efk使用_如何使用EFK创建开源堆栈
efk使用
管理服务器的基础架构并非易事。 当一个群集的行为异常时,登录到多个服务器,检查每个日志,并使用多个过滤器,直到您发现罪魁祸首不是对资源的有效利用。
改进处理基础结构或应用程序的方法的第一步是实施集中式日志记录系统。 这将使您能够将来自任何应用程序或系统的日志收集到一个集中的位置,并对它们进行过滤,汇总,比较和分析。 如果有服务器或应用程序,则应该有一个统一的日志记录层。
值得庆幸的是,我们有一个开源堆栈可以简化这一过程。 结合使用Elasticsearch,Fluentd和Kibana(EFK),我们可以创建功能强大的堆栈,以在集中位置收集,存储和可视化数据。
让我们首先定义每个组件以了解全局。 Elasticsearch是一个开源的分布式RESTful搜索和分析引擎,或者仅仅是存储所有日志的对象存储。 Fluentd是一个开源数据收集器,可让您统一数据收集和使用以更好地使用和理解数据。 最后, Kibana是Elasticsearch的Web UI。
一张图片胜过千言万语:
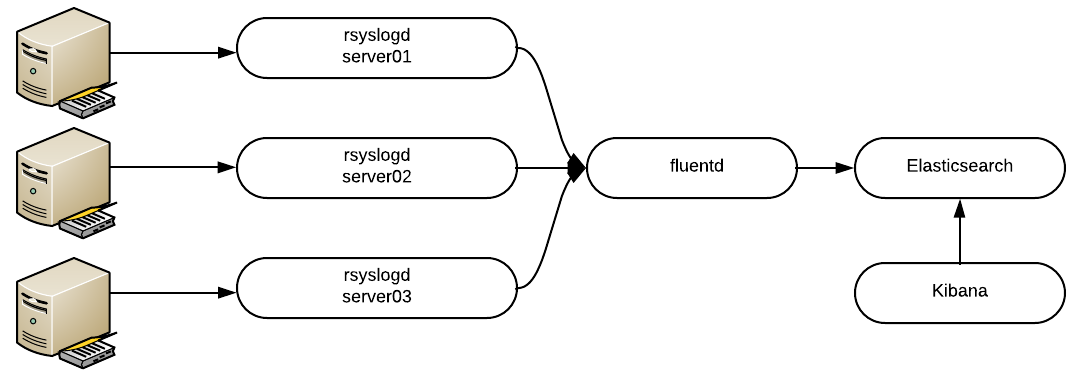
使用集中式Fluentd聚合器的EFK堆栈。
图片由Michael Zamot,CC BY
还有其他收集日志的方法,例如在每个主机中运行一个小型Fluentd转发器,但这超出了本文的范围。
要求
我们将每个组件安装在其自己的Docker容器中。 使用Docker,我们可以更快地部署每个组件,将重点放在EFK上,而不是发行版专用位,并且我们始终可以删除容器并重新开始。 我们将使用官方的上游图片。
要了解有关Docker的更多信息,请阅读Vincent Batts的精彩文章: Docker初学者指南 。
通过以root用户身份运行以下命令来提高mmap限制:
$ sudo sysctl -w vm.max_map_count=262144
要永久设置此值,请更新/etc/sysctl.conf的vm.max_map_count设置。
这是必需的; 否则,Elasticsearch可能会崩溃。
运行Elasticsearch
要允许容器彼此通信,请创建一个Docker网络:
$ sudo docker network create efk
[...]
执行以下命令以在Docker中启动Elasticsearch:
$ sudo docker run --network=efk --name elasticsearch -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "cluster.name=docker-cluster" -e "bootstrap.memory_lock=true" -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" --ulimit memlock=-1:-1 -v elasticdata:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2
验证容器正在运行:
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6e0db1486ee2 docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2 "/usr/local/bin/docke" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
让我们解耦命令以了解我们刚刚做了什么:
我们使用docker run创建一个新的容器。- 我们使用
--network将容器附加到该特定网络。 - 我们需要定义一个容器名称; 它将用作主机名。
- 参数
-p将我们的主机端口映射到容器端口。 Elasticsearch使用端口9200和9300。 - 带
-e的多个参数是传递到容器以更改配置的环境变量。 - 我们定义了一个自定义
ulimit来禁用交换,以提高性能和节点稳定性。 - 根据设计,容器是临时的。 这意味着它们不存储数据,因此为了保持数据和日志的安全,我们需要创建一个卷并将其安装在容器中。 在我们的情况下,它已安装到
/usr/share/elasticsearch/data。 这是Elasticsearch存储数据的路径。
验证该卷已创建:
$ sudo docker volume ls
[...]
local elasticdata
即使删除容器,此卷也将保留。
大! Elasticsearch正在运行。 让我们继续。
运行基巴纳
Kibana是一个简单得多的命令。 执行以下命令来旋转它:
$ sudo docker run --network=efk --name kibana -d -p 5601:5601 docker.elastic.co/kibana/kibana-oss:6.2.2
默认情况下,Kibana将尝试与名为elasticsearch的主机进行通信。
确认您可以通过以下URL在浏览器中访问Kibana:http:// <docker host>:5601
此时,Elasticsearch尚未索引任何数据,因此您将无法做更多的事情。
让我们开始收集日志!
运行流畅
以下步骤比较棘手,因为官方Docker映像不包含Elasticsearch插件。 我们将定制。
创建一个名为fluentd的目录,并创建一个名为plugins的子目录:
$ mkdir -p fluentd/plugins
现在,让我们创建Fluentd配置文件。 在fluentd目录中,创建一个名为fluent.conf的文件,其内容如下:
$ cat fluentd/fluent.conf
<source>
type syslog
port 42185
tag rsyslog
</source>
<match rsyslog.**>
type copy
<store>
type elasticsearch
logstash_format true
host elasticsearch # Remember the name of the container
port 9200
</store>
</match>
<source>块启用syslog插件,侦听端口和地址。 块<match rsyslog.**>将匹配来自syslog插件的所有日志,并将数据发送到Elasticsearch。
现在在Fluentd文件夹中创建另一个文件Dockerfile :
$ cat fluentd/Dockerfile
FROM fluent/fluentd:v0.12-onbuild
RUN apk add --update --virtual .build-deps \
sudo build-base ruby-dev \
&& sudo gem install \
fluent-plugin-elasticsearch \
&& sudo gem sources --clear-all \
&& apk del .build-deps \
&& rm -rf /var/cache/apk/* \
/home/fluent/.gem/ruby/2.3.0/cache/*.gem
这将修改官方的Fluentd Docker映像并添加Elasticsearch支持。
Fluentd目录应如下所示:
$ ls fluentd/
Dockerfile fluent.conf plugins
现在我们可以构建容器了。 在Fluentd目录中执行以下命令:
$ sudo docker build fluentd/
[...]
Successfully built <Image ID>
现在,我们准备开始堆栈的最后一部分。 执行以下命令以启动容器:
$ sudo docker run -d --network efk --name fluentd -p 42185:42185/udp <Image ID>
您的统一日志堆栈已部署。 现在是时候对主机的rsyslog进行配置,以将数据发送到Fluentd。
登录到要从中收集日志的每个节点,并在/etc/rsyslog.conf的末尾添加以下行:
*.* @<Docker Host>:42185
然后重新启动rsyslog服务:
$ sudo systemctl restart rsyslog
不要忘了检查Kibana,您的所有日志都将在那里。
用Docker Compose打包所有内容
我们可以使用Docker Compose将之前完成的所有步骤组合到一个命令中。 Compose是用于定义和运行多容器Docker应用程序的工具。 通过Compose,您可以使用YAML文件(称为Compose文件)来配置应用程序的服务。 在我们的案例中,是EFK服务。
要安装Docker Compose,请执行以下命令:
$ sudo curl -L https://github.com/docker/compose/releases/download/1.19.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
$ sudo chmod +x /usr/local/bin/docker-compose
验证它是否正常工作:
$ docker-compose version
docker-compose version 1.19.0, build 9e633ef
太棒了! 我们之前执行的所有步骤都可以使用以下docker-compose.yml文件进行总结(我们仍然需要创建Fluentd文件夹和文件):
$ cat docker-compose.yml
version: '2.1'
services:
fluentd:
build: ./fluentd
links:
- "elasticsearch"
expose:
- 42185
ports:
- "42185:42185/udp"
logging:
driver: "json-file"
options:
max-size: 100m
max-file: "5"
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2
container_name: elasticsearch
ports:
- "9200:9200"
environment:
- "discovery.type=single-node"
- "cluster.name=docker-cluster"
- "bootstrap.memory_lock=true"
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- elasticdata:/usr/share/elasticsearch/data
kibana:
image: docker.elastic.co/kibana/kibana-oss:6.2.2
container_name: kibana
links:
- "elasticsearch"
ports:
- "5601:5601"
volumes:
elasticdata:
driver: local
然后,您可以使用一个命令启动所有容器:
$ sudo docker-compose up
如果要删除所有容器(卷除外):
$ sudo docker-compose rm
使用一个简单的YAML文件,您的概念证明就可以立即部署到任何地方,并获得一致的结果。 当您对解决方案进行了彻底的测试后,请别忘了阅读Elasticsearch , Fluentd和Kibana的官方文档,以确保您的实施生产质量。
当您使用EFK(和Docker)时,您将认识到它的实用性,并且您作为系统管理员的生活将永远不同。
进一步阅读
使用Docker安装Elasticsearch
使用Docker安装Fluentd
统一日志记录层:将数据转化为行动
Docker撰写
翻译自: https://opensource.com/article/18/3/efk-creating-open-source-stack
efk使用
efk使用_如何使用EFK创建开源堆栈相关推荐
- 数据库创建函数_达梦数据库创建UUID函数
数据库创建函数_达梦数据库创建UUID函数 接触达梦数据库有一段时间了,整理了一些资料,今天分享一下达梦数据UUID自定义函数 UUID函数定义 很多数据库都有提供UUID函数,可是接触达梦数据库后, ...
- linux 添加路由_在 Linux 上使用开源软件创建 SDN | Linux 中国
使用开源路由协议栈 Quagga,使你的 Linux 系统成为一台路由器.https://linux.cn/article-12199-1.html作者:M Umer译者:messon007 网络路由 ...
- 开源css库_使用CSS和其他开源工具创建标志
开源css库 "创建和发展有关所有类型,其形式和功能的旗帜的知识体系,以及基于该知识的科学理论和原理." -根据国际皮肤病学联合会的定义,对皮肤病学进行定义. 有些国旗是国家的象征 ...
- 开源钱包_硬件钱包是否应该开源
开源钱包 Coauthored by Lixin Liu and Patrick Kim 刘立新 和 帕特里克·金 合着 This article was written before the lau ...
- huggingface实操_盘点2018年度GtiHub开源项目TOP 25
本文作者 Pranav Dar 是 Analytics Vidhya 的编辑,对数据科学和机器学习有较深入的研究和简介,致力于为使用机器学习和人工智能推动人类进步找到新途径.2018 这一年中,作者在 ...
- 开源贡献 计算_如何克服恐惧并为开源做贡献
开源贡献 计算 Are you a new developer? Or maybe even just an old-timer who has been in a company for ten y ...
- 开源项目_可能使用到的开源项目集合
可能会使用到的开源项目集合: http://www.oschina.net/news/69808/2015-annual-ranking-top-100-new-open-source-softwar ...
- mysql 新增从数据库_从零开始学 MySQL - 创建数据库并插入数据
目录 1.实验内容 2.实验知识点 3.开发准备 4.实验总结 1.实验内容 本次课程将介绍 MySQL 新建数据库,新建表,插入数据以及基本数据类型的相关知识.本节实验将创建一个名为 mysql_s ...
- chrome postman插件_一款 Postman 的开源替代品: Postwoman
阅读文本大概需要 6 分钟. 1. 前言 大家都知道,Postman是一个非常受欢迎的API接口调试工具,提供有Chrome扩展插件版和独立的APP,不过它的很多高级功能都需要付费才能使用. 如果你连 ...
最新文章
- 为什么说OLAP产品毁了BI?
- 【C++】【TinyXml】xml文件的读写功能使用——写xml文件
- java飞鸽传书_feige 飞鸽传书源代码java 实现不错的联系网络编程的资料飞鸽传书的GUI(java实现) - 下载 - 搜珍网...
- 【C++ STL学习之四】容器list深入学习
- debian linux vnc,Debian 如何配置安装Xfce桌面+VNC远程桌面服务
- 在不停止mysql复制主服务器的情况下,配置一个mysql复制从服务器
- 基于mycat的mysql_基于Mycat中间件的MySQL读写分离
- 【算法】算法 动态规划 背包问题
- PHP Zend Studio9.0怎么把代码搞成和服务器端的同步(就是直接在服务器端修改)
- 深度学习分类只有正样本_自动调制分类:一种深度学习的方法
- matlab保存数据用什么指令_Matlab数据处理——数据的保存和读取方法操作
- Qt5.12 制作串口调试助手
- 51单片机入门——LCD1602
- 秒杀面试 - 程序员面试宝典
- 灵感之源之十多年技术人生的经验与心得
- 发电厂电气部分第三版pdf_“十三五”普通高等教育本科规划教材 发电厂电气设备及运行(第三版) pdf epub mobi txt 下载...
- 动态SQL execute immediate
- 解决引用微信公众号获取的图片不能正常显示的问题,显示改图片来自微信公众号
- 【C】狐狸找兔子问题
- 【收藏防丢】rar压缩包忘记密码怎么办?手把手教你轻松解决