基于深度学习的三维点云识别
基于深度学习的三维点云识别
一、什么是三维物体识别
随着三维成像技术的发展,结构光测量、激光扫描、ToF等技术趋于成熟,物体表面的三维坐标能够精准而快速的获取,从而生成场景的三维数据,能够更好地感知和理解周围环境。三维数据包含了场景的深度信息,能够表示物体的表面形状,在机器人、AR/VR、人机交互、遥感测绘等多个领域具有广阔的应用前景。
三维数据由传感器直接获得,可以表示为深度图、点云、网格、CAD等不同形式。其中点云数据获取便捷,易于存储,具有离散和稀疏特性,方便扩展为高维的特征信息,是近年来的研究主流方向。
然而,与二维图像中像素的规则排列方式不同,点云数据是无序的 ,这使得它很难直接应用卷积来获取三维点之间的局部相关性信息。同时,由于采集方法的原因,点云数据常常是非均匀分布的,不同局部区域的点云密度常常不等,这会为特征提取时,数据点的采样带来困难。此外,三维空间中物体的形变较二维图像更为复杂,除三个维度的仿射变换外,还有非刚体形变需要考虑。
二、三维物体识别方法
按照特征提取方式分类,三维物体识别方法可以分为基于手动设计提取特征的方法和基于深度学习的方法两种。其中,手动设计特征的方法较为成熟,在一些领域有所应用。而基于深度学习的方法是近年来的研究热点。
2.1 基于手动提取特征的方法
此类方法从三维点的几何属性、形状属性、结构属性等方面提取三维空间特征,统计关键点局部邻域的空间分布信息,计算空间分布直方图,得到特征向量等描述子,输入SVM等分类器,或使用条件随机场等得到匹配结果。
根据特征的构造角度又可进行细分,其中,基于局部特征的方法主要提取物体的关键点、边缘或面片,或关键点的法向量、曲率等微分几何信息。基于全局特征的物体识别方法则需要先将目标从背景中分割出来,再计算法线夹角等几何信息来构建描述符。此外,还有基于图匹配的方法,其思想是将点云数据分解成基本形状,使用抽象点进行表示,再构造拓扑图表示形状之间的邻近关系,使用图匹配的方法进行识别。
现今基于手动提取特征的方法已经比较成熟,如HKS、FPFH等。然而,手动提取的特征仅从曲率、法方向等有限角度提取特征,而无法完全利用三维点云的全部信息。这些特征仅对某种特定的变换存在不变性,因此,此类方法所能达到的精度存在瓶颈,相较之下,基于深度学习方法更能全面利用三维点云的特征信息,拥有更大的研究前景。
2.2 基于深度学习的方法
2.2.1 难点与挑战
对于二维图片的识别任务来说,卷积神经网络是最主要的解决方法。不同大小的卷积核可以自动提取像素的局部相关性特征,从而达到很高的识别精度,卷积操作的权值共享特性也大大减少了网络优化参数。然而,图像中的像素是规则排列的,这为使用卷积创造提供了先决条件。
![]()
![]()
然而点云数据并非是在空间中规则排列的。如图所示,图i的单位为二维图像的像素,四个点有序规则排列在图片中,保留着空间结构信息。而对于图ii~图iv的点云数据,卷积算子的输入是一串点集,存在以下两种情况:
- 四个点分布于不同空间位置,相同次序输入。如图ii和图iii。对其特征做卷积,得到的结果(fii,fiii)(f_{ii},f_{iii})(fii,fiii)相同。因为每个点自有的特征与空间位置无关,此时,丢失了局部各店的结构相关信息。
- 四个点分布于同一空间位置,不同次序输入。如图iii和图iv。对其特征做卷积,得到的结果(fii,fiv)(f_{ii},f_{iv})(fii,fiv)不同。
这说明,图像中点的位置信息隐含在其排列次序中,而点云数据显示的以坐标存储,没有统一的排序规则,直接卷积会丢失点云的形状信息,并且卷积结果对点的顺序敏感,因此难以直接应用卷积操作。
除此之外,由于三维数据采集设备的特性所致,点云数据往往具有局部密度不等、分布稀疏等特点。而关键点局部邻域的划分,和邻域内的特征提取往往是构造特征的关键。相较于图像中分布均匀的二位点阵,直接在三维点云中应用卷积,会出现采样不均问题,影响特征提取。同时,稀疏的点云空间也会在卷积过程中造成大量的时间和内存浪费。
总的来说,三维点云的深度学习任务中,目前存在的主要挑战是:**点云数据的无序性问题,点云分布的不规则问题。**针对这一任务,目前有几种主要的处理方案。
2.2.2 主要方法
a) 直接处理点云的的方法
无法对点云直接使用卷积的根本原因是点云数据的无序性,对点云数据进行排序再卷积,则是一种很直观的解决方案。然而随着点云中数据点的增多,其全排列的数目会爆炸式增长,带来了极大的计算负担,激光雷达获取的点云数据量更大,更难直接应用。此外,如何在排序的同时,设定点的权值以保留形状信息也是一个需要考虑的问题。当前沿袭这种思想的主要方法有山东大学在2018年提出的PointCNN,其主要思想是通过深度网络学习一个置换矩阵,对输入数据进行排序和加权。
另一种思路是提取点云数据中与点序列无关的信息,以这种对于顺序不敏感的特征进行匹配。斯坦福大学提出的PointNet系列的方法即沿用了这个思路,他们提出了对称函数的思想,使用对称函数对特征点提取顺序无关的信息,来近似点云的全局信息,并在PointNet++中提出了层级结构,使其架构能够提取点云的局部相关性特征,并适应不同的局部点密度。
b) 基于voxel的方法
基于voxel的方法试图在三维数据上直接使用卷积。这种方法试图将不规则分布的点云或mesh,转换为规则分布的栅格化表示。voxel是将点云空间规则划分所得的单位,每一个voxel含有子空间中的多个点。以voxel为基本单位,使用3D-CNN进行特征提取。

这种方法保留了点的空间位置信息,但是由于点云数据量和3D-CNN的固有计算量,此方法通常开销很大,在保证计算效率的同时,往往需要降低分辨率,从而造成了精度损失。同时,点云数据在转化为voxel表示后,往往是稀疏分布的,很多voxel并没有包含三维点,带来了很多不必要的乘0或者为空的计算开销。因此,如何将稀疏voxel转化为密集向量,并提供可GPU加速的计算方法,是这种思路面临的主要挑战。FPNN和Vote3D提出了一些方法处理稀疏问题,但仍是在稀疏voxel上进行操作。苹果公司提出的VoxelNet在这方面做出了一些尝试,提出了端到端的高效方案,取得了较好的结果。
c) 多视角方法
此类方法的思路是将同一个三维物体,转化为不同视角下”拍摄“所得到的二维图像,将这些二维图像作为训练数据,使用二维卷积进行特征提取,如图是Multi-view CNN中提出的网络结构图。
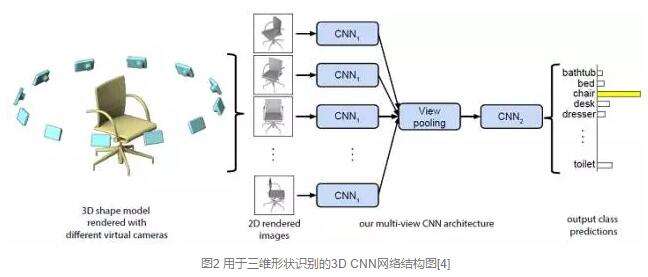
此类方法在分类任务上取得了较好的表现,但由于转化为二维图像的过程中丢失了三维空间位置信息,所以难以应用在场景分割、物体检测等任务中。
d) 其他方法
除了以上几种主要研究方向外,还有一些其他方法取得了不错的进展。如类似RNN的序列化解决思路,具体是,将一个点集当做序列进行处理。然而这种方法需要对输入数据进行输入增强,获得其所有排列的序列,依然存在很大的计算开销。而Spectral Networks系列文章则结合了图谱论知识,在网格数据中应用图谱卷积(spectral CNNs)。然而此类方法当前仅构建在规则物体上,难以拓展到非规律物体识别任务中。
![]()
调研调查了三种最近发表的文章可以发现,对于Multiview和volumetric的研究逐渐减少,而对于点云方法的研究却有了大幅增长。准确性方面,基于点云的方法也取得了超出或相平与state-of-art方法的表现。
三、直接处理点云数据的识别方法
1. PointNet/PointNet++
PointNet的思路是使用对称函数解决点的无序性问题。其中,PointNet将输入点云逐点进行特征抽象,通过对称函数得到全局特征向量。PointNet++在此基础上,改进了无法获取各点间局部相关性特征的问题,设计了层级结构,并提出了MSG/MRG结构,适应非均匀分布的点云数据。针对物体位姿变换问题,PointNet设计了STN自网络,学习变换矩阵T适应位姿变换,PointNet++更引入了不同尺度空间的特征概念,使网络能够适应非刚体变换。

式中,f是全局特征的提取函数,h是每一个点的特征提取函数,g是文章提出的对称函数。在数据量很大的情况下,对一系列点通过f提取特征,可以与对单个点提取特征的点集,与对称函数的作用结果相近似。即对称函数可以提取出与点集顺序无关的全局特征。文章使用max pooling作为对称函数。
pointNet++就在此基础上,设计了层级结构,每一级划分多个邻域范围的点集,以PointNet结构作为特征提取层,分别提取每个子点集的特征。这样,pointNet类似于卷积核,提取的点集类似于卷积划过的图像窗口,类似于感受野,最终多层级的提取了具有局部相关性的全局特征。
![]()
如图是PointNet++的网络结构。一个架构中含有多个层级,每个层级分为三部分。其中Sampling layer用于选取各点集的中心点,使用FPS方法,在当前尺度标准下选择能够更均匀覆盖整个输入点集的中心点集。Grouping layer对每个中心点找它的邻域点,形成子点集。PointNet layer则与Point Net结构相似,将每个邻域特征点集抽象为一个特征向量。同时,Grouping layer得到的每个邻域点集内点个数不一定相等,经过PointNet layer可以得到相等维度的特征向量,最终得到此层的输出特征矩阵。
文章还提出了解决点云数据分布不均匀的方法。将特征点集划分为多个子集再分别提取特征,可以得到密集点处的局部特征,而若将整个点集直接通过PointNet layer,可以更好的提取到稀疏分布特征点的全局特征。文章提出的MRG结构,就将前级输出的特征向量加和,与当前级所有点直接经过PointNet layer得到的特征向量加权组合,从而多尺度的采集非均匀分布点集的特征信息。
![]()
![]()
上图分别为PointNet++不同层级提取特征点的空间位置可视化结果和图像分割可视化结果。从特征点结果可见,随着层级变高,特征点的抽象层次也加深,但其空间位置依旧构成了原物体的形状,可以认为抓取了物体的骨架结构。而在分割问题的可视化结果中,可以看出PointNet++能够取得比较好的分割效果。
2.PointCNN
本文提出了一种可学习的矩阵$ conv_X $,对在卷积操作前三维点云数据加权、置换。使得卷积能够保留点云的空间位置信息,并且不依赖与点的输入顺序,解决了点的无序性排列问题。此方法可以同时应用在分类和分割任务中,作者介绍了在两类任务中的不同网络架构及细节实现。
文章提出,通过MLP从输入点集P学习一个K×K的矩阵,作用于点集P的特征F矩阵,这样,对于输入特征点加权、置换。由于加权操作,同一特征点在不同空间位置拥有不同的权重,解决了上图f2==f3的问题。由于置换操作,点被重新排序,解决了点顺序造成的敏感。即:理想状态的X变换,能够在考虑点集形状的同时,不依赖于点的输入顺序。
文章以表示点(represent point)来表示每一层的抽象特征点。随着层级提高,每一层表示点减少,而每个表示点维度加深,感受野增大,获得更高层的抽象信息。每个表示点都是由它的邻域点集卷积获得,针对均匀和非均匀的点云输入,文章分别使用K近邻法和半径搜索法确定邻域点集,使得采样尽可能均匀。

算法中,首先将邻域点集P移动到表示点p的坐标系下得到P’,以使得P’表示的是p邻域点集的相对位置关系。之后逐点使用MLP,输入P’,提取空间位置的delta维特征信息F_delta。将F_delta和F拼接得到F* ,这样得到了同时含有空间特征信息和原上级特征信息的特征矩阵F* 。同时,将P’输入MLP,根据点的相对位置信息,训练得到矩阵X。X与F*相乘,对特征矩阵进行加权和置换,得到最终的特征矩阵Fx。最终Fx和卷积核K做传统卷积操作,得到下一层的特征Fp。

文章分布给出了分类问题和分割问题的网络架构。分类任务中,为了彻底训练网络,需要更多的表示点连入全连接层。为了保持感受野和网络深度,本文使用了空洞卷积。测试阶段,多个顶层表示点(对应FC)的输出求均值,再输入softmax层得到预测结果。分割问题中,引入encoder-decoder结构,encoder即分类问题除去FC后的部分,decoder部分则在表示点后再依次加入卷积,输出更少的特征维度和更多的表示点,恢复分辨率。
![]()
图为PointCNN不同层次表示点的可视化结果。可见,提取到的表示点依旧具有原点云的形状信息,并且抓取到了物体的骨架结构。
![]()
图为分类任务中不同方法的结果。可见,在ModelNet40和ScanNet两个数据集上,PointCNN的表现超过基于Voxel和Multiview image的其他三维深度学习方法,也高于PointNet++,取得了state-of-the-art的表现。
四、未来发展方向
当下热门研究方向仍是应用直接处理点云数据的相关研究,此方法能够最大限度的保留三维数据的原始信息,使得模型精度拥有更高的提升空间。而此方法面临的问题仍然存在,PointCNN虽然使用了X卷积对点云数据进行加权排序,但却很难学习到精确的排列方式。而PointNet选用的对称函数的近似程度也有所挑战。同时,在处理如雷达获取的大规模点云数据时,此类方法的计算开销依然不容忽视。
未来研究中,仍有很多方向值得探索。例如,如何进一步解决点云无序性问题,处理非均匀分布的点云数据的采样问题,对于非刚体变换的不变性问题,检测任务中的定位问题,减少网络的参数和时间空间开销,处理原数据的噪声和遮挡等。
基于深度学习的三维点云识别相关推荐
- 关于使用深度学习进行三维点云几何压缩
文章目录 前言 了解名词 1. 点云 2. 体素 3. 表示学习 4. 损失函数 5. BPP 相关工作 1. 点云表示学习 2. 点云几何压缩 层次自编码(整体解压缩流程) 1. 多尺度特征提取 2 ...
- 深度学习在三维点云上的应用(Deep Learning for 3D Point Clouds: A Survey)
深度学习在三维点云上的应用 摘要 最近,点云由于在计算机视觉.自动驾驶和机器人技术等许多领域的广泛应用而受到越来越多的关注.深度学习作为一种主要的人工智能技术,已经成功地用于解决各种二维视觉问题.由于 ...
- 基于深度学习的三维语义理解(分割)综述列表
基于深度学习的三维语义理解(分割)综述列表 文章目录 基于深度学习的三维语义理解(分割)综述列表 前言 基于深度学习的三维语义理解(分割)综述列表 一. 从单一三维模型中进行深度学习 1.1基于点云的 ...
- 【camera】基于深度学习的车牌检测与识别系统实现(课程设计)
基于深度学习的车牌检测与识别系统实现(课程设计) 代码+数据集下载地址:下载地址 用python3+opencv3做的中国车牌识别,包括算法和客户端界面,只有2个文件,surface.py是界面代码, ...
- 基于深度学习的手写数字识别、python实现
基于深度学习的手写数字识别.python实现 一.what is 深度学习 二.加深层可以减少网络的参数数量 三.深度学习的手写数字识别 一.what is 深度学习 深度学习是加深了层的深度神经网络 ...
- 基于深度学习的手写数字识别Matlab实现
基于深度学习的手写数字识别Matlab实现 1.网络设计 2. 训练方法 3.实验结果 4.实验结果分析 5.结论 1.网络设计 1.1 CNN(特征提取网络+分类网络) 随着深度学习的迅猛发展,其应 ...
- 基于深度学习的花卉检测与识别系统(YOLOv5清新界面版,Python代码)
摘要:基于深度学习的花卉检测与识别系统用于常见花卉识别计数,智能检测花卉种类并记录和保存结果,对各种花卉检测结果可视化,更加方便准确辨认花卉.本文详细介绍花卉检测与识别系统,在介绍算法原理的同时,给出 ...
- 【论文笔记】《基于深度学习的中文命名实体识别研究》阅读笔记
作者及其单位:北京邮电大学,张俊遥,2019年6月,硕士论文 摘要 实验数据:来源于网络公开的新闻文本数据:用随机欠采样和过采样的方法解决分类不均衡问题:使用BIO格式的标签识别5类命名实体,标注11 ...
- 【毕业设计_课程设计】基于深度学习网络模型训练的车型识别系统
文章目录 0 项目说明 1 简介 2 模型训练精度 3 扫一扫识别功能 4 技术栈 5 模型训练 6 最后 0 项目说明 基于深度学习网络模型训练的车型识别系统 提示:适合用于课程设计或毕业设计,工作 ...
最新文章
- 全方面了解和学习PHP框架
- 巴克沙里手稿——历史性的突破可能比内容本身更加珍贵
- 调试工具_Apifox for Mac(接口调试管理工具)
- Jmeter4.X - 使用本身自带的脚本录制功能录制脚本
- 混合选择集的坐标提起lisp_晓东CAD家园-论坛-A/VLISP-[LISP程序]:请教如何对选择集进行排序-我有(setq ss(ssget _w p0 p1 (list (0 . CIRC...
- opendrive道路标准基础知识
- java时间格式化工具类_java日期格式化工具类
- Essential Netty in Action 《Netty 实战(精髓)》
- DIADEM_metric不能运行及解决办法
- html5背景图片幻灯片切换,如何将一个PPT的背景设置成另一个PPT的背景?
- Hadoop:Browse Directory Couldn‘t upload the file
- 提高信息系统的安全防护能力,一篇文章带你了解等保测评的重要性
- 软件安全实验——lab7(缓冲区溢出3:返回导向编程技术ROP)
- 解决Ubuntu16.04下wingide6.1无法用五笔输入中文的问题
- 打印机扫描显示服务器磁盘已满,打印机内存已满怎么办 打印机清除内存方法...
- 那些年我们玩过的Spark下的Standalone集群模型
- 公共经济学(期末复习资料)
- 话说笔记(V1.0.0)的设计和实现
- 饼图不显示百分比(%),显示原始数据的处理
- 蓝桥杯物联网竞赛基础图文教程——时钟选择