第三篇:基于深度学习的人脸特征点检测 - 数据集整理
https://yinguobing.com/facial-landmark-localization-by-deep-learning-data-collate/
在上一篇博文中,我们已经下载到了包括300-W、LFPW、HELEN、AFW、IBUG和300-VW在内的6个数据集,初步估算有25万个样本可以使用。同时还发现了一篇论文描述了采用深度神经网络来提取特征点的方法。在本篇文章中,我们将尝试对下载到的数据进行分析整理,包括:
- 统计数据集中不同格式文件的数量。
- 提取视频文件中的每一帧为单独的文件。
- 从自定义格式pts文件中读取特征点坐标,并显示在图片上。
这些步骤将为后续的工作打下坚实的数据基础。
检查数据集的形式
为方便使用,大部分数据集都会尽可能的保留原始数据,并将附加的信息以文本或者其它形式进行存储,然后打包成一个或者若干压缩文档。所以拿到数据集后的第一件事,就是阅读数据集的说明文档。通过阅读说明,我们发现这六个数据库中的特征点坐标均以后缀名为pts的格式进行存储,且文件名与对应的图片文件名相同。
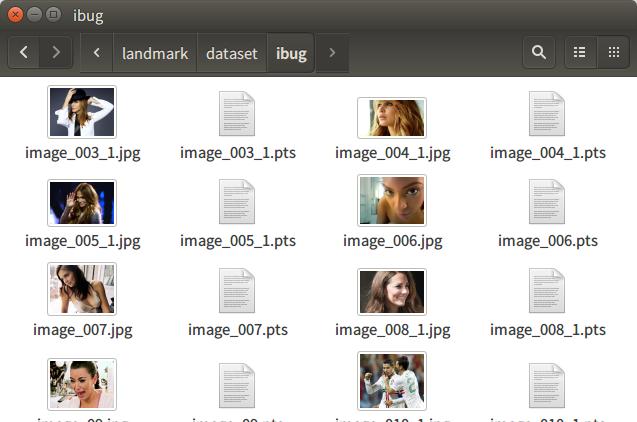
有一个例外是300-VW。由于它是视频数据库,每一个视频文件则对应多个pts文件,每个pts文件对应了视频中的某一帧。
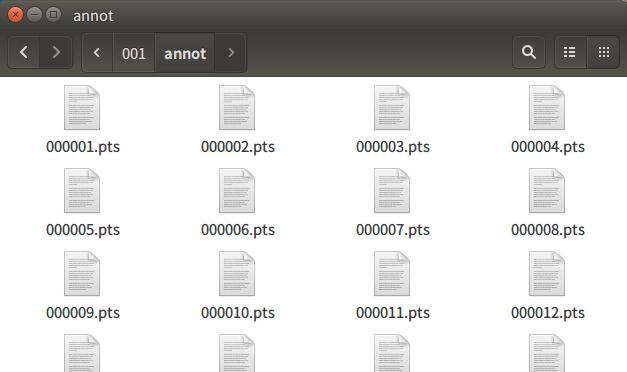
打开其中任意一个pts文件,发现文件内容大概是这个样子:
version: 1
n_points: 68
{
336.820955 240.864510
334.238298 260.922709
335.266918 283.697151
# 中间省略若干行
370.512631 329.910074
363.035791 328.132512
357.493721 327.074215
}
不难发现,每一个pts文件中第一行是文件版本,第二行是坐标个数说明,从第三行开始,括号内存储的是对应图像中人脸的68个特征点的坐标x与y,一行一组。所以有多少个pts文件,就有多少个可用样本。所以,我们究竟有多少个可用样本?
使用Python统计文件数量
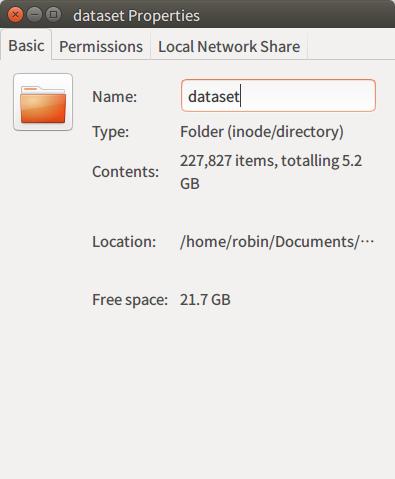
在Linux系统下,统计文件数量其实是非常简单的事情。直接在文件夹上点击鼠标邮件,选取Properties即可看到文件夹下的文件总数与大小。例如我这里总共包含227827项,大小5.2GB。但是这并不能准确的告诉我们pts文件的个数。并且,为了对数据集获得全面的认识,我们通常希望掌握文件夹下所有文件的数量与分布情况。这时候就该Python出场了!
为什么用Python?作为“自带电池”的计算机程序语言,Python提供了一系列模块可以极大的提升我们的工作效率,用尽可能少的代码快速的实现功能。对于统计文件数量这个需求来说,我们可以简单的使用几个函数就实现。主要的思路是:
os.walk()用来列出目录下所有文件夹与文件[1]。split()分割文件名,获取文件后缀名。collection.Counter来统计后缀名的数量[2]。
最后总体代码只有55行,包含了注释与空行。你可以自己尝试实现一下,也可以查看我在Github上开源实现。
经过统计,当前数据集所包含的文件数量与分布情况如下:
Total files: 227587
zip: 1; txt: 1; jpg: 2802; png: 1635; pts: 223034; avi: 114; Done!
从中可以看到我们可以使用的样本个数为223034个,即pts文件的个数。图片以两种格式存储,jpg格式2802个,png格式1635个,两者加起来才4437个。有20多万个样本都以视频帧的形式存储在114个avi文件中。
使用FFmpeg提取视频帧
若要利用这20多万个样本,需要从视频中提取每一帧图像为单独的文件。这里我推荐使用著名的音视频包FFmpeg[3]。
![]()
FFmpeg是一套完整的音视频转换与流媒体开源解决方案。在Ubuntu下你可以简单的通过apt命令来安装它。FFmpeg的使用也很简单,在终端中输入以下命令即可将视频中的每一帧提取成为单独的图像文件,存放在当前目录的image文件夹下,文件名取自帧编号:
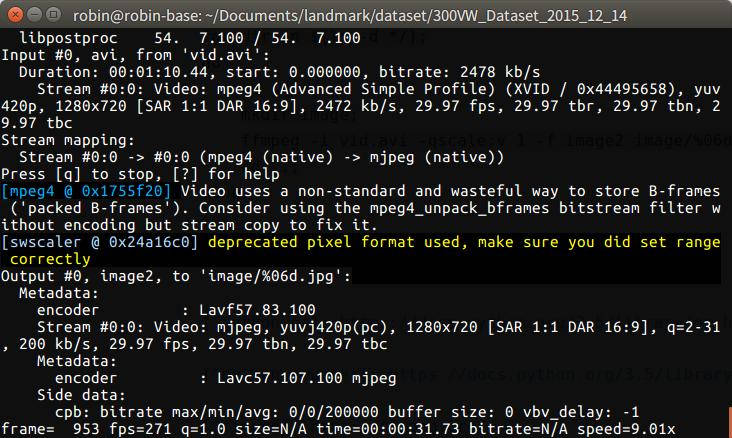
ffmpeg -i vid.avi -qscale:v 1 -f image2 image/%06d.jpg
其中-i是指定输入文件,-qscale:v是指定输出的图片质量参数,-f为输出文件的模式。如果不指定-qscale:v的话FFmpeg会使用默认参数输出,图片质量会变得很差[4]。下图从左向右依次是默认参数,质量为1和不压缩的BMP格式。

由于300-VW下的114个avi视频文件文件名是相同的,我们可以写一个简单的Shell脚本来批量将avi视频中的帧提取出来。
for dir in $(ls -d */);
do cd $dir;mkdir image;ffmpeg -i vid.avi -qscale:v 1 -f image2 image/%06d.jpg;cd ..;
done
这段脚本在执行过程中会输出log供参考。整个300-VW的转换在我的计算机上花费的时间不到10分钟。
转换完成后,我们可以使用之前创建好的文件统计脚本重新统计文件数量。
Total files: 446185
jpg: 221399; txt: 1; pts: 223034; png: 1635; zip: 1; sh: 1; avi: 114; Done!
将jpg的数量221399与png的数量1635加起来是223034,刚好等于pts文件的数量。
So far so good!不过,这些图片与pts中的坐标能对应上吗?
验证特征点坐标与图片的一致性
理论上图片与坐标数据是一一对应的,不过我相信你心里应该也会有那么一点点的不确定——同名的pts与图像文件真的一一对应吗?我们从视频中提取出来的图像呢,也能对应上吗?
为了消除心中的这个疑虑,也是为了从最开始就排除数据不匹配这一最糟糕的情况,最好将数据中的特征点画在对应图像上,人工用肉眼来验证一下!
要达成这一目标,需要实现以下两个主要功能:
- 从
pts文件中读取68个特征点的坐标。 - 读取对应的图像,将特征点绘制在图像上并呈现出来。
使用Python读取文本文件
Python读取文本文档是不能再简单的事情,使用以下3行代码即可逐行打印出文本文档中的所有内容[5]。
with open('image_003_1.pts') as file:for line in file:print(line)
使用该方法将一个pts文件中的内容打印出来如下:
version: 1
n_points: 68
{
336.820955 240.864510
334.238298 260.922709
335.266918 283.697151
# 中间省略若干行
370.512631 329.910074
363.035791 328.132512
357.493721 327.074215
}
仔细观察不难发现,68个特征点在pts文件中是顺序存储的,一行一组,所以只需要排除掉非坐标点行即可得到所有坐标。具体的排除方法可以自选,例如坐标行中仅包含数字、小数点和空格,非坐标行的字符与符号几乎是固定的。稍微留意一下方法的稳健性与通用性即可。如果你想也可以参考下我在Github上的实现方法[6]。
使用Python读取并显示图片
在这里,我推荐使用适用于Python的OpenCV模块。你可以通过pip方式安装,也可以按照官方教程[7]自行编译。
安装完成后,我们就可以使用Python调用OpenCV函数,主要是以下3个:
cv2.imread()读取图像文件。cv2.circle()在图像指定位置处绘制圆点。cv2.imshow()将修改后的图像显示在窗口中。
具体实现过程并不复杂,你可以自己尝试一下,同样也可以参考我在Github上的实现方法[6:1]。
最后,我们从搜集好的6个数据集中随机选择一些文件来看一下效果。
300-VW

300-W

AFW

HELEN
HELEN数据集中的图片分辨率较高,因此绘制的Mark点看上去很小。

IBUG

LFPW
同样需要注意的是有时候图片中存在多张人脸,但是一个pts文件中只存储一个人脸的数据。

看上去还不错,是吧!
接下来的工作
至此我们已经将数据集整理并验证完成。如果你有耐心,可以把所有的数据集都过一遍,你会发现数据集中的图片有大有小,样本人群多种多样,眼镜、首饰等等遮挡情况不时发生。总体看来这些都是不错的训练样本,不过也给我们后边的工作带来了一些麻烦。如果人脸只占图片中的一小部分,却将整张图片送入神经网络,然后要求学习特征点坐标,这意味着神经网络需要学习非常复杂的规则,花精力去区分非人脸部分,意味着网络的复杂度会提高,意味着参数的数量会上升,意味着需要更多的训练样本,更长的训练时间,以及最后在应用时更慢的运行速度。所以,我们怎么办?
这是我们在下一篇博文中要解决的问题:定义检测规则,并提取适合神经网络的训练样本。
https://docs.python.org/3.5/library/os.html ↩︎
https://docs.python.org/3.5/library/collections.html ↩︎
http://ffmpeg.org/ ↩︎
StackOverflow: How can I extract a good quality JPEG image from an H264 video file with ffmpeg? ↩︎
https://docs.python.org/3.5/tutorial/inputoutput.html ↩︎
https://github.com/yinguobing/image_utility/blob/master/pts_tools.py ↩︎ ↩︎
https://docs.opencv.org/master/d7/d9f/tutorial_linux_install.html ↩︎

第三篇:基于深度学习的人脸特征点检测 - 数据集整理相关推荐
- 第四篇:基于深度学习的人脸特征点检测 - 数据预处理
在上一篇博文中,我们整理了300-W.LFPW.HELEN.AFW.IBUG和300-VW这6个数据集,使用Python将特征点绘制在对应的图片上,人工验证了数据集的正确性,最终获得了223034个人 ...
- 第二篇:基于深度学习的人脸特征点检测 - 数据与方法(转载)
https://yinguobing.com/facial-landmark-localization-by-deep-learning-data-and-algorithm/ 在上一篇博文中,我们了 ...
- 第五篇:基于深度学习的人脸特征点检测 - 生成TFRecord文件
在上一篇博文中,我们已经获取到了所有样本的面部区域,并且对面部区域的有效性进行了验证.当使用TensorFlow进行神经网络训练时,涉及到的大量IO操作会成为训练速度的瓶颈.为了加快训练的速度,方便后 ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- python dlib caffe人脸相似度_基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【一】如何配置caffe属性表...
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 基于深度学习的人脸识别与管理系统(UI界面增强版,Python代码)
摘要:人脸检测与识别是机器视觉领域最热门的研究方向之一,本文详细介绍博主自主设计的一款基于深度学习的人脸识别与管理系统.博文给出人脸识别实现原理的同时,给出Python的人脸识别实现代码以及PyQt设 ...
- 基于深度学习的人脸检测和关键点检测推理实践(OpenCV实现,含代码)
目录 一.任务概述 二.环境准备 三.实现步骤 3.1 Python推理 3.2 C++推理 3.2.1 环境准备 3.2.2 推理 3.3 Java推理 一.任务概述 最近项目中大量场景需要用到人脸 ...
- 基于深度学习的人脸识别综述
本文转载自 https://xraft.github.io/2018/03/21/FaceRecognition/ (作者:Caleb Ge (葛政)),如有侵权请告知删除. (下文中的"我 ...
- 开发基于深度学习的人脸识别【考勤/签到】系统
开发基于深度学习的人脸识别[考勤/签到]系统 人脸识别介绍 平台环境需求 技术点 系统流程 细节设计 人脸检测 人脸关键点定位 人脸特征提取 模型的训练 模型的部署 MySQL数据库的使用 MFC工程 ...
最新文章
- 5G 与边缘计算的发展现状(2021 年 6 月)
- 视觉SLAM回环检测、词袋模型和视觉位置识别--论文记录和实验简析
- CTR预估中GBDT与LR融合方案
- 谷歌浏览器flash崩溃怎么办 Google Chrome flash崩溃解决方法
- iOS原生实现二维码拉近放大
- 什么样的人不适合当程序员呢?
- 专利附图绘制-VISIO线条图绘制入门
- java在线订单系统源码_春哥酒店在线预订微信小程序源码系统正式发布!
- EXCEL 数据透视表的制作
- matconvnet(CPU版本)基本使用
- Python 计时器(秒钟、秒表)
- 【智慧农业】LORA农业灌溉解决方案
- turlebot3 ROS相关求助
- ESP8266-Arduino网络编程实例-WiFi连接丢失解决方法
- 2021 安装centos
- Xshell 配置突出显示集(关键字高亮)
- maven oracle 10.2.0.4.0,马文介绍说ojdbc:ojdbc14-10.2.0.4.0.jar,Maven,引入,ojdbcojdbc14102040jar...
- 微信h5支付在iframe弹窗的坑
- 使用SSM框架整合时,无法创建XXXXBean
- 【Mysql上分之路】第三篇:Mysql安装与配置、目录结构