Hadoop---集群安装
在一个全配置的集群上,“运行Hadoop”意味着在网络分布的不同服务器上运行一组daemons。这些daemons包括:
- NameNode
- DataNode
- Secondary NameNode
- JobTracker
- TaskTracker
NameNode位于HDFS的主端,指导从端的DataNode执行底层的I/O任务。
DataNode将HDFS数据块读取或者写入到本地系统的实际文件中
Secondary NameNode是一个用于监测HDFS集群状态的辅助daemon。
JobTracker是应用程序和Hadoop之间的纽带。一旦提交代码到集群上,JobTracker就会确定执行计划,包括决定处理哪些文件、为不同的任务分配节点以及监控所有任务的运行。
TaskTracker管理各个任务在每个从节点上的执行情况。
下图为Hadoop集群的典型拓扑图。这是一个主/从架构,其中NameNode和JobTracker为主端,DataNode和TaskTracker为从端。
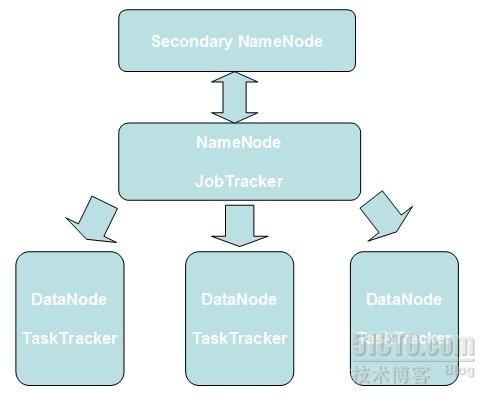
安装一个Hadoop集群时,需要专门指定一个服务器作为主节点。这个服务器通常会运行NameNode和JobTracker。它也将作为一个基站,负责联络并激活所有从节点上的DataNode和TaskTracker。Hadoop使用SSH协议来通信。
安装Hadoop集群前,要先定义一个公共账号。这里使用xiaoruoen
安装Hadoop集群时要先验证SSH是否安装。
如果没有安装,使用yum install openssh来安装,如下
- [xiaoruoen@localhost ~]# yum install openssh
- Loaded plugins: fastestmirror
- Loading mirror speeds from cached hostfile
- * base: mirrors.163.com
- * extras: mirrors.163.com
- * updates: mirrors.163.com
- Setting up Install Process
- Resolving Dependencies
- --> Running transaction check
- --> Processing Dependency: openssh = 4.3p2-36.el5 for package: openssh-clients
- --> Processing Dependency: openssh = 4.3p2-36.el5 for package: openssh-askpass
- --> Processing Dependency: openssh = 4.3p2-36.el5 for package: openssh-server
- ---> Package openssh.i386 0:4.3p2-82.el5 set to be updated
- --> Running transaction check
- ---> Package openssh-askpass.i386 0:4.3p2-82.el5 set to be updated
- ---> Package openssh-clients.i386 0:4.3p2-82.el5 set to be updated
- ---> Package openssh-server.i386 0:4.3p2-82.el5 set to be updated
- --> Finished Dependency Resolution
- Dependencies Resolved
- =====================================================================================================================================================
- Package Arch Version Repository Size
- =====================================================================================================================================================
- Updating:
- openssh i386 4.3p2-82.el5 base 291 k
- Updating for dependencies:
- openssh-askpass i386 4.3p2-82.el5 base 42 k
- openssh-clients i386 4.3p2-82.el5 base 455 k
- openssh-server i386 4.3p2-82.el5 base 275 k
- Transaction Summary
成功安装SSH之后,使用主节点上的ssh-keygen来生成一RSA密钥对。
- [xiaoruoen@localhost ~]$ ssh-keygen -t rsa
- Generating public/private rsa key pair.
- Enter file in which to save the key (/home/xiaoruoen/.ssh/id_rsa):
- Created directory '/home/xiaoruoen/.ssh'.
- Enter passphrase (empty for no passphrase):
- Enter same passphrase again:
- Your identification has been saved in /home/xiaoruoen/.ssh/id_rsa.
- Your public key has been saved in /home/xiaoruoen/.ssh/id_rsa.pub.
- The key fingerprint is:
- 33:47:bc:c0:cf:82:92:d2:69:3a:73:f1:3a:14:74:f8 xiaoruoen@localhost.localdomain
- [xiaoruoen@localhost ~]$ more /home/xiaoruoen/.ssh/id_rsa.pub
- ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAnYAiD7YCrZR3L8Ps1KKqy1FoA3azcnrFP481zJfGGVKC2judapiZJcjca48B99Zqa4jNyRgREAzTQHxbSRKkQqnA1TB5BK7sKrXp6yl3lCQ/E4k05i6aLHU6DImufWJlmbBr
- 3ILrxG+sNiD/ihcZ66o74/lXUemTHcNomRLEUgJoI8U6X2PiTmD5HqW7VxelseJ2yIZ8cfx9n+0MQbEQBj5Nme8JR7XBFEGWFzySfp2hWR9SfTwqcRRuiVgEczics4ebdk22SsP13lAdltSS/mqJfVG2G6neVBTt+E0+0AI8
- 27DBza9oY2bMiR0HCCihEU2vuLTaKpAzigna1/h2nQ== xiaoruoen@localhost.localdomain
将公钥分布到从服务器上
- [xiaoruoen@localhost ~]$ scp ~/.ssh/id_rsa.pub xiaoruoen@192.168.0.107:~/master_key
- The authenticity of host '192.168.0.107 (192.168.0.107)' can't be established.
- RSA key fingerprint is d1:ac:46:8f:97:32:0b:88:82:2b:14:60:b0:e6:70:c4.
- Are you sure you want to continue connecting (yes/no)? y
- Please type 'yes' or 'no': yes
- Warning: Permanently added '192.168.0.107' (RSA) to the list of known hosts.
- xiaoruoen@192.168.0.107's password:
- id_rsa.pub 100% 413 0
登录到从服务器上进行验证
- [xiaoruoen@localhost ~]$ mkdir ~/.ssh
- [xiaoruoen@localhost ~]$ chmod 700 ~/.ssh
- [xiaoruoen@localhost ~]$ mv ~/master_key ~/.ssh/authorized_keys
- [xiaoruoen@localhost ~]$ chmod 600 ~/.ssh/authorized_keys
尝试从主节点登录到目标节点来验证它的正确性
- [xiaoruoen@localhost ~]$ ssh 192.168.0.107
- Last login: Thu Apr 12 22:07:21 2012 from 192.168.0.102
到Hadoop根目录下的conf目录下找到hadoop-env.sh,修改JAVA_HOME
- [xiaoruoen@localhost ~]$ cd $HADOOP_HOME/conf
- [xiaoruoen@localhost conf]$ ll
- total 140
- -rw-rw-r-- 1 root root 7457 Mar 25 08:01 capacity-scheduler.xml
- -rw-rw-r-- 1 root root 535 Mar 25 08:01 configuration.xsl
- -rw-rw-r-- 1 root root 178 Mar 25 08:01 core-site.xml
- -rw-rw-r-- 1 root root 327 Mar 25 08:01 fair-scheduler.xml
- -rw-rw-r-- 1 root root 2237 Mar 25 08:01 hadoop-env.sh
- -rw-rw-r-- 1 root root 1488 Mar 25 08:01 hadoop-metrics2.properties
- -rw-rw-r-- 1 root root 4644 Mar 25 08:01 hadoop-policy.xml
- -rw-rw-r-- 1 root root 178 Mar 25 08:01 hdfs-site.xml
- -rw-rw-r-- 1 root root 4441 Mar 25 08:01 log4j.properties
- -rw-rw-r-- 1 root root 2033 Mar 25 08:01 mapred-queue-acls.xml
- -rw-rw-r-- 1 root root 178 Mar 25 08:01 mapred-site.xml
- -rw-rw-r-- 1 root root 10 Mar 25 08:01 masters
- -rw-rw-r-- 1 root root 10 Mar 25 08:01 slaves
- -rw-rw-r-- 1 root root 1243 Mar 25 08:01 ssl-client.xml.example
- -rw-rw-r-- 1 root root 1195 Mar 25 08:01 ssl-server.xml.example
- -rw-rw-r-- 1 root root 382 Mar 25 08:01 taskcontroller.cfg
- [xiaoruoen@localhost conf]$ vim hadoop-env.sh
- # Set Hadoop-specific environment variables here.
- # The only required environment variable is JAVA_HOME. All others are
- # optional. When running a distributed configuration it is best to
- # set JAVA_HOME in this file, so that it is correctly defined on
- # remote nodes.
- # The java implementation to use. Required.
- export JAVA_HOME=/home/samba/jdk1.6.0_30
Hadoop的设置主要包含在XML配置文件中。在0.20版本前,它们是hadoop-default.xml和hadoop-site.xml。在版本0.20中,这hadoop-site.xml被分离成3个xml文件:core-site.xml,hdfs-stie.xml与mapred-site.xml。
分布式运行hadoop,就要修改这三个文件
在core-site.xml配置NameNode
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://master:9000</value>
- </property>
- </configuration>
在mapred-site.xml中配置JobTracker
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>hdfs://master:9001</value>
- </property>
- </configuration>
在hdfs-site.xml中配置增大HDFS备份参数
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- </configuration>
更新masters和slaves文件来指定共它daemon的位置。
设定主服务器所在位置,也就是NameNode与JobTracker所在位置
- vim masters
- localhost
设定从服务器所在位置,也就是DataNode与TaskTracker所在位置
- vim slaves
- 192.168.0.108
- 192.168.0.109
格式化HDFS文件系统
hadoop namenode -format
(如果提示未找到类,可以在~/.bash_profile里设置CLASSPATH为$HADOOP_HOME/hadoop-core-*.jar;$HADOOP_HOME/hadoop-tool-*.jar;)
启动所有的节点
- ./start-all.sh
使用JPS来查看节点
- jps
- 30879 JobTracker
- 30717 NameNode
- 30965 jps
- jps
- 7101 TaskTracker
- 7617 Jps
- 6988 DataNode
转载于:https://blog.51cto.com/xiaoruoen/832651
Hadoop---集群安装相关推荐
- Hadoop实战-中高级部分 之 Hadoop 集群安装
Hadoop RestFul Hadoop HDFS原理1 Hadoop HDFS原理2 Hadoop作业调优参数调整及原理 Hadoop HA Hadoop MapReduce高级编程 Hadoop ...
- Hadoop集群安装与配置
转载自Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否则请先查看Had ...
- Hadoop集群安装及其配置(三台虚拟机)
Hadoop集群安装及其配置(三台虚拟机) 利安装配置前准备--安装虚拟机 利用cat查看配置文件 修改主机名称 配置IP映射 配置网卡设备的mac地址 Xshell的安装与配置 ssh的配置 JDK ...
- Hadoop集群安装和搭建(全面超详细的过程)
Hadoop集群安装和搭建(全面超详细的过程) 文章目录 Hadoop集群安装和搭建(全面超详细的过程) 前言 一.虚拟机的安装 二.Linux系统安装 1.环境准备 2.虚拟机安装 三.Centos ...
- hadoop集群安装
一.简述 本次集群安装基于4台虚拟集群下进行. hadoop版本使用 2.6.4 操作系统为 centos6.5 jdk版本为 jdk-7u67-linux-x64.tar.gz 二.准备 创建had ...
- Hadoop集群安装-CDH5(5台服务器集群)
CDH5包下载:http://archive.cloudera.com/cdh5/ 架构设计: 主机规划: IP Host 部署模块 进程 192.168.254.151 Hadoop-NN-01 N ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- Hadoop集群安装部署_分布式集群安装_02
文章目录 一.上传与 解压 1. 上传安装包 2. 解压hadoop安装包 二.修改hadoop相关配置文件 2.1. hadoop-env.sh 2.2. core-site.xml 2.3. hd ...
- Hadoop集群安装部署_分布式集群安装_01
文章目录 1. 分布式集群规划 2. 数据清理 3. 基础环境准备 4. 配置ip映射 5. 时间同步 6. SSH免密码登录完善 7. 免密登录验证 1. 分布式集群规划 伪分布集群搞定了以后我们来 ...
- Hadoop集群安装部署_伪分布式集群安装_02
文章目录 一.解压安装 1. 安装包上传 2. 解压hadoop安装包 二.修改Hadoop相关配置文件 2.1. hadoop-env.sh 2.2. core-site.xml 2.3. hdfs ...
最新文章
- Python 图像处理简介——色彩阴影调整
- Android UI -- 布局介绍(布局包括FrameLayout, LinearLayout, RelativeLayout, GridLayout)
- python浪漫代码-python七夕浪漫表白源码
- 【Python】趣学Python变量和赋值:大师兄和二师兄教的好~
- WebDriver高级应用实例(7)
- 445. 两数相加 II golang
- python 水位_Leetcode 42. 接雨水 - python - 递归 查找分水岭
- C++ 空间配置器(allocator)
- 例子---年倒计时/JS日期对象类型
- 不同网站不同网卡_弄清高端网站建设的独特不同之处才能做好网站
- 分类型变量预测连续型变量_「JS进阶」你真的掌握变量和类型了吗
- JavaScript之子类构建工具
- Windows服务创建及安装
- oracle将日期格式化to_char及字符串转日期to_date
- edge chrome Android,微软Edge浏览器正式登陆Android平台
- mac电脑上的效率工具:alfred 4
- GB28181协议--设备注册和注销
- 【MapGIS精品教程】001:MapGIS K9完整图文安装教程
- Android Jetpack 系列篇(一) Data Binding
- 无线承载根据承载的内容不同分为SRB和DRB EPS承载根据用户业务需求和Qos的不同可以分为GBR/ Non-GBR 承载...