to get random: Sampling(2047)
![]()
Decoding : Top-k sampling(2100)
![]()
![]()
Issues with Top-k sampling(2339)
![]()
Decoding: Top-p(nucleus)sampling(2421)
![]()
Scaling randomness: Softmax temperature (2500)[ToL]
![]()
improving decoding: re-balancing distributions(2710)
![]()
Backpropagation-based distribution re-balancing(3027)
![]()
Improving Decoding: Re-ranking(3300)[ToL]
![]()
Decoding: Takeaways(3540)
![]()
Training NLG models(4114)
Maximum Likelihood Training(4200)
Are greedy decoders bad because of how they’re trained?
![]()
Unlikelihood Training(4427)[ToL]
![]()
Exposure Bias(4513)[ToL]
![]()
Exposure Bias Solutions(4645)
![]()
![]()
![]()
Reinforce Basics(4900)
![]()
Reward Estimation(5020)
![]()
![]()
reinforce’s dark side(5300)
![]()
![]()
Training: Takeways(5423)
![]()
Evaluating NLG Systems(5613)
Types of evaluation methods for text generation(5734)
![]()
Content Overlap metrics(5800)
![]()
A simple failure case(5900)
![]()
Semantic overlap metrics(h0100)
![]()
Model-based metrics(h0120)
![]()
word distance functions(h0234)
![]()
Beyond word matching(h0350)
![]()
Human evaluations(h0433)
![]()
![]()
Issues(h0700)
![]()
Takeways(h0912)
![]()
Ethical Considerations(h1025)
![]()
![]()
![]()
![]()
![]()
![]()
Lecture 13 - Coreference Resolution
![]()
What is Coreference Resolution?(0604)
Identify all mentions that refer to the same entity in the world
![]()
Applications (1712)
![]()
![]()
Coreference Resolution in Two steps(1947)
![]()
Mention Detection(2049)
![]()
Not quite so simple(2255)
![]()
It is the best donut.
I want to find the best donut.
Avoiding a traditional pipeline system(2811)
![]()
End to End[ToL]
Onto Coreference! First, some linguistics (3035)
Coreference and Anaphor
![]()
![]()
not all anaphoric relations are coreferential (3349)
![]()
Anaphora vs Cataphora(3610)
One look its reference before it the other is after it.
![]()
Taking stock (3801)
![]()
Four kinds of coreference Models(4018)
![]()
Traditional pronominal anaphora resolution:Hobbs’s naive algorithm(4130)
![]()
![]()
![]()
Knowledge-based Pronominal Coreference(4820)
![]()
Hobb’s method can not really solve the questions, the model should really understand the sentence.
Coreference Models: Mention Pair(5624)
![]()
![]()
Mention Pair Test Time(5800)
![]()
Disadvantage(5953)
![]()
Coreference Models: Mention Ranking(h0050)
![]()
![]()
Convolutional Neural Nets(h0341)
![]()
What is convolution anyway?(h0452)
![]()
![]()
![]()
![]()
Summarize what we have usually use pooling
![]()
![]()
Max pooling is usually better.
![]()
End-to-End Neural Coref Model(h1206)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Conclusion (h2017)
![]()
Lecture 14 - T5 and Large Language Models
![]()
(0243)
![]()
![]()
T5 with a task prefix(0800)
![]()
Others
![]()
![]()
STSB
![]()
Summarize
![]()
T5 change little from original transformer(1300)
![]()
what should my pre-training data set be?(1325)
Get from open source data source and then wipe them and get c4 1500
Then is how to train from a start(1659)
![]()
pretrain(1805)
![]()
choose the model(2412)
![]()
They use the encoder-Decoder model, It turns out it works well.
They dont change hyper paramenters because of the cost
pre-training objective(2629)
![]()
Choose different train method
different structure of data source(2822)
![]()
Multi task learning (3443)
![]()
close the gap between multi-task training and this pre-training followed by separate fine tuning(3621)
![]()
What if it happens there are four times computes as much as before (3737)
![]()
Overview(3840)
![]()
![]()
![]()
![]()
What about all of the other languages?(mT5)(4735)
![]()
Same model different corpus.
![]()
![]()
XTREME (5000)
![]()
How much knowledge does a language model pick up during pre-training?(5225)
![]()
![]()
![]()
![]()
Salient span masking (5631)
![]()
Instead of mask randomly, it mask username please date, etc.
Do large language models memorize their training data(h0100)
It seems it did
![]()
![]()
![]()
![]()
![]()
![]()
They need to see examples, they need to see particular examples fewer times in order!
Can we close the gap between large and small models by improving the transformer architecture(h1010)
![]()
in these test, they change some architecture such as RELu.
there actually were very few, if any modifications that improved performance meaningfully.
![]()
![]() (h1700)
(h1700)
QA(h1915)
Lecture 15 - Add Knowledge to Language Models
![]()
Recap: LM(0232)
![]()
![]()
What does a language model know?(0423)
![]()
Thing may right in logic but wrong in fact.
![]()
The importance of know ledge-aware language models(0700)
![]()
Query traditional knowledge bases(0750)
![]()
Query language models as knowledge bases(0955)
![]()
Compare and disadvantage(1010)
![]()
Techniques to add knowledge to LMs(130)
![]()
Add pretrained embeddings(1403)
![]()
Aside: What is entity linking?(1516)
![]()
Method 1: Add pretrained entity embeddings(1815)
![]()
How to we incorporate pretrained entity embeddings from a different embedding space?(2000)
![]()
ERNIE: Enhanced language representation with informative entities(2143)
![]()
![]()
![]()
![]()
strengths & remaining challenges(2610)
![]()
Jointly learn to link entities with KnowBERT(2958)
![]()
Use an external memory(3140)
![]()
KGLM(3355)
![]()
Local knowledge and full knowledge
![]()
When should the model use the external knowledge(3600)
![]()
![]()
![]()
![]()
Compare to the others(4334)
![]()
More recent takes: Nearest Neighbor Language Models(kNN-LM)(4730)
![]()
![]()
Modify the training data(5230)
![]()
![]()
WKLM(5458)
![]()
![]()
![]()
Learn inductive biases through masking(5811)
![]()
![]()
Salient span masking(5927)
![]()
Recap(h0053)
![]()
Evaluating knowledge in LMS(h0211)
LAMA(h0250)
![]()
![]()
The limitations (h0650)
![]()
LAMA_UnHelpful Names(LAMA-UHN)
![]()
** They delete something that may caused by co-occurrence **
Developing better prompts to query knowledge in LMS
![]()
![]()
Knowledge-driven downstream tasks(h1253)
![]()
Relation extraction performance on TACED(h1400)
![]()
Entity typing performance on Open Entuty
![]()
Recap: Evaluating knowledge in LMs(h1600)
![]()
Other exciting progress & what’s next?(h1652)
![]()
Lecture 17 - Model Analysis and Explanation
![]()
![]()
Motivation
what are our models doing(0415)
![]()
how do we make tomorrow’s model?(0515)
![]()
What biases are built into model?(0700)
![]()
how do we make in the following 25years(0800)
![]()
Model analysis at varying levels of abstraction(0904)
![]()
Model evaluation as model analysis(1117)
![]()
Model evaluation as model analysis in natural language inference(1344)
![]()
What if the model is simple using heuristics to get good accuracy?(1558)
![]()
![]()
Language models as linguistic test subjects(2023)
![]()
![]()
![]()
Careful test sets as unit test suites: CheckListing(3230)
![]()
Fitting the dataset vs learning the task(3500)
![]()
Knowledge evaluation as model analysis(3642)
![]()
Input influence: does my model really use long-distance context?(3822)
![]()
Prediction explanations: what in the input led to this output?(4054)
![]()
Prediction explanations: simple saliency maps(4230)
![]()
![]()
Explanation by input reduction (4607)
![]()
![]()
Analyzing models by breaking them(5106)
![]()
![]()
They add a nonsense sentence at the end and the prediction changed.
![]()
Change the Q also make the prediction changed
Are models robust to noise in their input?(5518)
![]()
It seems not.
Analysis of “interpretable” architecture components(5719)
![]()
![]()
![]()
![]()
![]()
![]()
Probing: supervised analysis of neural networks(h0408)
![]()
![]()
![]()
![]()
![]()
![]()
the most efficient layer is in the middlwe.
![]()
deeper, more abstract
Emergent simple structure in neural networks(h1019)
![]()
Probing: tress simply recoverable from BERT representations(h1136)
![]()
Final thoughts on probing and correlation studies(h1341)
![]()
Not causal study
Recasting model tweaks and ablations as analysis(h1406)
![]()
Ablation analysis: do we need all these attension heads?(h1445)
![]()
What’s the right layer order for a transformer?(h1537)
![]()
Parting thoughts(h1612)
![]()
Lecture 18 - Future of NLP + Deep Learning
![]()
![]()
General Representation Learning Recipe(0312)
![]()
Certain properties emerge only when we scale up the model size!
Large Language Models and GPT-3(0358)
Large Language models and GPT-3(0514)
![]()
What’s new about GPT-3
![]()
![]()
![]()
There are three lessons left, They will be finished in the review when I come back from Lee.
CS224N NLP相关推荐
- cs224n上完后会会获得证书吗_斯坦福NLP组-CS224n: NLP与深度学习-2019春全套资料分享...
斯坦福自然语言处理小组2019年的最新课程<CS224n: NLP与深度学习>春季课程已经全部结束了,课程内容囊括了深度学习在各项NLP任务中应用的最新技术,非常值得一看.本文整理本期课程 ...
- CS224n NLP句法分析依赖解析深度学习作业笔记
CS224n NLP句法分析依赖解析深度学习之作业笔记 句法分析的基础内容请参阅CS224n笔记6 句法分析 http://www.hankcs.com/nlp/cs224n-dependency-p ...
- Task 2: Word Vectors and Word Senses (附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)
Task 2: Word Vectors and Word Senses 目录 Task 2: Word Vectors and Word Senses 一.词向量计算方法 1 回顾word2vec的 ...
- Task 3: Subword Models (附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)
Task 3: Subword Models 目录 Task 3: Subword Models 回顾:Word2vec & Glove 一.人类语言声音:语音学和音系学 二.字符级模型(Ch ...
- Task 4: Contextual Word Embeddings (附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)
Task 4: Contextual Word Embeddings 目录 Task 4: Contextual Word Embeddings 词向量的表示 一.Peters et al. (201 ...
- Task 5: Homework(附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)
Task 5: Homework--英文词向量的探索 目录 Task 5: Homework--英文词向量的探索 词向量 本项目需要下载的包 Part 1:基于计数的词向量 问题1.1:实现不同单词 ...
- 斯坦福CS224n NLP课程【十五】——共指解析 指代消解
Coreference Resolution 指代消解是什么? 找出文本中名词短语所指代的真实世界中的事物.比如: 不只是代词能够指代其他事物,所有格和其他名词性短语也可以.甚至还存在大量嵌套的指代: ...
- 斯坦福CS224n NLP课程【十四】——树RNN递归和短语句法分析
语言光谱模型 对于语义相似性等这类目标来说,最好的方法还是词袋 最简陋最常用的是词袋模型,或"词向量袋模型".最复杂的可能是短语结构树,额外再标注一些诸如指代.语义等标签. 这张图 ...
- 训练softmax分类器实例_CS224N NLP with Deep Learning(四):Window分类器与神经网络
Softmax分类器 我们来回顾一下机器学习中的分类问题.首先定义一些符号,假设我们有训练集 ,其中 为输入, 为标签,共包括 个样本: 表示第 个样本,是一个 维的向量: 表示第 个样本的标签,它的 ...
- CS224N笔记(1~3)简介+word2vector
CS224N NLP与深度学习的结合简介 文章目录 CS224N NLP与深度学习的结合简介 简介 为什么NLP会这么困难? Deep NLP: What is word2vector? word2v ...
最新文章
- 前端开发之走进Vue.js
- grpc通信原理_容器原理架构详解(全)
- UART的16倍频过采样和3倍频过采样
- struts2 不返回result的做法
- Angular模块/服务/MVVM
- 区块链,供应链金融的新机遇
- Redis 远程连接和基本命令
- C++vector容器-互换容器
- 【剑指offer】面试题31:栈的压入,弹出序列
- Oracle corrupt block(坏块) 详解
- 曾鸣:互联网的本质是什么?| 内部干货
- 关于电子科技大学成电讲坛类门票获取的调查报告
- mmdetection 安装配置全过程
- 大数据基石-Hadoop3.x学习教程-大数据场景介绍
- 使用微信小程序拨打电话
- 大数据告诉你哪部电影最有影响力
- 代码随想录训练营day51
- 东南大学 学分绩点gpa 计算器 【源码】
- dem数据下载后怎么使用?查看等高线、地形渲染、地形裁剪教程
- 不知如何选股?不知哪种指标策略可靠?量化分析比较VRSI、BBIBOLL、WR、BIAS、RSI指标策略收益情况