六大主流大数据采集平台架构分析
日志收集的场景
DT时代,数以亿万计的服务器、移动终端、网络设备每天产生海量的日志。
中心化的日志处理方案有效地解决了在完整生命周期内对日志的消费需求,而日志从设备采集上云是始于足下的第一步。

随着大数据越来越被重视,数据采集的挑战变的尤为突出。今天为大家介绍几款数据采集平台:
- Apache Flume
- Fluentd
- Logstash
- Chukwa
- Scribe
- Splunk Forwarder
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集-->数据存储-->数据处理-->数据展现(可视化,报表和监控)
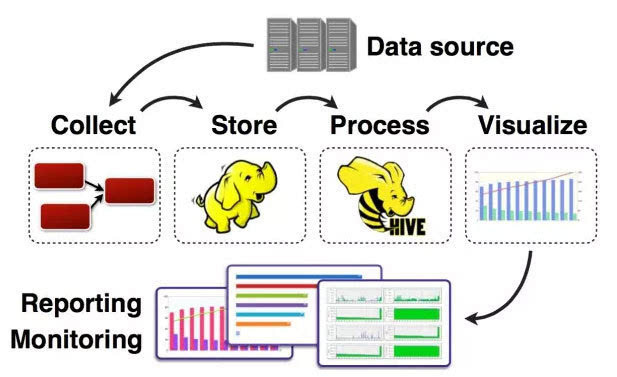
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
- 数据源多种多样
- 数据量大
- 变化快
- 如何保证数据采集的可靠性的性能
- 如何避免重复数据
- 如何保证数据的质量
我们今天就来看看当前可用的六款数据采集的产品,重点关注它们是如何做到高可靠,高性能和高扩展。
1、Apache Flume
官网:https://flume.apache.org/
Flume 是Apache旗下的一款开源、高可靠、高扩展、容易管理、支持客户扩展的数据采集系统。 Flume使用JRuby来构建,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。

Flume设计成一个分布式的管道架构,可以看作在数据源和目的地之间有一个Agent的网络,支持数据路由。

每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管道。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或者文件,解析其中新生成的事件。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如内存,文件,JDBC等。使用内存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如内存。
Sink
Sink负责从管道中读出数据并发给下一个Agent或者最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或者其它的Flume Agent。
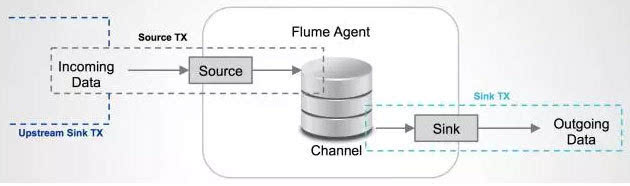
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据丢失。
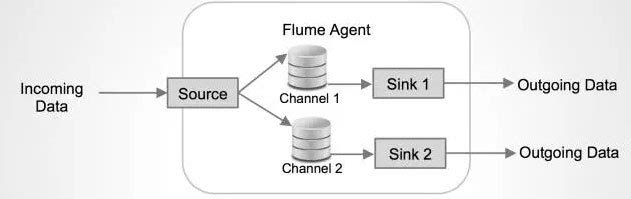
Source上的数据可以复制到不同的通道上。每一个Channel也可以连接不同数量的Sink。这样连接不同配置的Agent就可以组成一个复杂的数据收集网络。通过对agent的配置,可以组成一个路由复杂的数据传输网络。
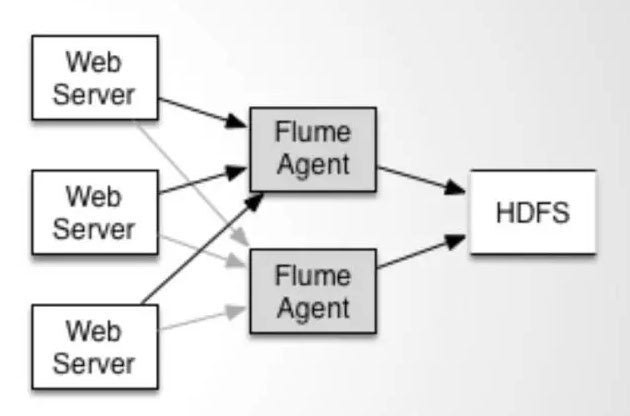
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证即使有一个agent失效的情况下,整个系统仍能正常收集数据。

Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发:
Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的这些客户端都不能满足需求,用户可以定制的客户端,和已有的FLume的Source进行通信,或者定制实现一种新的Source类型。
同时,用户可以使用Flume的SDK定制Source和Sink。似乎不支持定制的Channel。
2、Fluentd
官网:http://docs.fluentd.org/articles/quickstart
Fluentd是另一个开源的数据收集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和很好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
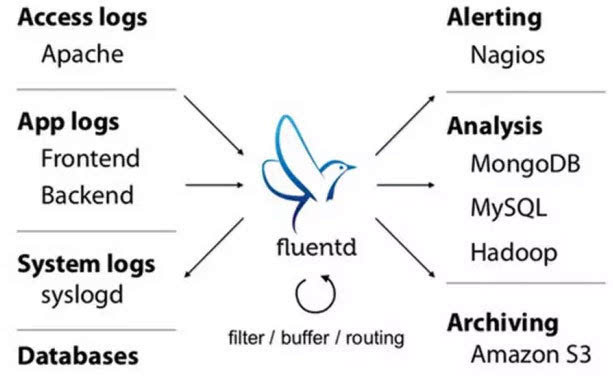
Fluentd的部署和Flume非常相似:
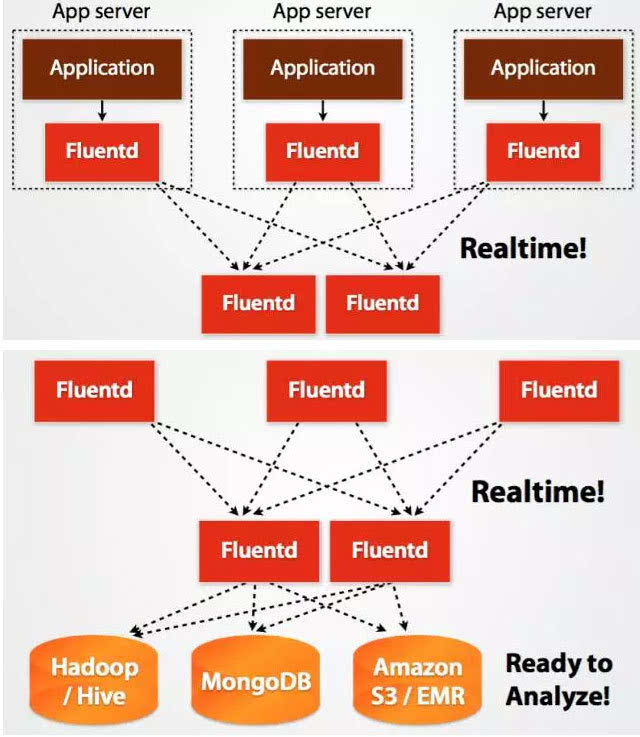
Fluentd的架构设计和Flume如出一辙:
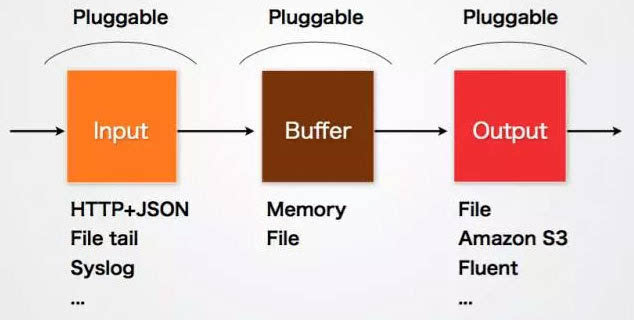
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或者主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或内存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地例如文件,AWS S3或者其它的Fluentd。
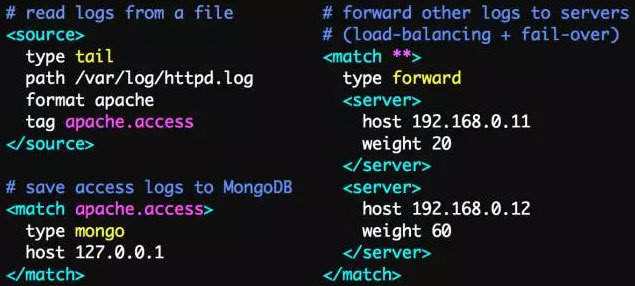
Fluentd的配置非常方便,如下图:
Fluentd的技术栈如下图:
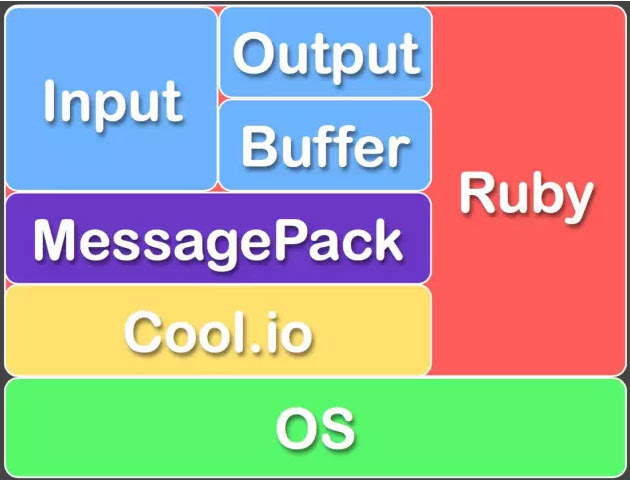
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的事件驱动框架。
FLuentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。
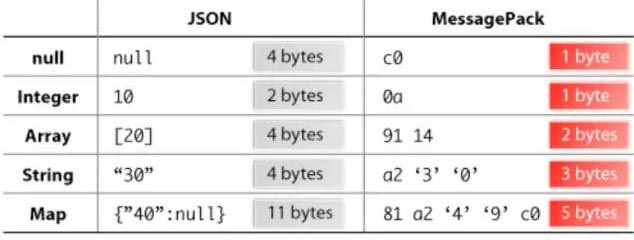
Fluentd从各方面看都很像Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特点。相对去Flumed,配置也相对简单一些。
3、Logstash
https://github.com/elastic/logstash
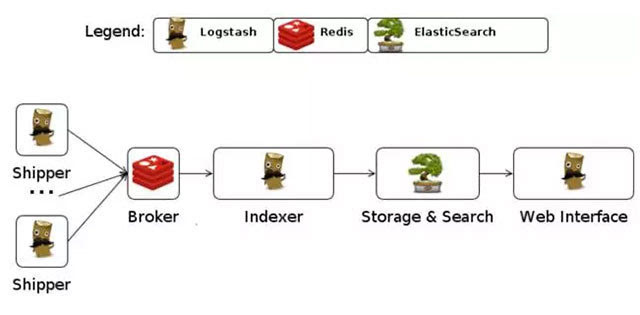
Logstash是著名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那个L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的部署架构如下图,当然这只是一种部署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。

几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
4、Chukwa
官网:https://chukwa.apache.org/
Apache Chukwa是apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来构建(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 github的更新事7年前。可见该项目应该已经不活跃了。
Chukwa的部署架构如下:

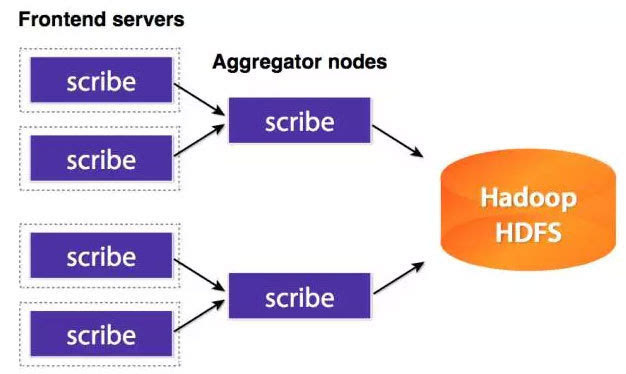
Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目已经不活跃,我们就不细看了。
5、Scribe
代码托管:https://github.com/facebookarchive/scribe
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
6、Splunk Forwarder
官网:http://www.splunk.com/
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据存储,数据分析和处理,以及数据展现的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
- Search Head负责数据的搜索和处理,提供搜索时的信息抽取。
- Indexer负责数据的存储和索引
- Forwarder,负责数据的收集,清洗,变形,并发送给Indexer
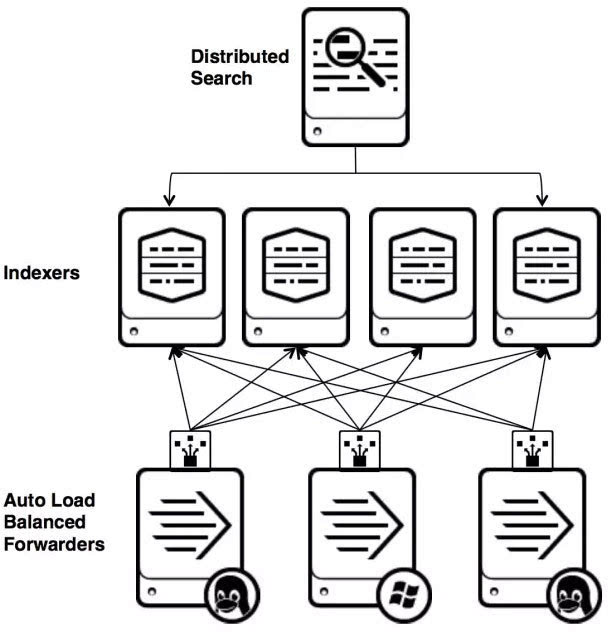
Splunk内置了对Syslog,TCP/UDP,Spooling的支持,同时,用户可以通过开发 Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以方便的从云或者是数据库中获取数据进入Splunk的数据平台做分析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩展的,但是Splunk现在还没有针对Farwarder的Cluster的功能。也就是说如果有一台Farwarder的机器出了故障,数据收集也会随之中断,并不能把正在运行的数据采集任务Failover到其它的 Farwarder上。
总结
我们简单讨论了几种流行的数据收集平台,它们大都提供高可靠和高扩展的数据收集。大多平台都抽象出了输入,输出和中间的缓冲的架构。利用分布式的网络连接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash也许是首选,因为ELK栈提供了很好的集成。Chukwa和Scribe由于项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据收集的解决方案。
六大主流大数据采集平台架构分析相关推荐
- 果断收藏!六大主流大数据采集平台架构分析
随着大数据越来越被重视,数据采集的挑战变的尤为突出.今天为大家介绍几款数据采集平台: Apache Flume Fluentd Logstash Chukwa Scribe Splunk Forwar ...
- 六款大数据采集平台的架构分析
本文转自:<六款大数据采集平台的架构分析> 文中介绍了目前业界存在的六款数据采集平台,数据采集平台可以作为数据平台的日志采集系统,个人尝试过Flume+ES+Kibana这样的开源组合,为 ...
- 大数据平台架构及主流技术栈
互联网和移动互联网技术开启了大规模生产.分享和应用数据的大数据时代.面对如此庞大规模的数据,如何存储?如何计算?各大互联网巨头都进行了探索.Google的三篇论文 GFS(2003),MapReduc ...
- 软件架构设计原则和大数据平台架构层
1.软件架构设计的六大原则: 1)"开-闭"原则(OCP) Software entities should be open forextension, but closed fo ...
- 大数据平台架构技术选型与场景运用
内容来源:2017年5月6日,大眼科技CTO张逸在"魅族技术开放日第八期--数据洞察"进行<大数据平台架构技术选型与场景运用>演讲分享.视频地址:https://mp. ...
- 大数据平台架构的层次划分
1. 数据源层:包括传统的数据库,数据仓库,分布式数据库,NOSQL数据库,半结构化数据,无结构化数据,爬虫,日志系统等,是大数据平台的数据产生机构. 2. 数据整理层:包括数据清洗.数据转换.数据加 ...
- 大数据平台架构浅析——以讯飞大数据平台Odeon为例
文章目录 大数据平台架构解析--以讯飞大数据平台Odeon为例 定义 功能 数据采集 数据开发 数据分析 数据编程 补充 大数据平台架构解析--以讯飞大数据平台Odeon为例 定义 Odeon大数据平 ...
- 硅谷企业的大数据平台架构什么样?看看Twitter、Airbnb、Uber的实践
导读:本文分析一下典型硅谷互联网企业的大数据平台架构. 作者:彭锋 宋文欣 孙浩峰 来源:大数据DT(ID:hzdashuju) 01 Twitter的大数据平台架构 Twitter是最早一批推进数字 ...
- 大数据平台架构包含哪些功能
为了满足企业对于数据的各种需求,需要基于大数据技术构建大数据平台.结合大数据在企业的实际应用场景,如下图所示的大数据平台架构所示: 最上层为应用提供数据服务与可视化,解决企业实际问题.第2层是大数据处 ...
最新文章
- 实战:使用OpenCV+Python+dlib为人脸生成口罩
- python 创建txt文件并写入字符串-Python将字节字符串写入文件
- 微软亚洲研究院谭旭:AI音乐,技术与艺术的碰撞
- java面试题七 char转int
- hadoop_namenode如果选择在哪个datanode存储副本
- 开关问题(模板+高斯消元)
- 通用apdu指令_8086微处理器中的通用指令格式
- apache和mysql 403_如何使用mysql(lamp)分离环境搭建dedecms织梦网站及apache服务器常见的403http状态码及其解决方法...
- ios 获取是否静音模式_高效人士进阶-IOS
- 三番四次,Installer 0day 终于获得微补丁
- 入侵Tomcat服务器一次实战
- R for data science之purrr包(下)
- 为ashx文件启用session管理
- 易语言的Java皮肤_易语言软件更换皮肤的方法
- 如何制作BAT(Windows批处理文件)病毒
- 2020.10.20英语前端电话面试总结
- Android开发之仿360手机卫士悬浮窗效果
- 数据库sql文件导入失败(高版本转入低版本),报错:[SQL] Query test start[ERR] 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘
- 生成拼音语料及拼音识别转换成中文
- 用Freeman码链表示图像边界
热门文章
- 双非计算机考研可以调剂的学校,考研调剂时别盲目选择名校!最好的调剂院校其实是你的本科院校!...
- kubernetes部署高可用Harbor
- edusoho linux安装教程,CentOS部署部署Edusoho
- shell脚本实战(第2版)/人民邮电出版社 脚本12 构建shell叫脚本库
- 虚拟机 windows10激活后复制到其他盘无法激活解决办法
- SVG学习笔记(一)画一个哆啦A梦
- 解决java.sql.SQLException: Access denied for user ‘root‘@‘localhost‘ (using password: YES)
- linux dd iflag oflag,Linux dd 命令
- windows下,怎么使用管理员运行cmd.exe程序。
- android hprof,Android Hprof 分析