Python爬虫新手入门教学(十八):爬取yy全站小视频
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
前文内容
Python爬虫新手入门教学(一):爬取豆瓣电影排行信息
Python爬虫新手入门教学(二):爬取小说
Python爬虫新手入门教学(三):爬取链家二手房数据
Python爬虫新手入门教学(四):爬取前程无忧招聘信息
Python爬虫新手入门教学(五):爬取B站视频弹幕
Python爬虫新手入门教学(六):制作词云图
Python爬虫新手入门教学(七):爬取腾讯视频弹幕
Python爬虫新手入门教学(八):爬取论坛文章保存成PDF
Python爬虫新手入门教学(九):多线程爬虫案例讲解
Python爬虫新手入门教学(十):爬取彼岸4K超清壁纸
Python爬虫新手入门教学(十一):最近王者荣耀皮肤爬取
Python爬虫新手入门教学(十二):英雄联盟最新皮肤爬取
Python爬虫新手入门教学(十三):爬取高质量超清壁纸
Python爬虫新手入门教程(十四):爬取有声小说网站数据
Python爬虫新手入门教学(十五):Python爬取某音乐网站的排行榜歌曲
Python爬虫新手入门教学(十六):爬取网站音乐素材
Python爬虫新手入门教学(十七):爬取好看小视频
基本开发环境
- Python 3.6
- Pycharm
相关模块的使用
import os import requests
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一、确定目标需求
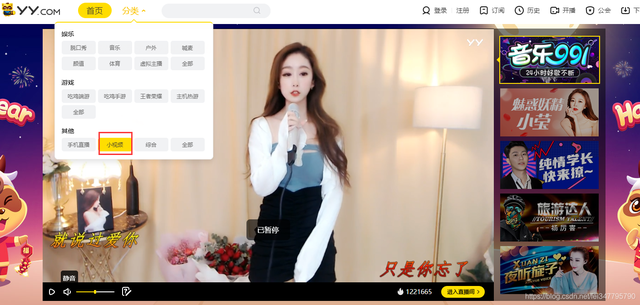
百度搜索YY,点击分类选择小视频,里面的小姐姐自拍的短视频就是我们所需要的数据了。
二、网页数据分析
网站是下滑网页之后加载数据,在上篇关于好看视频的爬取文章中已经有说明,YY视频也是换汤不换药。
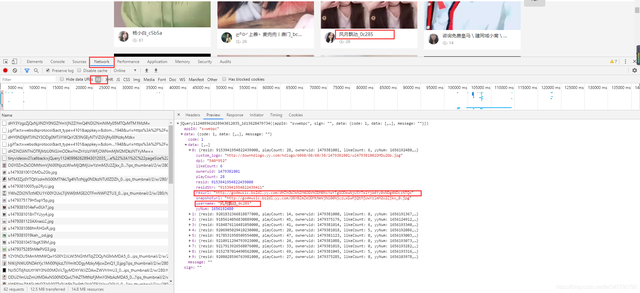
如图所示,所框选的url地址,就是短视频的播放地址了。
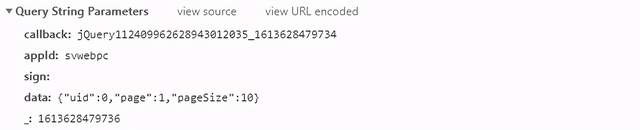
数据包接口地址:
https://api-tinyvideo-web.yy.com/home/tinyvideosv2?callback=jQuery112409962628943012035_1613628479734&appId=svwebpc&sign=&data=%7B%22uid%22%3A0%2C%22page%22%3A1%2C%22pageSize%22%3A10%7D&_=1613628479736
第二页的数据请求参数:
第三页的数据请求参数:
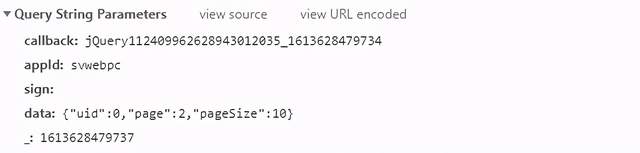
很明显这是根据data参数中的page改变翻页的。
构建翻页循环,获取视频url地址以及发布人的名字,保存到本地。
三、代码实现
1、请求数据接口
import requests
url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
params = {'callback': 'jQuery112409962628943012035_1613628479734','appId': 'svwebpc','sign': '','data': '{"uid":0,"page":0,"pageSize":10}','_': '1613628479737',
}
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
问题来了,返回的数据是json数据嘛?
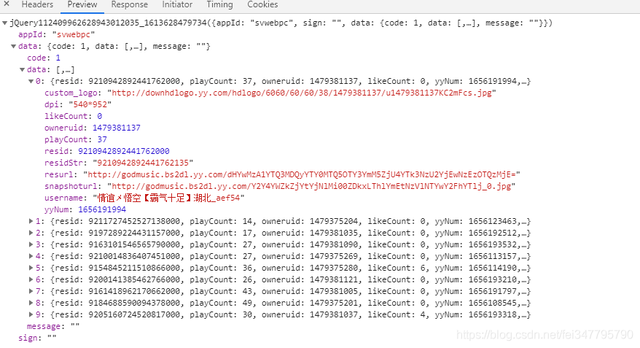
如上图所示,很多人看到这样的数据肯定就觉得这不就是一个json数据嘛?
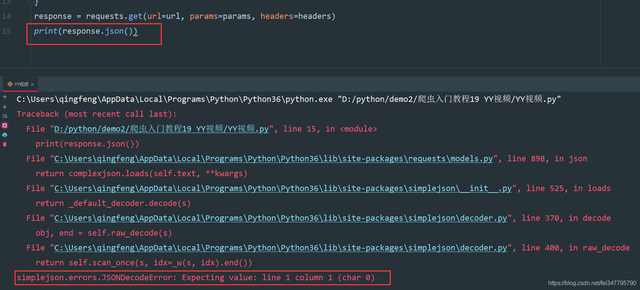
JSONDecodeError: json解码错误,它并不是有一个json数据,而是字符串。
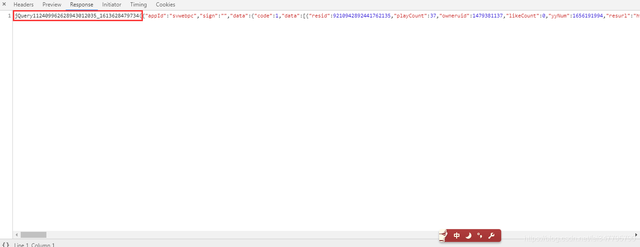
通过response查看就知道了,返回给我们的数据是多了一段 jQuery112409962628943012035_1613628479734()
其中的json数据是包含在里面的,如果想要提取数据有三种方法。
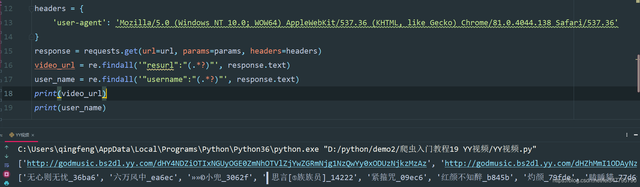
1、返回response.text,使用正则表达式提取url地址以及发布人的名字
video_url = re.findall('"resurl":"(.*?)"', response.text)
user_name = re.findall('"username":"(.*?)"', response.text)
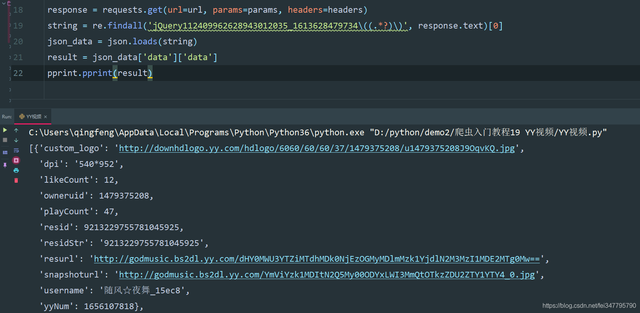
2、返回response.text,使用正则表达式提取 jQuery112409962628943012035_1613628479734() 中的数据,然后通过json模块把字符串转成json数据,然后遍历提取数据。
string = re.findall('jQuery112409962628943012035_1613628479734\((.*?)\)', response.text)[0]
json_data = json.loads(string)
result = json_data['data']['data']
pprint.pprint(result)
3、把请求的url地址中的 callback 删掉,可以直接获取json数据
import pprint
import requestsurl = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
params = {'appId': 'svwebpc','sign': '','data': '{"uid":0,"page":1,"pageSize":10}','_': '1613628479737',
}
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json()
result = json_data['data']['data']
pprint.pprint(result)
2、保存数据
for index in result:video_url = index['resurl']user_name = index['username']video_content = requests.get(url=video_url, headers=headers).contentwith open('video\\' + user_name + '.mp4', mode='wb') as f:f.write(video_content)print(user_name)
注意点: 用户名有特殊字符,保存的时候会报错
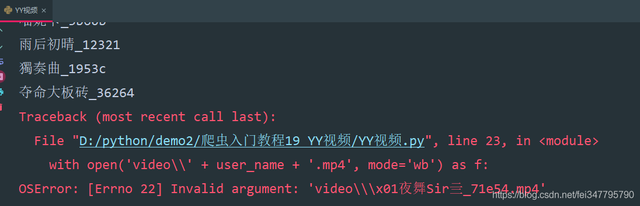

所以需要使用正则表达式替换掉特殊字符
def change_title(title):pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'new_title = re.sub(pattern, "_", title) # 替换为下划线return new_title
完整实现代码
import reimport requests
import redef change_title(title):pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'new_title = re.sub(pattern, "_", title) # 替换为下划线return new_titlepage = 0
while True:page += 1url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2'params = {'appId': 'svwebpc','sign': '','data': '{"uid":0,"page":%s,"pageSize":10}' % str(page),'_': '1613628479737',}headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}response = requests.get(url=url, params=params, headers=headers)json_data = response.json()result = json_data['data']['data']for index in result:video_url = index['resurl']user_name = index['username']new_title = change_title(user_name)video_content = requests.get(url=video_url, headers=headers).contentwith open('video\\' + new_title + '.mp4', mode='wb') as f:f.write(video_content)print(user_name)

Python爬虫新手入门教学(十八):爬取yy全站小视频相关推荐
- Python爬虫新手入门教学(十七):爬取yy全站小视频
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(十六):爬取好看视频小视频
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(十五):爬取网站音乐素材
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(十四):爬取有声小说网站数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(二十):爬取A站m3u8视频格式视频
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文内容 Python爬虫新手入门教学(一):爬取豆瓣电影排行信息 Python爬虫新手入门 ...
- Python爬虫新手入门教学(十):爬取彼岸4K超清壁纸
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(十三):爬取高质量超清壁纸
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(九):多线程爬虫案例讲解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
- Python爬虫新手入门教学(二):爬取小说
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space. ...
最新文章
- C 上传文件到服务器(含接收端源码)
- mysql skip network_MYSQL-skip-networking
- 两个主键怎么设置tsql_如何在sql server中设置两个主键?
- HTML 标签 参考手册
- 全球及中国沼气发电行业现状及项目发展动态调研报告2021年版
- java程序结构_Java 程序结构说明(学习 Java 编程语言 004)
- python docx 设置表格字体和格式_python-docx修改已存在的Word文档的表格的字体格式方法...
- Django框架深入了解_01(Django请求生命周期、开发模式、cbv源码分析、restful规范、跨域、drf的安装及源码初识)
- 【渝粤题库】国家开放大学2021春3700汽车电工电子基础题目
- androidstudio 日历视图怎么显示农历_中秋国庆旅游攻略怎么做?用这个便签软件很简单...
- php 万分之一几率,那万分之一的概率啊……
- css 3d魔方源代码,CSS3 3D环境实现立体 魔方效果代码(示例代码)
- turtle填充随机颜色同心圆
- Web安全实践(6)web应用剖析之信息提炼
- 深入理解Auto Layout 第一弹
- 网络掩码和子网掩码区别?
- 返回上一视图,凸显一个视图,其他视图变模糊
- python打印索引序号_打印带有索引的矩阵python
- CCNA 折扣号申请流程(新版)
- 数据结构——图的应用