Apache Cassandra和Apache Ignite:关系并置和分布式SQL
为什么80%的码农都做不了架构师?>>> 
在上一篇文章中,回顾和总结了Cassandra中使用的查询驱动数据模型(或者说非常规数据模型)方法论的缺陷。事实证明,如果不对查询有深入的了解,通过该方法论将无法开发高效的应用。实际上,这种场景的应用架构上会变得更加的复杂,难于维护,并且会造成很大的数据冗余。
此外,这个问题通常会被这样的观点掩盖:“如果想要扩展性、速度以及高可用性,那么就得准备存储多份数据,并且牺牲SQL和强一致性。”,这个论调十年前可能是正确的,但是现在完全错误!
没那么夸张,我们选择了另一个ASF成员,Apache Ignite。在本文中,会讲解基于Ignite的应用架构,然后衡量它的维护成本。
我们选择的应用仍然是跟踪所有厂商生产的车辆,然后了解每个单一厂商的产能,如果看过第一篇文章,那么应该知道关系模型如下:
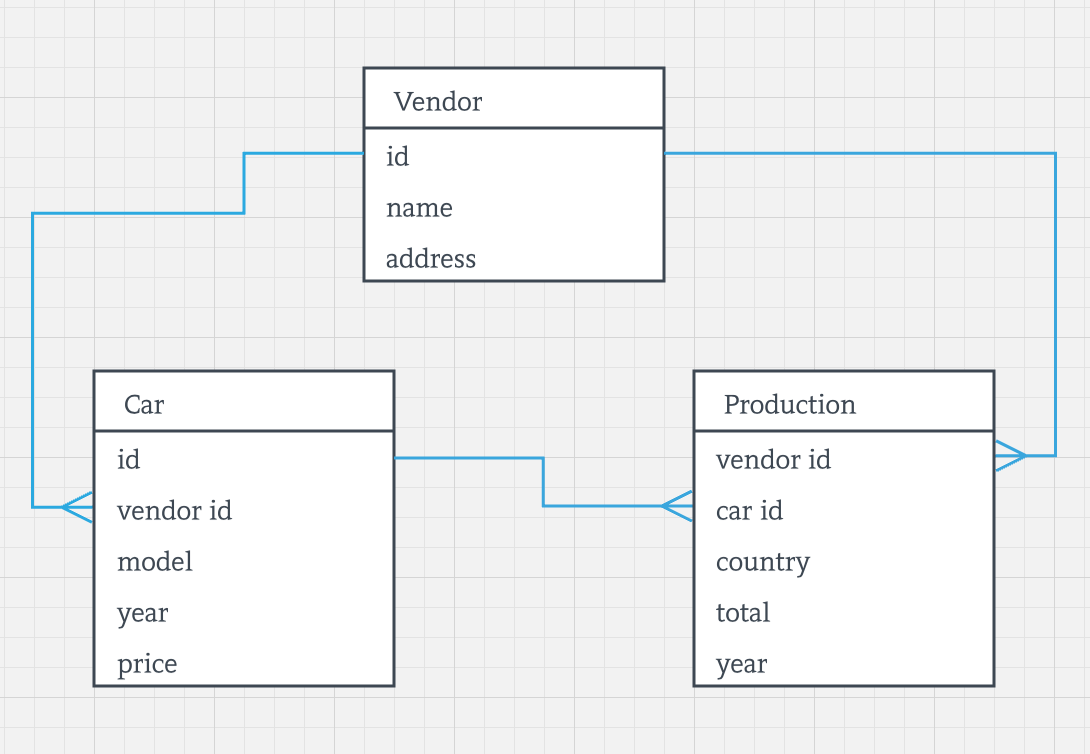
下一步,可以使用Ignite的CREATE TABLE命令创建这三个表,然后运行由SQL驱动的应用了么?不一定,如果不需要对存储于不同表中的数据进行关联操作,那么是可以的。但是根据前文,前提是应用需要支持两种关联的查询:
- Q1:获取一个厂商在特定的时间段内生产的车型。
- Q2:获取一个厂商特定车型的产量。
在Cassandra的案例中,我们为每个查询创建了一张表规避了关联的问题,那么用Ignite,是不是还要经历同样的过程?完全不用。事实上,Ignite的非并置的关联已经完全可用,如果三个表已经建好了,那么不需要什么额外的工作。但是,这没有比并置的高效和快速。因此,首先要多学习一下关系并置,然后了解这个概念在Ignite中是如何使用的。
基于并置关联的数据模型
关系并置在Ignite(还有其他的分布式数据库,比如Google Spanner以及MemSQL)中是一个强大的概念,它可以在以一个集群节点上存储相关的数据。那么哪些数据是相关的呢?尤其是在关系数据库的背景下,这非常简单,只需要在业务对象之间标示一个父子关系,在CREATE TABLE语句中指定一个关系键就可以了,剩下的就交给Ignite了!
还是拿车辆和厂商的应用举例,使用厂商作为父实体,车辆作为子实体是合理的。比如,按照这样配置好之后,某个厂商生产的所有车辆数据都会存储于同一个节点上,如下图所示:
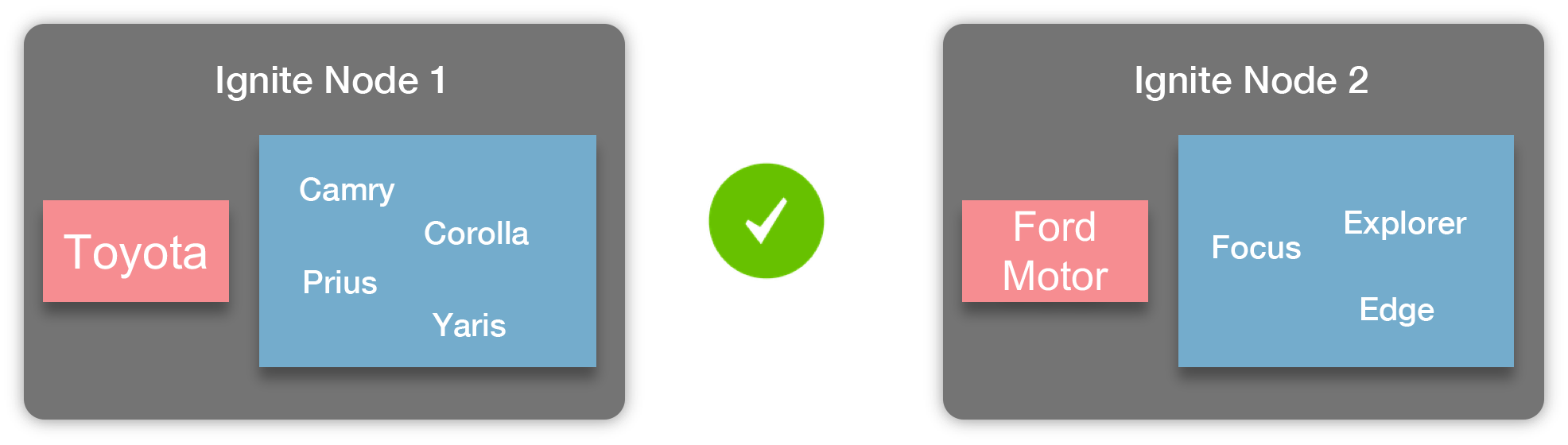
如图所示,丰田生产的车辆都存储于节点1,而福特生产的车辆都存储于节点2,这就是关系并置,车辆都会存储于对应的厂商所在的节点上。
要做到这样的数据分布,Vendor表的SQL定义如下:
CREATE TABLE Vendor (id INT PRIMARY KEY,name VARCHAR,address VARCHAR
);
厂商数据会在整个集群中随机地分布,Ignite会使用主键列计算厂商数据所在的节点。 下一个是Car表:
CREATE TABLE Car (id INT,vendor_id INT,model VARCHAR,year INT,price float,PRIMARY KEY(id, vendor_id)
) WITH "affinityKey=vendor_id";
车辆表有一个affinityKey参数,配置为vendor_id列,它告诉Ignite,车辆存储于vendor_id对应的集群节点。
在Production表上重复同样的过程,它的数据也是存储于vendor_id对应的集群节点上,如下:
CREATE TABLE Production (id INT,car_id INT,vendor_id INT,country VARCHAR,total INT,year INT,PRIMARY KEY(id, car_id, vendor_id)
) WITH "affinityKey=vendor_id";
这样数据模型就建完了,下一步就进入应用的代码,然后开发必要的查询。
带关联的SQL查询
Ignite集群可以使用我们熟悉的SQL进行查询,它支持分布式的SQL关联以及二级索引。 Ignite支持两种类型的关联:并置和非并置。假定要关联的表已经并置,并且本地数据全部可用,那么并置的关联会避免数据(关联所需的)的移动,这是在分布式数据库中效率最高、性能最好的。如果部分表无法实现关系并置,但是还需要进行关联,那么非并置的关联就是一个备份计划。这种类型的关联速度较慢,因为在关联时它需要在集群节点间进行数据的移动。
之前,已经配置好了Vendor、Car和Production表,下一步就是利用并置关联的优势,为Q1写一个SQL:
SELECT c.model, p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = 'Ford Motor' and p.year >= 2017
ORDER BY p.year;
还能更快么?当然能。下面为Vendor.name和Production.year列定义二级索引:
CREATE INDEX vendor_name_id ON Vendor (name);
CREATE INDEX prod_year_id ON Production (year);
针对Q2的查询也不需要额外的工作:
SELECT p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = 'Ford Motor' and c.model = 'Explorer';
现在,如果老板要求增加一个新特性时,很快就能构造出一套新的SQL满足他。 完成!作为比较,如果要支持Q2,可以看看基于Cassandra的架构是怎么搞的。
架构简化:任务完成!
Ignite的基于关系并置的数据模型,针对Cassandra的基于查询驱动的模型有如下的优点:
- 应用的数据层基于熟悉的关系模型进行建模,易于维护;
- 数据使用标准的SQL语法进行访问;
- 关系并置提供了现代分布式数据库的更多好处:
- 高效和高性能的分布式关联;
- 并置计算;
使用Ignite替代Cassandra,简化的软件架构并不是唯一的好处,过段时间,还会有关于强一致性和内存极性能方面的想法。
本文译自Denis Magda的博客。
转载于:https://my.oschina.net/liyuj/blog/1615008
Apache Cassandra和Apache Ignite:关系并置和分布式SQL相关推荐
- Apache Cassandra和Apache Ignite:分布式数据库的明智之选
为什么80%的码农都做不了架构师?>>> Apache Cassandra应用广泛,是一个开源的.分布式的.键值存储列模式NoSQL数据库,支撑了很多大公司的关键业务,比如Ne ...
- 使用Apache Storm和Apache Ignite进行复杂的事件处理(CEP)
在本文中, "使用Apache Ignite进行高性能内存计算"一书的作者将讨论使用Apache Strom和Apache Ignite进行复杂的事件处理. 本文的一部分摘自 书 ...
- Apache Cassandra简介
Apache Cassandra 是一个开源的.分布式.无中心.弹性可扩展.高可用.容错.一致性可调.面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable ...
- apache ignite_使用Apache Storm和Apache Ignite进行复杂事件处理(CEP)
apache ignite 在本文中, "使用Apache Ignite进行高性能内存计算"一书的作者将讨论使用Apache Strom和Apache Ignite进行复杂的事件处 ...
- 使用Apache Cassandra设置SpringData项目
在这篇文章中,我们将使用Gradle和spring boot来创建一个集成spring-mvc和Apache Cassandra数据库的项目. 首先,我们将从Gradle配置开始 group 'com ...
- 使用Apache Cassandra设置一个SpringData项目
在这篇文章中,我们将使用Gradle和spring boot来创建一个将spring-mvc和Apache Cassandra数据库集成在一起的项目. 首先,我们将从Gradle配置开始 group ...
- Apache Cassandra和低延迟应用程序
介绍 多年来, Grid Dynamics拥有许多与NoSQL相关的项目,尤其是Apache Cassandra. 在这篇文章中,我们要讨论一个给我们带来挑战的项目,而我们在该项目中试图回答的问题今天 ...
- Apache Cassandra和Java入门(第一部分)
在此页面上,您将学到足够的知识来开始使用NoSQL Apache Cassandra和Java,包括如何安装,尝试一些基本命令以及下一步做什么. 要求 要遵循本教程,您应该已经有一个正在运行的Cass ...
- Apache Cassandra和Java入门(第二部分)
要求 要遵循本教程,您应该已经有一个正在运行的Cassandra实例( 一个小型集群会很好 ,但不是必需的),已安装Datastax Java驱动程序( 请参阅第I部分 ),并且已经在这里进行了10分 ...
最新文章
- 如何具体学习计算机视觉
- 我们都是和自己赛跑的人
- python内置函数用来返回_Python内置函数用法
- linux php运行用户名和密码,Linux实例(一)使用用户名密码验证连接Linux
- python测试框架untest怎么循环执行_unittest如何在循环遍历一条用例时生成多个测试结果...
- 怎么样把c语言转变为汇编语言,如何把汇编语言转换成C语言
- 利刃 MVVMLight 2:Model、View、ViewModel结构以及全局视图模型注入器的说明
- 关于近段时间不更新博客的借口
- python中ta_非常详细的Ta-Lib安装及使用教程
- shell oracle 多进程,Shell多进程实现
- BFS java实现,java实现dfs及bfs算法
- Java实战---搜搜移动业务大厅
- Multi-armed Bandits(多臂老虎机问题)
- 2112731-59-4,N-(Azido-PEG2)-N-Biotin-PEG3-acid末端羧酸可在活化剂(例如EDC或HATU)存在下与伯氨基反应
- HTML5酷炫动画集锦
- 如何让360浏览器打开网页默认为“极速模式”
- java下载文件时文件名中文乱码
- 介绍Mybatis与使用(什么是Mybatis?)
- 跟班学习JavaScript第二天———流程控制、分支、循环、函数
- excel表如何汇总统计平均值