ERNIE,ERNIE2.0,Transformer-XL,XLNET
文章目录
- ERNIE
- 实体级别的Mask
- 其他细节
- Dialog embedding
- 与bert对比
- ERNIE 1.0 做了什么
- ERNIE 2.0
- 整体框架
- 连续多任务学习
- 任务一:词法级别预训练任务
- 任务二:语言结构级别预训练任务
- 任务三:语法级别预训练任务
- 结论
- Transformer-XL
- Vanilla Transformer Language Models
- Transformer-XL:循环机制
- Transformer-XL:传递方式
- Transformer-XL:相对位置编码
- Transformer-XL:最终形态
- 总结
- XLNet
- AR & AE
- **自回归语言模型(Autoregressive LM**)**GPT**类的模型
- **自编码语言模型(Autoencoder LM)**BERT类的模型
- Permutation Language Modeling——一种基于排列组合的输入方法
- 双流自注意力
- 训练方法
- 与Bert比较
- 参考
ERNIE
- ERNIE: Enhanced Representation through Knowledge Integration (Baidu)
贡献:通过实体和短语mask能够学习语法和句法信息的语言模型,在很多中文自然语言处理任务上达到state-of-the art。
方法:与bert类似
训练数据集:中文维基百科,百度百科,百度新闻,百度贴吧
参数: L = 12,H = 768,A = 12 (BERT BASE)
实体级别的Mask
人名,地名,专有名词等都可以作为实体。
下图可以看出,a series of是一个短语,那么就要连续一起mask。后面的也是一样。
为什么只是mask而没有把实体作为输入,预测实体输出?原因就是实体的种类太多了,OOV,准确率不高。
![]()
不同级别的mask(单字、实体、短语)
![]()
![]()
其他细节
中文繁体->简体
英文大写->小写
词表大小17964
Dialog embedding
输入层使用多轮对话修改NSP任务(random replace 构造负样本)
![]()
与bert对比
![]()
ERNIE 1.0 做了什么
- 更多的中文语料语料
- 实体级别的连续Mask——>改变了训练Task。改变了训练的任务。
- 能否通过重新设计Task提升效果?
ERNIE 2.0
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding (Baidu)
贡献:
- 多任务持续学习预训练框架 ERNIE 2.0
- 构建三种类型的无监督任务,训练模型并刷新GLUE
- Fine-tuning code & English model
数据更多: Reddit 搜索数据等
参数与BERT一致
整体框架
![]()
连续多任务学习
![]()
不遗忘之前的训练结果
多任务高效的进行训练
使用上一任务的参数,并且新旧任务一起训练
将每个任务分成多次迭代,框架完成不同迭代的训练自动分配
多任务训练
Sentence level loss & word level loss
每个任务有独立的loss function, sentence task 可以和word task 一起训练。
模型结构
![]()
任务一:词法级别预训练任务
Knowledge Masking Task(ERNIE 1.0):学习当前和全局依赖
Capitalization Prediction Task:大写用于专名识别等,小写也可用在其他任务
Token-Document Relation Prediction Task:token存在段落A中,是否token会在文档的段落B中出现
任务二:语言结构级别预训练任务
Sentence Reordering Task:文档中的句子打乱(分成1到m段,shuffle),识别正确顺序
Sentence Distance Task:句子间的距离,3分类任务
0 相连的句子
1同一文档中不相连的句子
2两篇文档间的句子
任务三:语法级别预训练任务
Discourse Relation Task:计算两句间的语义与修辞关系(转折,因果)
IR Relevance Task:短文本信息检索关系(百度的核心)
Query-title (搜索数据)
0:搜索并点击
1:搜索并展现
2:无关,随机替换
结论
目前来看最好的中英文预训练语言模型之一
https://gluebenchmark.com/leaderboard
等待模型的放出或云服务•目前来看最好的中英文预训练语言模型之一
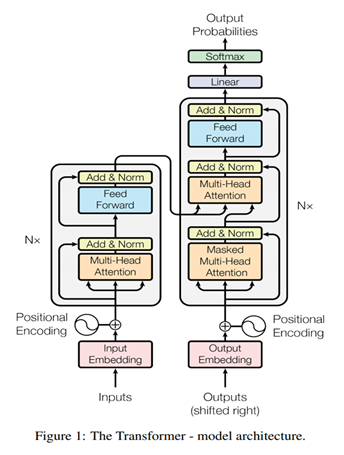
Transformer-XL
Transformer:
优点:并行,长距离依赖,
缺点:位置信息,就算引入了postionEmbedding,也是人为标注的位置。
RNN:
优点:天然的位置,时序的表达。
Transformer 结合 RNN -> Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(Google)(ICLR 2019 被拒)
解决长文本的建模,捕获超长距离依赖
LSTM 200 ,Transformer 512
贡献:循环的transformer建模机制,一种相对位置编码方式
Vanilla Transformer Language Models
![]()
长文本输入->切分Segment
问题:
最长依赖取决于segment长度
不同segment之间不传递信息
固定大小切分造成语义碎片
Transformer-XL:循环机制
将上一个分片的信息通过一个memory传到下一个分片
![]()
Transformer-XL:传递方式
![]()
信息传递方式:
- 下一层接受上一层的信息
- 下一层接受上一时刻的上层信息
- 通过拼接实现
![]()
Transformer-XL:相对位置编码
为什么要用相对位置编码?因为分片了。第二片的第一位和第一片的第一位相同。
Transformer 原始位置编码的问题:
将attention中QK展开dei’da得到![]()
- a :词之间的attention关系
- b :位置与词的关系
- c :词与位置的关系
- d :全局位置之间的关系
改变编码方式
思路:
- R_(i-j)代替U,只注意相对的距离。R:正弦信号编码矩阵,不需要学习。
- 引入一个可训练的参数项u、v
- 设计2个权重矩阵W_(k,E),W_(k,R)分别生成content-based的key vectors和location-based的key vectors。
![]()
(a) content-base的定位
(b) 捕获content-dependent的位置bias
© 控制全局的content bias
(d) 全局位置bias的编码
Transformer-XL:最终形态
变化不是特别大,就是h需要接受上一个memory的数据并且不要把梯度回传。改变了位置编码
 +
+![]()
总结
优点
- 在几种不同的数据集(大/小,字符级别/单词级别等)均实现了最先进的语言建模结果。
- 结合了深度学习的两个重要概念——循环机制和注意力机制,解决长距离依赖的问题
- 学习的依赖关系大约比 RNN 长 80%,比 Vanilla Transformer 长 450%
- inference阶段非常快,比之前最先进的利用Transformer模型进行语言建模的方法快300~1800倍。
不足
- 未在具体的NLP任务如情感分析、QA等上应用。
- 没有给出与其他的基于Transformer的模型,如BERT等,对比有何优势。
- 训练模型需要用到大量的TPU资源(循环机制)。
XLNet
XLNet:Generalized Autoregressive Pretraining for Language Understanding(Google)
类bert模型,在20 个任务上超过了 BERT 的表现,并在 18 个任务上取得state-of-the-art
AR & AE
自回归语言模型(Autoregressive LM)GPT类的模型
根据上文内容预测下一个可能的单词,自左向右的语言模型任务(或自右向左,单向)
**缺点:**只能利用上文或者下文的信息
**优点:**可以完成生成类NLP任务
![]()
**自编码语言模型(Autoencoder LM)**BERT类的模型
根据上下文单词来预测这些被Mask掉的单词(噪音)。
**优点:**双向语言模型,
**缺点:**预训练阶段和Fine-tuning阶段不一致
m t m_t mt标识mask?1:0。
![]()
XLNet的出发点:融合两者的优点。
Permutation Language Modeling——一种基于排列组合的输入方法
比如有4个输入,就有4的阶乘的输入组合。
不会改变原始词的顺序。实现是通过Attention的Mask来对应不同的分解方法
![]()
目标
![]()
双流自注意力
任务:
- 预测后面的字符是哪个
- 预测自己到底是哪个字符
两套表征方式
- Content Stream Attention:和Bert、Transformer是一样的
- Query Stream Attention:只关注位置,不关注信息。
橙色的点标识知道的信息,白色标识不知道信息,按照输入的顺序,2知道3,4知道3和2。第一行标识1知道的信息。第二含表示2知道的信息,依次类推。
![]()
加入位置作为预测信息:
z t z_t zt位置信息。
![]()
两种Attention的构造:
![]()
训练方法
数据输入:50%的概率是连续的句子(前后语义相关),有50%的概率是不连续(无关)的句子。
对于排列组合的数据,用随机采样的方式选取数据。阶乘数据太多了。
CLS放在最后,可以收集更多的信息。
为了减少计算量,只预测1/k个Token,k=6或者7。
与Bert比较
XLNet预测部分词是出于性能考虑,而BERT是随机的选择一些词来预测
尽量规避Bert的独立假设,如下
![]()
参考
Transformer-XL
https://arxiv.org/pdf/1901.02860.pdf
XLNet
https://arxiv.org/pdf/1906.08237.pdf
https://github.com/zihangdai/xlnet
中文XLNet预训练模型
https://github.com/ymcui/Chinese-PreTrained-XLNet
ERNIE,ERNIE2.0,Transformer-XL,XLNET相关推荐
- JAVA计算:用 100 元钱买 100 支笔,其中钢笔 3 元 / 支,圆珠笔 2 元 / 支,铅笔 0.5 元 / 支,问钢笔、圆珠笔和铅笔可以各买多少支 ?
Java 计算 用 100 元钱买 100 支笔,其中钢笔 3 元 / 支,圆珠笔 2 元 / 支,铅笔 0.5 元 / 支,问钢笔.圆珠笔和铅笔可以各买多少支 ? 穷举法,用JAVA写了一下,代码很 ...
- 三星9500android 8.0,三星note 8 高通835 N9500(国行、港行),8.0的安卓版本,可以自行安装xposed框架...
目前三星note 8 高通835(国行.港行),8.0的安卓版本,可以自行安装xp框架了,是xp框架本身就支持8.0 看到不少同学在询问安装框架的方法,分享一下个人的安装流程,稍后整理一下,附上一些工 ...
- Multi-task Learning in LM(多任务学习,PLE,MT-DNN,ERNIE2.0)
提升模型性能的方法有很多,除了提出过硬的方法外,通过把神经网络加深加宽(深度学习),增加数据集数目(预训练模型)和增加目标函数(多任务学习)都是能用来提升效果的手段.(别名Joint Learning ...
- 自己挖坑自己填,谷歌大改Transformer注意力,速度、内存利用率都提上去了
机器之心报道 机器之心编辑部 考虑到 Transformer 对于机器学习最近一段时间的影响,这样一个研究就显得异常引人注目了. Transformer 有着巨大的内存和算力需求,因为它构造了一个注意 ...
- 空间注意力机制sam_自己挖坑自己填,谷歌大改Transformer注意力,速度、内存利用率都提上去了...
考虑到 Transformer 对于机器学习最近一段时间的影响,这样一个研究就显得异常引人注目了. 机器之心报道,机器之心编辑部. Transformer 有着巨大的内存和算力需求,因为它构造了一个注 ...
- Notification的学习,4.0前后的差别,和在设置声音的时候获取资源的uri方法
android 4.0 前后很多api都有了较大的差别,不多说现在学习下notification前后实现的差别,本文参考了 :http://my.oschina.net/ososchina/blog/ ...
- 汇编程序—将一个全是字母,以0结尾的字符串,转化为大写
程序思路 我们有一个现成的指令jcxz 可以判断cx寄存器中是否0,可以将data段的数据一个一个放到cx中,紧接着调用jcxz指令,如果cx为0 跳出子程序,如果不为0进行大写转化! 这里为了方便展 ...
- 洛谷P1134阶乘问题(数论,末尾0的个数变形,思维转换)
题目链接:https://www.luogu.org/problemnew/show/P1134 读完这道题发现它和51nod1003阶乘后面0的数量非常相似,只不过它变形了一下,要求你对2*5产生0 ...
- 捷信Q1经营大幅下滑,净利润0.3亿元,不良率走高
作者 | 库昊 来源 | 见闻财经 受疫情影响,众多金融机构在今年一季度业绩都受到影响,而较为依赖线下渠道展业的持牌消金机构捷信消费金融(以下简称"捷信"),其业绩更是受到较大冲击 ...
最新文章
- PHP根据时间戳返回星期几
- python抖音批量点赞_python抖音三百条,悠悠一笑乐逍遥
- OpenStack基金会的白金和黄金成员公司
- linux 信号处理
- 《南溪的目标检测学习笔记》——验证模式下出现“Process finished with exit code 137 (interrupted by signal 9: SIGKILL)“的问题
- 开发小程序遇协同、平台兼容难题,该如何破局?
- 关于equals和hashCode
- idea console窗口不见了_Python 闲谈 14——安利下IDEA开发神器中好用到爆的插件
- Doom启示录(一)---李乃峰所崇拜之 两个约翰!
- Linux 怎么找回管理员密码?
- 今天忙着画一个用例图,发现一个好用的工具
- 刷排名优优软件_刷网站排名软件
- BZOJ 3162 独钓寒江雪(树形DP)
- 网页游戏外挂资料(转)
- 计算机指令包括哪2部分,机器指令分为哪几部分
- WPS格式文件转换图片格式如何实现
- 挂耳式骨传导蓝牙耳机,2021骨传导耳机推荐
- 兄弟1218无线打印服务器错误,兄弟无线打印机无法打印怎么办?
- linux大型机如何下载数据,如何从大型机传输PS文件到Linux服务器?
- Java专栏学习导图【一】