segfault at xxx rip xxx rsp xxx error 4(合并整理)
通过 sudo cat /var/log/messages |grep segfault 或者 sudo dmesg|grep segfault 获得
这种信息一般都是由内存访问越界造成的,不管是用户态程序还是内核态程序访问越界都会出core, 并在系统日志里面输出一条这样的信息。这条信息的前面分别是访问越界的程序名,进程ID号,访问越界的地址以及当时进程堆栈地址等信息,比较有用的信息是 最后的error number. 在上面的信息中,error number是4 ,下面详细介绍一下error number的信息:
在上面的例子中,error number是6, 转成二进制就是110, 即bit2=1, bit1=1, bit0=0, 按照上面的解释,我们可以得出这条信息是由于用户态程序读操作访问越界造成的。
error number是由三个字位组成的,从高到底分别为bit2 bit1和bit0,所以它的取值范围是0~7.
bit2: 值为1表示是用户态程序内存访问越界,值为0表示是内核态程序内存访问越界
bit1: 值为1表示是写操作导致内存访问越界,值为0表示是读操作导致内存访问越界
bit0: 值为1表示没有足够的权限访问非法地址的内容,值为0表示访问的非法地址根本没有对应的页面,也就是无效地址
如:
Nov 3 09:27:50 ip-172-31-18-210 kernel: [12702742.866113] nginx[53350]: segfault at 1b852e2 ip 00007f9085b3b616 sp 00007ffdf15f1368 error 4 in libc-2.17.so[7f90859ec000+1b7000]
nginx[31752]: segfault at 0 ip 000000000047c0d5 sp 00007fff688cab40 error 4 in nginx[400000+845000]
Linux下打开core文件,定位segfault --http://blog.chinaunix.net/uid-24774106-id-344195.html
出现段错误,不容易定位到底是哪行代码出现了问题,segfault多次折磨的笔者死去活来,
--------------------------------
Linux上Core Dump文件的形成和分析---http://baidutech.blog.51cto.com/4114344/904419/
Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:
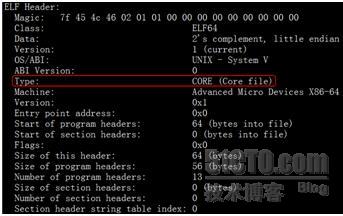
从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:
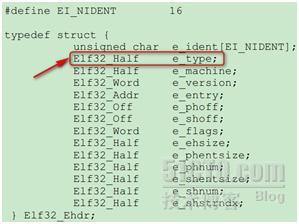
其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main(){
int stack_of[100000000];
int b=1;
int* a;
*a=b;
}
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:

可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:
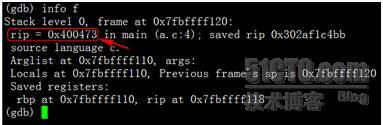
其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:

这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:

可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main(){
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
}
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:
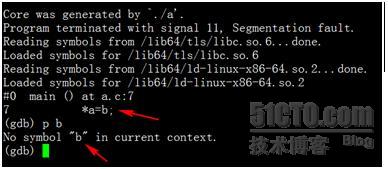
可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:
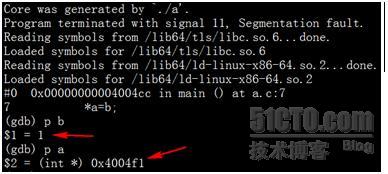
这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。
segfault at xxx rip xxx rsp xxx error 4(合并整理)相关推荐
- segfault at XXX rip XXX rsp XXX error 4 错误
http://chenwenming.blog.51cto.com/327092/1322103 内核日志经常会出现以下报错. nginx-payment-n[29580]: segfault at ...
- 解决webpack报错:ERROR in multi ./xxx/xxx.js ./xxx/xxx.js Module not found: Error: Can't resolve '.\xxx\
问题描述 初次使用webpack打包 报了一个鲜红的异常: ERROR in multi ./xxx/xxx.js ./xxx/xxx.js Module not found: Error: Can' ...
- Couldn't register com.zyg.ios.XXX with the bootstrap server. Error: unknown error code.
运行应用突然崩溃,然后再次运行就出现了如下错误: Couldn't register com.zyg.ios.XXX with the bootstrap server. Error: unknown ...
- Error:(8,16) java: 找不到符号和Error:(9, 15) java: 找不到符号符号:类 xxx位置:程序包 xxx.xxx
昨天晚上遇到的一个bug,写了一个main方法,发现执行的时候老师报:Error:(15,8) java: 找不到符号和Error:(9, 15) java: 找不到符号符号:类 xxx位置:程序包 ...
- git 问题解决之remote: Permission to xxx/xxx.git denied to xxx.
Git问题总结: 1.$ git push origin :dev-xx remote: Permission to xxx/xxx.git denied to xxx. fatal: unable ...
- 在Ubuntu下,编译Kernel报错:Makefile:xxx: recipe for target 'xxx' failed
**在Ubuntu下,编译Kernel报如下错误:** Makefile:xxx: recipe for target 'xxx' failed make[2]:***[arch/arm/boot/c ...
- remote: Permission to xxx.git denied to xxx. fatal: unable to access 'https://github.com/xxx.git/':
remote: Permission to xxx.git denied to xxx. fatal: unable to access 'https://github.com/xxx.git/': ...
- TFS2010映射工作区问题 路径 XXX 已在工作区 XXX;XXX 中映射
路径 XXX 已在工作区 XXX;XXX 中映射 原因:之前用别的用户登录工作区并映射到该路径. 解决办法:再用之前的用户登录工作区取消映射即可. 备忘:在文件 C:\Documents and Se ...
- fatal: Path ‘XXX‘ is in submodule ‘XXX‘错误(path is in submodule)
由于需求的原因,最近在修改Netron这个机器学习可视化网络的开源代码,并重新编译,但是在修改成功之后上传到本人的git仓库的时候却出现了 fatal: Path 'XXX' is in submod ...
最新文章
- OWA登录页面显示为英文而不是中文
- js在PageOffice打开的Word文档光标处插入书签
- Unable to open a test connection to the given database.
- LNMP(Nginx负载均衡,SSL原理,Nginx配置SSL,生产SSL密钥对)
- 一些日常工具集合(C++代码片段)
- JS学习笔记:防止发生命名冲突
- 公司僵尸帐号引发了一系列的入侵事件-细说密码强度验证的重要性
- java获取本周的开始时间和结束时间_创业板注册制开始时间/股票开户流程结束后,怎么炒股?...
- js判断null_JavaScript中的undefined和null
- Server Tomcat v7.0 Server at localhost was unable to start within 45 seconds
- SLAM_kitti数据集求相机cam2到IMU的变换矩阵
- 《中国科学》中文论文模板使用CCTTEX编译
- 高中数学竞赛书籍推荐
- 第1章 SAAS-HRM系统概述与搭建环境
- oracle现金流量表逻辑,财务学习:现金流量表内在逻辑研究
- 仅需3 小时,如何用 AI 做场景贴图,完成场景制作 ?AI创作工作流探索
- HTML+CSS静态网页设计:(房地产网站设计与实现6页)
- Spring data报错:Inferred type 'S' for type parameter 'S' is not within its bound;
- 哈工大计算机专业复试科目,哈工大 计算机科学与技术学院复试科目.doc
- CNN-台大李宏毅学习笔记