机器学习算法优缺点_用于机器学习的优化算法的优缺点
机器学习算法优缺点
A deep-dive into Gradient Descent and other optimization algorithms
深入研究梯度下降和其他优化算法
Optimization Algorithms for machine learning are often used as a black box. We will study some popular algorithms and try to understand the circumstances under which they perform the best.
机器学习的优化算法通常被用作黑匣子。 我们将研究一些流行的算法,并尝试了解它们在何种情况下表现最佳。
该博客的目的是: (The purpose of this blog is to:)
Understand Gradient descent and its variants, such as Momentum, Adagrad, RMSProp, NAG, and Adam;
了解梯度下降及其变体,例如动量,Adagrad,RMSProp,NAG和Adam。
- Introduce techniques to improve the performance of Gradient descent; and引入技术以改善梯度下降的性能; 和
- Summarize the advantages and disadvantages of various optimization techniques.总结了各种优化技术的优缺点。
Hopefully, by the end of this read, you will find yourself equipped with intuitions towards the behavior of different algorithms, and when to use them.
希望在阅读本文结束时,您会发现自己对不同算法的行为以及何时使用它们具有直觉。
梯度下降 (Gradient descent)
Gradient descent is a way to minimize an objective function J(w),by updating parameters(w) in opposite direction of the gradient of the objective function. The learning rate η determines the size of the steps that we take to reach a minimum value of objective function.
梯度下降是一种通过在目标函数梯度的相反方向上更新参数(w)来最小化目标函数J(w)的方法。 学习率η决定了达到目标函数最小值的步长。
Advantages and Disadvantages of Gradient Descent:
梯度下降的优点和缺点:
Overall Drawbacks of Gradient Descent:
梯度下降的总体缺点:

Techniques to improve the performance of Gradient Descent:
改善梯度下降性能的技术:

梯度下降的变化 (Variations of Gradient Descent)
- Momentum动量
- Nesterov Accelerated GradientNesterov加速梯度
- Adagrad阿达格勒
- Adadelta/RMSPropAdadelta / RMSProp
- Adam亚当
动量 (Momentum)
SGD (Stochastic Gradient Descent)has trouble navigating areas where the surface of optimization function curves much more steeply into one dimension than in another.
SGD(随机梯度下降)在导航区域中存在麻烦,在这些区域中,优化功能的曲面向一维弯曲的幅度比向一维弯曲的幅度大得多。
Momentum is a method that helps to accelerate SGD in the relevant direction, and dampens oscillations as can be seen below. It does this by adding a fraction using γ. γ is based on the principle of exponentially weighed averages, where weights are not drastically impacted by a single data point.
动量是一种有助于在相关方向上加速SGD并抑制振荡的方法,如下所示。 通过使用γ加一个分数来实现。 γ基于指数加权平均值的原理,其中权重不受单个数据点的影响很大。
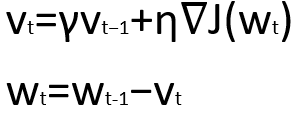
The momentum term increases in dimensions whose gradient continues in the same direction, and reduces updates for dimensions whose gradients change directions. As a result, we get faster convergence and reduced oscillation.
动量项增加了其梯度在相同方向上连续的尺寸,并减少了其梯度改变方向的尺寸的更新。 结果,我们获得了更快的收敛速度并减少了振荡。
Nesterov加速梯度(NAG) (Nesterov accelerated gradient(NAG))
Nesterov accelerated gradient (NAG) is a way to give momentum more precision.
Nesterov加速梯度(NAG)是提高动量精度的一种方法。
We will use momentum to move the parameters. However, computing our parameters as shown below, gives us an approximation of the the gradient at the next position. We can now effectively look ahead by calculating the gradient not w.r.t. to our current value of the parameters but w.r.t. the approximate future value of the parameters.
我们将使用动量来移动参数。 但是,如下所示计算参数,可以得出下一个位置处的梯度的近似值。 现在,我们可以通过计算梯度(而不是参数的当前值),而是计算参数的近似未来值,来有效地向前看。
The momentum term will make appropriate corrections and not overreach.
动量项将进行适当的更正,而不是超出范围。
- In case future slope is steeper, momentum will speed up.如果未来的坡度更陡,动量将加快。
- In case future slope is low, momentum will slow down.如果未来的坡度较低,动量将减慢。
阿达格勒 (Adagrad)
The motivation behind Adagrad is to have different learning rates for each neuron of each hidden layer for each iteration.
Adagrad背后的动机是, 对于每次迭代,每个隐藏层的每个神经元都有不同的学习率 。
But why do we need different learning rates?
但是为什么我们需要不同的学习率?
Data sets have two types of features:
数据集具有两种类型的功能:
Dense features, e.g. House Price Data set (Large number of non-zero valued features), where we should perform smaller updates on such features; and
密集特征,例如房屋价格数据集(大量非零值特征),我们应该在其中进行较小的更新; 和
Sparse Features, e.g. Bag of words (Large number of zero valued features), where we should perform larger updates on such features.
稀疏特征 ,例如单词袋(大量零值特征),我们应该在其中进行较大的更新。
It has been found that Adagrad greatly improved the robustness of SGD, and is used for training large-scale neural nets at Google.
已经发现,Adagrad大大提高了SGD的鲁棒性,并在Google上用于训练大规模神经网络。


- η : initial Learning rateη:初始学习率
- ϵ : smoothing term that avoids division by zeroϵ:避免被零除的平滑项
- w: Weight of parametersw:参数权重
As the number of iterations increases, α increases. As α increases, learning rate at each time step decreases.
随着迭代次数的增加,α增加。 随着α的增加,每个时间步的学习率都会降低。
One of Adagrad’s main benefits is that it eliminates the need to manually tune the learning rate. Most implementations use a default value of 0.01 and leave it at that.
Adagrad的主要好处之一是,它无需手动调整学习速度。 大多数实现使用默认值0.01并保留该默认值。
Adagrad’s weakness is its accumulation of the squared gradients in the denominator. Since every added term is positive, the accumulated sum keeps growing during training. This in turn causes the learning rate to shrink and eventually become infinitesimally small, at which point the algorithm is no longer able to acquire additional knowledge. The next optimization algorithms aim to resolve this flaw.
阿达格勒(Adagrad)的弱点是它在分母中积累了平方梯度。 由于每个增加的项都是正数,因此在训练期间累积的总和会不断增长。 反过来,这导致学习率下降,并最终变得无限小,这时算法不再能够获取其他知识。 下一个优化算法旨在解决这一缺陷。
Adadelta / RMSProp (Adadelta/RMSProp)
Adadelta/RMSProp are very similar in their implementation and they overcome the shortcomings of Adagrad’s accumulated gradient by using exponentially weighted moving average gradients.
Adadelta / RMSProp在实现上非常相似,它们通过使用指数加权移动平均梯度来克服Adagrad累积梯度的缺点。

Instead of inefficiently storing all previous squared gradients, we recursively define a decaying average of all past squared gradients. The running average at each time step then depends (as a fraction γ , similarly to the Momentum term) only on the previous average and the current gradient.
代替无效地存储所有先前的平方梯度,我们递归地定义所有过去平方梯度的衰减平均值。 然后,每个时间步长的移动平均值仅取决于先前的平均值和当前梯度(类似于动量项,为分数γ)。
Any new input data points do not dramatically change the gradients, and will hence converge to the local minima with a smoother and shorter path.
任何新的输入数据点都不会显着改变梯度,因此将以更平滑,更短的路径收敛到局部最小值。
亚当 (Adam)
Adam optimizer is highly versatile, and works in a large number of scenarios. It takes the best of RMS-Prop and momentum, and combines them together.
Adam优化器具有高度的通用性,可以在多种情况下使用。 它充分利用了RMS-Prop和动量,并将它们结合在一起。
Whereas momentum can be seen as a ball running down a slope, Adam behaves like a heavy ball with friction, which thus prefers flat minima in the error surface.
动量可以看成是一个顺着斜坡滑下的球,而亚当的举动就像是一个带有摩擦的沉重的球,因此,它更喜欢在误差表面上保持平坦的最小值。
As it can be anticipated, Adam accelerates and decelerates thanks to the component associated to momentum. At the same time, Adam keeps its learning rate adaptive which can be attributed to the component associated to RMS-Prop.
可以预见,由于动量相关的分量,亚当加速和减速。 同时,Adam保持其学习率自适应,这可以归因于与RMS-Prop相关的组件。
Default values of 0.9 for β1 is 0.999 for β2 is , and 10pow(-8) for ϵ. Empirically, Adam works well in practice and compares favorably to other adaptive learning-method algorithms.
β1的默认值为0.9,β2的默认值为0.999,ϵ的默认值为10pow(-8)。 根据经验,Adam在实践中表现良好,并且可以与其他自适应学习方法算法相比。
讨论的优化算法摘要 (Summary of Optimization Algorithms discussed)
Happy Coding !!
快乐编码!
翻译自: https://medium.com/swlh/strengths-and-weaknesses-of-optimization-algorithms-used-for-machine-learning-58926b1d69dd
机器学习算法优缺点
http://www.taodudu.cc/news/show-2910957.html
相关文章:
- 【互联网人的英语】到底要不要学语法?什么时候学比较好?
- 英语六级(词组、同义替换)
- 英语--副词描述变化量大小
- 企业级计算机储存容量,家用NAS与企业级NAS功能大比拼
- 虚拟机可以做成存储服务器吗,利用win10自带虚拟机功能轻松打造家用nas
- 家用NAS配置方案
- 个人家用nas_家庭私有云盘系列教程-本地搭建家庭NAS方案
- 树莓派家用NAS解决方案
- 使用树莓派搭建家用 NAS
- Ubuntu打造家用NAS二——服务器管理
- 巴法络nas硬盘挂linux,教你轻松DIY——巴法络家用NAS使用详解
- NAS实现家用服务器
- 家用nas装linux和windows,你会用 NAS 给 PC 装系统吗?
- win10 nas搭建_零起步自建家用NAS
- 群晖家用NAS选购心得
- 文件管理nas php,家用nas安装配置可道云进行文件管理
- 家用NAS上安装Domino
- 个人家用nas_方便易用的家用NAS私家云不超千元
- diy nas配置推荐2019_Server2019+htpc+NAS搭建家庭数据中心+远程唤醒开关机+晒晒桌面...
- 树莓派制作家用服务器,树莓派搭建家用小型NAS服务器
- 个人家用nas_希捷个人云评测:家用NAS中的佼佼者
- diy nas配置推荐2019_打造家用NAS之一(2019年版)
- 资源字典
- app怎么调用mysql数据_教你如何拿别人APP中的数据
- android 英汉字典,英汉全文字典安卓版
- POWER DESIGNER导出数据字典
- Kali之Crunch:自定义字典
- 牛津英语字典pdf下载_从1到18岁,这款牛津认证的免费APP是学英语最好的装备
- python制作英语字典_Python爬虫之自制英汉字典
- 中英文字典树
机器学习算法优缺点_用于机器学习的优化算法的优缺点相关推荐
- 算法函数_关于损失函数和优化算法,看这一篇就够了
在进行神经网络训练时,很多同学都不太注重损失函数图和损失函数的优化算法的理解,造成的结果就是:看起来效果不错,但是不知道训练的参数是否合理,也不知道有没有进一步优化的空间,也不知道初始点的选择是否恰当 ...
- 智能优化算法1-冠状病毒群免疫优化算法(CHIO)
智能优化算法1-冠状病毒群免疫优化算法(CHIO) 1.算法简介 2020年Mohammed Azmi Al-Betar等人提出的一种新的基于自然的优化算法--冠状病毒群体免疫优化算法(CHIO).其 ...
- 粒子群优化算法及其离散二进制粒子群优化算法总结
粒子群优化算法及其离散二进制粒子群优化算法总结 文章目录 粒子群优化算法及其离散二进制粒子群优化算法总结 前言 一.什么是粒子群优化算法? 二.粒子群算法基本形式 标准粒子群算法 粒子群拓扑结构 离散 ...
- 【优化算法】改进的侏儒猫鼬优化算法(IDMO)【含Matlab源码 2314期】
⛄一.获取代码方式 获取代码方式1: 完整代码已上传我的资源:[优化算法]改进的侏儒猫鼬优化算法(IDMO)[含Matlab源码 2314期] 点击上面蓝色字体,直接付费下载,即可. 获取代码方式2: ...
- 多目标优化算法:多目标袋獾优化算法MOTDO(提供MATLAB代码)
一.袋獾优化算法TDO 1.1算法简介 袋獾优化算法(Tasmanian Devil Optimization,TDO)由MOHAMMAD DEHGHANI等人于2022年提出,该算法模拟了自然界中袋 ...
- 【优化算法】基于matlab象鼻虫损害优化算法 (WDOA)【含Matlab源码 2228期】
⛄一.获取代码方式 获取代码方式1: 完整代码已上传我的资源:[优化算法]基于matlab象鼻虫损害优化算法 (WDOA)[含Matlab源码 2228期] 点击上面蓝色字体,直接付费下载,即可. 获 ...
- 多目标优化算法:多目标人工兔优化算法(Multi-Objective Artificial Rabbits Optimization ,MOARO)
一.人工兔优化算法算法简介 人工兔优化算法(Artificial Rabbits Optimization ,ARO)由Liying Wang等人于2022年提出,该算法模拟了兔子的生存策略,包括绕道 ...
- 机器学习、深度学习中常用的优化算法详解——梯度下降法、牛顿法、共轭梯度法
一.梯度下降法 1.总述: 在机器学习中,基于基本的梯度下降法发展了三种梯度下降方法,分别为随机梯度下降法,批量梯度下降法以及小批量梯度下降法. (1)批量梯度下降法(Batch Gradient D ...
- 机器学习经典算法实践_服务机器学习算法的系统设计-不同环境下管道的最佳实践
机器学习经典算法实践 "Eureka"! While working on a persistently difficult-to-solve problem, you disco ...
最新文章
- 2021年大数据Spark(四十一):SparkStreaming实战案例六 自定义输出 foreachRDD
- EntityCURD操作的参数和返回值
- 计算机一直在启动修复怎么关机,电脑开机一直要启动修复,自动修复好久开不了机,然后进去系统恢复选?...
- 美国人工智能就业市场全景:开放职位512个,基本工资最高26万美元
- JAVA实现环形缓冲多线程读取远程文件
- 修复Linux系统内核TCP漏洞,修复Linux TCP SACK PANIC 远程拒绝服务漏洞
- 第k短路 (A*算法)
- 基因表达式编程gep_基因表达式编程GEP— 前言
- 记一次线上服务假死排查过程
- 有关javabean的说法不正确的是_关于 JavaBean, 下列叙述中不正确的是 ( ) 。_学小易找答案...
- 基于百度地图API的微信周边搜索
- FD.io VPP:CentOS7下构建自己的VPP RPM包
- android flag,Android 屏幕锁 - FLAG_KEEP_SCREEN_ON
- armv6, armv7, armv7s, arm64 的区别
- 硬盘格式化后数据还可以恢复吗?格式化硬盘的恢复方法
- 看云|专注于文档在线创作、协作、分享和托管
- IG赢了,让我们先理直气壮的喊出那句 我们是冠军!
- Ac4GlcNAz,98924-81-3,N-乙酰葡糖胺叠氮基,可以进行糖化学修饰
- 跟小博老师一起学JSP ——通信作用域
- 第一个发布成功的UI组件库