Kibana【从无到有从有到无】【搜索引擎】【K4】可视化
目录
1.可视化
1.1.创建可视化视图
1.2.线形图、区域图和条形图
1.2.1. 指标 & 轴
1.2.2. 指标
1.2.3.Y 轴
1.2.4. X 轴
1.2.5.面板设置
1.2.6. 通用选项
1.2.7.网格选项
1.3.数据表
1.4.Markdown 控件
1.5.指标(Metric)
1.6.饼图
1.7.Tile 地图
1.7.1.配置
1.7.1.1.数据
1.7.1.1.1.指标
1.7.1.1.2.桶
1.7.1.2.选项
1.7.2.浏览地图
1.8.时间序列可视化生成器
1.8.1.特色可视化
1.8.1.1.时间序列
1.8.1.2.指标
1.8.1.3.Top N
1.8.1.4.测量仪(Gauge)
1.8.1.5.Markdown
1.8.2.界面概述
1.8.2.1.数据标签页
1.8.2.1.1.序列标签和颜色
1.8.2.1.2.指标
1.8.2.1.3.序列选项
1.8.2.1.4.分组控件
1.8.2.2.面板选项标签页
1.8.2.3.Annotations 标签页
1.8.2.4.Markdown 选项卡
1.9.标签云
1.10.热点图
1.11.可视化监测
1.可视化
可视化 (Visualize) 功能可以为您的 Elasticsearch 数据创建可视化控件。然后,您就可以创建仪表板将这些可视化控件整合到一起展示。
Kibana 可视化控件基于 Elasticsearch 的查询。利用一系列的 Elasticsearch 查询聚合功能来提取和处理数据,您可以通过创建图表来呈现您关心的数据分布和趋势。
您可以基于在 Discover 页面保存的查询或者新建一个查询来创建可视化控件。
1.1.创建可视化视图
要创建可视化视图:
- 点击左侧导航栏的 Visualize 。
- 点击 Create new visualization 按钮或 + 按钮。
选择视图类型:
基础图形
Line, Area and Bar charts
在X/Y图中比较两个不同的序列。
Heat maps
使用矩阵的渐变单元格。
Pie chart
显示每个来源的占比。
数据
Data table
显示一个组合聚合的原始数据。
Metric
显示单个数字。
地图
Coordinate map
把一个聚合结果关联到地理位置。
时间序列
Timelion
计算和合并来自多个时间序列数据集。
Time Series Visual Builder
使用管道聚合显示时间序列数据。
其他
Tag cloud
显示标签云,每个标签的字体大小表示其重要性。
Markdown widget
显示自由格式信息或说明。
4. 指定一个查询,为视图获取数据:
- 想要输入新的搜索条件,只需为包含想要可视化数据的索引库选择索引模式。这将打开一个可视化视图编辑器,并关联一个匹配所选索引库里所有文档的通配符查询。
想要从一个已有的搜索来构建一个可视化视图,只需点击想使用的已有查询名称即可。这将打开一个视图编辑器并加载所选的查询。
当从一个已有的搜索来构建可视化视图时,随后对已有查询的任何修改都会自动反馈在视图中。
想要禁止自动更新,您需要断开视图和已保存的搜索之间的连接。5. 在视图编辑器中为视图的Y轴选择指标聚合:
- 指标聚合(Metrics Aggregations) :
- count
- average
- sum
- min
- max
- standard deviation
- unique count
- median (50th percentile)
- percentiles
- percentile ranks
- top hit
- geo centroid
- 父类管道聚合(Parent Pipeline Aggregations) :
- derivative
- cumulative sum
- moving average
- serial diff
- 兄弟管道聚合(Sibling Pipeline Aggregations) :
- average bucket
- sum bucket
- min bucket
- max bucket
6. 为视图X轴选择一个桶聚合:
- date histogram
- range
- terms
- filters
- significant terms
比如,如果正在索引 Apache 服务器日志,就可以构建一个条形图,通过指定 geo.src 字段上的一个 term 聚合,来展示地理位置的请求分布:
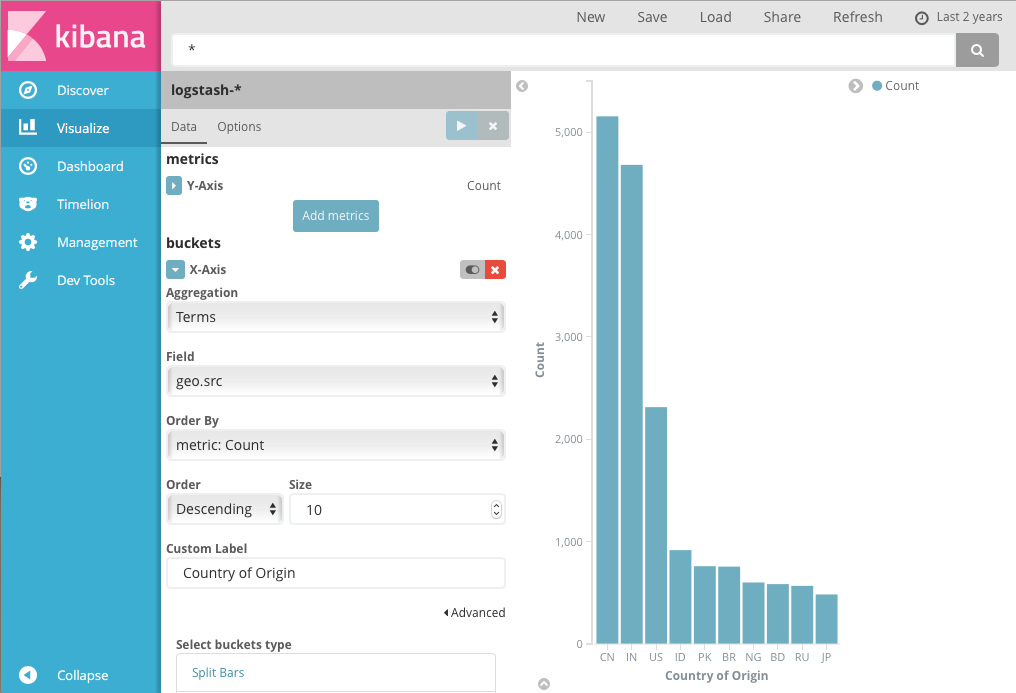
Y轴表示来自每个国家的请求数量,而X轴则表示要显示的国家。
图、线或区域图的可视化都是使用 度量 指标作为Y轴,使用 桶 作为X轴。桶类似于SQL中的 GROUP BY 语句。Pie 图中使用分片大小作为指标,分片数量作为桶。
还可以进一步根据指定的子聚合来划分数据。第一个聚合决定任何子序列聚合的数据集。子聚合是有顺序的,可以通过拖拽聚合来改变。
比如,可以在 geo.dest 字段增加一个 term 子聚合到原始国家条形图,来查看这些请求对应的位置。
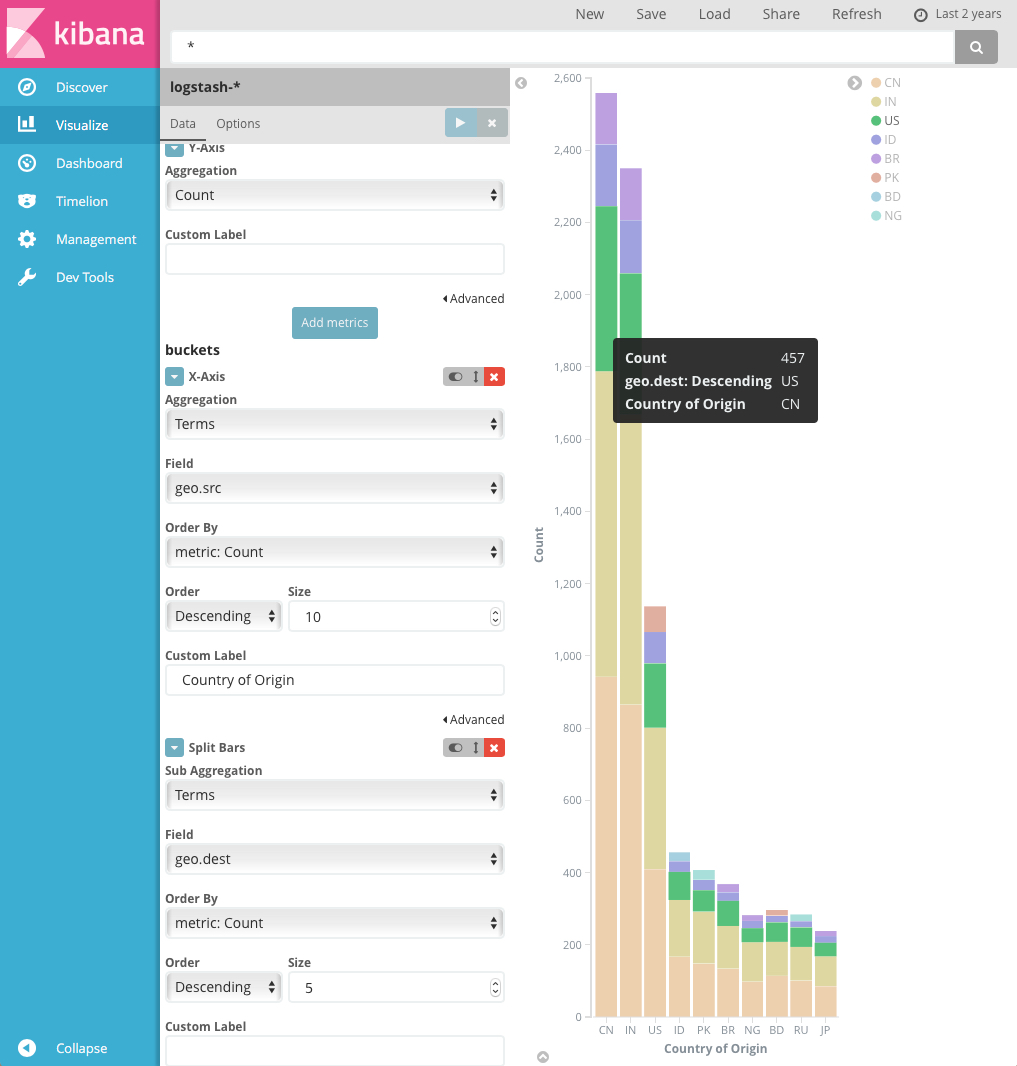
更多关于子聚合的内容,请参考这篇博文 Kibana, Aggregation Execution Order, and You。
1.2.线形图、区域图和条形图
线形图,区域图和条形图允许您在 X/Y 轴上绘制数据。
首先,您需要选择定义值轴的 指标 。
指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
该聚合返回数字字段的平均值 。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数字字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数字字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数字字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数 聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。
Standard Deviation
扩展统计 聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。
Percentiles
百分数 聚合将数字字段中的值分成您指定的百分数区间。从下拉列表中选择一个字段,然后在 Percentiles输入域中指定一个或多个范围。点击 X 删除百分数字段。点击 + Add 添加百分数字段。
Percentile Rank
百分位等级 聚合返回指定的数值字段中的值的百分位等级。从下拉菜单中选择一个数字字段,然后在 Values 输入域中指定一个或多个百分比等级值。点击 X 删除值字段。点击 + Add 添加值字段。
父级管道聚合:
对于每个父管道聚合,您必须定义用于计算聚合的指标。这可能是您现有的指标之一或新的指标。您也可以嵌套这些聚合(例如产生3阶导数)。
Derivative
导数 聚合计算特定指标的导数。
Cumulative Sum
累计总和 聚合计算父直方图中指定指标的累计总和。
Moving Average
移动平均值 聚合将动态移动数据窗口,生成该窗口数据的平均值。
Serial Diff
串行差分 是一种时间序列中的值在不同时间滞后或周期内从自身减去的技术。
兄弟管道聚合:
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的指标。除此之外,还需要提供一个桶聚合,它将定义同级聚合将在其中运行的桶。
Average Bucket
桶平均值 计算同级聚合中指定指标的(中数)平均值
Sum Bucket
桶总和 计算同级聚合中指定指标值的总和
Min Bucket
桶最小值 计算同级聚合中指定指标的最小值
Max Bucket
桶最大值 计算同级聚合中指定指标的最大值
您可以通过单击 + Add Metrics 按钮来添加聚合。
在 Custom Label 输入域中输入字符串以更改显示标签。
桶 聚合确定从数据集中检索哪些信息。
在选择桶聚合之前,请指定是在单个图表内拆分切片还是拆分为多个图表。多个图表拆分必须在任何其他聚合之前运行。在拆分图表时,可以通过单击 Rows | Columns 选择器来更改拆分是显示在行中还是列中。
这个图表的 X 轴是 桶 轴。您可以为 X 轴定义桶,用于图表上的分割区域,也可以用于分割图表。
这个图表的 X 轴支持下面的聚合。单击每个聚合的链接名称以访问该聚合的 Elasticsearch 主文档。
Date Histogram
日期直方图 是从数值字段构建并按日期组织的。您可以以秒、分钟、小时、天、周、月或年为单位指定时间间隔。您还可以通过选择 Custom 作为间隔并在文本域中输入数字和时间单位来指定自定义时间间隔。自定义间隔时间单位 s 为秒, m 为分钟, h 为小时, d 为天, w 为周, y 为年。不同的单位支持不同级别的精度,低至一秒。
Histogram
标准 直方图 是从数字字段构建的。为此字段指定一个整数间隔。选择 Show empty buckets 复选框以在直方图中包含空白区间。
Range
通过 范围 聚合,您可以为数字字段指定值的范围。点击 Add Range 添加一组范围端点。点击红色的 (x) 符号删除一个范围。
Date Range
日期范围 聚合报告在您指定的日期范围内的值。您可以使用 日期数学 表达式来指定日期的范围。点击 Add Range 添加一组范围端点。 点击红色的 (x) 符号删除一个范围。
IPv4 Range
IPv4 范围 聚合使您能够指定 IPv4 地址的范围。点击 Add Range 添加一组范围端点。点击红色的 (x) 符号删除一个范围。
Terms
词条 聚合使您可以指定要显示的给定字段的顶部或底部 n 个元素,按数量或自定义指标进行排序。
Filters
您可以为数据指定一组 过滤器 。您可以将过滤器指定为查询字符串或采用 JSON 格式,就像在 Discover 搜索栏中一样。点击 Add Filter 添加另一个过滤器。点击  label 按钮打开标签字段,其中 您可以键入一个名称以显示在可视化中。
label 按钮打开标签字段,其中 您可以键入一个名称以显示在可视化中。
Significant Terms
显示实验性的 重要词项 聚合的结果。
一旦您指定了 X 轴聚合,您可以定义子聚合来优化可视化。单击 + Add Sub Aggregation 定义子聚合,然后选择 Split Area 或 Split Chart ,然后从类型列表中选择一个子聚合。
在图表轴上定义多个聚合时,可以使用聚合类型右侧的向上或向下箭头来更改聚合的优先级。
在 Custom Label 输入域中输入字符串以更改显示标签。
点击每个标签旁边的色点来显示 颜色选择器 ,可以自定义视图的颜色。
在 Custom Label 输入域中输入字符串以更改显示标签。
您可以点击 Advanced 链接为您的指标或桶聚合显示更多自定义选项:
Exclude Pattern
在此输入域中指定一个模式以从结果中排除。
Include Pattern
在此输入域中指定一个模式以包含在结果中。
JSON Input
一个文本域,您可以在其中添加特定的 JSON 格式的属性以与聚合定义合并,如下例所示:
{ "script" : "doc['grade'].value * 1.2" }
在 Elasticsearch 版本1.4.3及更高版本中,此功能要求您启用动态 Groovy 脚本.
这些选项的可用性取决于您选择的聚合。
1.2.1. 指标 & 轴
选择 Metrics & Axes 选项卡可以更改图表上每个单独的指标的显示方式。数据系列在 指标 部分中进行样式设置,而轴在 X 和 Y 轴部分进行样式设置。
1.2.2. 指标
修改数据面板中的每个指标在图表上被可视化的方式。
Chart type
在 Area 、 Line 和 Bar 类型之间进行选择。
Mode
堆叠不同的指标,或将它们彼此相邻绘制。
Value Axis
选择要绘制此数据的轴(每个属性在 Y 轴下配置)。
Line mode
线条或柱条的轮廓是否应该是 smooth(平滑) 、 straight(笔直) 、或 stepped(阶梯) 的。
1.2.3.Y 轴
调整图表的所有 Y 轴。
Position
Y 轴的位置(垂直图表为 left 或 right ,水平图表为 top 或 bottom )。
Scale type
数值的缩放( linear 、 log 或 square root )。
高级选项
Labels - Show Labels
允许您隐藏轴标签。
Labels - Filter Labels
如果启用了标签过滤,则在没有足够空间显示它们的情况下,会隐藏一些标签。
Labels - Rotate
您可以以度数为单位输入您想要标签旋转的角度。
Labels - Truncate
您可以输入标签被截断的像素大小。
Scale to Data Bounds
默认的Y轴界限为零和数据中返回的最大值。选中此框可更改上限和下限以匹配数据中返回的值。
Custom Extents
您可以为每个轴定义自定义的最小值和最大值。
1.2.4. X 轴
默认情况下,图表中定义了一个 X 轴,但您可以根据需要添加。点击 + 号创建一个新的 X 轴。
Position
X 轴的位置 (水平图表为 left 或 right ,垂直图表为 top 或 bottom )。
高级选项
Labels - Show Labels
允许您隐藏轴标签。
Labels - Filter Labels
如果启用了标签过滤,则在没有足够空间显示它们的情况下,会隐藏一些标签。
Labels - Rotate
您可以以度数为单位输入您想要标签旋转的角度。
Labels - Truncate
您可以输入标签被截断的像素大小。
1.2.5.面板设置
这些选项适用于整个图表,而不仅仅是单个数据系列。
1.2.6. 通用选项
Legend Position
将您的图例移动到 left 、 right 、 top 或 bottom 。
Show Tooltip
启用或禁止显示鼠标悬停在图表对象上时的工具提示。
Current Time Marker
显示一条线表示当前时间。
1.2.7.网格选项
您可以在图表上启用网格。 默认情况下,网格仅显示在类别轴上。
X-axis
您可以禁止显示类别轴上的网格线。
Y-axis
您可以选择要显示网格线的数值轴(如果有)。
1.3.数据表
指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
该聚合返回数字字段的平均值 。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数字字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数字字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数字字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数 聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。
Standard Deviation
扩展统计 聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。
Percentiles
百分数 聚合将数字字段中的值分成您指定的百分数区间。从下拉列表中选择一个字段,然后在 Percentiles输入域中指定一个或多个范围。点击 X 删除百分数字段。点击 + Add 添加百分数字段。
Percentile Rank
百分位等级 聚合返回指定的数值字段中的值的百分位等级。从下拉菜单中选择一个数字字段,然后在 Values 输入域中指定一个或多个百分比等级值。点击 X 删除值字段。点击 + Add 添加值字段。
父级管道聚合:
对于每个父管道聚合,您必须定义用于计算聚合的指标。这可能是您现有的指标之一或新的指标。您也可以嵌套这些聚合(例如产生3阶导数)。
Derivative
导数 聚合计算特定指标的导数。
Cumulative Sum
累计总和 聚合计算父直方图中指定指标的累计总和。
Moving Average
移动平均值 聚合将动态移动数据窗口,生成该窗口数据的平均值。
Serial Diff
串行差分 是一种时间序列中的值在不同时间滞后或周期内从自身减去的技术。
兄弟管道聚合:
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的指标。除此之外,还需要提供一个桶聚合,它将定义同级聚合将在其中运行的桶。
Average Bucket
桶平均值 计算同级聚合中指定指标的(中数)平均值
Sum Bucket
桶总和 计算同级聚合中指定指标值的总和
Min Bucket
桶最小值 计算同级聚合中指定指标的最小值
Max Bucket
桶最大值 计算同级聚合中指定指标的最大值
您可以通过单击 + Add Metrics 按钮来添加聚合。
在 Custom Label 输入域中输入字符串以更改显示标签。
数据表的行叫做 桶 。可以通过定义桶把表格划分为多行或者拆分表格到另外的表中。
每个桶类型支持以下聚合:
Date Histogram
一个 date histogram 从一个数值型字段构建,并按日期组织。可以为间隔指定一个按秒、分钟、小时、天、周、月或年的时间段。也可以指定一个自定义的时间区间,只需选择 Custom 作为间隔,并在文本字段中指定一个数字和一个时间单位即可。对于自定义间隔时间单位,s 表示秒, m 表示分钟,h 表示小时, d表示天, w 表示周, y 表示年。不同单位支持不同的精度级别,最低为一秒。
Histogram
一个标准的 histogram 从一个数值型字段构建,并为该字段指定一个整数类型的间隔,选择 Show empty buckets 复选框可在直方图中包括空的间隔。
Range
通过一个 range 聚合,可以为一个数值型字段指定值的范围。点击 Add Range 增加一个范围聚合,点击红色的 (x) 符号来删除一个范围。
Date Range
date range 聚合展示在指定日期范围内的值。可通过 date math 表达式来指定日期范围。
IPv4 Range
IPv4 range 聚合支持指定IPV4地址范围。点击 Add Range 增加一组范围端点,点击红色的 (/) 符号移除范围。
Terms
terms 聚合支持指定一个给定字段的头部或尾部 n 个元素来显示,并通过数量或自定义指标排序。
Filters
可以为数据指定一系列 filters 。支持通过一个查询串或者 JSON 格式来指定一个过滤器,就像在 Discover 搜索框中一样。点击 Add Filter 来增加另一个过滤器。点击 label 按钮打开标签字段,输入一个可显示在视图中的名称。
Significant Terms
显示试验 significant terms 聚合的结果。 Size 参数的值定义该聚合返回的实体数量。
Geohash
geohash 聚合根据 geohash 坐标来显示点。
一旦指定了一个桶类型的聚合,就可以定义子桶来优化视图。点击 + Add sub-buckets 来定义一个子桶,然后选择 Split Rows 或 Split Table ,再从类型列表中选择一种聚合。
可以使用向上或向下键翻到合适的聚合类型,以更改聚合优先级。
在 Custom Label 字段中输入一个字符串来修改显示标签。
可以点击 Advanced 链接显示指标或桶聚合的更多自定义选项:
Exclude Pattern
从结果中排除该字段指定的模式。
Include Pattern
在结果中包括该字段所指定的模式。
JSON Input
一个文本字段,可以通过加入指定的 JSON 格式属性与聚合定义合并,示例如下:
{ "script" : "doc['grade'].value * 1.2" }
| 在Elasticsearch 1.4.3及更新的版本中,此功能需要打开 dynamic Groovy scripting。 |
这些选项是否可用取决于所选的聚合。
选择 Options 标签来改变表格的下列方面:
Per Page
该字段控制表格的分页,默认每页10行。
复选框用于打开或关闭下列行为:
Show metrics for every bucket/level
勾选该选项,将为每个 bucket 聚合显示中间结果。
Show partial rows
勾选该选项,即使没有结果也会显示一行。
| 支持这些行为可能对性能会有较大影响。 |
1.4.Markdown 控件
Markdown 控件是一个文本输入字段,支持 Github 风格的 Markdown 文本。Kibana 会渲染输入到该字段的文本,并把结果展示在仪表板上。点击 Help 链接可以跳转到 Github 风格 Markdown 的 帮助页面,点击 Apply 在预览窗格中显示渲染文本,或点击 Discard 回退到之前的版本。
1.5.指标(Metric)
一个指标视图为每个查询聚合显示一个单一的数字:
指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
该聚合返回数字字段的平均值 。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数字字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数字字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数字字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数 聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。
Standard Deviation
扩展统计 聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。
Percentiles
百分数 聚合将数字字段中的值分成您指定的百分数区间。从下拉列表中选择一个字段,然后在 Percentiles输入域中指定一个或多个范围。点击 X 删除百分数字段。点击 + Add 添加百分数字段。
Percentile Rank
百分位等级 聚合返回指定的数值字段中的值的百分位等级。从下拉菜单中选择一个数字字段,然后在 Values 输入域中指定一个或多个百分比等级值。点击 X 删除值字段。点击 + Add 添加值字段。
父级管道聚合:
对于每个父管道聚合,您必须定义用于计算聚合的指标。这可能是您现有的指标之一或新的指标。您也可以嵌套这些聚合(例如产生3阶导数)。
Derivative
导数 聚合计算特定指标的导数。
Cumulative Sum
累计总和 聚合计算父直方图中指定指标的累计总和。
Moving Average
移动平均值 聚合将动态移动数据窗口,生成该窗口数据的平均值。
Serial Diff
串行差分 是一种时间序列中的值在不同时间滞后或周期内从自身减去的技术。
兄弟管道聚合:
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的指标。除此之外,还需要提供一个桶聚合,它将定义同级聚合将在其中运行的桶。
Average Bucket
桶平均值 计算同级聚合中指定指标的(中数)平均值
Sum Bucket
桶总和 计算同级聚合中指定指标值的总和
Min Bucket
桶最小值 计算同级聚合中指定指标的最小值
Max Bucket
桶最大值 计算同级聚合中指定指标的最大值
您可以通过单击 + Add Metrics 按钮来添加聚合。
在 Custom Label 输入域中输入字符串以更改显示标签。
点击 高级 链接来显示更多自定义选项:
JSON Input
一个文本属性,可以增加指定的 JSON 格式属性来与聚合定义合并,示例如下:
{ "script" : "doc['grade'].value * 1.2" }
| 在 Elasticsearch 1.4.3及后续版本中,这个功能需要打开 dynamic Groovy scripting。 |
这些选项是否可用取决于所选择的聚合。
点击 Options 选项卡显示字体大小下拉框。
1.6.饼图
饼图的切片大小由 metrics 聚合决定,下列聚合可用于饼图:
Count
count 聚合返回所选索引模式中元素的原始数量。
Sum
sum 聚合返回一个数值型字段的总和。从下拉框选择一个字段。
Unique Count
cardinality 聚合返回一个字段中唯一值的数量。从下拉列表选择一个字段。
在 Custom Label 字段中输入一个字符串来修改显示标签。
桶 聚合用于决定从数据集抽取何种信息。
在选择一个桶聚合之前,需要知道是否为单个图或组合图的X轴或Y轴定义桶。一个组合图必须在所有其他聚合之前执行。当划分一个图时,可以通过点击 Rows | Columns 选择器,来改变划分是显示为一行还是一列。
可以为饼图指定下列任意桶聚合:
Date Histogram
一个 date histogram 从一个数值型字段构建,并按日期组织。可以为间隔指定一个按秒、分钟、小时、天、周、月或年的时间段。也可以指定一个自定义的时间区间,只需选择 Custom 作为间隔,并在文本字段中指定一个数字和一个时间单位即可。对于自定义间隔时间单位,s 表示秒, m 表示分钟,h 表示小时, d表示天, w 表示周, y 表示年。不同单位支持不同的精度级别,最低为一秒。
Histogram
一个标准的 histogram 从一个数值型字段构建,并为该字段指定一个整数类型的间隔,选择 Show empty buckets 复选框可在直方图中包括空的间隔。
Range
通过一个 range 聚合,可以为一个数值型字段指定值的范围。点击 Add Range 增加一个范围聚合,点击红色的 (x) 符号来删除一个范围。
Date Range
date range 聚合展示在指定日期范围内的值。可通过 date math 表达式来指定日期范围。点击 Add Range 增加一个范围聚合,点击红色的 (/) 符号来删除一个范围。
IPv4 Range
IPv4 range 聚合支持指定IPV4地址范围。点击 Add Range 增加一组范围端点,点击红色的 (/) 符号移除范围。
Terms
terms 聚合支持指定要显示的给定字段的头部或尾部 n 个元素,并按数量或自定义指标进行排序。
Filters
可以为数据指定一系列 filters 。支持通过一个查询串或者 JSON 格式来指定一个过滤器,就像在 Discover 搜索框中一样。点击 Add Filter 来增加另一个过滤器。点击 label 按钮打开标签字段,输入一个可显示在视图中的名称。
Significant Terms
显示试验 significant terms 聚合的结果。Size 参数的值定义了该聚合返回的实体数量。
一旦指定了一个 bucket 类型的聚合,就可以定义子 bucket 来优化视图。点击 + Add sub-buckets 来定义一个子 bucket,然后选择 Split Rows 或 Split Table ,再从类型列表中选择一种聚合。
当在坐标轴上定义好多个聚合以后,就可以使用向上或向下键翻到合适的聚合类型,以更改聚合优先级。
点击每个标签旁边的色点来显示 颜色选择器 ,可以自定义视图的颜色。
在 Custom Label 字段输入一个字符串可修改显示标签。
可以点击 Advanced 链接显示指标或桶聚合的更多自定义选项:
Exclude Pattern
从结果中排除该字段指定的模式。
Include Pattern
在结果中包括该字段所指定的模式。
JSON Input
一个文本字段,可以通过加入指定的 JSON 格式属性与聚合定义合并,示例如下:
{ "script" : "doc['grade'].value * 1.2" }
| 在 Elasticsearch 1.4.3及以后版本中,该功能需要打开 dynamic Groovy scripting 。 |
这些选项是否可用取决于所选的聚合。
选择 Options 标签来改变表格的下列方面:
Donut
显示为切片环状图,而不是切片饼状图。
Show Tooltip
勾选此项开启显示提示语。
在修改选项后,点击 Apply changes 按钮更新视图,或者点击 Discard changes 按钮保持视图为当前状态。
1.7.Tile 地图
坐标地图显示一个地理区域,按照由您指定的数据桶确定的数据,在上面覆盖一些圆圈。
默认情况下,Kibana 使用 Elastic Tile Service 来显示地图瓦片(Tiles)。
要使用其他 Tile 服务提供商,请在 kibana.yml 中设置 tilemap 配置项。1.7.1.配置
1.7.1.1.数据
1.7.1.1.1.指标
坐标地图的默认 指标 聚合是 Count 聚合。您可以选择以下任何一项聚合作为指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
此聚合返回数值字段的平均值。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数值字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数值字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数值字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数聚合返回字段中去重之后的唯一值的数量。从下拉菜单中选择一个字段。
在 Custom Label 输入框中输入字符串以更改显示标签。
1.7.1.1.2.桶
Tile 地图使用 geohash 聚合。从下拉菜单中选择一个字段,通常是坐标(coordinates)字段。
- Change precision on map zoom(更改地图缩放的精度) 选项框默认是选中的。取消选中该选项框以禁用此行为。 Precision(精度) 滑块决定了地图上显示的结果的粒度。有关由每个精度级别指定的区域的详细信息,请参阅 geohash grid 聚合的文档。
更高的精度会增加显示 Kibana 的浏览器以及底层 Elasticsearch 集群的内存使用量。- place markers off grid(不将标记放置在网格上 (use geocentroid)) 选项框默认是选中的。选中此选框时,标记将放置在该桶中所有文档的中心。未选中时,标记将放置在 geohash 网格单元的中心。保持此项选中通常会产生更准确的可视化。
在 Custom Label 输入框中输入字符串以更改显示标签。
您可以点击 Advanced 链接为您的度量或桶聚合显示更多自定义选项:
Exclude Pattern
在此输入框中指定一个模式以从结果中排除。
Include Pattern
在此输入框中指定一个模式以包含在结果中。
JSON Input
一个文本输入框,您可以在其中添加特定的 JSON 格式的属性以与聚合定义合并,如下例所示:
{ "script" : "doc['grade'].value * 1.2" }
| 在 Elasticsearch 版本1.4.3及更高版本中,此功能要求您启用 动态 Groovy 脚本。 |
这些选项的可用性取决于您选择的聚合。
1.7.1.2.选项
Map type
从下拉列表中选择以下选项之一。
Scaled Circle Markers(缩放的圆圈标记)
根据度量聚合的值缩放标记的大小。
Shaded Circle Markers(带阴影的圆圈标记)
根据度量聚合的值显示具有不同阴影的标记。
Shaded Geohash Grid(带阴影的 Geohash 网格)
显示 geohash 网格的矩形单元格,而不是圆形标记,并根据度量聚合的值显示不同的阴影。
Heatmap(热点图)
热点图将模糊应用于圆形标记,并根据重叠量应用阴影。 热点图有以下选择:
- Radius(半径): 设置单个热点图像点的大小。
- Blur(模糊): 设置热点图像点的模糊量。
- Maximum zoom(最大缩放): Kibana中的Tilemaps支持18个缩放级别。 此滑块定义当热点图像点以全强度出现时的最大缩放级别。
- Minimum opacity(最小不透明度): 设置像点的不透明度的最小值。
- Show Tooltip(显示工具提示): 选中此选框可在光标位于点上时提供该点的值提示。
Desaturate map tiles(地图图块去饱和)
对地图颜色进行去饱和处理,以使标记更加清晰。
WMS compliant map server(符合WMS的地图服务器)
选中此选框可启用符合 Web 地图服务(WMS)标准的第三方地图服务。 指定以下元素:
- WMS URL: WMS 地图服务的 URL。
- WMS layers(WMS 图层): 在此可视化中使用的图层的逗号分隔列表。每个地图服务器都提供自己的图层列表。
- WMS version(WMS 版本): 此地图服务使用的 WMS 版本。
- WMS format(WMS 格式): 此地图服务使用的图像格式。两种最常见的格式是
image/png和image/jpeg。 - WMS attribution(WMS 来源): 用于标识地图来源的可选用户定义字符串。地图在右下角显示来源字符串。
- WMS styles(WMS 样式): 此可视化中使用的样式的逗号分隔列表。每个地图服务器都提供自己的样式选项。
更改选项后,单击 Apply changes 按钮更新可视化效果,或单击灰色的 Discard changes 按钮以将可视化保持在当前状态。
1.7.2.浏览地图
当您的 Tile 地图可视化准备就绪了,您可以通过几种方式浏览地图:
- 点击并按住地图上的任意位置并移动光标以移动地图中心。 按住 Shift 键并在地图上拖出一个边界框以放大选区。
- 点击 Zoom In/Out(缩小/放大)
 按钮手动更改缩放级别。
按钮手动更改缩放级别。 - 点击 Fit Data Bounds(适应数据边界)
 按钮自动将地图边界裁剪为至少有一个结果的 geohash 桶。
按钮自动将地图边界裁剪为至少有一个结果的 geohash 桶。 - 点击 Latitude/Longitude Filter(经度/纬度过滤器)
 按钮,然后在地图上拖出一个边界框,为框住的坐标创建过滤器。
按钮,然后在地图上拖出一个边界框,为框住的坐标创建过滤器。
1.8.时间序列可视化生成器
试验特性
时间序列可视化生成器是一个时间序列数据可视化工具,重点在于允许您使用 Elasticsearch 聚合框架的全部功能。时间序列可视化生成器允许您组合无限数量的聚合和管道聚合,以有意义的方式显示复杂的数据。
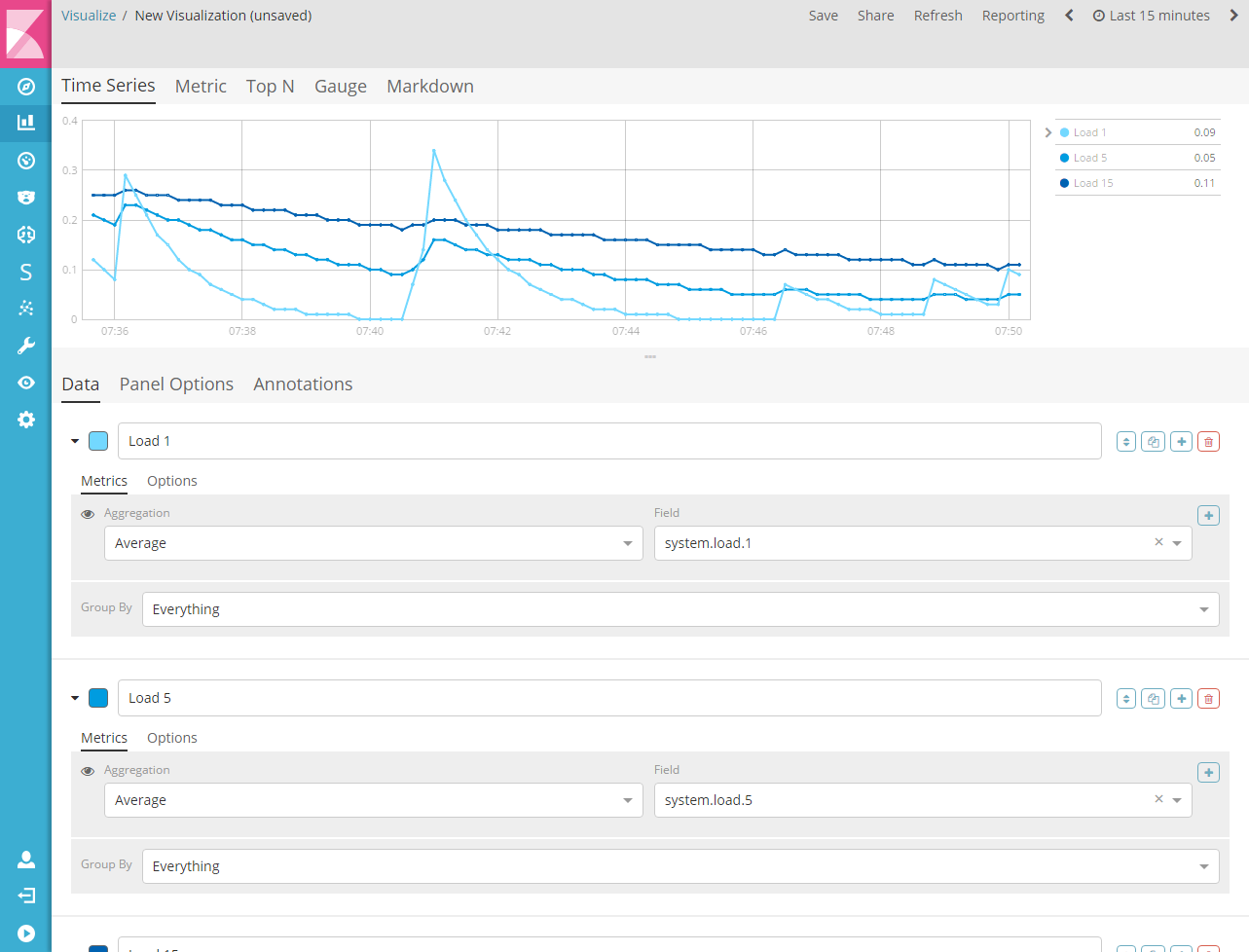
1.8.1.特色可视化
时间序列可视化构建包含5种不同的可视化类型。您可以使用界面顶部的选项卡式选取器在每种可视化类型之间切换。
1.8.1.1.时间序列
直方图可视化,支持具有多个 y 轴的区域图、线形图、条形图和步骤图。您可以完全自定义颜色、点、线条粗细和填充不透明度。该可视化还支持时间偏移来比较两个时间段。该可视化还支持注解(annotations),该注解可以基于查询从单独的索引加载。
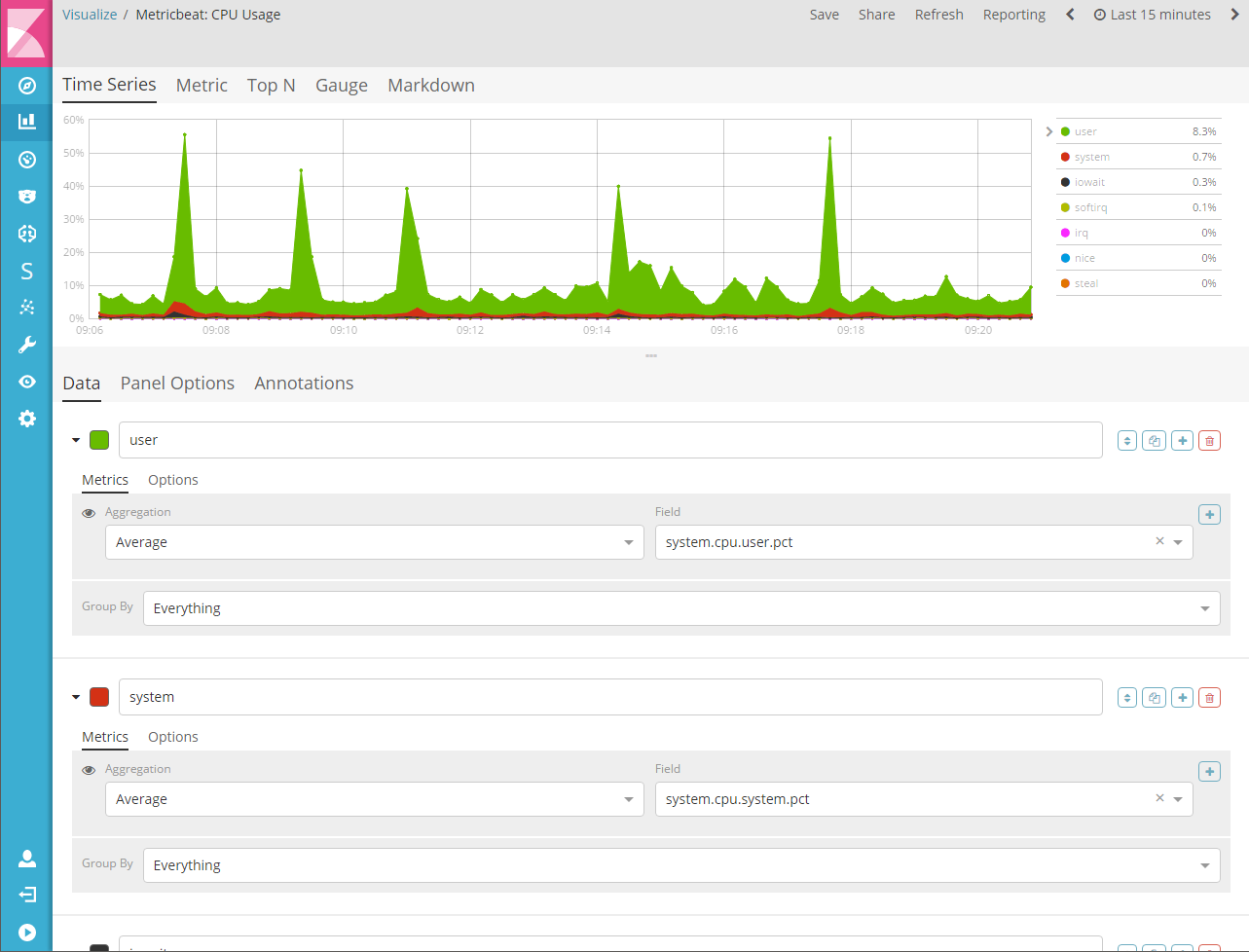
1.8.1.2.指标
用于显示系列中最新数值的可视化。该可视化支持2个指标:主要指标和次要指标。标签和背景可以根据一组规则完全自定义。
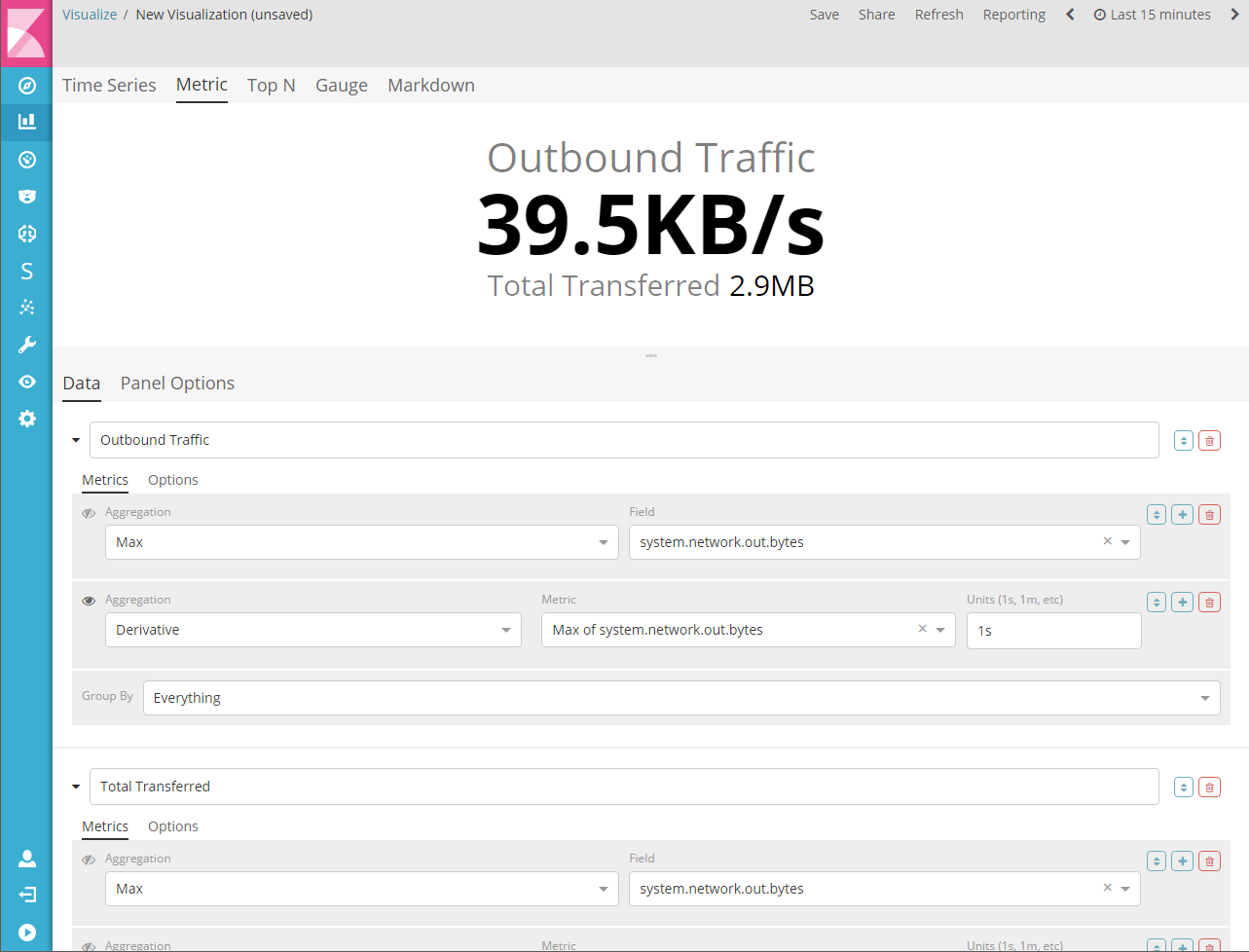
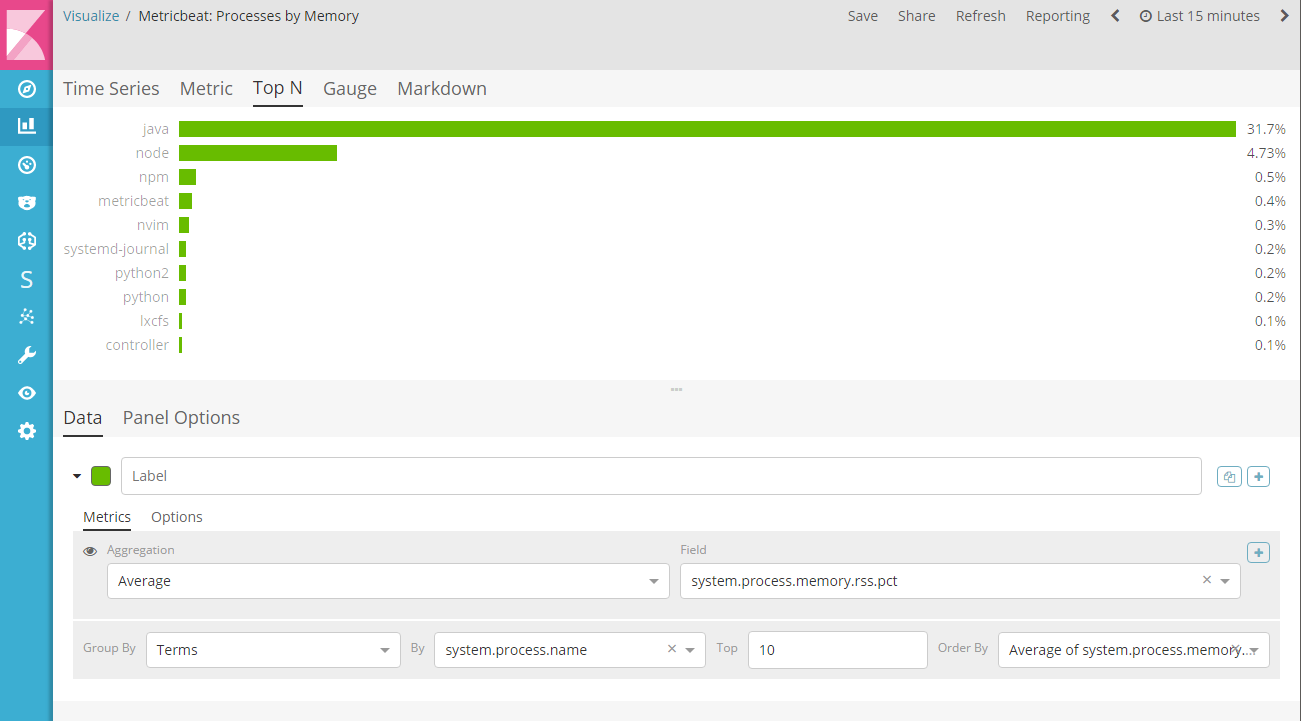
1.8.1.3.Top N
这是一个水平条形图,其中 y 轴是基于一个系列的指标,x 轴是这些系列中的最新值,按降序排列。条形的颜色可以根据一组规则完全自定义。
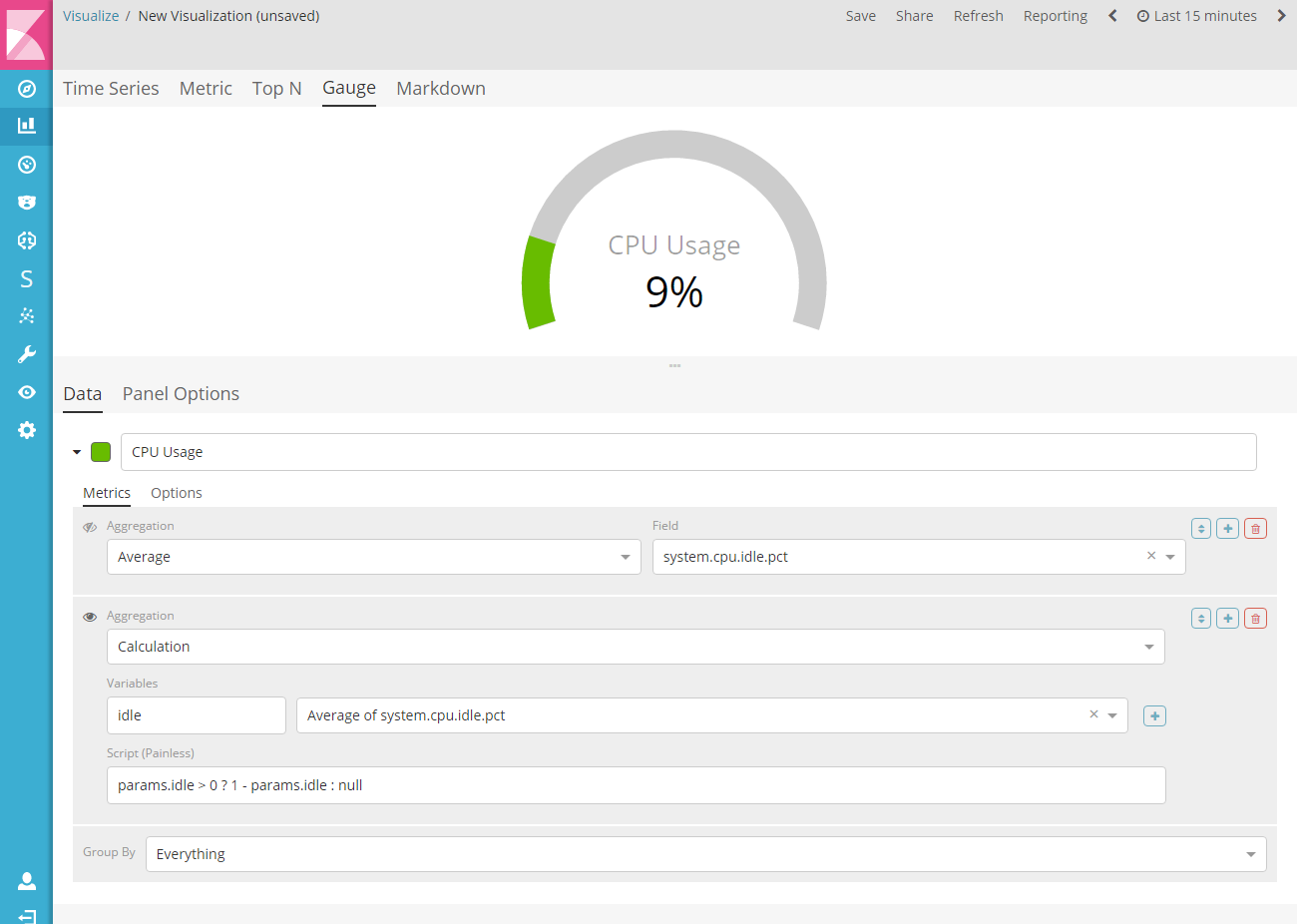
1.8.1.4.测量仪(Gauge)
这是基于系列中最新值的单值计量可视化。测量仪的面貌可以是半圆表或全圆表。您可以自定义内线和外线的厚度以达到所需的设计美学效果。测量仪和文本的颜色可根据一组规则完全自定义。
1.8.1.5.Markdown
此可视化允许您输入 Markdown 文本并嵌入 Mustache 模板语法,以基于一组系列数据自定义 Markdown。该可视化还支持 HTML 标记以及自定义样式表的功能。
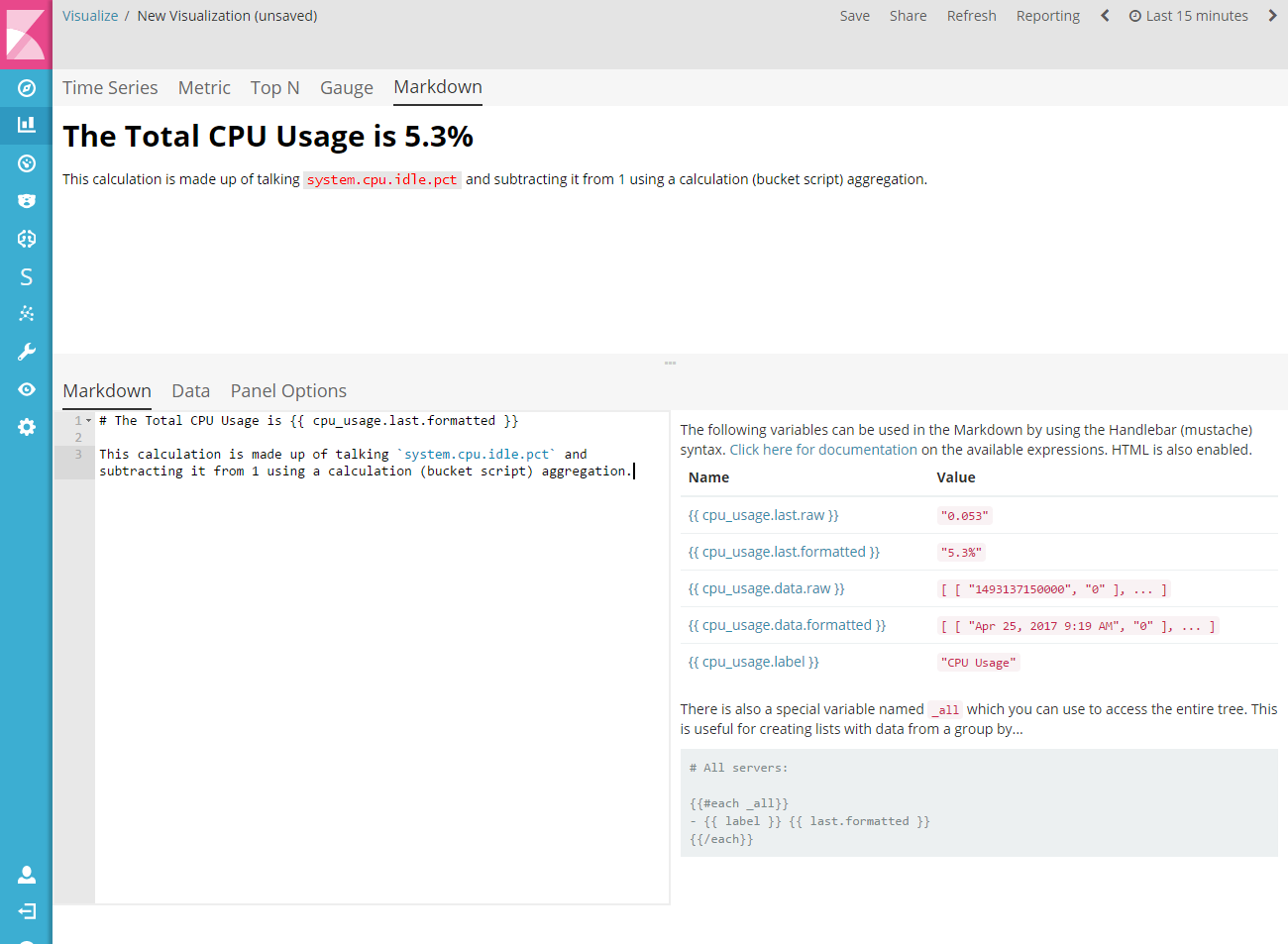
1.8.2.界面概述
每个可视化的用户界面由 Data 标签页和 Pannel Options 组成。唯一例外的是时间序列和 Markdown 可视化,时间序列具有用于 Annotations 的第三个标签页,Markdown 具有用于编辑器的第三个标签页。
1.8.2.1.数据标签页
数据标签页用于配置每个可视化的序列。此选项卡允许您根据可视化支持的内容添加多个序列,并将多个聚合组合在一起以创建单个指标。以下是数据标签页 UI 重要组件的细分。
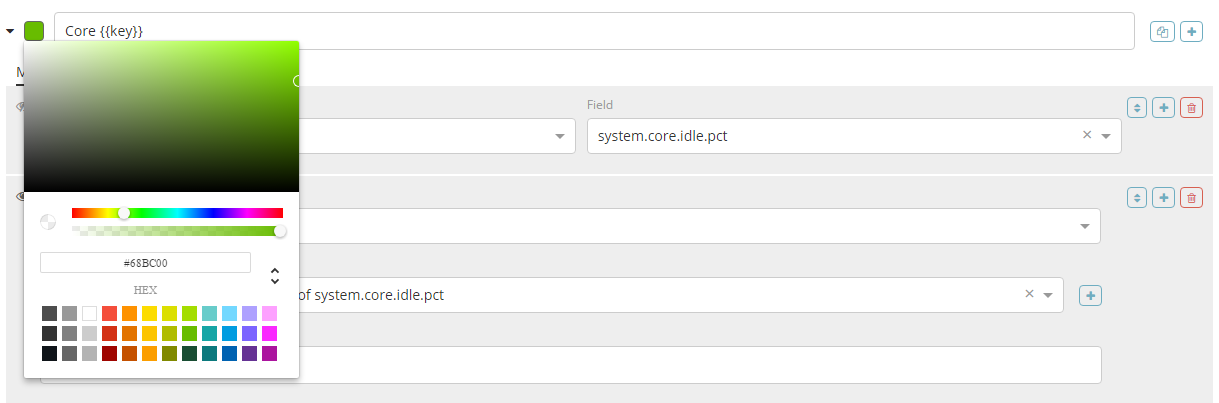
1.8.2.1.1.序列标签和颜色
每个序列都支持一个标签,该标签将用于图例和标题,具体取决于所选的可视化类型。对于按词项分组的序列,可以指定 {{key}} 的 mustache 变量以替换该词项。对于大多数可视化,您还可以通过点击色板打开颜色选择器选择一种颜色。
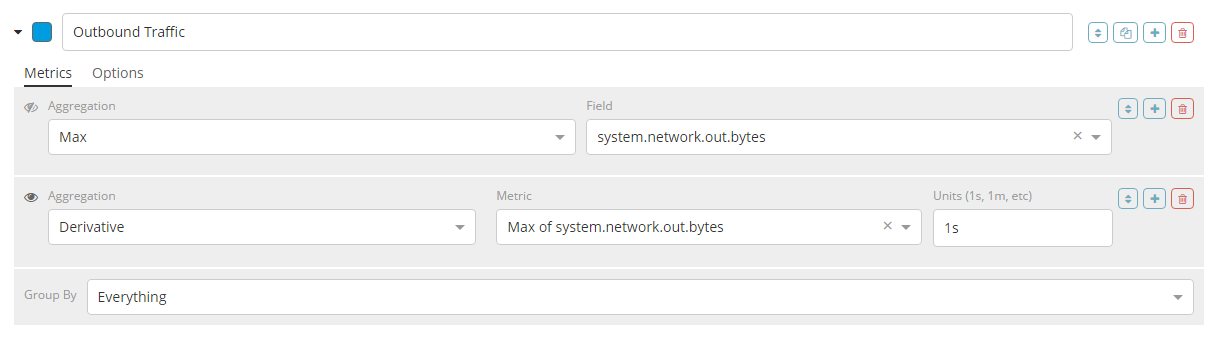
1.8.2.1.2.指标
每个序列支持多个指标(聚合); 最后一个指标(聚合)是将为该序列显示的值,用指标左侧的“眼睛”图标表示。指标可以使用管道聚合进行组合。一个常见的用例是创建一个带有“最大值”聚合的指标,然后创建一个“导数”指标,并选择之前的“最大值”指标作为源,这将会创造一个比率。
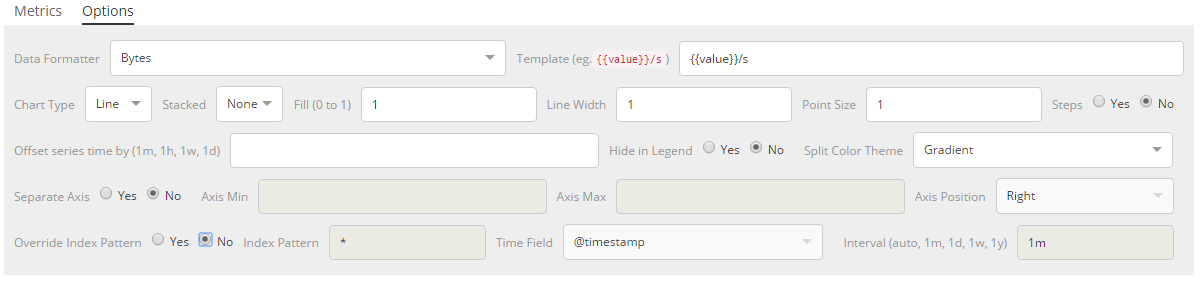
1.8.2.1.3.序列选项
每个系列还支持一组选项,这些选项取决于您选择的可视化类型。每个可视化类型通用的配置项有:
- 数据格式
- 时间范围偏移
- 索引模式、时间戳和区间覆盖

对于时间序列可视化,您还可以配置:
- 图表类型
- 每种图表类型的选项
- 图例可见性
- Y 轴选项
- 分色主题
1.8.2.1.4.分组控件
在指标的底部有一组“分组依据”控件,允许您指定该序列应该如何分组或拆分。有四种选择:
- 所有
- 过滤器(单个)
- 过滤器(可配置颜色的多个)
- 词项
默认情况下,系列按照所有进行分组。
1.8.2.2.面板选项标签页
面板选项标签页用于配置整个面板,可用选项集取决于您选择的可视化。以下是每个可视化可用的选项列表:
时间序列
- 索引模式、时间戳和区间
- Y 轴最小值和最大值
- Y 轴位置
- 背景颜色
- 图例可见性
- 图例位置
- 面板过滤器
指标
- 索引模式、时间戳和区间
- 面板过滤器
- 背景和主要值的颜色规则
Top N
- 索引模式、时间戳和区间
- 面板过滤器
- 背景颜色
- 项目 URL
- 条形的颜色规则
测量仪
- 索引模式、时间戳和区间
- 面板过滤器
- 背景颜色
- 测量仪最大值
- 测量仪样式
- 内规颜色
- 内规宽度
- 规线宽
- 规线颜色规则
Markdown
- 索引模式、时间戳和区间
- 面板过滤器
- 背景颜色
- 滚动条可见性
- 内容垂直对齐
- 自定义面板 CSS 支持 Less 语法
1.8.2.3.Annotations 标签页
注解标签页用于将注解数据源添加到时间序列可视化中。您可以配置以下选项:
- 索引模式和时间字段
- 注解颜色
- 注解图标
- 包含在消息中的字段
- 消息的格式
- 面板和全局级别的过滤选项
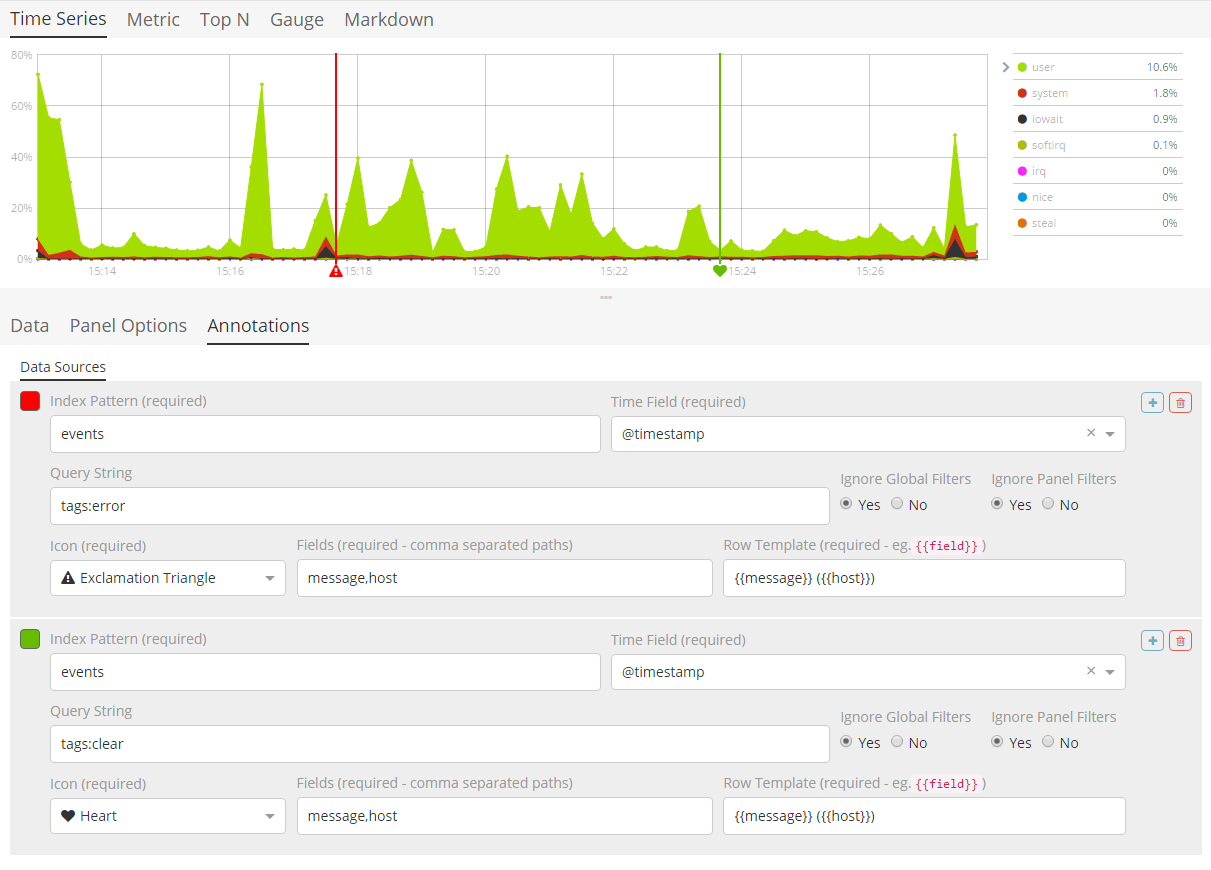
1.8.2.4.Markdown 选项卡
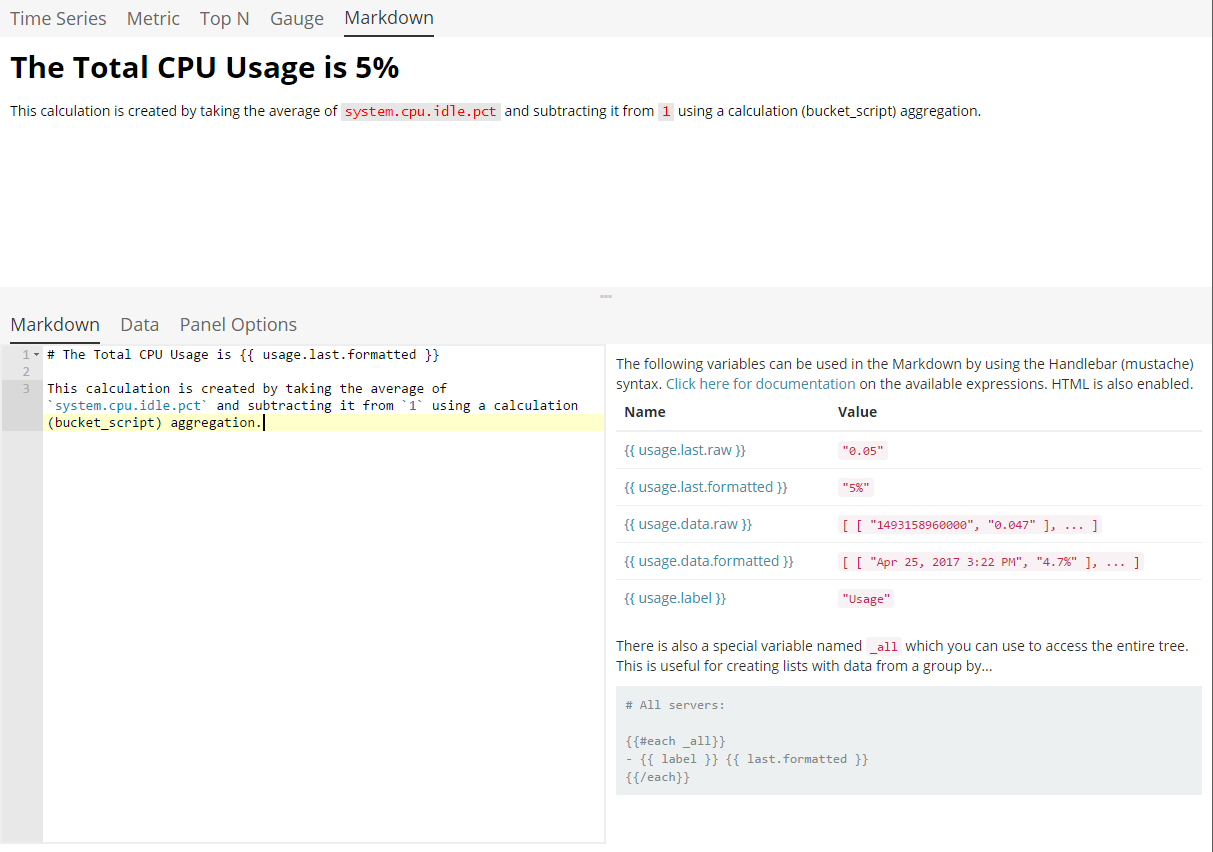
Markdown 标签页用于编辑 Markdown 可视化的源代码。用户界面左侧有一个编辑器,右侧有数据标签页中的可用变量。您可以单击变量名称将 Mustache 模板变量插入到光标位置的标记中。Mustache 语法使用 Handlebar.js 处理器,它是 Mustache 模板语言的扩展版本。
1.9.标签云
标签云视图是文本数据的一种可视化表示,通常用来可视化自由形式的文本。标签一般是单独的词,每个标签的重要程度通过字体大小或颜色来表示。
每个词的字体大小,是由 指标 聚合来决定的。下列聚合可用于这个图:
指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
该聚合返回数字字段的平均值 。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数字字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数字字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数字字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数 聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。
Standard Deviation
扩展统计 聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。
Percentiles
百分数 聚合将数字字段中的值分成您指定的百分数区间。从下拉列表中选择一个字段,然后在 Percentiles输入域中指定一个或多个范围。点击 X 删除百分数字段。点击 + Add 添加百分数字段。
Percentile Rank
百分位等级 聚合返回指定的数值字段中的值的百分位等级。从下拉菜单中选择一个数字字段,然后在 Values 输入域中指定一个或多个百分比等级值。点击 X 删除值字段。点击 + Add 添加值字段。
父级管道聚合:
对于每个父管道聚合,您必须定义用于计算聚合的指标。这可能是您现有的指标之一或新的指标。您也可以嵌套这些聚合(例如产生3阶导数)。
Derivative
导数 聚合计算特定指标的导数。
Cumulative Sum
累计总和 聚合计算父直方图中指定指标的累计总和。
Moving Average
移动平均值 聚合将动态移动数据窗口,生成该窗口数据的平均值。
Serial Diff
串行差分 是一种时间序列中的值在不同时间滞后或周期内从自身减去的技术。
兄弟管道聚合:
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的指标。除此之外,还需要提供一个桶聚合,它将定义同级聚合将在其中运行的桶。
Average Bucket
桶平均值 计算同级聚合中指定指标的(中数)平均值
Sum Bucket
桶总和 计算同级聚合中指定指标值的总和
Min Bucket
桶最小值 计算同级聚合中指定指标的最小值
Max Bucket
桶最大值 计算同级聚合中指定指标的最大值
您可以通过单击 + Add Metrics 按钮来添加聚合。
在 Custom Label 输入域中输入字符串以更改显示标签。
桶 聚合决定了需要从数据集中抽取哪些信息。
在选择一个桶聚合前,要勾选 Split Tags 选项。
可以为标签云视图指定下列桶聚合:
Terms
一个 terms 聚合支持显示给定字段的前面或后面的 n 个元素,并按数量或自定义指标排序。
点击 Advanced 链接可以显示该指标或桶聚合的更多自定义选项:
JSON Input
这是一个文本字段,支持增加特定的 JSON 格式属性合并到聚合定义中,见下述例子:
{ \"script\" : \"doc[\'grade\'].value * 1.2\" }
注意:在 Elasticsearch 1.4.3及以后的版本中,这个功能需要打开 动态 Groovy 脚本 。
选择 Options 标签来改变下列图形的方向:
Text Scale
可以选择 linear*、 *log 或 square root 作为文本比例。可以使用对数比例来显示指数变化的数据,或者使用平方根比例来归一化显示包含自身波动很大的变量的数据集。
Orientation
支持选择在标签云中如何定位文本,可以选择下列选项之一:
单个、直角和多个。
Font Size
支持设置视图的最小和最大字体大小。
1.10.热点图
热点图是数据的一种图形化表示,该图中使用颜色来表示矩阵所包含的单个数值。每个矩阵位置的颜色由 (指标)metrics 聚合来决定。热点图支持以下聚合:
指标聚合:
Count
计数 聚合返回所选索引模式中元素的原始计数。
Average
该聚合返回数字字段的平均值 。从下拉菜单中选择一个字段。
Sum
总和 聚合返回数字字段的总和。从下拉菜单中选择一个字段。
Min
最小值 聚合返回数字字段的最小值。从下拉菜单中选择一个字段。
Max
最大值 聚合返回数字字段的最大值。从下拉菜单中选择一个字段。
Unique Count
基数 聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。
Standard Deviation
扩展统计 聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。
Percentiles
百分数 聚合将数字字段中的值分成您指定的百分数区间。从下拉列表中选择一个字段,然后在 Percentiles输入域中指定一个或多个范围。点击 X 删除百分数字段。点击 + Add 添加百分数字段。
Percentile Rank
百分位等级 聚合返回指定的数值字段中的值的百分位等级。从下拉菜单中选择一个数字字段,然后在 Values 输入域中指定一个或多个百分比等级值。点击 X 删除值字段。点击 + Add 添加值字段。
父级管道聚合:
对于每个父管道聚合,您必须定义用于计算聚合的指标。这可能是您现有的指标之一或新的指标。您也可以嵌套这些聚合(例如产生3阶导数)。
Derivative
导数 聚合计算特定指标的导数。
Cumulative Sum
累计总和 聚合计算父直方图中指定指标的累计总和。
Moving Average
移动平均值 聚合将动态移动数据窗口,生成该窗口数据的平均值。
Serial Diff
串行差分 是一种时间序列中的值在不同时间滞后或周期内从自身减去的技术。
兄弟管道聚合:
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的指标。除此之外,还需要提供一个桶聚合,它将定义同级聚合将在其中运行的桶。
Average Bucket
桶平均值 计算同级聚合中指定指标的(中数)平均值
Sum Bucket
桶总和 计算同级聚合中指定指标值的总和
Min Bucket
桶最小值 计算同级聚合中指定指标的最小值
Max Bucket
桶最大值 计算同级聚合中指定指标的最大值
您可以通过单击 + Add Metrics 按钮来添加聚合。
在 Custom Label 输入域中输入字符串以更改显示标签。
桶 聚合决定需要从数据集抽取何种信息。
在选择一个桶聚合之前,需要知道是否为单个图或组合图的X轴或Y轴定义桶。一个组合图必须在所有其他聚合之前执行。当划分一个图时,可以通过点击 Rows | Columns 选择器,来改变划分是显示为一行还是一列。
该图的X轴和Y轴支持下面的聚合,点击每个聚合的链接名称查看对应聚合的 Elasticsearch 文档。
Date Histogram
一个 date histogram 从一个数值型字段构建,并按日期组织。可以为间隔指定一个按秒、分钟、小时、天、周、月或年的时间段。也可以指定一个自定义的时间区间,只需选择 Custom 作为间隔,并在文本字段中指定一个数字和一个时间单位即可。对于自定义间隔时间单位,s 表示秒, m 表示分钟,h 表示小时, d表示天, w 表示周, y 表示年。不同单位支持不同的精度级别,最低为一秒。
Histogram
一个标准的 histogram 从一个数值型字段构建,并为该字段指定一个整数类型的间隔,选择 Show empty buckets 复选框可在直方图中包括空的间隔。
Range
通过一个 range 聚合,可以为一个数值型字段指定值的范围。点击 Add Range 增加一个范围聚合,点击红色的 (x) 符号来删除一个范围。
Date Range
date range 聚合展示在指定日期范围内的值。可通过 date math 表达式来指定日期范围。点击 Add Range 增加一个范围聚合,点击红色的 (x) 符号来删除一个范围。
IPv4 Range
IPv4 range 聚合支持指定IPV4地址范围。点击 Add Range 增加一组范围端点,点击红色的 (x) 符号移除范围。
Terms
terms 聚合支持指定一个给定字段的头部或尾部 n 个元素来显示,并通过数量或自定义指标排序。
Filters
可以为数据指定一系列 filters 。支持通过一个查询串或者 JSON 格式来指定一个过滤器,就像在Discover搜索框中一样。点击 Add Filter 来增加另一个过滤器。点击 label 按钮打开标签字段,输入一个可显示在视图中的名称。
Significant Terms
显示试验 significant terms 聚合的结果。
在 Custom Label 字段输入一个字符串可修改显示标签。
点击 Advanced 链接显示指标或桶聚合的更多自定义选项:
Exclude Pattern
从结果中排除该字段指定的模式。
Include Pattern
在结果中包括该字段所指定的模式。
JSON Input
一个文本字段,可以通过加入指定的 JSON 格式属性与聚合定义合并,示例如下:
{ "script" : "doc['grade'].value * 1.2" }
这些选项是否可用取决于所选的聚合。
选择 Options 标签来改变表格的下列方面:
Show Tooltips
勾选此项支持显示提示语。
Highlight
勾选此项支持高亮相同标签的原色。
Legend Position
选择在何处显示图例(上、左、右、下)。
Color Schema
可以选择已有配色方案,或者自定义自己的颜色图例。
Reverse Color Schema
勾选此项将翻转配色方案。
Color Scale
可以切换为 linear、log 及 sqrt 的颜色范围。
Scale to Data Bounds
默认的Y轴边界是0到返回数据中的最大值。勾选此项可以更新上下边界来适应实际数值。
Number of Colors
创建的颜色桶数量。最小为2最大为10。
Percentage Mode
打开时将会以百分比形式显示图例值。
Custom Range
可以为颜色桶自定义范围。对于每个颜色桶,需要指定一个范围的最小值(包括)和最大值(不包括)。
Show Label
在每个单元格中与数值一起显示标签。
Rotate
将单元格数值的标签旋转90度。
1.11.可视化监测
为了查看可视化容器背后的原始数据,点击容器左下方  按钮,可视化监测窗口将会打开。可以选中查看原始数据详情。
按钮,可视化监测窗口将会打开。可以选中查看原始数据详情。
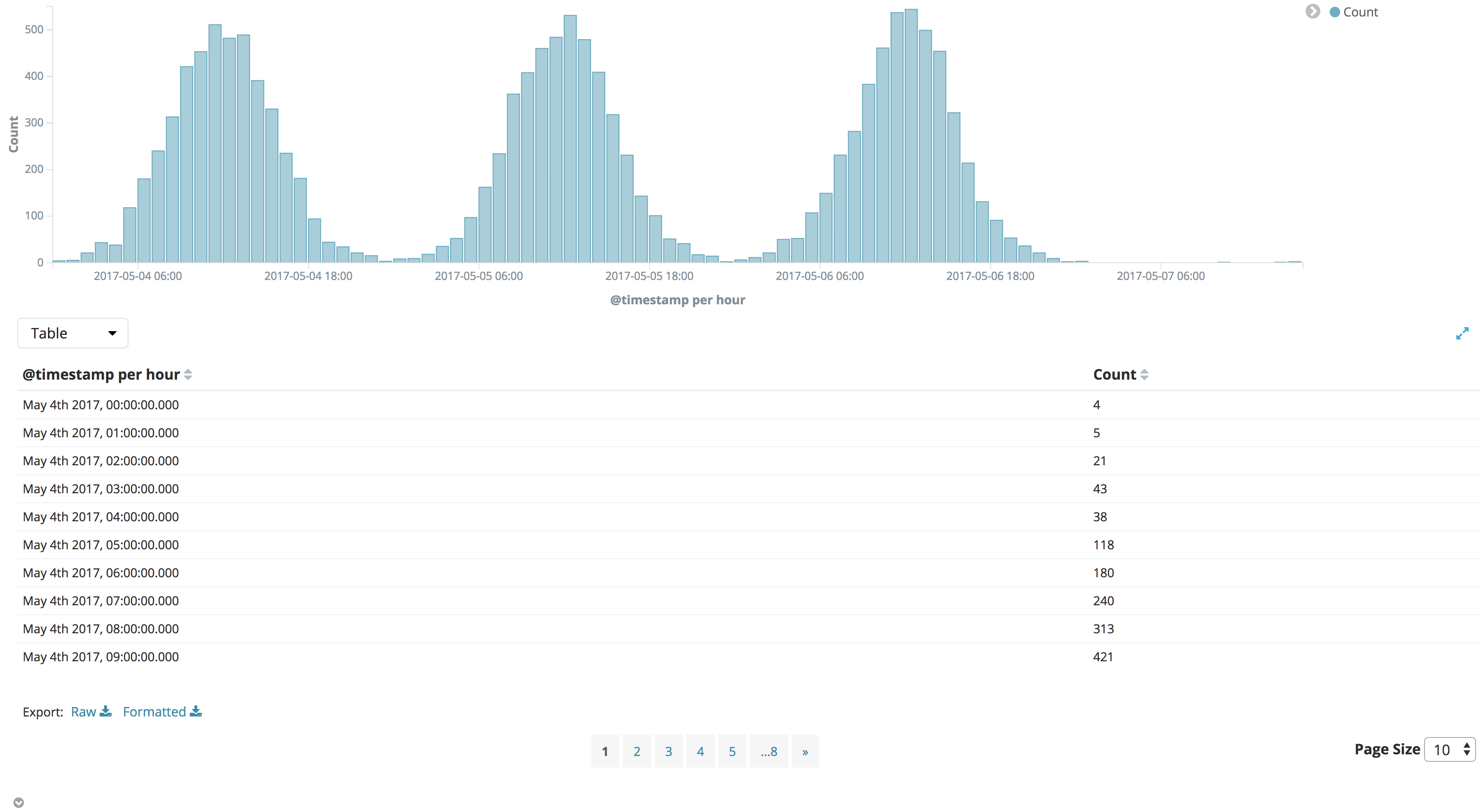
表格. 分页表格形式呈现的基础数据。可以点击表头每行字段名的上下箭头来按照该列排序。
请求. 服务器原始请求数据,以 JSON 形式呈现。
响应. 服务器原始响应数据,以 JSON 形式呈现。
统计. 请求和响应的统计汇总数据,以表格形式呈现。包括查询周期,请求周期,查询到的记录数以及用于查询的索引模板。
调试. 以 JSON 形式保存的可视化容器的状态。
将可视化数据以逗号分割值的形式导成(cvs)文件,点击数据表底部的 Raw 或者 Formatted 链接。 Raw 导出 Elasticsearch 存储格式的数据。 Formatted 导出格式化好的数据,详情参考 field formatters。
Kibana【从无到有从有到无】【搜索引擎】【K4】可视化相关推荐
- Apache Spark【从无到有从有到无】【编程指南】【AS5】结构化流编程指南
目录 1.概观 2.快速示例 3.编程模型 3.1.基本概念 3.2.处理事件时间和延迟数据 3.3.容错语义 4.使用数据集和数据框架的API 4.1.创建streaming DataFrames ...
- Logstash【从无到有从有到无】【简介】【L2】Logstash入门
目录 1.Logstash入门 1.1.安装Logstash 1.1.1.从下载的二进制安装 1.1.2.从包存储库安装 1.1.3.使用Homebrew在Mac上安装Logstash 1.1.4.使 ...
- Logstash【从无到有从有到无】【L2】Logstash入门
目录 1.Logstash入门 1.1.安装Logstash 1.1.1.从下载的二进制文件安装 1.1.2.从包存储库安装(Package Repositories) 1.1.3.APT 1.1.3 ...
- Apache HBase【从无到有从有到无】【AH8】RegionServer调整大小的经验法则
目录 RegionServer调整大小的经验法则 1.关于列族的数量 1.1.ColumnFamilies的基数 2.Rowkey设计 2.1.热点发现(Hotspotting) 2.2.单调增加行键 ...
- Apache HBase【从无到有从有到无】【AH4】Apache HBase配置
目录 1.Apache HBase配置 1.1.配置文件 1.2.基本先决条件 1.2.1.操作系统实用程序 1.2.2.Hadoop 1.2.2.1.dfs.datan
- Logstash【从无到有从有到无】【L20】编解码器插件(Codec plugins)
1.编解码器插件 编解码器插件可更改事件的数据表示形式. 编解码器本质上是流过滤器,可以作为输入或输出的一部分进行操作. 下面提供了以下编解码器插件. 有关Elastic支持的插件的列表,请查阅Sup ...
- Logstash【从无到有从有到无】【L24】贡献了Java插件
目录 1.贡献了Java插件 1.1.流程概述 1.2.如何编写Java输入插件 1.2.1.设置环境 1.2.2.代码插件 1.2.3.打包和部署 1.2.4.与Java输入插件运行Logstash ...
- 从低代码到无代码:可视化逻辑编排
点击上方 程序员成长指北,关注公众号 回复1,加入高级Node交流群 背景介绍 近年来,关于低代码(LowCode)和无代码(NoCode)的讨论在前端社区内越来越火,简单的说低代码就是通过编写少量代 ...
- 微服务8--ELasticsearch搜索引擎
代码参考: Gitee:cloudcode: Java微服务技术学习指南 - Gitee.com GitHub:https://github.com/lexinhu/cloudcode/tree/ma ...
最新文章
- 【c语言】蓝桥杯算法训练 1的个数
- 聊聊flink的AscendingTimestampExtractor
- 『转』Photoshop中改进ios设计流程的30个诀窍
- SAP UI5 初学者教程之三:开始接触第一个 SAP UI5 控件 试读版
- 新鲜抓取古文赏析五千篇
- elementUI vue 编辑中的input的验证残留清除
- Shit和trash不是评价设计的词汇
- dubbo使用nacos作为注册中心
- cad多线段长度计算总和_没想到啊,我平时用的CAD多段线有这么多学问
- 3-37Pytorch与torchvision
- python动态视频下载器
- mybatis中mysql递归查询多级_mybatis+mysql递归查询
- WinRAR去广告实现
- Java语言 随机点名程序
- ID Ransomware帮你识别到底中了什么勒索软件
- 移动App模块化设计
- Camera硬件结构组成
- Java_obj(一)
- 机器学习(一)——BP、RBF(径向基)、GRNN(广义回归)、PNN(概率)神经网络对比分析(附程序、数据)
- 微软急疯了?部分用户称PC自动升级到Win10
热门文章
- 基于物联网图像识别的SF6环网柜气压监测系统
- signature=07da782715954d48aa05e9d49faf92a9,ndls-20201029
- 一文掌握Flutter for Windows桌面端稳定版新特性
- 计算机非全日制有用吗,计算机在职研究生还会有用吗?
- 台式计算机一般多大功率,电脑的功率有多大,台式电脑的功率是多少
- Android Studio 下安卓 jni 开发错误 undefined reference to AndroidBitmap_getInfo
- 【转自知乎】软件实施工程师技能要求
- Python小例子——BMR计算器
- esp32-pico-d4问题
- 1.24UPC寒假个人训练第12场