强化学习实践三 :编写通用的格子世界环境类
gym里内置了许多好玩经典的环境用于训练一个更加智能的个体,不过这些环境类绝大多数不能用来实践前五讲的视频内容,主要是由于这些环境类的观测空间的某个维度是连续变量而不是离散变量,这是前五讲内容还未涉及到的知识。为了配合解释David Silver视频公开课提到的一些示例,参考了gym的思想设计了一个通用的格子世界环境类,该环境类的观测空间是一维离散变量,可以很好地模拟其公开课中提到的:简单格子、有风格子、随机行走、悬崖行走、随机策略(骷髅和钱袋子)等问题。在此基础上理解、实践强化学习的基础算法就相对简单而且直观了。
先贴上格子世界环境类的源文件:gridworld.py,只把该文件下载到您自己的文件夹内,导入其中的类或方法就可以了。已经内置的一些环境类UI界面类似下面这些:
一些内置的格子世界环境
简单或有风10*7格子世界
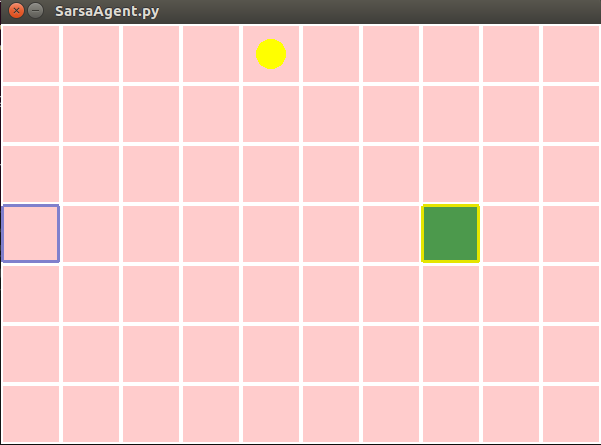
悬崖行走示例
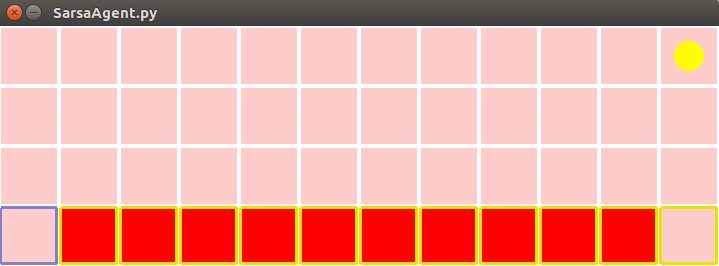
随机行走示例

模仿Gridworld with Dynamic Programming 的一个格子世界

用户可以自定义格子的大小、水平和垂直格子数目、内部障碍分布、以及每一个格子的即时奖励值。在通用的格子世界环境类的UI界面中,我使用不同的颜色设置表示不同的意义,其中:
- 带有蓝色边框的格子 表示起始状态;
- 带有金黄色边框的格子 表示终止状态,终止状态可以不止一个;
- 黑色的格子表示障碍格子,个体一般不能进入;
- 其他不同颜色的格子表示格子的即时奖励值不同,奖励值为0的格子颜色为灰色,奖励值为负值颜色显示偏向于红色,值越小,红色越深;奖励值大于0的格子偏向于显示绿色,值越大,绿色越饱满;
- 个体使用黄色圆形来表示。
如何使用通用的格子世界类来定制自己想要的格子环境:
通用的格子世界环境类接受如下参数:
def __init__(self, n_width:int=10,n_height:int = 7,u_size = 40,default_reward:float = 0,default_type = 0,windy=False):分别是水平方向上格子数量,竖直方向上格子数量,每一个单位格子的绘制边长(单位为像素值),默认每一个格子的即时奖励值以及默认格子的类型。定义格子类型值为0时为个体可进入格子,类型为1表示为障碍,个体不能进入格子。有兴趣您可以修改代码支持更多的类型。
下面以一个悬崖行走格子世界环境为例,讲解如何使用通用的格子世界环境类来得到自己想要的格子世界环境对象。悬崖行走的例子出现在David Silver强化学习公开课的 第五讲 ,环境如下:
![]()
- 首先,明确格子世界环境的布局:长宽格子数、内部的障碍、即时奖励、起始状态、终止状态等信息。对于悬崖行走示例来说,世界长
、宽
,起始位置在左下角,坐标为
,终止状态在右下角,坐标为
。
- 使用对应的参数建立一个格子世界环境类对象:
# 导入GridWorldEnv前确保当前代码文件与gridworld.py文件同在一个包内
from gridworld import GridWorldEnv
env = GridWorldEnv(n_width=12, # 水平方向格子数量n_height = 4, # 垂直方向格子数量u_size = 60, # 可以根据喜好调整大小default_reward = -1, # 默认格子的即时奖励值default_type = 0) # 默认的格子都是可以进入的
from gym import spaces # 导入spaces
env.action_space = spaces.Discrete(4) # 设置行为空间支持的行为数量
# 格子世界环境类默认使用0表示左,1:右,2:上,3:下,4,5,6,7为斜向行走
# 具体可参考_step内的定义
# 格子世界的观测空间不需要额外设置,会自动根据传入的格子数量计算得到- 设置起始和终止状态,起始状态用元组描述,终止状态用列表描述:
env.start = (0,0)
env.ends = [(11,0)]对一些特殊格子的类型和即时奖励值进行修改,这里要把组成悬崖的格子的即时奖励设为-100,这个例子中没有不可进入的格子,所以不需要对格子类型进行修改。示例中悬崖格子是终止状态,因此有:
for i in range(10):env.rewards.append((i+1,0,-100))env.ends.append((i+1,0))
- 特殊类型的格子设置类似于即时奖励设置,比如我们将坐标为(5,1)和(5,2)的两个格子设为不可进入,可以添加如下代码:
env.types = [(5,1,1),(5,2,1)]
- 最后为了使这些设置在实际生效,调用刷新设置方法:
env.refresh_setting()
至此,我们自定义的格子世界环境就设置好了,调用其render()方法查看一下吧:
env.render()
input("press any key to continue...")效果如下:
![]()
两块障碍已经顺利生成了,可是发现个体的位置不在起始位置,为此我们需要重置下个体的位置,只需要调用env的reset()方法就可以了:
env.reset()再看效果符合预期:
![]()
生成这个环境完整的代码如下:
from gridworld import GridWorldEnv
from gym import spacesenv = GridWorldEnv(n_width=12, # 水平方向格子数量n_height = 4, # 垂直方向格子数量u_size = 60, # 可以根据喜好调整大小default_reward = -1, # 默认格子的即时奖励值default_type = 0) # 默认的格子都是可以进入的
env.action_space = spaces.Discrete(4) # 设置行为空间数量
# 格子世界环境类默认使用0表示左,1:右,2:上,3:下,4,5,6,7为斜向行走
# 具体可参考_step内的定义
# 格子世界的观测空间不需要额外设置,会自动根据传输的格子数量计算得到
env.start = (0,0)
env.ends = [(11,0)]
for i in range(10):env.rewards.append((i+1,0,-100))env.ends.append((i+1,0))
env.types = [(5,1,1),(5,2,1)]
env.refresh_setting()
env.reset()
env.render()
input("press any key to continue...")有了格子世界通用环境类,我们就可以比较方便定制自己的格子世界环境。为了方便使用,我也写好了几个内置的格子世界环境,大家只要调用相应的方法就可以得到它:
env = LargeGridWorld() # 10*10的大格子
env = SimpleGridWorld() # 10*7简单无风格子
env = WindyGridWorld() # 10*7有风格子
env = RandomWalk() # 随机行走
env = CliffWalk() # 悬崖行走
env = SkullAndTreasure() # 骷髅和钱袋子示例如果您希望让您的个体支持斜向行走,请将相应的行为空间参数设为8,同时请留意环境类的_step方法关于斜向行走状态的改变是否如您所愿的那样设置,您可以在此基础上定制自己的行为规则。
要使用格子世界环境类提供的功能,您必须已经实现安装了gym库以及其依赖库。关于如何安装gym库、如何向gym注册自定义的环境类可以参考相关教程。通过gym库提供的相关功能,你还可以把个体经历Episode的过程录制成视频。
下次实践编写与个体相关的代码来巩固我们对强化学习相关基础算法的理解。敬请期待。
强化学习实践三 :编写通用的格子世界环境类相关推荐
- 强化学习实践四:编写通用的格子世界环境类
gym里内置了许多好玩经典的环境用于训练一个更加智能的个体,不过这些环境类绝大多数不能用来实践前五讲的视频内容,主要是由于这些环境类的观测空间的某个维度是连续变量而不是离散变量,这是前五讲内容还未涉及 ...
- 强化学习实践六 :给Agent添加记忆功能
在<强化学习>第一部分的实践中,我们主要剖析了gym环境的建模思想,随后设计了一个针对一维离散状态空间的格子世界环境类,在此基础上实现了SARSA和SARSA(λ)算法.<强化学习& ...
- 强化学习实践七:给Agent添加记忆功能
在<强化学习>第一部分的实践中,我们主要剖析了gym环境的建模思想,随后设计了一个针对一维离散状态空间的格子世界环境类,在此基础上实现了SARSA和SARSA(λ)算法.<强化学习& ...
- 【赠书】掌握人工智能重要主题,深度强化学习实践书籍推荐
今天要给大家介绍的书是深度强化学习实践的第二版,本书的主题是强化学习(Reinforcement Learning,RL),它是机器学习(Machine Learning,ML)的一个分支,强调 ...
- 强化学习(三) - Gym库介绍和使用,Markov决策程序实例,动态规划决策实例
强化学习(三) - Gym库介绍和使用,Markov决策程序实例,动态规划决策实例 1. 引言 在这个部分补充之前马尔科夫决策和动态规划部分的代码.在以后的内容我会把相关代码都附到相关内容的后面.本部 ...
- DeepMind 的新强化学习系统是迈向通用 AI 的一步吗?
作者 | Ben Dickson 来源 | 数据实战派 这篇文章是我们对 AI 研究论文评论的一部分,这是一系列探索人工智能最新发现的文章. 对于已经精通围棋.星际争霸 2 和其他游戏的深度强化学习模 ...
- 多智能体强化学习(三)单智能体强化学习
多智能体强化学习(三)单智能体强化学习 1. 问题制定:马尔可夫决策过程 2. 奖励最大化的理由 3. 解决马尔可夫决策过程 3.1 基于价值的方法 3.2 基于策略的方法 通过试验和错误,一个RL智 ...
- 动手学强化学习(三):动态规划算法 (Dynamic Programming)
动手学强化学习(三):动态规划算法 (Dynamic Programming) 1. 简介 2. 悬崖漫步环境 3. 策略迭代算法 3.1 策略评估 3.2 策略提升 3.3 策略迭代算法 4.价值迭 ...
- 强化学习实践:DDQN—LunarLander月球登入初探
强化学习实践:DDQN-月球登入LunarLander初探 算法DDQN 实践 环境准备 GYM及PARL+paddle parl的框架结构 agent构建 搭建神经网络 replay_memory经 ...
最新文章
- 找到一个全能的免费空间!支持SQL和.net2.0
- sqlserver的基本介绍
- 《快速软件开发——有效控制与完成进度计划》
- 计算机应用技术重点学科,福州大学省级重点学科介绍:计算机应用技术(081203)...
- ArrayList详细
- 50.magento 订单状态
- HighCharts:图表默认的英文日期改为中文显示
- MATLAB拟合优度检验
- 关于数据加载的一些思考
- AUTOCAD——多段线命令
- Django中select_related的作用和用法
- 【实践案例分享】PyFlink 在聚美优品的应用实践
- Halcon 3D create_pose
- 安装SSMS报错:0x80070643
- 机械制造作业考研题目答案分享——回转体的加工
- 解决Chrome中打不开Google搜索结果链接
- 大数据分析R语言RStudio使用教程
- Typhon爬取图片
- SQLSERVER2012 保存阿拉伯文字乱码的问题
- ZOOM国际版无法访问 可申领ZOOM平安云版本试用账号了