德国交通标志检测识别数据集
http://benchmark.ini.rub.de/?section=gtsdb&subsection=dataset
http://benchmark.ini.rub.de/?section=gtsrb&subsection=dataset#Downloads
The German Traffic Sign Detection Benchmark
The German Traffic Sign Detection Benchmark is a single-image detection assessment for researchers with interest in the field of computer vision, pattern recognition and image-based driver assistance. It is introduced on the IEEE International Joint Conference on Neural Networks 2013. It features ...
- a single-image detection problem
- 900 images (devided in 600 training images and 300 evaluation images)
- division into three categories that suit the properties of various detection approaches with different properties
- an online evaluation system with immediate analysis and ranking of the submitted results




Competion Test Dataset
If you want to participate in our competition, please download the test dataset (530 MB) and process the images by your traffic sign detector. For details on the submission procedure, please refer to section "Submission format and regulations".
Download
Feel free to download the full data set (1.6 GB) and use it for your purposes. The download package comprises
- the 900 training images (1360 x 800 pixels) in PPM format
- the image sections containing only the traffic signs
- a file in CSV format containing ground truth
- a ReadMe.txt explainig some details
You can also still download the training and test datasets that were used for the competition ( training data set (1.1 GB), test data set (500 MB) ). Momentarily it is still possible to submit results on the test data set in order to compare your performance to that of other teams. For details on the submission procedure, please refer to section "Submission format and regulations".
Image format
- The images contain zero to six traffic signs. However, even if there is a traffic sign located in the image it may not belong to the competition relevant categories (prohibitive, danger, mandatory).
- Images are stored in PPM format
- The sizes of the traffic signs in the images vary from 16x16 to 128x128
- Traffic signs may appear in every perspective and under every lighting condition
Annotation format
Annotations are provided in CSV files. Fields are seperated by a semicolon (;). They contain the following information:
- Filename: Filename of the image the annotations apply for
- Traffic sign's region of interest (ROI) in the image
- leftmost image column of the ROI
- upmost image row of the ROI
- rightmost image column of the ROI
- downmost image row of the ROI
- ID providing the traffic sign's class
You can download source code that will help you to read and compare the annotation files with your detector's results. For an explanation of the class IDs we refer to the ReadMe.txt in the download package.
Submission format and regulations
Similar to the annotation format, the result files that can be submitted during the competition phase (schedule) are supposed to be provided in a CSV file format, seperated by a semicolon (;). The fields are
- Filename with extension (without path) of the file your algorithm has detected a traffic sign
- Detection's region of interest (ROI) in the image
- leftmost image column of the ROI
- upmost image row of the ROI
- rightmost image column of the ROI
- downmost image row of the ROI
Hence, the result file will contain one line per detection. You can download and use source code with functions to write those result files (C++, Matlab).
In the submission section you will be asked to choose a category (prohibitive, danger, mandatory) for your detection results. Please note that any detection of a sign that is not in that category will be counted as a false detection. For submitting the results of your detector you will have to upload a zip file. The zip file should contain the result text files of several runs with different parametrizations. The results are then evaluated and a precision-recall plot is created thereof. The precision-recall plot is always computed with all files you submitted so far.
Code snippets
- C++ Code package
- Matlab Code package (updated 01/19/2013)
Dataset
Overview
Structure
Image format
Annotation format
Result format
Pre-calculated features
Code snippets
Citation
Result analysis application
Downloads
Acknowledgements
Overview
- Single-image, multi-class classification problem
- More than 40 classes
- More than 50,000 images in total
- Large, lifelike database
- Reliable ground-truth data due to semi-automatic annotation
- Physical traffic sign instances are unique within the dataset
(i.e., each real-world traffic sign only occurs once)
Structure
The training set archive is structures as follows:
- One directory per class
- Each directory contains one CSV file with annotations ("GT-<ClassID>.csv") and the training images
- Training images are grouped by tracks
- Each track contains 30 images of one single physical traffic sign
Image format
- The images contain one traffic sign each
- Images contain a border of 10 % around the actual traffic sign (at least 5 pixels) to allow for edge-based approaches
- Images are stored in PPM format (Portable Pixmap, P6)
- Image sizes vary between 15x15 to 250x250 pixels
- Images are not necessarily squared
- The actual traffic sign is not necessarily centered within the image.This is true for images that were close to the image border in the full camera image
- The bounding box of the traffic sign is part of the annotatinos (see below)
Annotation format
Annotations are provided in CSV files. Fields are separated by ";" (semicolon). Annotations contain the following information:

- Filename: Filename of corresponding image
- Width: Width of the image
- Height: Height of the image
- ROI.x1: X-coordinate of top-left corner of traffic sign bounding box
- ROI.y1: Y-coordinate of top-left corner of traffic sign bounding box
- ROI.x2: X-coordinate of bottom-right corner of traffic sign bounding box
- ROI.y2: Y-coordinate of bottom-right corner of traffic sign bounding box
The training data annotations will additionally contain
- ClassId: Assigned class label
Important note: Before January 17, 2011, there were some errors in the annotion data. These errors only affected the the Width and Height information of the whole image (being off 1 pixel in one or both directions), not other columns like ClassId or the ROI information. Thanks to Alberto Escalante for pointing this out. The annotations have been fixed and are included in the training image archive. For those of you who already downloaded the image date set, we provide a ZIP file which contains only the updated annotation data only.
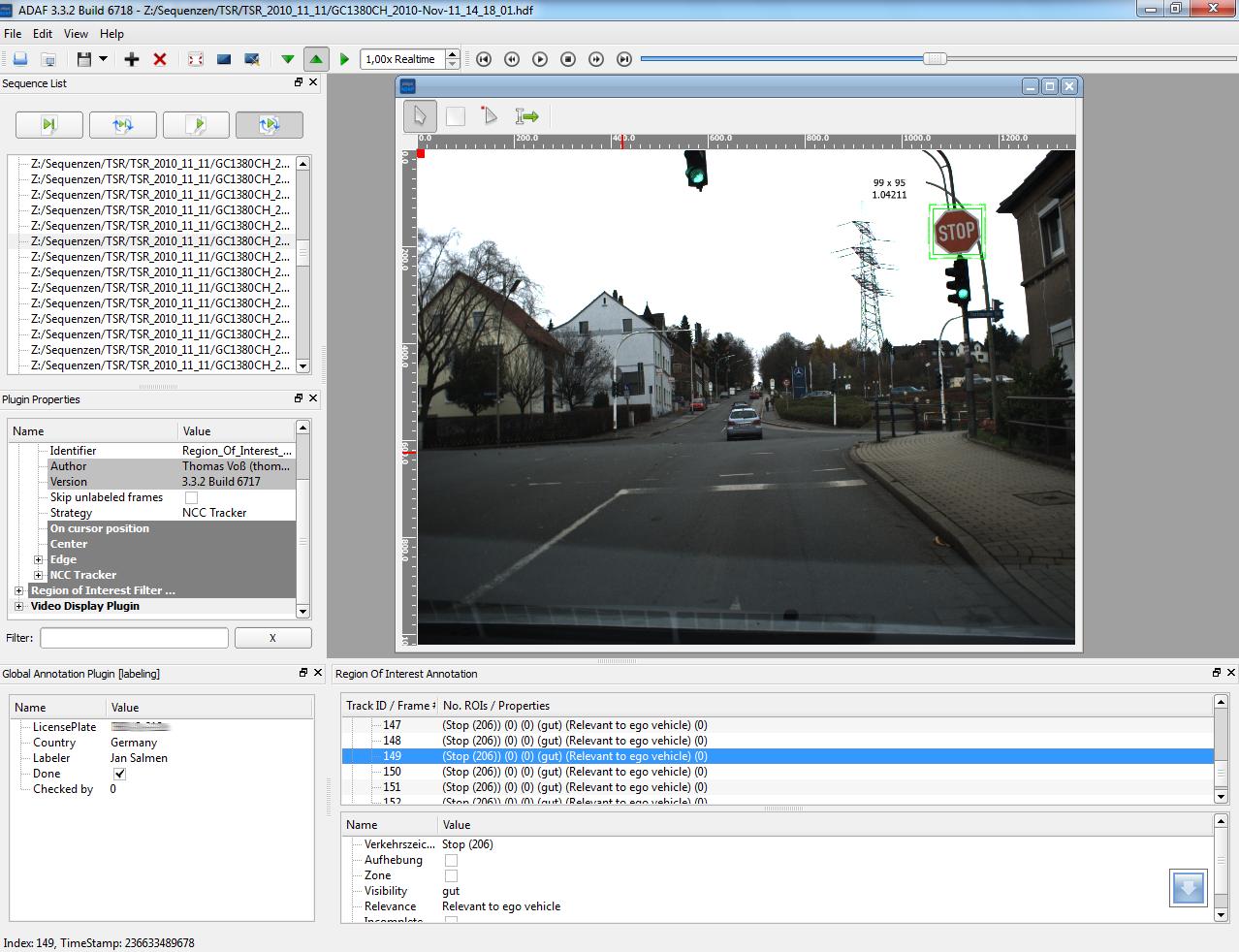
The annotations were created with Advanced Development & Analysis Framework (ADAF) by Nisys GmbH
Result format
The results will be submitted as single CSV.
It contains two columns and no header. The separator is ";"(semicolon).
There is no quoting character for the filename.
First columns is the image filename, second column is the assigned class id.
The file must contain exactly one entry per element of the test set.
Example:
00000.ppm; 4
00001.ppm; 22
00002.ppm; 16
00003.ppm; 7
00004.ppm; 6
00005.ppm; 2
........
Pre-calculated features
To allow scientists without a background in image processing to participate, we several provide pre-calculated feature sets. Each feature set contains the same directory structure as the training image set. For details on the parameters of the feature algorithm, please have a look at the file Feature_description.txt which is part of each archive file.
HOG features
The file contains three sets of differently configured HOG features (Histograms of Oriented Gradients). The sets contain feature vectors of length 1568, 1568, and 2916 respectively. The features were calculated using the source code from http://pascal.inrialpes.fr/soft/olt/. For detailed information on HOG, we refer to
N. Dalal and B. Triggs. Histograms of Oriented Gradients for Human Detection. IEEE Conference on Computer Vision and Pattern Recognition, pages 886-893, 2005
Haar-like features
The file contains one set of Haar-like features. For each image, 5 different types of Haar-like features were computed in different sizes for a total of 12 different features. The overall feature vector contains 11,584 features.
Hue Histograms
For each image in the training set, the file contains a 256-bin histogram of hue values (HSV color space).
Code snippets
Matlab
The Matlab example code provides functions to iterate over the datasets (both training and test) to read the images and the corresponding annotations.
Locations where you can easiliy hook in your training or classification method are marked in the code by dummy function calls.
Please have a look at the file Readme.txt in the ZIP file for more details
C++
The C++ example code demonstrates how to to train a linear classifier (LDA) using the Shark machine learning library.
This code uses the precalculated features. It was used to generate the baseline results.
Please have a look at the file Readme.txt in the ZIP file for more details
Python
The Python example code provides a function to iterate over the training set to read the images and the corresponding class id.
The code depends on matplotlib. Please have a look at the file Readme.txt in the ZIP file for more details
Citation
The data is free to use. However, we cordially ask you to cite the following publication if you do:
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel. The German Traffic Sign Recognition Benchmark: A multi-class classification competition. In Proceedings of the IEEE International Joint Conference on Neural Networks , pages 1453–1460. 2011.
Thank you.
Result Analysis Application
We provide a simple application to facilitate result analysis. It allows you to compare different approaches, analyse the confusion matices and inspect which images were classified correctly.
The software is supplied under GPLv2 . It depends on Qt 4.7 , which is available here in source code and binary form. Qt is licensed under LGPL. Qt is a trademark of Nokia Corporation.
The software is provided as source code . The files can be found in the download section . The code is platform-independent, however, it has only been tested on Microsoft Windows with Visual Studio. So there might be a couple of issues left where GCC is more strict than Visual Studio. We appreciate any comments, patches and bug reports.
The project uses CMake , an open-source, cross-platform build system which allows you to generate project files/makefiles for your preferred compiler toolchain.
Here are some screenshots to get an idea of this tool.
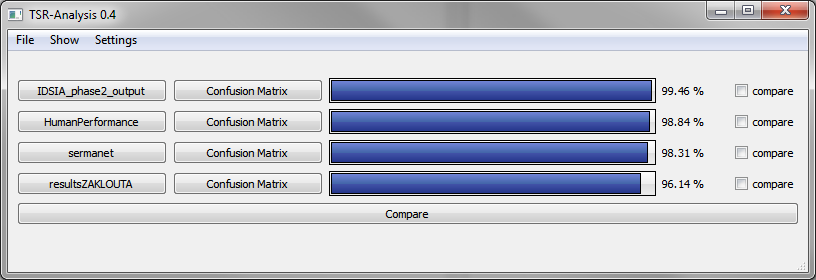
Main window: Performance of one or more approaches
Compare multiple approaches and on which images they erred
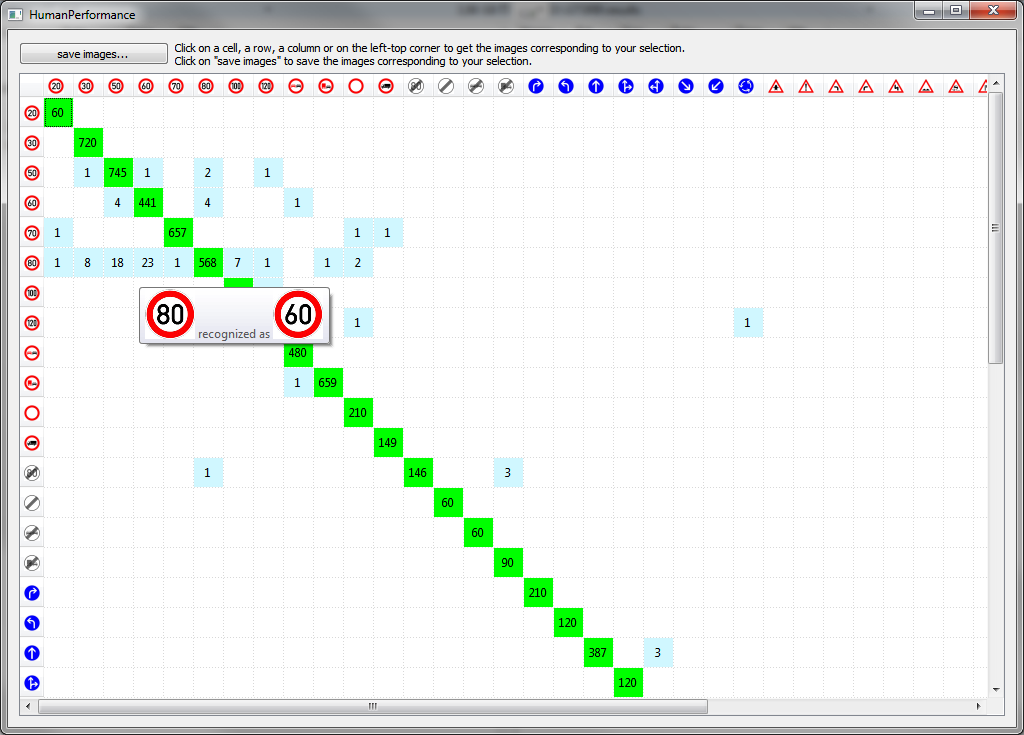
Confusion matrix: See which classes got confused.
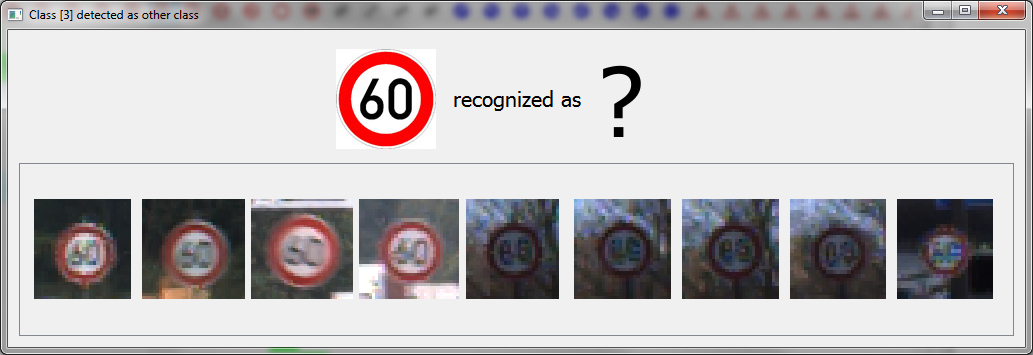
Clicking cells, rows or columns in the confusion matrix shows which images were misclassified.
Here: All "Speed limit 60" images that were incorrectly classified as some other class.
Downloads
Training dataset
This is the official GTSRB training set. If you either intend to participate in the final competition session at IJCNN 2011 or you want to publish experimental results based on GTRSB data, you must use this dataset for training.
The training data set contains 39,209 training images in 43 classes.
- Images and annotations: Download (263 MB)
- Three sets of different HOG features: Download (870 MB)
- Haar-like features: Download (944 MB)
- Hue histograms: Download (17 MB)
Test dataset
Thís is the official GTSRB test set. It was first published at IJCNN 2011 during the special session "Traffic Sign Recognition for Machine Learning". All experimental results that are reported on GTSRB data must use this dataset for testing (apart from the ones already published at IJCNN 2011). The structure of the dataset follows the test set that was published for the online competition (and is now part of the training data).
The test dataset contains 12,630 test images or the corresponding pre-calculated features in random order.
- Images and annotations: Download (84 MB)
- Three sets of different HOG features: Download (278 MB)
- Haar-like features: Download (304 MB)
- Hue histograms: Download (5 MB)
- Extended annotations including class ids: Download (98 kB)
Training dataset(online-competition only!)
This was the training set during the online competition stage of GTSRB. It is kept for reproducibilty reasons. If you want to report experimental results on the GTSRB data, make sure to download the official/final training dataset (see above). It comprises this dataset and the online competition test data (see below).
The training data set contains 26,640 training images in 43 classes.
- Images and annotations: Download (178 MB)
- Fixed annotations(already included in image archive, only required, if you downloaded the image training set before January 17, 2011): Download (217 kB)
- Three sets of different HOG features: Download (527 MB)
- Haar-like features: Download (595 MB)
- Hue histograms: Download (14 MB)
Test dataset (online-competition only!)
This was the test set during the online competition stage of GTSRB. It is kept for reproducibilty reasons. If you want to report experimental results on the GTSRB data, make sure to download the official/final test dataset (see above) which consists of fresh data. The testset below is part of the final training dataset and may not be used to report official results on the GTSRB dataset.
The test dataset contains 12,569 test images or the corresponding pre-calculated features in random order.
- Images and annotations: Download (84 MB)
- Three sets of different HOG features: Download (282 MB)
- Haar-like features: Download (304 MB)
- Hue histograms: Download (5 MB)
- Extended annotations including class ids: Download (102 kB)
- Sorted testsets (i.e., same directory and filename structure as the training set, elements are sorted by class and track):
- Images and annotations: Download (84 MB)
- HOG features: Download (282 MB)
- Haar-like features: Download (304 MB)
- Hue histograms: Download (5 MB)
Code
- Example code for Matlab to read all training and test images including annotations: Download
- Example code for C++ to train a LDA classifier using the Shark machine learning library: Download
- Example code for Python to read all training images: Download
Result analysis application
The code is platform-independent, however, it has only been tested Visual Studio. So there might be a couple of issues left where GCC is more strict than Visual Studio.
We appreciate any comments, patches and bug reports. The code uses CMake, an open-source, cross-platform build system which allows you to generate project files/makefiles for your preferred compiler toolchain.
- Readme.txt
- Source code: tsr-analysis-src.zip (503 kB)
Make sure to check the news page regularly for updates. If you sign up, you will be notified about important updates by email.
Acknowledgements
We would not have been able to provide this benchmark dataset without the extensive and valuable help of others.
Many thanks to Lukas Caup, Sebastian Houben, Lukas Kubik, Bastian Petzka, Stefan Tenbült, Marc Tschentscher for their annotation support, to Sebastian Houben for providing the Matlab code samples, Lukas Kubik and especially Bastian Petzka for creation of this web site.
![]()
Furthermore, we thank Nisys GmbH for their support and for providing the Advanced Development & Analysis Framework.
德国交通标志检测识别数据集相关推荐
- 德国交通标志检测基准
德国交通标志检测基准是对研究员噶兴趣的计算机视觉,模式识别和基于图像的驾驶员辅助领域的单图像检测评估. 它是在IEEE国际神经网络联合会议上推出的.它的特点是 ... 单图像检测 900个图像 (分为 ...
- 基于Yolov5的交通标志检测识别设计
项目介绍 上一篇文章介绍了基于卷积神经网络的交通标志分类识别Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow),并且最后实现了一个pyqt5的GUI界面,并且还制作了一个简单 ...
- 中国交通标志检测数据集(CCTSDB)【新增测试数据】
作者已经更新了测速数据,同时修改了存在的问题. 中国交通标志检测数据集(CCTSDB)来源于 A Real-Time Chinese Traffic Sign Detection Algorithm ...
- 德国交通标志识别数据集GTSRB
德国交通标志识别数据集GTSRB* 交通标图片来源于网站:German Traffic Sign Benchmarks 访问较慢 本人提供一下完整数据集包括测试集和训练集及对应的label数据sign ...
- 【目标检测】基于yolov5的交通标志检测和识别(附代码和数据集)
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌. 文末附项目代码和数据集,请看检测效果: 1. 介绍 Y ...
- 【目标检测】基于yolov3交通标志检测和识别(附代码和数据集)
Hello,大家好,我是augustqi.今天给大家分享的目标检测项目是:基于yolov3交通标志检测和识别(附代码和数据集)[目前yolov7都出来了,为什么要用2018年的yolov3呢?因为我想 ...
- TSR交通标志检测与识别
TSR交通标志检测与识别 说明: 传统图像处理算法的TSR集成在在ARM+DSP上运行,深度学习开发的TSR集成到FPGA上运行. 输入输出接口 Input: (1)图像视频分辨率(整型int) (2 ...
- 计算机识别技术检测交通标志,基于计算机视觉的交通标志检测与识别算法研究...
摘要: 据有关数据统计,2017年全国道路交通事故中死亡率达到18.2%,因此交通安全问题已经成为我们日常生活中最常见的问题.而解决交通事故问题的有效途径之一就是准确有效的识别道路交通标志,目前,人工 ...
- 数字图像处理之校园交通标志检测与识别
文章目录 背景综述 设计目的 实现过程 第一步为了更好地进行信息的交互,需要先设计基于Matlab的GUI界面设计 第二步其次我们需要读入含有交通标志的图像 第三步接下来是对原始图像进行高斯滤波 第四 ...
最新文章
- linux 磁盘诡异的被占用
- Jackson解析JavaBean空值不显示问题
- 同一台服务器上面安装多个mysql数据库
- 63.死锁和死锁的原因
- 代码生成工具CodeSmith中SchemaExplorer类API文档[转]
- [pymongo] pymongo.errors.CursorNotFound Exception
- a+=b 等价于 a=a+b ?
- mongodb连接失败_深入浅出mongodb(一)
- aes加密算法_令你的文件安全有了新方法AES-256-GCM加密网站免费用
- java基础----Java中枚举的使用(一)
- MVC HtmlHelper listbox用法
- 6.4 tensorflow2实现FNN推荐系统——Python实战(第一篇)
- SylixOS原子量操作
- PdgCntEditor一键生成PDF书签目录
- pytorch例子学习——NEURAL TRANSFER USING PYTORCH神经迁移
- 速抢:500份粉丝购书优惠券
- iOS8定位问题解决方案
- 【MySQL】MySQL复制技术
- python实现 把列表中数字0移动到末尾
- Doevents用法