【技术帖】Apache Kylin 高级设置:层级维度(Hierarchy Dimension)原理
 众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。
众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。
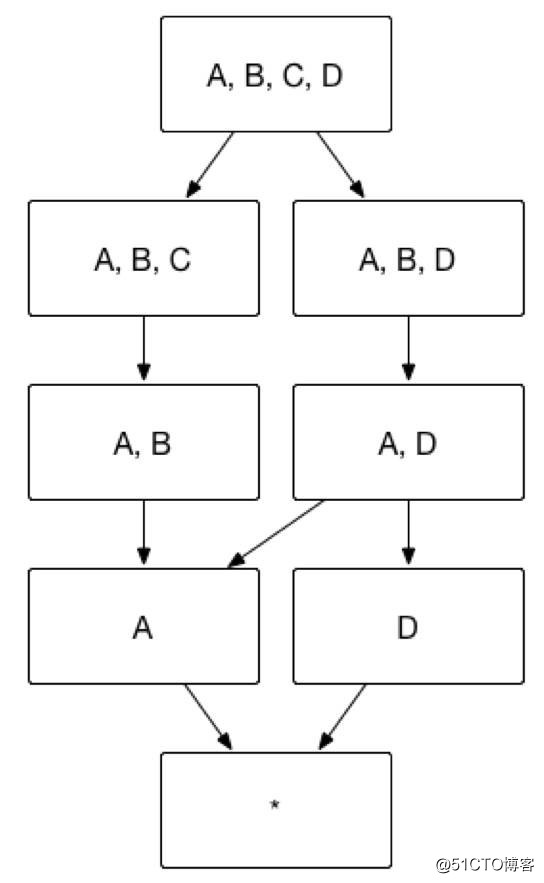
(图1)
随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierarchy Dimension)和必要维度(Mandatory Dimension)等。
本文将着重介绍层级维度(Hierarchy Dimension)的实现原理与适用的场景实例。
层级维度
用户选择的维度中常常会出现具有层级关系的维度。例如对于国家(country)、省份(province)和城市(city)这三个维度,从上而下来说国家/省份/城市之间分别是一对多的关系。也就是说,用户对于这三个维度的查询可以归类为以下三类:
group by country
group by country, province(等同于group by province)
- group by country, province, city(等同于 group by country, city 或者group by city)
以图 2 所示的 Cube 为例,假设维度 A 代表国家,维度 B 代表省份,维度 C 代表城市,那么ABC 三个维度可以被设置为层级维度,生成的Cube 如图 2 所示。
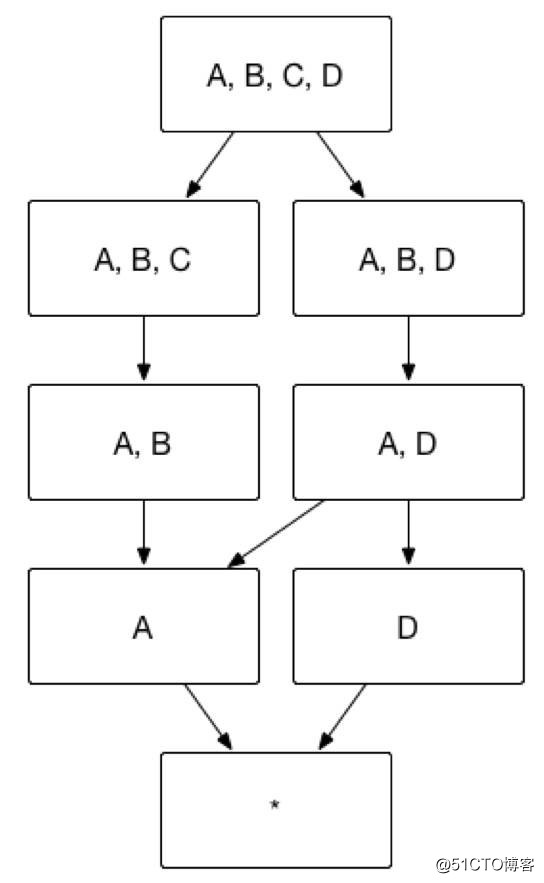
(图2)
例如,Cuboid [A,C,D]=Cuboid[A, B, C, D],Cuboid[B, D]=Cuboid[A, B, D],因而 Cuboid[A, C, D] 和 Cuboid[B, D] 就不必重复存储。
图 3 展示了 Kylin 按照前文的方法将冗余的Cuboid 剪枝从而形成图 2 的 Cube 结构,Cuboid 数目从 16 减小到 8。
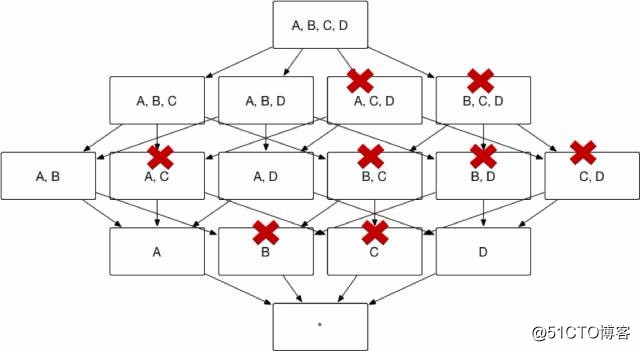
(图3)
应用实例
假设一个交易数据的 Cube,它具有很多普通的维度,像是交易的城市 city,交易的省 province,交易的国家 country, 和支付类型 pay_type等。分析师可以通过按照交易城市、交易省份、交易国家和支付类型来聚合,获取不同层级的地理位置消费者的支付偏好。在上述的实例中,建议在已有的聚合组中建立一组层级维度(国家country/省province/城市city),包含的维度和组合方式如图 4:
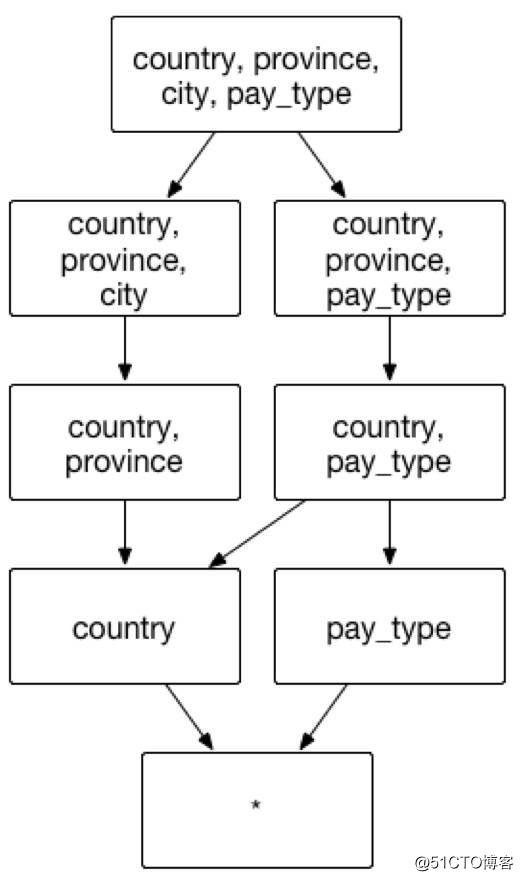
(图4)
聚合组:[country, province, city,pay_type]
层级维度: [country, province, city]
Case 1 当分析师想从城市维度获取消费偏好时:
SELECT city, pay_type, count(*) FROM table GROUP BY city, pay_type 则它将从 Cuboid [country, province, city, pay_type] 中获取数据。
Case 2 当分析师想从省级维度获取消费偏好时:
SELECT province, pay_type, count(*) FROM table GROUP BY province, pay_type则它将从Cuboid [country, province, pay_type] 中获取数据。
Case 3 当分析师想从国家维度获取消费偏好时:
SELECT country, pay_type, count(*) FROM table GROUP BY country, pay_type则它将从Cuboid [country, pay_type] 中获取数据。
Case 4 如果分析师想获取不同粒度地理维度的聚合结果时:
无一例外都可以由图 3 中的 cuboid 提供数据 。
例如,SELECT country, city, count(*) FROM table GROUP BY country, city 则它将从 Cuboid [country, province, city] 中获取数据。
转载于:https://blog.51cto.com/xiaolanlan/2068975
【技术帖】Apache Kylin 高级设置:层级维度(Hierarchy Dimension)原理相关推荐
- 【读书笔记】数据仓库- Apache Kylin权威指南
Apache Kylin权威指南(第2版) ◆ 1.2.1 为什么要使用Apache Kylin 它们的主要技术是"大规模并行处理"(Massively Parallel Proc ...
- Apache Kylin新手入门指南
Apache Kylin新手入门指南 文章目录 Apache Kylin新手入门指南 1 Apache Kylin是什么 2 为什么使用Apache Kylin 3 Apache Kylin的易用性如 ...
- 一文读懂Apache Kylin(麒麟)
"麒麟出没,必有祥瑞." -- 中国古谚语 Kylin思维导图 前言 随着移动互联网.物联网等技术的发展,近些年人类所积累的数据正在呈爆炸式的增长,大数据时代已经来临.但是海量数据 ...
- 一文读懂Apache Kylin
感谢分享. http://www.jianshu.com/p/abd5e90ab051?utm_campaign=maleskine&utm_content=note&utm_medi ...
- Apache Kylin
"麒麟出没,必有祥瑞." -- 中国古谚语 Kylin思维导图 前言 随着移动互联网.物联网等技术的发展,近些年人类所积累的数据正在呈爆炸式的增长,大数据时代已经来临.但是海量数据 ...
- Apache Kylin | 麒麟出没,必有祥瑞
点击上方蓝色字体,选择"设为星标" 回复"资源"获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! ...
- 易乐游无盘服务器网卡设置,技术帖 | 易乐游客户机网卡PNP设置
原标题:技术帖 | 易乐游客户机网卡PNP设置 关注易乐游(微信/头条/搜狐/一点),了解网吧行业最新动态. 该功能适用于无盘网吧,开启网卡PNP功能后,可以在网吧服务器上更新客户机网卡驱动和修改客户 ...
- 一篇文章搞懂 Apache Kylin 4.x 的技术架构
前言 本文隶属于专栏<1000个问题搞定大数据技术体系>,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和文献引用请见1000个问题搞定大数据技 ...
- Apache Kylin从入门到精通
Kylin 文章目录 Kylin 一.概述 1.1 Kylin定义 1.2 Kylin架构 1.3 Kylin特点 1.4 Apache Kylin4 概述 为什么选择 Parquet 替换 HBas ...
- 深入 Apache Kylin Cube 与查询优化
2019独角兽企业重金招聘Python工程师标准>>> 近几年,Apache Kylin作为一个高速的开源分布式大数据查询引擎正在迅速崛起.它充分发挥Hadoop.Spark.HBa ...
最新文章
- Cisco ××× 完全配置指南-连载-IPSec
- 用flood测试web服务器响应时间,用Flood测试Web服务器响应时间(1)
- 面向对象精要-理解对象
- 动态规划-重叠区间2020.3.30
- 网络爬虫--18.python中的GIL(全局解释器锁)、多线程、多进程、并发、并行
- (16)FPGA面试题MOORE 与 MEELEY状态机
- kettle优化抽取数据速度_基于kettle工具提高表输出写入速度(每秒万条记录)
- web 端 gantt组件选型
- 修改ranger ui的admin用户登录密码踩坑小记
- Makefile之eval与call用法
- 【SICP练习】142 练习3.77
- 英特尔® 实感™ SDK 架构
- LPC1788启动代码分析
- WebView复制粘贴文本
- 物联网——WIFI热点配网
- [leetcode] 179 Largest Number
- <机器学习>支持向量机(SVM)理论
- c语言程序设计形成性作业3,C语言程序设计形成性作业3-4..doc
- 什么是程序?如何构成?
- 《ZigBee开发笔记》第五部分 外设篇 - 基础实验 第5章 CC2530继电器模块