小猪的Python学习之旅 —— 15.浅尝Python数据分析
小猪的Python学习之旅 —— 15.浅尝Python数据分析:分析2018政府工作报告中的高频词
标签:Python
一句话概括本文:
爬取2018政府工作报告,通过jieba库进行分词后做词频统计,
最后使用 wordcloud 库制作naive词云,非常有意思~
引言:
昨晚写完上一篇把爬取到的数据写入到Excel后,在回家的路上我就盘算着
折腾点有趣的东西玩玩——简单的数据分析:分词,统计词频,然后做成词云;
分析点什么玩玩好呢?想起以前看到过一个梗,有人把汪峰唱过的歌的歌词做
词频统计,然后自嗨作词了一首汪峰Style的歌,2333,本来早上想弄的,
发现处理起来有些麻烦,歌词源考虑了下爬虾米音乐,但是有些歌词不规范,
这个多点什么,那个少点什么,处理起来挺麻烦的,就放弃了,后面在
看文章的时候发现了一个有点意思的例子:
Python文本分析:2016年政府工作报告有哪些高频词?
3月5日不是刚召开完第十三届全国人民代表大会吗?会后发布了:
2018政府工作报告,作为一个积极爱国分子,写个Python脚本来分析
分析高频词,弄个词云学习学习,岂不美哉~开始本节内容!

1.数据准备
百度随手搜下关键字,2018政府工作报告,随手翻开一个:
2018政府工作报告全文(推荐收藏):http://news.ifeng.com/a/20180305/56472392_0.shtml
这种就非常简单了,直接Element看所需的数据节点:

div包着一堆p标签,拿到p标签里的text就可以了,这里过滤掉最后一个来源:新华社
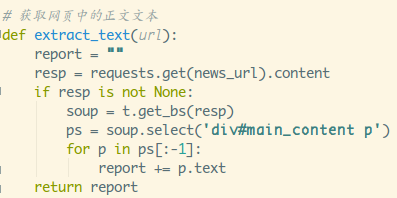
可以加个print把text打出来:

没错是想要的数据,在做分词前,通过正则把各种乱七八糟的
标点符号还有数字都替换掉:
punctuation_pattern = re.compile('[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?“”、~@#¥%……&*()(\d+)]+')
result = punctuation_pattern.sub("", extract_text(news_url))
print(result)替换结果:

到此,用作分词的字符串就准备好了~
2.分词与词频统计
因为我们的数据都是中文的,这里选用号称:
做最好的 Python 中文分词组件 的 jieba库
- Github仓库:https://github.com/fxsjy/jieba
- 官方文档:https://pypi.python.org/pypi/jieba/
- Python中文分词 jieba 十五分钟入门与进阶:http://blog.csdn.net/fontthrone/article/details/72782499
pip命令行安装一波库:
pip install jieba使用方法也很简单:

cut方法参数:(分词的字符串,cut_all是否打开全模式),全模式的意思
就是会这样匹配,比如:大傻逼,会分词成:大傻,傻逼和大傻逼
另外这里还做了下判断,长度大于等于2才算一个词。运行下把分词
后数组遍历下,可以,没毛病。
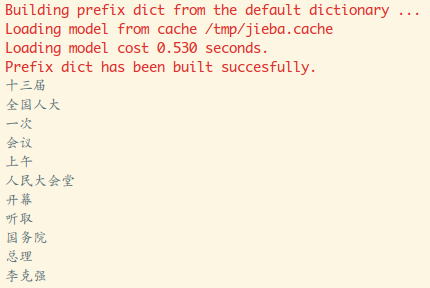
接着就到同此词频了,这里的统计的话分两个选项吧,
你看你是要统计词出现的频次,还是出现的频率,这里就先统计下
频次吧,就是词出现的次数,看到网上的套路都是通过:
collections模块的Counter类来实现的,Counter是一个无序的容器
类型,以字典的键值对形式存储,元素为key,计数为value,一般
用来跟踪值出现的次数。

PS:括号里的50代表取次数最多的前50个~
输出结果:

频次拿到了,但是有个问题,我们发现有一些关键词是没什么意义
的,比如推进,提高等等动词,我们需要对数据进行过滤(貌似有
个专业名词叫:数据清洗),最简单的就是定义一个过滤列表,
把想过滤的词都丢进去,分词后遍历一波,把在过滤列表中存在
的元素进行移除:

运行结果:

可以,意义不大的关键词都过滤掉了,关于统计频次目前只知道
这个套路,有其他高大上的套路的欢迎在评论区留言告知~
接着就是频率统计,就是出现的百分比,这个可以知己
通过jieba库里的analyse模块解决,这个东西支持停用词
文件过滤,就是把不想要的分词都丢一个文件里,分词时会
自动过滤,调用的函数是:extract_tags
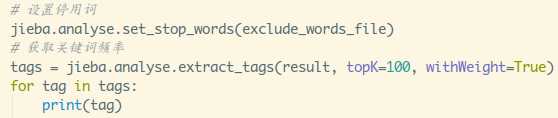
运行结果:

参数topK代表提取多少个,withWeight是否带有频率(权重),
另外可能你对停用词文件比较好奇,其实内容非常简单:

分词与词频问题就已经解决了,接下来搞词云了。
3.生成词云
网上搜词云的库基本都用的wordcloud这个库,就直接拿这个开刀吧!
- Github仓库:https://github.com/amueller/word_cloud
- 官方博客:https://amueller.github.io/word_cloud/
- Python词云 wordcloud 十五分钟入门与进阶:
http://blog.csdn.net/fontthrone/article/details/72775865
pip命令行安装一波库:
pip install wordcloud用这个库最关键的就是WordCloud构造函数:

参数详解:
- font_path:字体路径,就是绘制词云用的字体,比如monaco.ttf
- width:输出的画布宽度,默认400像素
- height:输出的画布宽度,默认200像素
- margin:画布偏移,默认2像素
- prefer_horizontal : 词语水平方向排版出现的频率,默认0.9,垂直方向出现概率0.1
- mask:如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将
被忽略,遮罩形状被 mask,除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。
如:bg_pic = imread(‘读取一张图片.png’),背景图片的画布一定要设置为白色(#FFFFFF),
然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色
的画布上再保存,就ok了。- scale:按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍
- color_func:生成新颜色的函数,如果为空,则使用 self.color_func
- max_words:显示的词的最大个数
- min_font_size:显示的最小字体大小
- stopwords:需要屏蔽的词(字符串集合),为空使用内置STOPWORDS
- random_state:如果给出了一个随机对象,用作生成一个随机数
- background_color:背景颜色,默认为黑色
- max_font_size:显示的最大的字体大小
- font_step:字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差
- mode:当参数为”RGBA”,并且background_color不为空时,背景为透明。默认RGB
- relative_scaling:词频和字体大小的关联性,默认5
- regexp:使用正则表达式分隔输入的文本
- collocations:是否包括两个词的搭配
- colormap:给每个单词随机分配颜色,若指定color_func,则忽略该方法
- normalize_plurals:是否删除尾随的词语
常用的几个方法:
- fit_words(frequencies) //根据词频生成词云
- generate(text) //根据文本生成词云
- generate_from_frequencies(frequencies[, …]) #根据词频生成词云
- generate_from_text(text) #根据文本生成词云
- process_text(text) #将长文本分词并去除屏蔽词
(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies) )- recolor([random_state, color_func, colormap]) #对现有输出重新着色。重新上色会比重新生成整个词云快很多。
- to_array() #转化为 numpy array
- to_file(filename) #输出到文件
看得我真是一脸懵逼,直接写个最简单的例子,帮助我们上手~

调用下这个方法,把我们前面的分词后的数组传进去:

输出结果:

可以,非常有意思,此时此刻,突然:

官方可以的是这样的例子:

啧啧,Too young,too simple!
先找一个膜法师专用图,然后改一波代码(没有原图,别问我):

执行下(真正的粉丝…):

这个字体是随机颜色的,感觉还差点什么,不如让字体跟随
着图片的颜色?可能会感受更深刻一些!获取一波颜色数组,
设置下就可以了:
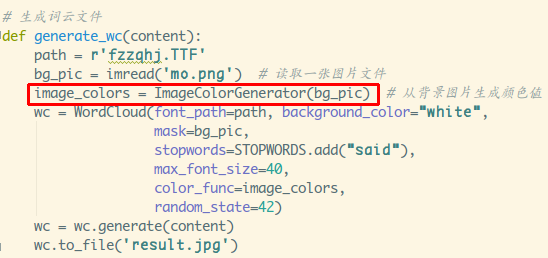
执行下:

真别问我要原图,没有,另外上面用到一个scipy库,用来获取一个颜色矩阵的,
官方示例里还用到了另外的一个库:matplotlib 一个很屌的可视化绘图模块。
本来想试试的,不过快下班了,下次吧~

小结
本节试了一波Python里的数据分析,讲真,老早之前就想试试这个
东西了,通过大量的数据分析得出一些结论,比如抓取某个心仪
同事妹子朋友圈里或者微博里的所有信息,做下词频统计分析,
可以大概猜测这个人的兴趣爱好,又比如抓取某个商品的所有
评论,分析下词频,可以得到购买者们对此商品的客观评价
(刷单是存在的,只能说作为一个参考依据),又比如最近是
招聘的金三银四,HR每天都要过滤一堆简历,ORC识别后,分词
统计出,过滤工作年限,是否有项目经验等,设置一个匹配度
的机制,筛选掉匹配度不足多少的简历。(只是脑洞…)
Python是真的好玩!最后说一句,我只是一个跑得快的香港
接着,并不想搞个大新闻,naive!

附:最终代码(都可以在:https://github.com/coder-pig/ReptileSomething 找到):
# 分析2018政府工作报告全文高频词
import jieba
import jieba.analyse
import requests
import tools as t
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from collections import Counter
import matplotlib.pyplot as plt
from scipy.misc import imreadnews_url = "http://news.ifeng.com/a/20180305/56472392_0.shtml"
# 过滤掉所有中文和英文标点字符,数字
punctuation_pattern = re.compile('[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?“”、~@#¥%……&*()(\d+)]+')
exclude_words_file = "exclude_words.txt"# 获取网页中的正文文本
def extract_text(url):report = ""resp = requests.get(news_url).contentif resp is not None:soup = t.get_bs(resp)ps = soup.select('div#main_content p')for p in ps[:-1]:report += p.textreturn report# 生成词云文件
def generate_wc(content):path = r'fzzqhj.TTF'bg_pic = imread('mo.png') # 读取一张图片文件image_colors = ImageColorGenerator(bg_pic) # 从背景图片生成颜色值wc = WordCloud(font_path=path, background_color="white",mask=bg_pic,stopwords=STOPWORDS.add("said"),max_font_size=40,color_func=image_colors,random_state=42)wc = wc.generate(content)wc.to_file('result.jpg')if __name__ == '__main__':result = punctuation_pattern.sub("", extract_text(news_url))words = [word for word in jieba.cut(result, cut_all=False) if len(word) >= 2]# # 设置停用词# jieba.analyse.set_stop_words(exclude_words_file)# # 获取关键词频率# tags = jieba.analyse.extract_tags(result, topK=100, withWeight=True)# for tag in tags:# print(tag[0] + "~" + str(tag[1]))exclude_words = ["中国", "推进", "全面", "提高", "工作", "坚持", "推动","支持", "促进", "实施", "加快", "增加", "实现", "基本","重大", "我国", "我们", "扩大", "继续", "优化", "加大","今年", "地方", "取得", "以上", "供给", "坚决", "力度","着力", "深入", "积极", "解决", "降低", "维护", "问题","保持", "万亿元", "改善", "做好", "代表", "合理"]for word in words:if word in exclude_words:words.remove(word)data = r' '.join(words)generate_wc(data)# c = Counter(words)# for word_freq in c.most_common(50):# word, freq = word_freq# print(word, freq)
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

小猪的Python学习之旅 —— 15.浅尝Python数据分析相关推荐
- 小猪的Python学习之旅 —— 15.浅尝Python数据分析:分析2018政府工作报告中的高频词...
一句话概括本文: 爬取2018政府工作报告,通过**jieba**库进行分词后做词频统计, 最后使用 wordcloud 库制作naive词云,非常有意思- 引言: 昨晚写完上一篇把爬取到的数据写入到 ...
- Python学习之旅-15
关于列表,元组,字典的小练习 元素分类 有如下值集合 [11,22,33,44,55,66,77,88,99,90-],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个 ...
- 小猪的Python学习之旅 —— 16.采集拉勾网数据分析Android就业行情
小猪的Python学习之旅 -- 16.再尝Python数据分析:采集拉勾网数据分析Android就业行情 标签:Python 一句话概括本文: 爬取拉钩Android职位相关数据,利用numpy,p ...
- 小猪的Python学习之旅 —— 1.基础知识储备
小猪的Python学习之旅 -- 1.基础知识储备 引言: (文章比较长,建议看目录按需学习-) 以前刚学编程的时候就对Python略有耳闻,不过学校只有C,C++,Java,C#. 和PHP有句&q ...
- 小猪的Python学习之旅 —— 10.三分钟上手Requests库
小猪的Python学习之旅 -- 10.三分钟上手Requests库 标签:Python 一句话概括本文: 本节讲解Requests库的常见使用,以及一个实战项目: 扒取某一篇微信文章里所有的图片,视 ...
- 小猪的Python学习之旅 —— 17.Python数据分析:我主良缘交友了解下
小猪的Python学习之旅 -- 17.Python数据分析:我主良缘交友了解下 标签:Python 一句话概括本文: 爬取我主良缘交友所有的妹子信息,利用Jupyter Notebook对五个方面: ...
- 小猪的Python学习之旅 —— 6.捋一捋Python线程概念
小猪的Python学习之旅 -- 6.捋一捋Python线程概念 标签: Python 引言 从刚开始学习Python爬虫的时候,就一直惦记着多线程这个东西, 想想每次下载图片都是单线程,一个下完继续 ...
- 小猪的Python学习之旅 —— 20.抓取Gank.io所有数据存储到MySQL中
小猪的Python学习之旅 -- 20.抓取Gank.io所有数据存储到MySQL中 标签:Python 一句话概括本文: 内容较多,建议先mark后看,讲解了一波MySQL安装,基本操作,语法速成, ...
- 小猪的Python学习之旅 —— 19.Python微信自动好友验证,自动回复,发送群聊链接
小猪的Python学习之旅 -- 19.Python微信自动好友验证,自动回复,发送群聊链接 标签:Python 一句话概括本文: 上一节利用itchat这个库,做了小宇宙早报的监测与转发, 本节新增 ...
最新文章
- git 版本操作命令大全
- 怎么操作会导致MySQL锁表
- BZOJ 1014 火星人prefix
- jsp java 分离,java与jsp页面的字符串拼接和拆分
- VMware vCenter Converter:将物理机转换为虚拟机
- Kubernetes详解(八)——Kubernetes资源配置清单
- 公司部分断电,这些人就没法干活?
- 绝美中国建筑!为中国摄影师鼓掌!
- Win7下安装DirectShow
- 电脑启动盘引导丢失怎么办
- 滴滴二面:Kafka是如何读写副本消息的?
- 大道至简:透过现象看本质
- 行测-判断推理-图形推理-样式规律-黑白运算
- python bp神经网络的库_python bp神经网络库
- 基于java体育竞赛成绩管理系统(Java毕业设计)
- sqlserver字符串转日期
- ping请求超时问题研究
- 以太坊:快速入门 Truffle
- Unity 如何实现苹果动态模糊遮罩
- hfs支持php文件系统,HFS+文件系统的发展及特点介绍