架构面试精讲第三节 分布式技术RPC、MQ、Redis、Mysql、restful详解
07 RPC:如何在面试中展现出“造轮子”的能力?
我们知道,很多应用系统发展到一定规模之后,都会向着服务化方向演进,演进后的单体系统就变成了由一个个微服务组成的服务化系统,各个微服务系统之间通过远程 RPC 调用的方式通信。
可以说,RPC 是微服务架构的基础,从事互联网系统开发,就离不开 RPC 框架,所以这一讲,我们就立足面试场景下对 RPC 技术的考察,来讲解你要掌握的技术点和面试思路。
案例背景
主流的 RPC 框架很多,比如 Dubbo、Thrift、gRPC 等,非主流的框架你在 GitHub 上搜索也有很多结果。框架资源多,很多同学在工作中的选择也多,基本上都是拿来就用,停留在基础概念和使用上,不会深究技术实现。
所以很多候选人对于 RPC 有关的面试问题存在一个误区,认为面试官只会问这样几个问题:
RPC 的一次调用过程是怎样的?
RPC 的服务发现是如何实现的?
RPC 的负载均衡有哪些?
……
这些问题看似专业,却很容易搜索到答案,如果作为面试题很难区分候选人的技术能力。所以针对 RPC 的技术考察,目前大多数面试官会从“实践操作 + 原理掌握”两个角度出发,递进地考察候选人。
具体怎么考察呢?我们接着往下看。
RPC 实践操作
面试官通常会从线上的实际案例出发,考察候选人对“实践操作”的掌握程度。举个例子:在电商 App 商品详情页中,用户每次刷新页面时,App 都会请求业务网关系统,并由网关系统远程调用多个下游服务(比如商品服务、促销服务、广告服务等)。
针对这个场景,面试官会问“对于整条 RPC 调用链路(从 App 到网关再到各个服务系统),怎么设置 RPC 的超时时间,要考虑哪些问题?”
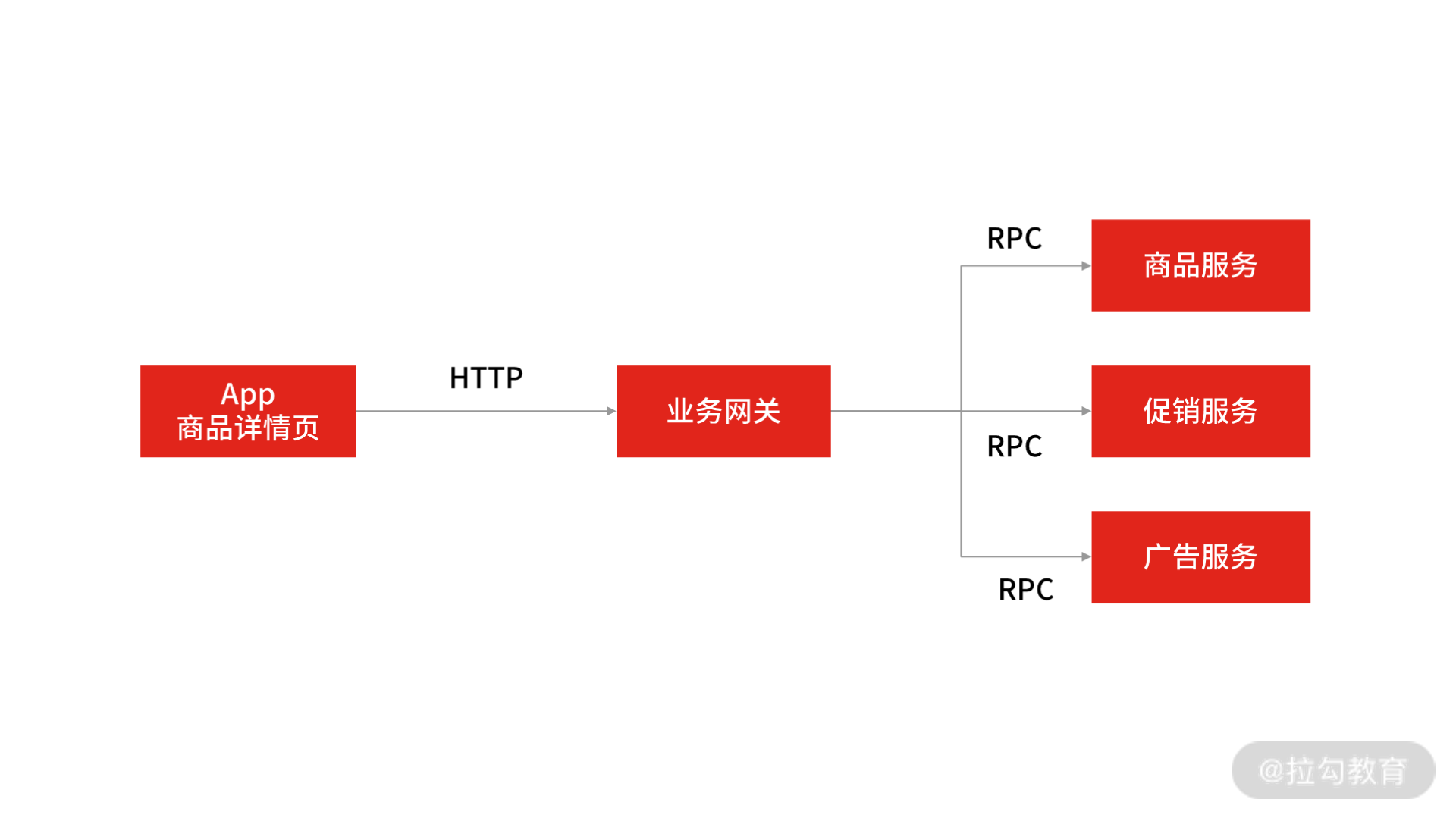
App 商品详情页服务调用
一些初中级研发会觉得问题很简单,不用想也知道:App 远程调用网关系统的超时时间要大于网关系统调用后端各服务的超时时间之和。这样至少能保证在网关与下游服务的每个 PRC 调用执行完成之前不超时。
如果你这么回答,从“实践”的角度上看,基本是不合格的。
因为 PRC 接口的超时设置看似简单,但其中却涉及了很多技术层面的问题。比如 RPC 都有超时重传的机制,如果后端服务触发超时重传,这时对 App 来说,也会存在请求等待超时的风险,就会出现后端服务还没来得及做降级处理,商品详情页就已经等待超时了。
并且在 RPC 调用的过程中也还会涉及其他的技术点,比如:
即使考虑到整个调用链的平均响应时长会受到所有依赖服务的耗时和重传次数影响,那么依据什么来设置 RPC 超时时间和重试次数呢?
如果发生超时重传,怎么区分哪些 RPC 服务可重传,哪些不可重传呢?
如果请求超过了 PRC 的重传次数,一般会触发服务降级,这又会对商品详情页造成什么影响?
......
总的来说,任何一个微服务出现性能问题,都会影响网关系统的平均响应时长,最终对 App 产生影响。所以从 RPC 接口的超时问题上,面试官会考察候选人很多深层次的开发实践能力。
那具体要怎么回答呢?我建议你参考以下解题思路。
结合 TP99 请求耗时:首先如果你要回答“超时时间设置和重传次数问题”,需要根据每一个微服务 TP99 的请求耗时,以及业务场景进行综合衡量。
RPC 调用方式:你要站在业务场景下,讲清楚网关调用各下游服务的串并行方式,服务之间是否存在上下服务依赖。
分析核心服务:分析出哪些是核心服务,哪些是非核心服务,核心服务是否有备用方案,非核心服务是否有降级策略。
总的来讲,解答“实践操作类面试题”,一定要结合理论和落地实践,要做到即有理也有据,有理表示要有分析问题的能力,有据表示具备落地实战的经验。很多同学的通病是:回答问题只有方案,没有落地细节,这会让面试官认为你技术不扎实。
进一步,如果面试官觉得你“实践问题”答得不错,会深入考察你对 RPC 的原理性知识的掌握情况。
RPC 原理掌握
以刚刚的“电商 App”场景为例:
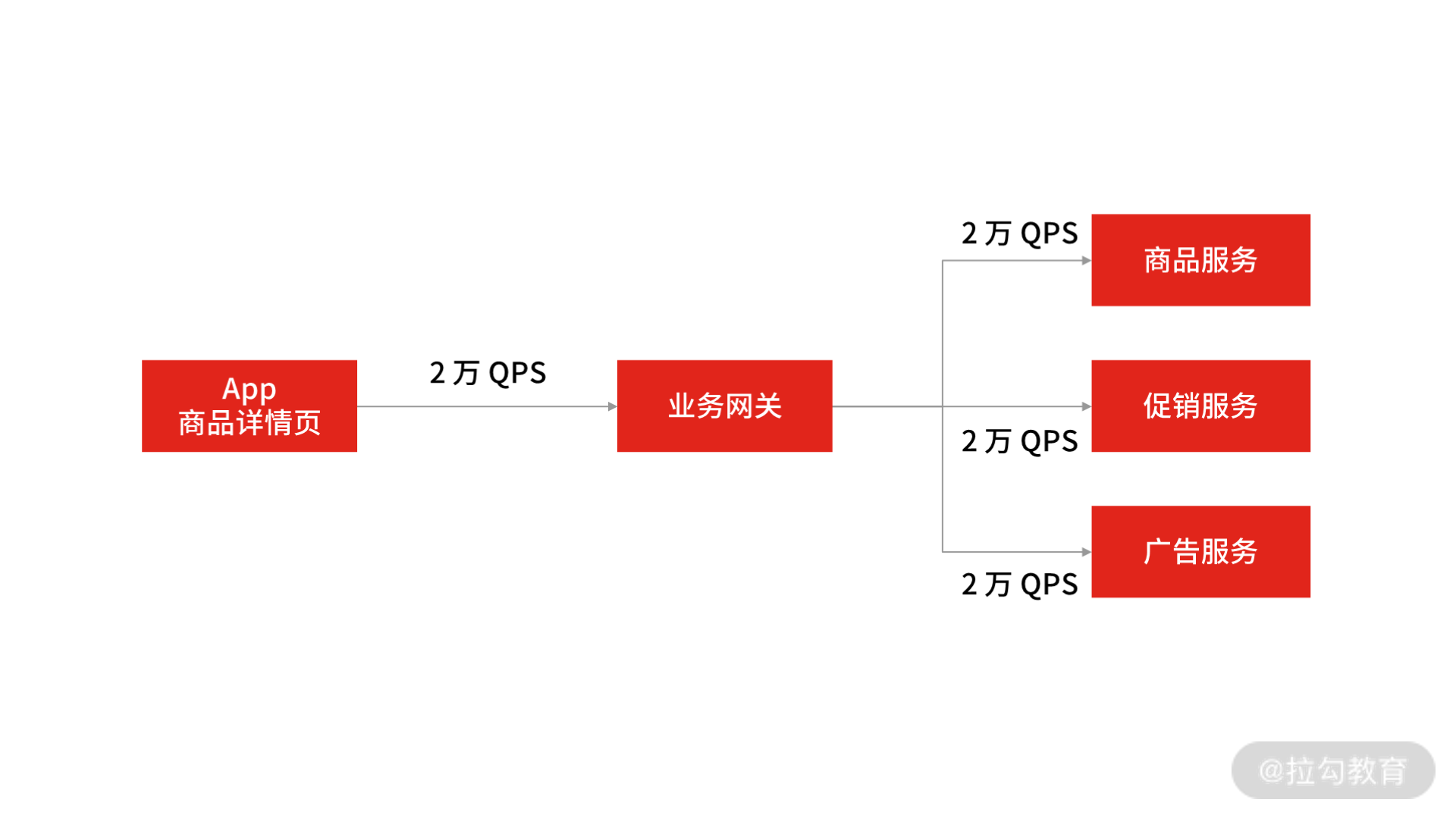
App 商品详情页服务调用
此时,商品详情页的 QPS 已达到了 2 万次/s,在做了服务化拆分之后,此时完成一次请求需要调用 3 次 RPC 服务,计算下来,RPC 服务需要承载大概 6 万次/s 的请求。那么你怎么设计 RPC 框架才能承载 6 万次/s 请求量呢?
能否答好这个问题,很考验候选人对 RPC 原理掌握的深度,我建议你从两个角度分析。
优化 RPC 的网络通信性能: 高并发下选择高性能的网络编程 I/O 模型。
选型合适的 RPC 序列化方式: 选择合适的序列化方式,进而提升封包和解包的性能。
然而我在面试候选人时发现,一些同学虽然做了准备,但只能说出个别 RPC 框架的大致流程,不能深刻理解每个环节的工作原理,所以整体给我的感觉就是:应用层面通过,原理深度不够。
而我对你的要求是:对于中间件等技术工具和框架,虽然在实际工作中不推荐重复“造轮子”,但在面试中要证明自己具备“造轮子”的能力,因为要评价一个程序员是否对技术栈有全面的认识,考察其“造轮子”的能力是一个不错的切入点。
接下来我们先理解一下完整的 RPC 会涉及哪些步骤,然后再解析其中的重要环节,搞懂 RPC 原理的考察点。
一次完整的 RPC 流程
因为 RPC 是远程调用,首先会涉及网络通信, 又因为 RPC 用于业务系统之间的数据交互,要保证数据传输的可靠性,所以它一般默认采用 TCP 来实现网络数据传输。
网络传输的数据必须是二进制数据,可是在 RPC 框架中,调用方请求的出入参数都是对象,对象不能直接在网络中传输,所以需要提前把对象转成可传输的二进制数据,转换算法还要可逆,这个过程就叫“序列化”和“反序列化”。
另外,在网络传输中,RPC 不会把请求参数的所有二进制数据一起发送到服务提供方机器上,而是拆分成好几个数据包(或者把好几个数据包封装成一个数据包),所以服务提供方可能一次获取多个或半个数据包,这也就是网络传输中的粘包和半包问题。为了解决这个问题,需要提前约定传输数据的格式,即“RPC 协议”。 大多数的协议会分成数据头和消息体:
数据头一般用于身份识别,包括协议标识、数据大小、请求类型、序列化类型等信息;
消息体主要是请求的业务参数信息和扩展属性等。
在确定好“ RPC 协议”后,一次完整的 RPC 调用会经过这样几个步骤:
调用方持续把请求参数对象序列化成二进制数据,经过 TCP 传输到服务提供方;
服务提供方从 TCP 通道里面接收到二进制数据;
根据 RPC 协议,服务提供方将二进制数据分割出不同的请求数据,经过反序列化将二进制数据逆向还原出请求对象,找到对应的实现类,完成真正的方法调用;
然后服务提供方再把执行结果序列化后,回写到对应的 TCP 通道里面;
调用方获取到应答的数据包后,再反序列化成应答对象。
这样调用方就完成了一次 RPC 调用。
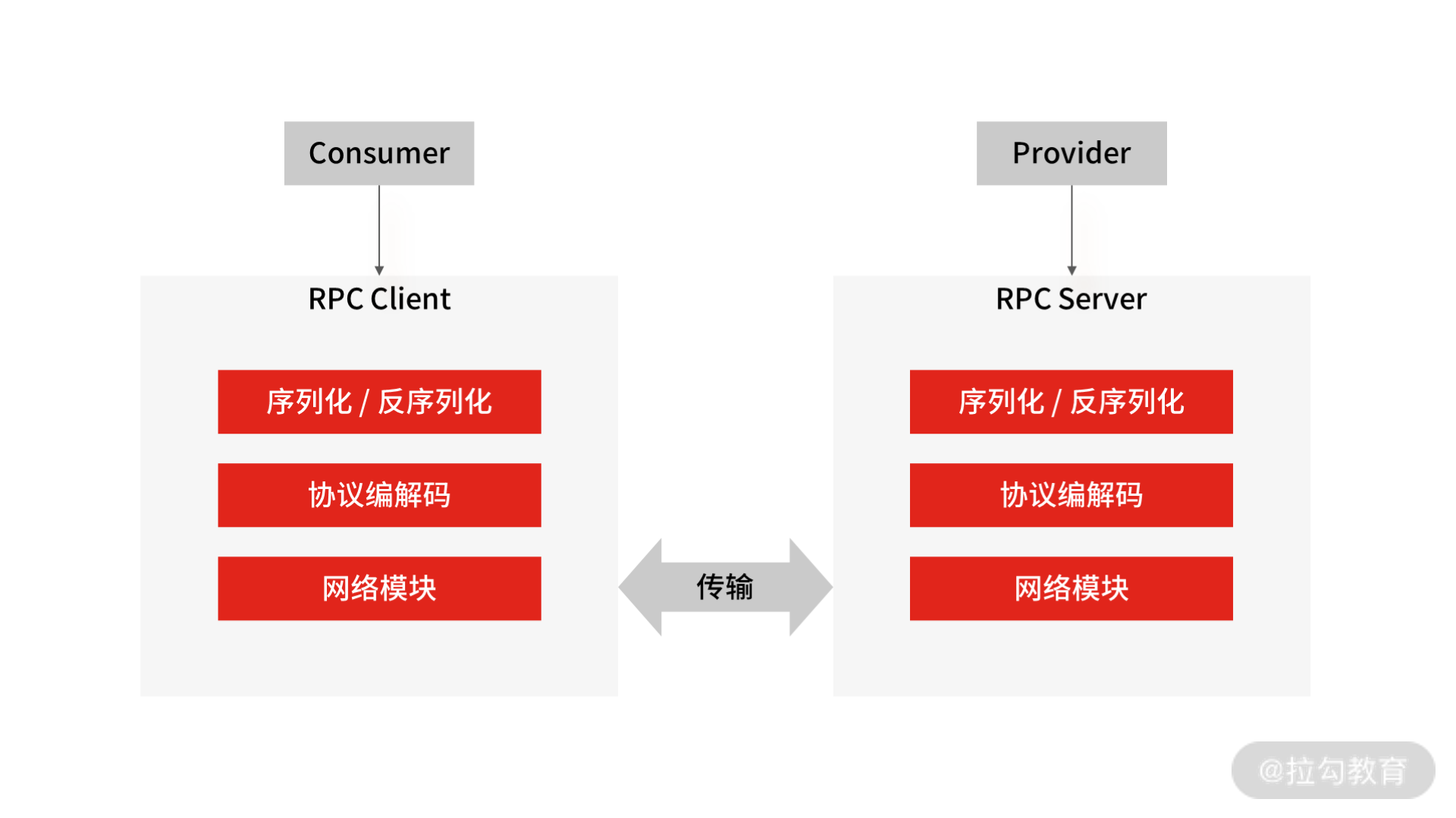
RPC 通信流程
你应该能发现, RPC 通信流程中的核心组成部分包括了协议、序列化与反序列化,以及网络通信。在了解了 RPC 的调用流程后,我们回到“电商 App”的案例中,先来解答序列化的问题。
如何选型序列化方式
RPC 的调用过程会涉及网络数据(二进制数据)的传输,从中延伸的问题是:如何选型序列化和反序列化方式?
要想回答这一点,你需要先明确序列化方式,常见的方式有以下几种。
JSON:Key-Value 结构的文本序列化框架,易用且应用最广泛,基于 HTTP 协议的 RPC 框架都会选择 JSON 序列化方式,但它的空间开销很大,在通信时需要更多的内存。
Hessian:一种紧凑的二进制序列化框架,在性能和体积上表现比较好。
Protobuf:Google 公司的序列化标准,序列化后体积相比 JSON、Hessian 还要小,兼容性也做得不错。
明确“常见的序列化方式”后,你就可以组织回答问题的逻辑了:考虑时间与空间开销,切勿忽略兼容性。
在大量并发请求下,如果序列化的速度慢,势必会增加请求和响应的时间(时间开销)。另外,如果序列化后的传输数据体积较大,也会使网络吞吐量下降(空间开销)。所以,你要先考虑上述两点才能保证 RPC 框架的整体性能。除此之外,在 RPC 迭代中,常常会因为序列化协议的兼容性问题使 RPC 框架不稳定,比如某个类型为集合类的入参服务调用者不能解析,某个类的一个属性不能正常调用......
当然还有安全性、易用性等指标,不过并不是 RPC 的关键指标。总的来说,在面试时,你要综合考虑上述因素,总结出常用序列化协议的选型标准,比如首选 Hessian 与 Protobuf,因为它们在时间开销、空间开销、兼容性等关键指标上表现良好。
如何提升网络通信性能
如何提升 RPC 的网络通信性能,这句话翻译一下就是:一个 RPC 框架如何选择高性能的网络编程 I/O 模型?这样一来,和 I/O 模型相关的知识点就是你需要掌握的了。
对于 RPC 网络通信问题,你首先要掌握网络编程中的五个 I/O 模型:
同步阻塞 I/O(BIO)
同步非阻塞 I/O
I/O 多路复用(NIO)
信号驱动
以及异步 I/O(AIO)
但在实际开发工作,最为常用的是 BIO 和 NIO(这两个 I/O 模型也是面试中面试官最常考察候选人的)。为了让你更好地理解编程模型中,这两个 I/O 模型典型的技术实现,我以 Java 程序例,编程写了一个简单的网络程序:
public class BIOSever {ServerSocket ss = new ServerSocket();// 绑定端口 9090ss.bind(new InetSocketAddress("localhost", 9090));System.out.println("server started listening " + PORT);try {Socket s = null;while (true) {// 阻塞等待客户端发送连接请求s = ss.accept();new Thread(new ServerTaskThread(s)).start();}} catch (Exception e) {// 省略代码...} finally {if (ss != null) {ss.close();ss = null;}
}
public class ServerTaskThread implements Runnable {// 省略代码...while (true) {// 阻塞等待客户端发请求过来String readLine = in.readLine();if (readLine == null) {break;}// 省略代码...}// 省略代码...
}
这段代码的主要逻辑是: 在服务端创建一个 ServerSocket 对象,绑定 9090 端口,然后启动运行,阻塞等待客户端发起连接请求,直到有客户端的连接发送过来后,accept() 方法返回。当有客户端的连接请求后,服务端会启动一个新线程 ServerTaskThread,用新创建的线程去处理当前用户的读写操作。
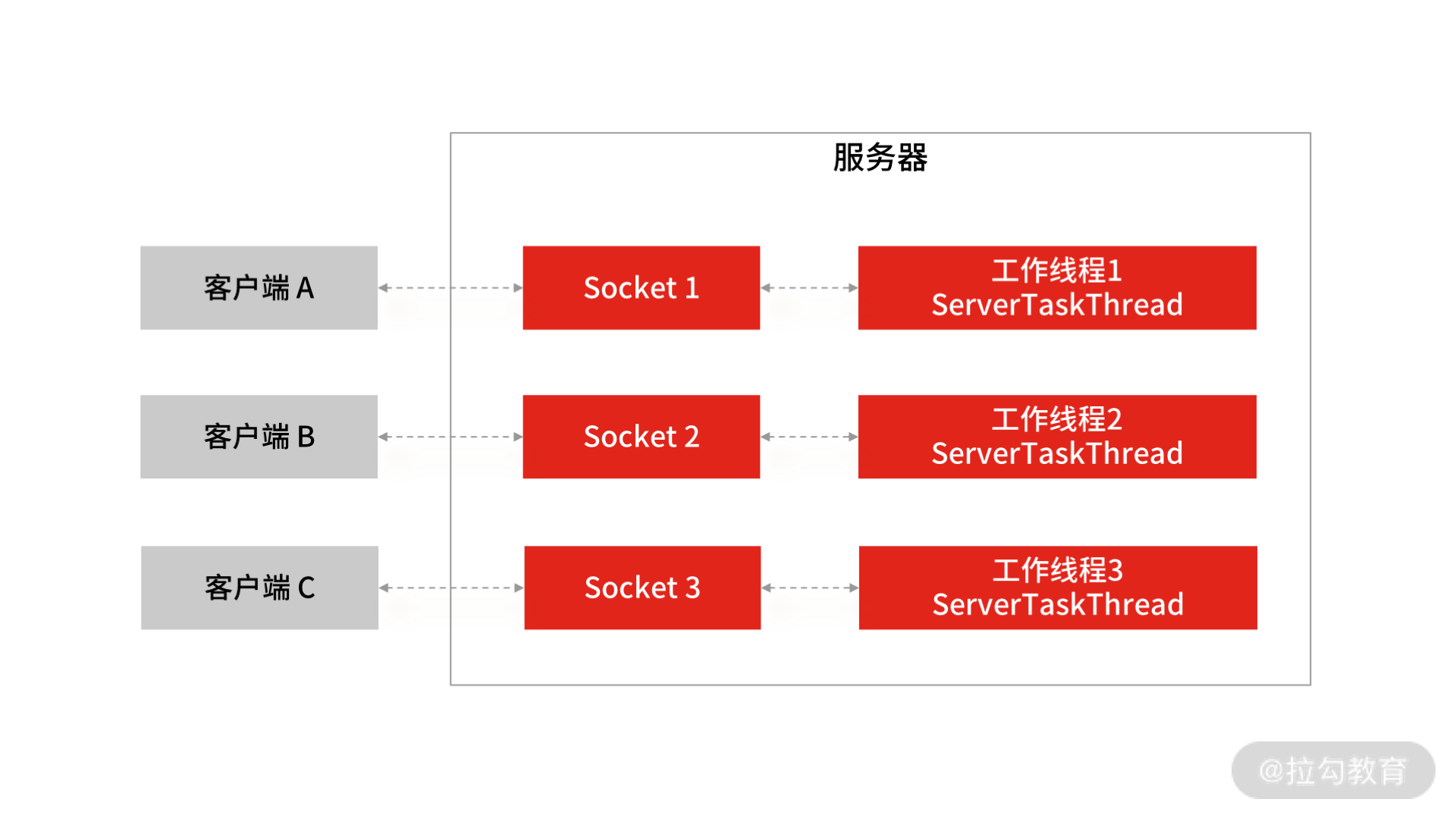
BIO 网络模型
所以,BIO 的网络模型中,每当客户端发送一个连接请求给服务端,服务端都会启动一个新的线程去处理客户端连接的读写操作,即每个 Socket 都对应一个独立的线程,客户端 Socket 和服务端工作线程的数量是 1 比 1,这会导致服务器的资源不够用,无法实现高并发下的网络开发。所以 BIO 的网络模型只适用于 Socket 连接不多的场景,无法支撑几十甚至上百万的连接场景。
另外,BIO 模型有两处阻塞的地方。
服务端阻塞等待客户端发起连接。在第 11 行代码中,通过 serverSocket.accept() 方法服务端等待用户发连接请求过来。
连接成功后,工作线程阻塞读取客户端 Socket 发送数据。在第 27 行代码中,通过 in.readLine() 服务端从网络中读客户端发送过来的数据,这个地方也会阻塞。如果客户端已经和服务端建立了一个连接,但客户端迟迟不发送数据,那么服务端的 readLine() 操作会一直阻塞,造成资源浪费。
以上这些就是 BIO 网络模型的问题所在,总结下来就两点:
Socket 连接数量受限,不适用于高并发场景;
有两处阻塞,分别是等待用户发起连接,和等待用户发送数据。
那怎么解决这个问题呢? 答案是 NIO 网络模型,操作上是用一个线程处理多个连接,使得每一个工作线程都可以处理多个客户端的 Socket 请求,这样工作线程的利用率就能得到提升,所需的工作线程数量也随之减少。此时 NIO 的线程模型就变为 1 个工作线程对应多个客户端 Socket 的请求,这就是所谓的 I/O多路复用。
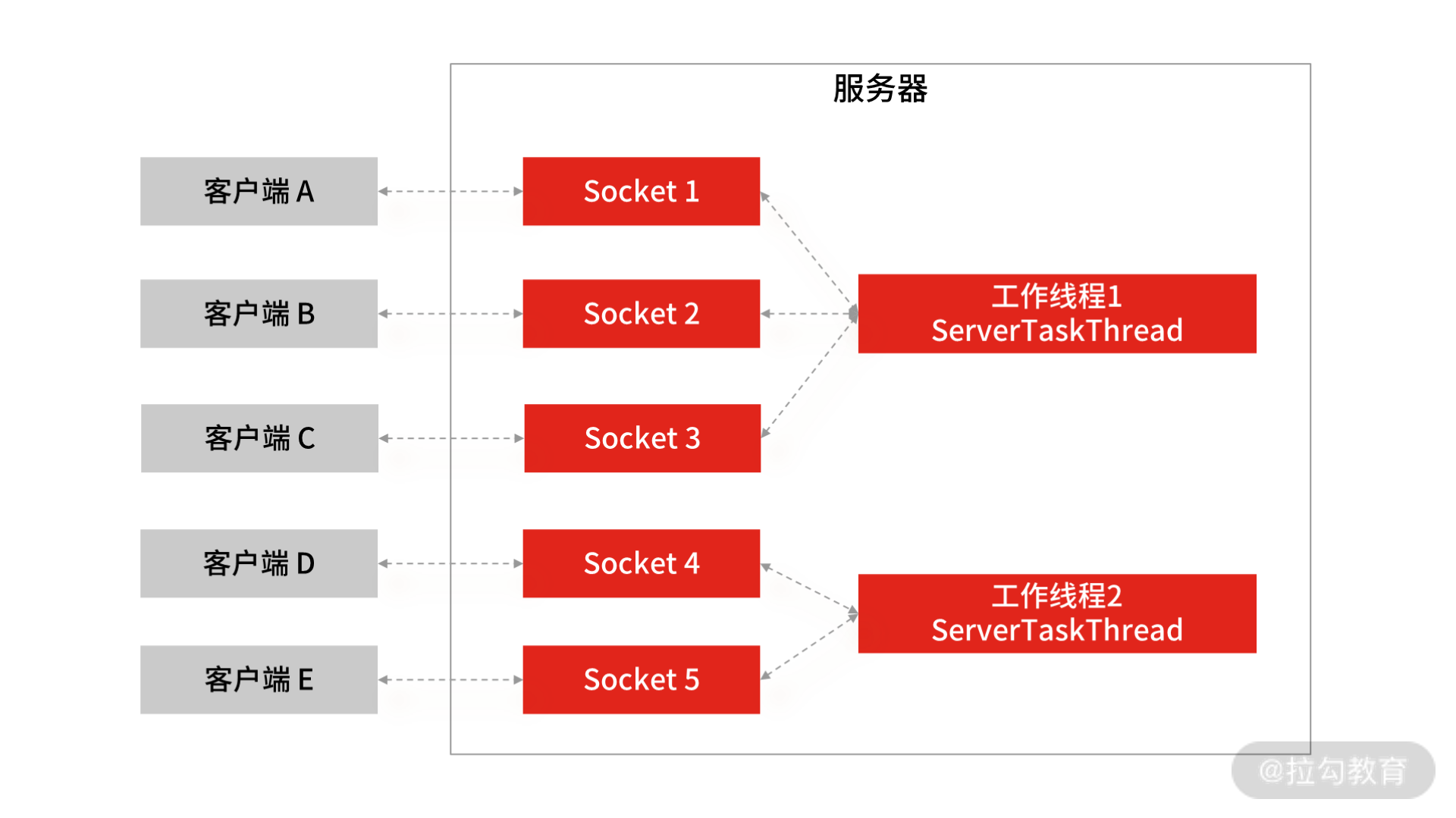
NIO 网络模型
顺着这个思路,我们继续深入思考:既然服务端的工作线程可以服务于多个客户端的连接请求,那么具体由哪个工作线程服务于哪个客户端请求呢?
这时就需要一个调度者去监控所有的客户端连接,比如当图中的客户端 A 的输入已经准备好后,就由这个调度者去通知服务端的工作线程,告诉它们由工作线程 1 去服务于客户端 A 的请求。这种思路就是 NIO 编程模型的基本原理,调度者就是 Selector 选择器。
由此可见,NIO 比 BIO 提高了服务端工作线程的利用率,并增加了一个调度者,来实现 Socket 连接与 Socket 数据读写之间的分离。
在目前主流的 RPC 框架中,广泛使用的也是 I/O 多路复用模型,Linux 系统中的 select、poll、epoll等系统调用都是 I/O 多路复用的机制。
在面试中,对于高级研发工程师的考察,还会有两个技术扩展考核点。
Reactor 模型(即反应堆模式),以及 Reactor 的 3 种线程模型,分别是单线程 Reactor 线程模型、多线程 Reactor 线程模型,以及主从 Reactor 线程模型。
Java 中的高性能网络编程框架 Netty。
可以这么说,在高性能网络编程中,大多数都是基于 Reactor 模式,其中最为典型的是 Java 的 Netty 框架,而 Reactor 模式是基于 I/O 多路复用的,所以,对于 Reactor 和 Netty 的考察也是避免不了的。因为相关资料很多,我就不展开了,你可以在课下补充这部分的知识,并在留言区与我交流。
总结
这一讲,我带你了解了面试官考察 RPC 技术的套路,无论是初中级还是高级研发工程师,都需要掌握这一讲的内容。
在“实践操作”中,我带你通过“如何设置 RPC 超时时间”的场景,学习了在微服务系统中,系统整体的平均响应时长,会受到所有依赖服务接口的耗时和重传次数影响。
在“原理掌握”中,我通过“商品详情页”的案例,引出 RPC 框架的原理与核心功能,如网络通信模型的选型、序列化和反序列化框架的选型等。
最后,我还是要强调一下,程序员一定要具备造轮子的能力,目的是突破技术栈瓶颈,因为技术只有动手实践过,才能有更加全面和深入的思考。学完这一讲后,我建议你阅读一些成熟的 RPC 框架的源代码,比如阿里开源的 Dubbo,或 Google 的 gRPC。
当然在实际工作中,一个产品级别的 RPC 框架的开发,除了要具备网络通信、序列化和反序列化、协议等基础的功能之外,还要具备如连接管理、负载均衡、请求路由、熔断降级、优雅关闭等高级功能的设计,虽然这些内容在面试中不要求你掌握,但是如果你了解是可以作为加分项的,例如连接管理就会涉及连接数的维护与服务心跳检测。
本节课的思考题是:结合你在工作中使用 RPC 框架的时候,遇到过什么问题,你是怎么解决的?我们下期再会!
08 MQ:如何回答消息队列的丢失、重复与积压问题
这一讲,我们将围绕 MQ 消息中间件,讨论你经常被问到的高频设计问题。
面试官在面试候选人时,如果发现候选人的简历中写了在项目中使用了 MQ 技术(如 Kafka、RabbitMQ、RocketMQ),基本都会抛出一个问题:在使用 MQ 的时候,怎么确保消息 100% 不丢失?
这个问题在实际工作中很常见,既能考察候选者对于 MQ 中间件技术的掌握程度,又能很好地区分候选人的能力水平。接下来,我们就从这个问题出发,探讨你应该掌握的基础知识和答题思路,以及延伸的面试考点。
案例背景
以京东系统为例,用户在购买商品时,通常会选择用京豆抵扣一部分的金额,在这个过程中,交易服务和京豆服务通过 MQ 消息队列进行通信。在下单时,交易服务发送“扣减账户 X 100 个京豆”的消息给 MQ 消息队列,而京豆服务则在消费端消费这条命令,实现真正的扣减操作。

那在这个过程中你会遇到什么问题呢?
案例分析
要知道,在互联网面试中,引入 MQ 消息中间件最直接的目的是:做系统解耦合流量控制,追其根源还是为了解决互联网系统的高可用和高性能问题。
系统解耦:用 MQ 消息队列,可以隔离系统上下游环境变化带来的不稳定因素,比如京豆服务的系统需求无论如何变化,交易服务不用做任何改变,即使当京豆服务出现故障,主交易流程也可以将京豆服务降级,实现交易服务和京豆服务的解耦,做到了系统的高可用。
流量控制:遇到秒杀等流量突增的场景,通过 MQ 还可以实现流量的“削峰填谷”的作用,可以根据下游的处理能力自动调节流量。
不过引入 MQ 虽然实现了系统解耦合流量控制,也会带来其他问题。
引入 MQ 消息中间件实现系统解耦,会影响系统之间数据传输的一致性。 我们在 04 讲提到过,在分布式系统中,如果两个节点之间存在数据同步,就会带来数据一致性的问题。同理,在这一讲你要解决的就是:消息生产端和消息消费端的消息数据一致性问题(也就是如何确保消息不丢失)。
而引入 MQ 消息中间件解决流量控制, 会使消费端处理能力不足从而导致消息积压,这也是你要解决的问题。
所以你能发现,问题与问题之间往往是环环相扣的,面试官会借机考察你解决问题思路的连贯性和知识体系的掌握程度。
那面对“在使用 MQ 消息队列时,如何确保消息不丢失”这个问题时,你要怎么回答呢?首先,你要分析其中有几个考点,比如:
如何知道有消息丢失?
哪些环节可能丢消息?
如何确保消息不丢失?
候选人在回答时,要先让面试官知道你的分析思路,然后再提供解决方案: 网络中的数据传输不可靠,想要解决如何不丢消息的问题,首先要知道哪些环节可能丢消息,以及我们如何知道消息是否丢失了,最后才是解决方案(而不是上来就直接说自己的解决方案)。就好比“架构设计”“架构”体现了架构师的思考过程,而“设计”才是最后的解决方案,两者缺一不可。
案例解答
我们首先来看消息丢失的环节,一条消息从生产到消费完成这个过程,可以划分三个阶段,分别为消息生产阶段,消息存储阶段和消息消费阶段。
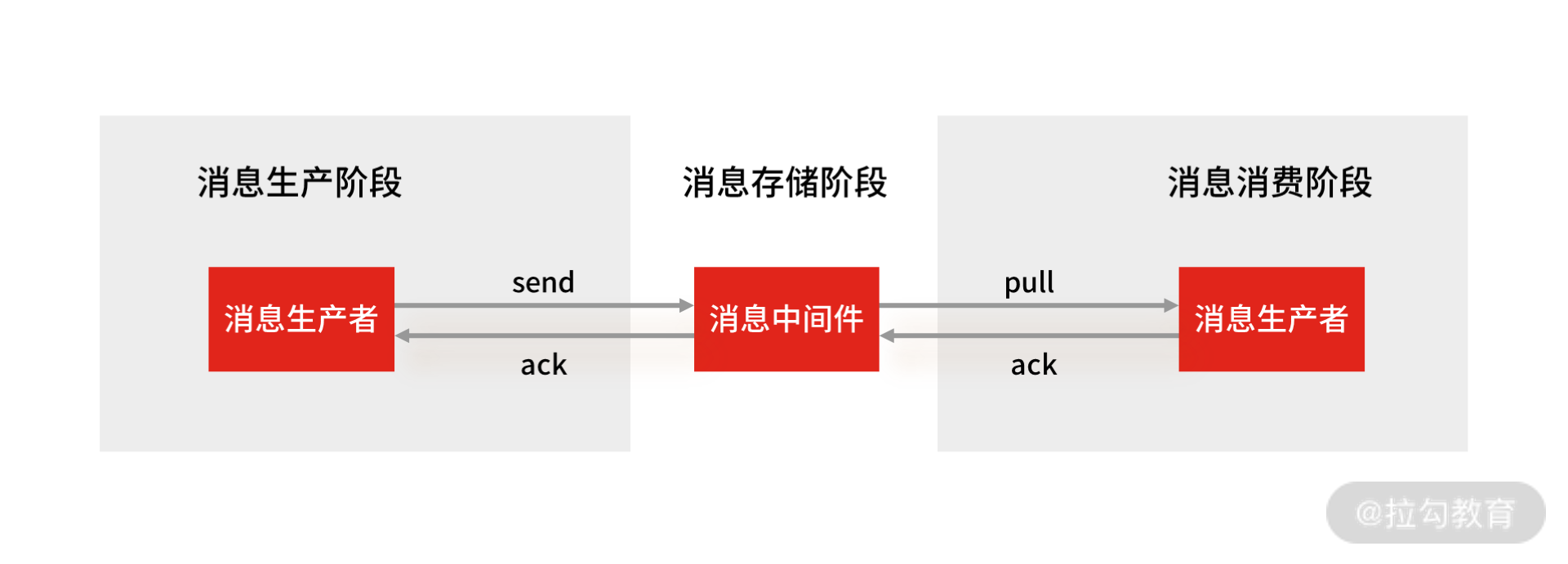
消息的生产、存储与消费
消息生产阶段: 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 MQ Broker 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,这个阶段是不会出现消息丢失的。
消息存储阶段: 这个阶段一般会直接交给 MQ 消息中间件来保证,但是你要了解它的原理,比如 Broker 会做副本,保证一条消息至少同步两个节点再返回 ack(这里涉及数据一致性原理,我在 04 讲中已经讲过,在面试中,你可以灵活延伸)。
消息消费阶段: 消费端从 Broker 上拉取消息,只要消费端在收到消息后,不立即发送消费确认给 Broker,而是等到执行完业务逻辑后,再发送消费确认,也能保证消息的不丢失。
方案看似万无一失,每个阶段都能保证消息的不丢失,但在分布式系统中,故障不可避免,作为消费生产端,你并不能保证 MQ 是不是弄丢了你的消息,消费者是否消费了你的消息,所以,本着 Design for Failure 的设计原则,你还是需要一种机制,来 Check 消息是否丢失了。
紧接着,你还可以向面试官阐述怎么进行消息检测? 总体方案解决思路为:在消息生产端,给每个发出的消息都指定一个全局唯一 ID,或者附加一个连续递增的版本号,然后在消费端做对应的版本校验。
具体怎么落地实现呢?你可以利用拦截器机制。 在生产端发送消息之前,通过拦截器将消息版本号注入消息中(版本号可以采用连续递增的 ID 生成,也可以通过分布式全局唯一 ID生成)。然后在消费端收到消息后,再通过拦截器检测版本号的连续性或消费状态,这样实现的好处是消息检测的代码不会侵入到业务代码中,可以通过单独的任务来定位丢失的消息,做进一步的排查。
这里需要你注意:如果同时存在多个消息生产端和消息消费端,通过版本号递增的方式就很难实现了,因为不能保证版本号的唯一性,此时只能通过全局唯一 ID 的方案来进行消息检测,具体的实现原理和版本号递增的方式一致。
现在,你已经知道了哪些环节(消息存储阶段、消息消费阶段)可能会出问题,并有了如何检测消息丢失的方案,然后就要给出解决防止消息丢失的设计方案。解决方案你可以参考 05 讲中的 “基于 MQ 的可靠消息投递”的机制,我这里就不再赘述。
回答完“如何确保消息不会丢失?”之后,面试官通常会追问“怎么解决消息被重复消费的问题?” 比如:在消息消费的过程中,如果出现失败的情况,通过补偿的机制发送方会执行重试,重试的过程就有可能产生重复的消息,那么如何解决这个问题?
这个问题其实可以换一种说法,就是如何解决消费端幂等性问题(幂等性,就是一条命令,任意多次执行所产生的影响均与一次执行的影响相同),只要消费端具备了幂等性,那么重复消费消息的问题也就解决了。
我们还是来看扣减京豆的例子,将账户 X 的金豆个数扣减 100 个,在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。
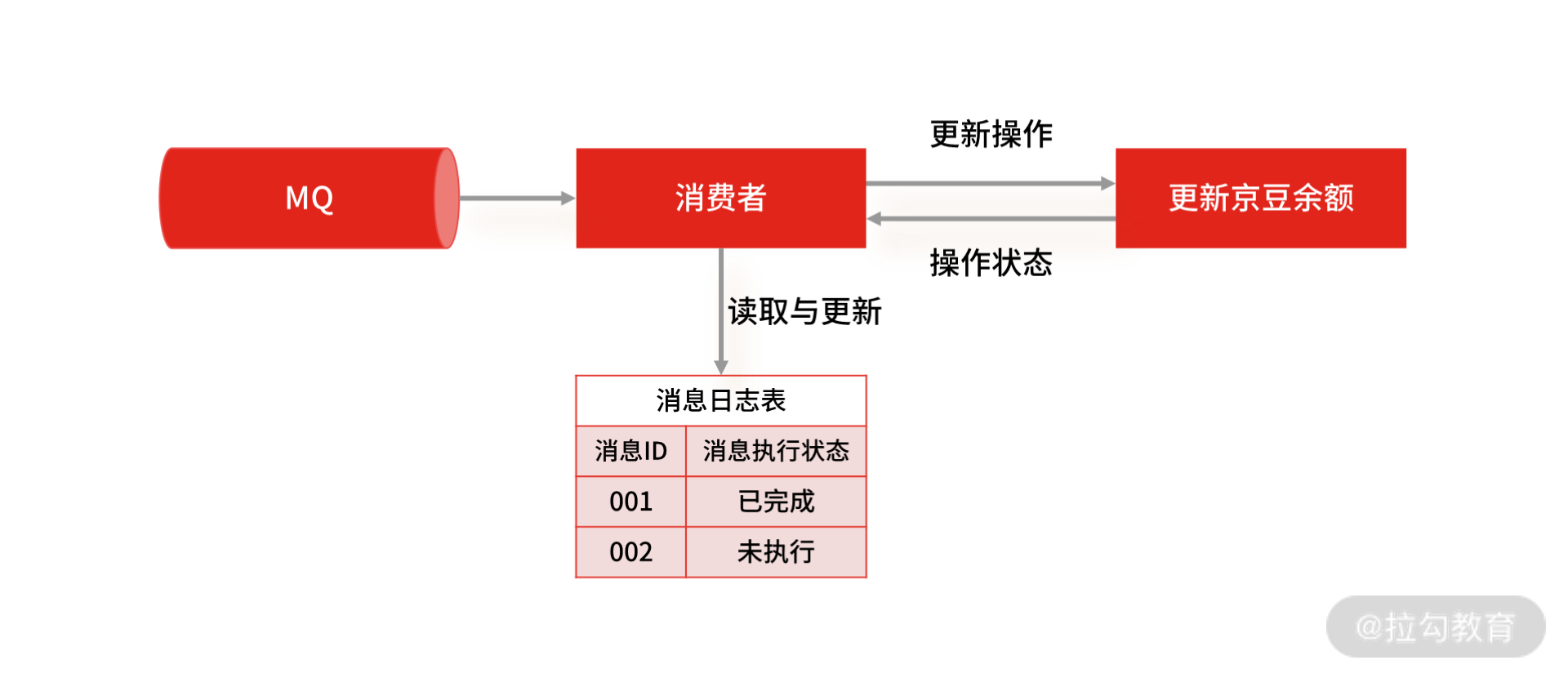
扣减京豆
最简单的实现方案,就是在数据库中建一张消息日志表, 这个表有两个字段:消息 ID 和消息执行状态。这样,我们消费消息的逻辑可以变为:在消息日志表中增加一条消息记录,然后再根据消息记录,异步操作更新用户京豆余额。
因为我们每次都会在插入之前检查是否消息已存在,所以就不会出现一条消息被执行多次的情况,这样就实现了一个幂等的操作。当然,基于这个思路,不仅可以使用关系型数据库,也可以通过 Redis 来代替数据库实现唯一约束的方案。
在这里我多说一句,想要解决“消息丢失”和“消息重复消费”的问题,有一个前提条件就是要实现一个全局唯一 ID 生成的技术方案。这也是面试官喜欢考察的问题,你也要掌握。
在分布式系统中,全局唯一 ID 生成的实现方法有数据库自增主键、UUID、Redis,Twitter-Snowflake 算法,我总结了几种方案的特点,你可以参考下。
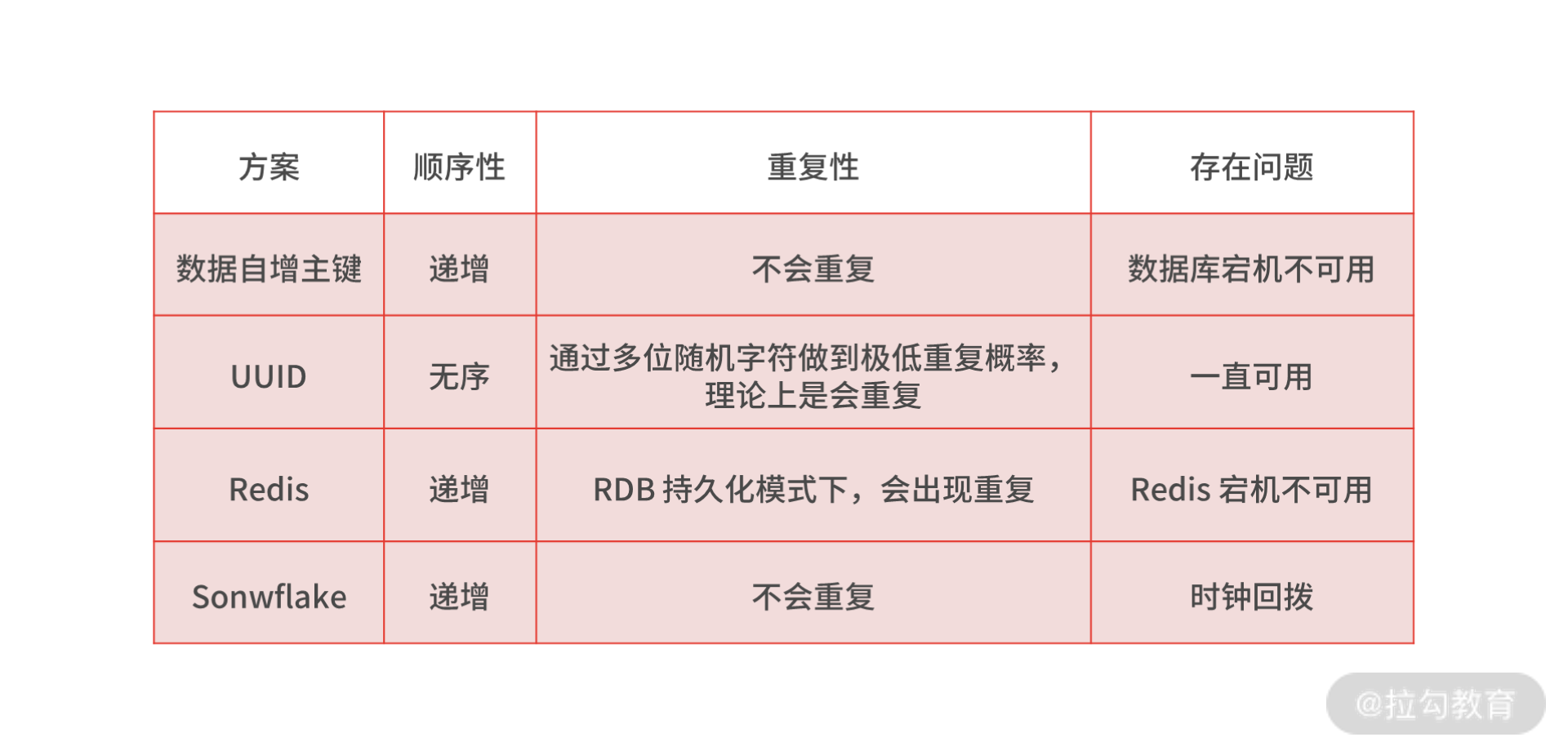
我提醒你注意,无论哪种方法,如果你想同时满足简单、高可用和高性能,就要有取舍,所以你要站在实际的业务中,说明你的选型所考虑的平衡点是什么。我个人在业务中比较倾向于选择 Snowflake 算法,在项目中也进行了一定的改造,主要是让算法中的 ID 生成规则更加符合业务特点,以及优化诸如时钟回拨等问题。
当然,除了“怎么解决消息被重复消费的问题?”之外,面试官还会问到你“消息积压”。 原因在于消息积压反映的是性能问题,解决消息积压问题,可以说明候选者有能力处理高并发场景下的消费能力问题。
你在解答这个问题时,依旧要传递给面试官一个这样的思考过程: 如果出现积压,那一定是性能问题,想要解决消息从生产到消费上的性能问题,就首先要知道哪些环节可能出现消息积压,然后在考虑如何解决。
因为消息发送之后才会出现积压的问题,所以和消息生产端没有关系,又因为绝大部分的消息队列单节点都能达到每秒钟几万的处理能力,相对于业务逻辑来说,性能不会出现在中间件的消息存储上面。毫无疑问,出问题的肯定是消息消费阶段,那么从消费端入手,如何回答呢?
如果是线上突发问题,要临时扩容,增加消费端的数量,与此同时,降级一些非核心的业务。通过扩容和降级承担流量,这是为了表明你对应急问题的处理能力。
其次,才是排查解决异常问题,如通过监控,日志等手段分析是否消费端的业务逻辑代码出现了问题,优化消费端的业务处理逻辑。
最后,如果是消费端的处理能力不足,可以通过水平扩容来提供消费端的并发处理能力,但这里有一个考点需要特别注意, 那就是在扩容消费者的实例数的同时,必须同步扩容主题 Topic 的分区数量,确保消费者的实例数和分区数相等。如果消费者的实例数超过了分区数,由于分区是单线程消费,所以这样的扩容就没有效果。
比如在 Kafka 中,一个 Topic 可以配置多个 Partition(分区),数据会被写入到多个分区中,但在消费的时候,Kafka 约定一个分区只能被一个消费者消费,Topic 的分区数量决定了消费的能力,所以,可以通过增加分区来提高消费者的处理能力。
总结
至此,我们讲解了 MQ 消息队列的热门问题的解决方案,无论是初中级还是高级研发工程师,本讲都是你需要掌握的,你都可以从这几点出发,与面试官进行友好的交流。我来总结一下今天的重点内容。
如何确保消息不会丢失? 你要知道一条消息从发送到消费的每个阶段,是否存在丢消息,以及如何监控消息是否丢失,最后才是如何解决问题,方案可以基于“ MQ 的可靠消息投递 ”的方式。
如何保证消息不被重复消费? 在进行消息补偿的时候,一定会存在重复消息的情况,那么如何实现消费端的幂等性就这道题的考点。
如何处理消息积压问题? 这道题的考点就是如何通过 MQ 实现真正的高性能,回答的思路是,本着解决线上异常为最高优先级,然后通过监控和日志进行排查并优化业务逻辑,最后是扩容消费端和分片的数量。
在回答问题的时候,你需要特别注意的是,让面试官了解到你的思维过程,这种解决问题的能力是面试官更为看中的,比你直接回答一道面试题更有价值。
另外,如果你应聘的部门是基础架构部,那么除了要掌握本讲中的常见问题的主线知识以外,还要掌握消息中间件的其他知识体系,如:
如何选型消息中间件?
消息中间件中的队列模型与发布订阅模型的区别?
为什么消息队列能实现高吞吐?
序列化、传输协议,以及内存管理等问题
……
本节课的思考题是:Kafka 是如何实现高性能的?欢迎你把答案写到留言区,和我一起讨论。
09 如何回答 MySQL 的索引原理与优化问题?
在互联网技术面试中,面试官除了会考察分布式、中间件等技术以外,还会考察数据库知识。无论你是程序员,还是架构师,都要掌握关系型数据库 MySQL 的原理与设计问题,从今天起,我就用 4 讲的时间带你打卡 MySQL 的面试内容。
今天这一讲,我们就先来看一看怎么回答 MySQL 的索引原理与优化问题。
案例背景
很多面试官考察候选人对“数据库知识”的掌握程度,会以“数据库的索引原理和优化方法”作为切入点。
假设面试官问你: 在电商平台的订单中心系统中,通常要根据商品类型、订单状态筛选出需要的订单,并按照订单创建的时间进行排序,那针对下面这条 SQL,你怎么通过索引来提高查询效率呢?
select * from order where status = 1 order by create_time asc
有的同学会认为,单独给 status 建立一个索引就可以了。
但是更优的方式是建立一个 status 和 create_time 组合索引,这是为了避免 MySQL 数据库发生文件排序。因为在查询时,你只能用到 status 的索引,但如果要对 create_time 排序,就要用文件排序 filesort,也就是在 SQL 执行计划中,Extra 列会出现 Using filesort。
所以你要利用索引的有序性,在 status 和 create_time 列建立联合索引,这样根据 status 筛选后的数据就是按照 create_time 排好序的,避免在文件排序。
案例分析
通过这个案例,你可以发现“索引知识”的重要性,所以我一般也会拿索引知识来考察候选人,并扩展出 MySQL 索引原理与优化策略的一系列问题,比如:
数据库索引底层使用的是什么数据结构和算法呢?
为什么 MySQL InnoDB 选择 B+Tree 当默认的索引数据结构?
如何通过执行计划查看索引使用详情?
有哪些情况会导致索引失效?
平时有哪些常见的优化索引的方法?
……
总结起来就是如下几点:
理解 MySQL InnoDB 的索引原理;
掌握 B+Tree 相比于其他索引数据结构(如 B-Tree、二叉树,以及 Hash 表)的优势;
掌握 MySQL 执行计划的方法;
掌握导致索引失效的常见情况;
掌握实际工作中常用的建立高效索引的技巧(如前缀索引、建立覆盖索引等)。
如果你曾经被问到其中某一个问题,那你就有必要认真夯实 MySQL 索引及优化的内容了。
案例解答
MySQL InnoDB 的索引原理
从数据结构的角度来看, MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。我在表中总结了 MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。(后两个存储引擎在实际工作和面试中很少提及,所以本讲我只讲 InnoDB) 。

索引类型
在实际应用中,InnoDB 是 MySQL 建表时默认的存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎默认使用表的主键作为主键索引,该主键索引就是聚簇索引(Clustered Index),如果表没有定义主键,InnoDB 就自己产生一个隐藏的 6 个字节的主键 ID 值作为主键索引,而创建的主键索引默认使用的是 B+Tree 索引。
接下来我们通过一个简单的例子,说明一下 B+Tree 索引在存储数据中的具体实现,为的是让你理解通过 B+Tree 做索引的原理。
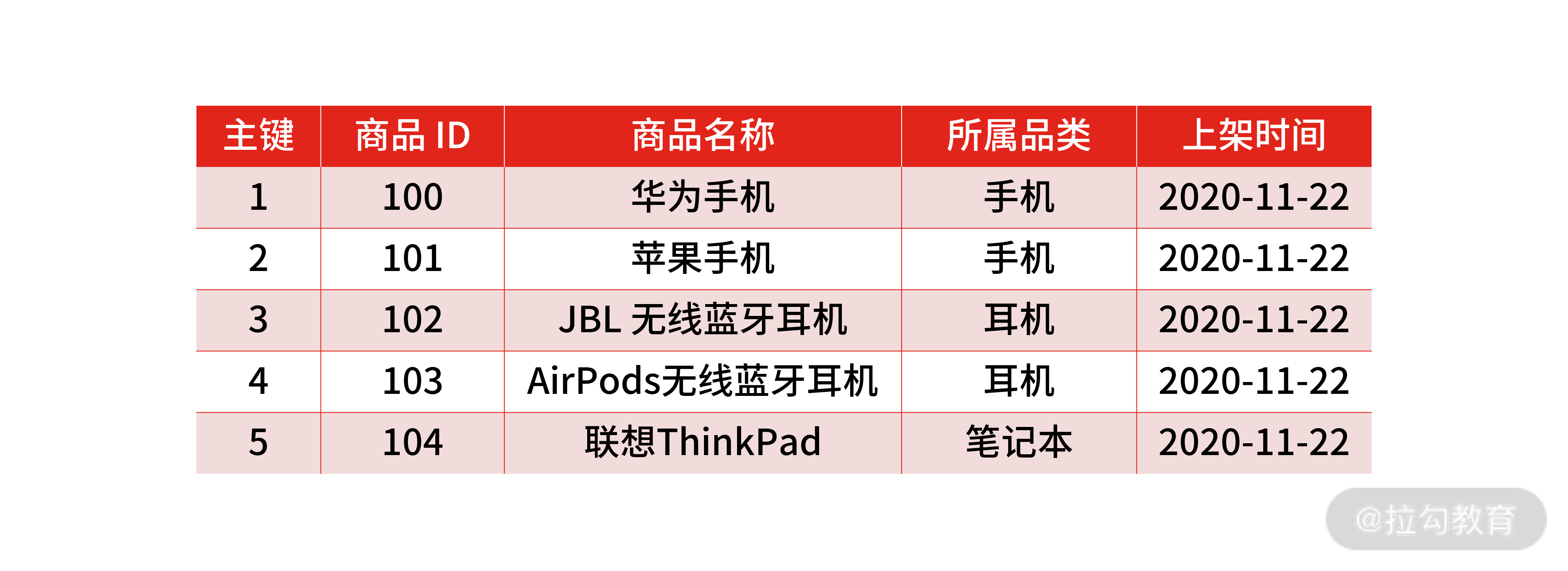
首先,我们创建一张商品表:
CREATE TABLE `product` (`id` int(11) NOT NULL,`product_no` varchar(20) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,`price` decimal(10, 2) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
然后新增几行数据:
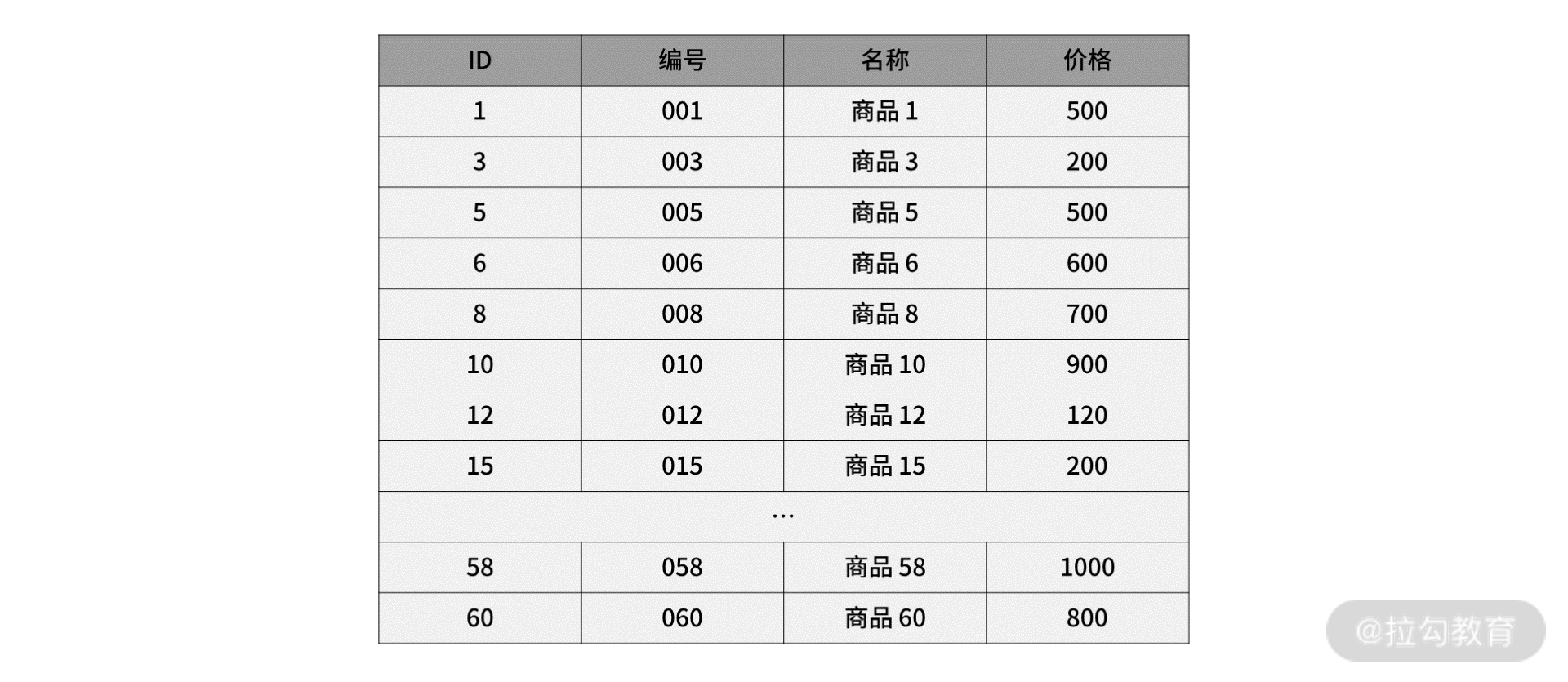
商品数据表
通过主键查询(主键索引)商品数据的过程
此时当我们使用主键索引查询商品 15 的时候,那么按照 B+Tree 索引原理,是如何找到对应数据的呢?
select * from product where id = 15
我们可以通过数据手动构建一个 B+Tree,它的每个节点包含 3 个子节点(B+Tree 每个节点允许有 M 个子节点,且 M>2),根节点中的数据值 1、18、36 分别是子节点(1,6,12),(18,24,30)和(36,41,52)中的最小值。
每一层父节点的数据值都会出现在下层子节点的数据值中,因此在叶子节点中,包括了所有的数据值信息,并且每一个叶子节点都指向下一个叶子节点,形成一个链表。如图所示:
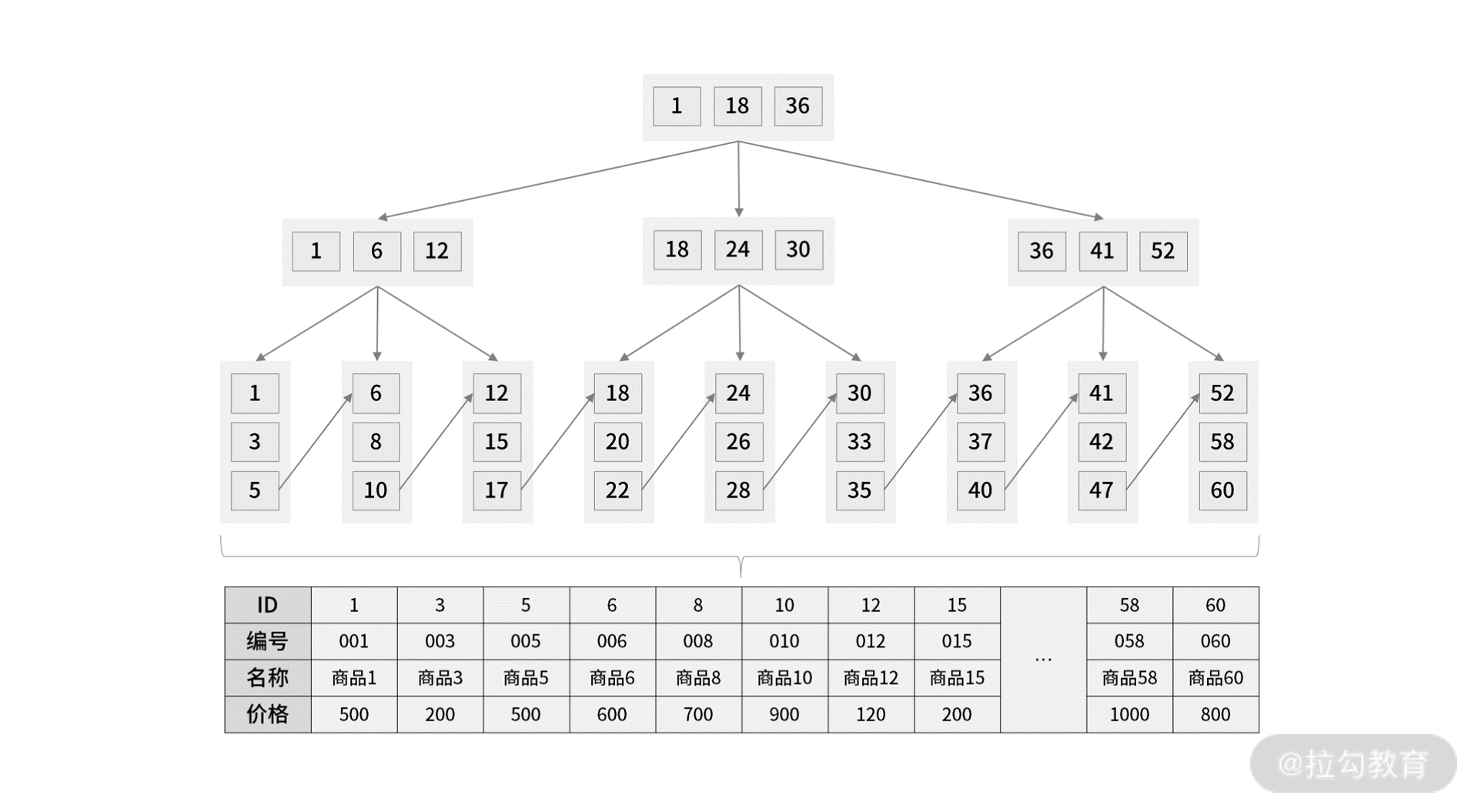
主键索引查询过程
我们举例讲解一下 B+Tree 的查询流程,比如想要查找数据值 15,B+Tree 会自顶向下逐层进行查找:
将 15 与根节点的数据 (1,18,36) 比较,15 在 1 和 18 之间,所以根据 B+Tree的搜索逻辑,找到第二层的数据块 (1,6,12);
在第二层的数据块 (1,6,12) 中进行查找,因为 15 大于 12,所以找到第三层的数据块 (12,15,17);
在叶子节点的数据块 (12,15,17) 中进行查找,然后我们找到了数据值 15;
最终根据数据值 15 找到叶子节点中存储的数据。
整个过程一共进行了 3 次 I/O 操作,所以 B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率。
那么问题来了,如果你当前查询数据时候,不是通过主键 ID,而是用商品编码查询商品,那么查询过程又是怎样的呢?
通过非主键(辅助索引)查询商品数据的过程
如果你用商品编码查询商品(即使用辅助索引进行查询),会先检索辅助索引中的 B+Tree 的 商品编码,找到对应的叶子节点,获取主键值,然后再通过主键索引中的 B+Tree 树查询到对应的叶子节点,然后获取整行数据。这个过程叫回表。
以上就是索引的实现原理。 掌握索引的原理是了解 MySQL 数据库的查询效率的基础,是每一个研发工程师都需要精通的知识点。
在面试时,面试官一般不会让你直接描述查询索引的过程,但是会通过考察你对索引优化方法的理解,来评估你对索引原理的掌握程度,比如为什么 MySQL InnoDB 选择 B+Tree 作为默认的索引数据结构?MySQL 常见的优化索引的方法有哪些?
所以接下来,我们就详细了解一下在面试中如何回答索引优化的问题。
B+Tree 索引的优势
如果你被问到“为什么 MySQL 会选择 B+Tree 当索引数据结构?”其实在考察你两个方面: B+Tree 的索引原理; B+Tree 索引相比于其他索引类型的优势。
我们刚刚已经讲了 B+Tree 的索引原理,现在就来回答一下 B+Tree 相比于其他常见索引结构,如 B 树、二叉树或 Hash 索引结构的优势在哪儿?
B+Tree 相对于 B 树 索引结构的优势
B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询更多的节点。
另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
B+Tree 相对于二叉树索引结构的优势
对于有 N 个叶子节点的 B+Tree,其搜索复杂度为O(logdN),其中 d 表示节点允许的最大子节点个数为 d 个。在实际的应用当中, d 值是大于100的,这样就保证了,即使数据达到千万级别时,B+Tree 的高度依然维持在 3~4 层左右,也就是说一次数据查询操作只需要做 3~4 次的磁盘 I/O 操作就能查询到目标数据(这里的查询参考上面 B+Tree 的聚簇索引的查询过程)。
而二叉树的每个父节点的儿子节点个数只能是 2 个,意味着其搜索复杂度为 O(logN),这已经比 B+Tree 高出不少,因此二叉树检索到目标数据所经历的磁盘 I/O 次数要更多。
B+Tree 相对于 Hash 表存储结构的优势
我们知道范围查询是 MySQL 中常见的场景,但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
至此,你就知道“为什么 MySQL 会选择 B+Tree 来做索引”了。在回答时,你要着眼于 B+Tree 的优势,然后再引入索引原理的查询过程(掌握这些知识点,这个问题其实比较容易回答)。
接下来,我们进入下一个问题:在实际工作中如何查看索引的执行计划。
通过执行计划查看索引使用详情
我这里有一张存储商品信息的演示表 product:
CREATE TABLE `product` (`id` int(11) NOT NULL,`product_no` varchar(20) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,`price` decimal(10, 2) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY 'index_name' ('name').KEY 'index_id_name' ('id', 'name')
) CHARACTER SET = utf8 COLLATE = utf8_general_ci
表中包含了主键索引、name 字段上的普通索引,以及 id 和 name 两个字段的联合索引。现在我们来看一条简单查询语句的执行计划:

执行计划
对于执行计划,参数有 possible_keys 字段表示可能用到的索引,key 字段表示实际用的索引,key_len 表示索引的长度,rows 表示扫描的数据行数。
这其中需要你重点关注 type 字段, 表示数据扫描类型,也就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为(考虑到查询效率问题,全表扫描和全索引扫描要尽量避免):
ALL(全表扫描);
index(全索引扫描);
range(索引范围扫描);
ref(非唯一索引扫描);
eq_ref(唯一索引扫描);
const(结果只有一条的主键或唯一索引扫描)。
总的来说,执行计划是研发工程师分析索引详情必会的技能(很多大厂公司招聘 JD 上写着“SQL 语句调优” ),所以你在面试时也要知道执行计划核心参数的含义,如 type。在回答时,也要以重点参数为切入点,再扩展到其他参数,然后再说自己是怎么做 SQL 优化工作的。
索引失效的常见情况
在工作中,我们经常会碰到 SQL 语句不适用已有索引的情况,来看一个索引失效的例子:

这条带有 like 查询的 SQL 语句,没有用到 product 表中的 index_name 索引。
我们结合普通索引的 B+Tree 结构看一下索引失效的原因: 当 MySQL 优化器根据 name like ‘%路由器’ 这个条件,到索引 index_name 的 B+Tree 结构上进行查询评估时,发现当前节点的左右子节点上的值都有可能符合 '%路由器' 这个条件,于是优化器判定当前索引需要扫描整个索引,并且还要回表查询,不如直接全表扫描。
当然,还有其他类似的索引失效的情况:
索引列上做了计算、函数、类型转换操作,这些情况下索引失效是因为查询过程需要扫描整个索引并回表,代价高于直接全表扫描;
like 匹配使用了前缀匹配符 '%abc';
字符串不加引号导致类型转换;
我给你的建议是, 如果 MySQL 查询优化器预估走索引的代价比全表扫描的代价还要大,则不走对应的索引,直接全表扫描,如果走索引比全表扫描代价小,则使用索引。
常见优化索引的方法
前缀索引优化
前缀索引就是用某个字段中,字符串的前几个字符建立索引,比如我们可以在订单表上对商品名称字段的前 5 个字符建立索引。使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
但是,前缀索引有一定的局限性,例如 order by 就无法使用前缀索引,无法把前缀索引用作覆盖索引。
覆盖索引优化
覆盖索引是指 SQL 中 query 的所有字段,在索引 B+tree 的叶子节点上都能找得到的那些索引,从辅助索引中查询得到记录,而不需要通过聚簇索引查询获得。假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个组合索引,即商品ID、名称、价格作为一个组合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。所以,使用覆盖索引的好处很明显,即不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作。
联合索引
联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。比如联合索引 (userpin, username),如果查询条件是 WHERE userpin=1 AND username=2,就可以匹配上联合索引;或者查询条件是 WHERE userpin=1,也能匹配上联合索引,但是如果查询条件是 WHERE username=2,就无法匹配上联合索引。
另外,建立联合索引时的字段顺序,对索引效率也有很大影响。越靠前的字段被用于索引过滤的概率越高,实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
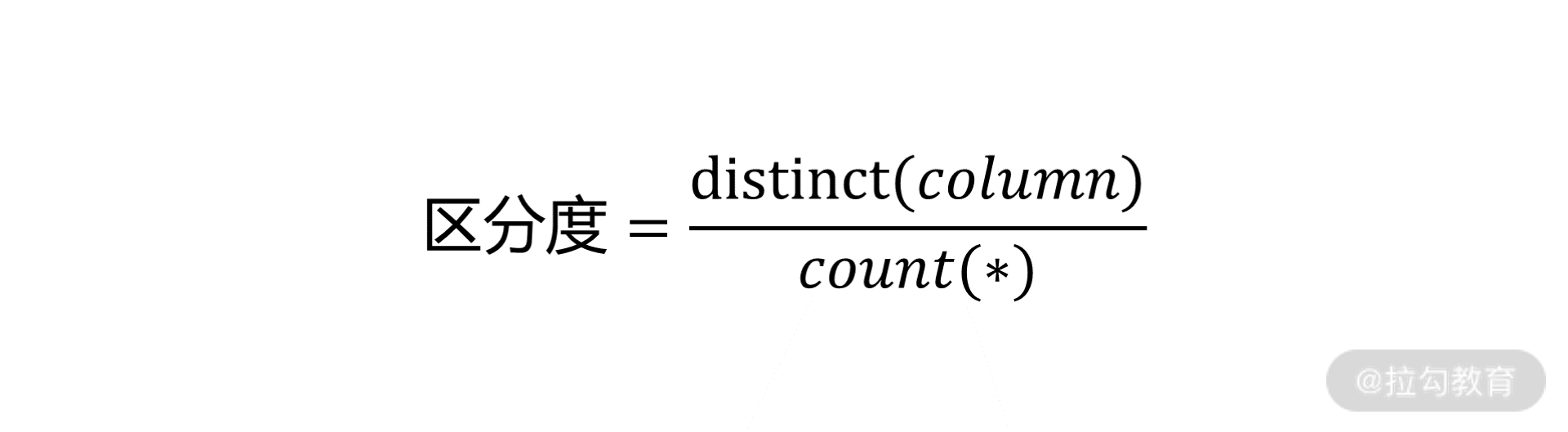
区分度就是某个字段 column 不同值的个数除以表的总行数,比如性别的区分度就很小,不适合建立索引或不适合排在联合索引列的靠前的位置,而 uuid 这类字段就比较适合做索引或排在联合索引列的靠前的位置。
总结
今天,我们讲了 MySQL 的索引原理,介绍了 InnoDB 为什么会采用 B+Tree 结构。因为 B+Tree 能够减少单次查询的磁盘访问次数,做到查询效率最大化。另外,我们还讲了如何查看 SQL 的执行计划,从而找到索引失效的问题,并有针对性的做索引优化。
最后,我总结一些你容易在面试中被问到的,索引的使用原则:

另外,你在了解索引优势的同时,也要了解索引存在的问题:索引会带来数据的写入延迟,引入额外的空间消耗;在海量数据下,想要通过索引提升查询效率也是有限的。
所以此时你还要考虑其他的方案,比如读写分离、分库分表等设计方案(这些内容我会在11、12讲带你了解)。
最后,感谢你的阅读,我们下一讲见。
10 如何回答 MySQL 的事务隔离级别和锁的机制?
上一讲,我讲了 MySQL 的索引原理与优化问题,今天我带你继续学习 MySQL 的事务隔离级别和锁的机制,MySQL 的事务和锁是并发控制最基本的手段,在面试中,它们与 09 讲的索引一样,同样是 MySQL 重要的考察点。
案例背景
MySQL 的事务隔离级别(Isolation Level),是指:当多个线程操作数据库时,数据库要负责隔离操作,来保证各个线程在获取数据时的准确性。它分为四个不同的层次,按隔离水平高低排序,读未提交 < 读已提交 < 可重复度 < 串行化。

MySQL 隔离级别
读未提交(Read uncommitted):隔离级别最低、隔离度最弱,脏读、不可重复读、幻读三种现象都可能发生。所以它基本是理论上的存在,实际项目中没有人用,但性能最高。
读已提交(Read committed):它保证了事务不出现中间状态的数据,所有数据都是已提交且更新的,解决了脏读的问题。但读已提交级别依旧很低,它允许事务间可并发修改数据,所以不保证再次读取时能得到同样的数据,也就是还会存在不可重复读、幻读的可能。
可重复读(Repeatable reads):MySQL InnoDB 引擎的默认隔离级别,保证同一个事务中多次读取数据的一致性,解决脏读和不可重复读,但仍然存在幻读的可能。
可串行化(Serializable):选择“可串行化”意味着读取数据时,需要获取共享读锁;更新数据时,需要获取排他写锁;如果 SQL 使用 WHERE 语句,还会获取区间锁。换句话说,事务 A 操作数据库时,事务 B 只能排队等待,因此性能也最低。
至于数据库锁,分为悲观锁和乐观锁,“悲观锁”认为数据出现冲突的可能性很大,“乐观锁”认为数据出现冲突的可能性不大。那悲观锁和乐观锁在基于 MySQL 数据库的应用开发中,是如何实现的呢?
悲观锁一般利用 SELECT … FOR UPDATE 类似的语句,对数据加锁,避免其他事务意外修改数据。
乐观锁利用 CAS 机制,并不会对数据加锁,而是通过对比数据的时间戳或者版本号,实现版本判断。
案例分析
如果面试官想深挖候选人对数据库内部机制的掌握程度,切入点一般是 MySQL 的事务和锁机制。接下来,我就从初中级研发工程师的角度出发,从概念到实践,带你掌握“MySQL 事务和锁机制”的高频考点:
举例说明什么是脏读、不可重复度和幻读(三者虽然基础,但很多同学容易弄混)?
MySQL 是怎么解决脏读、不可重复读,和幻读问题的?
你怎么理解死锁?
……
案例解答
怎么理解脏读、不可重复读和幻读?
脏读: 读到了未提交事务的数据。
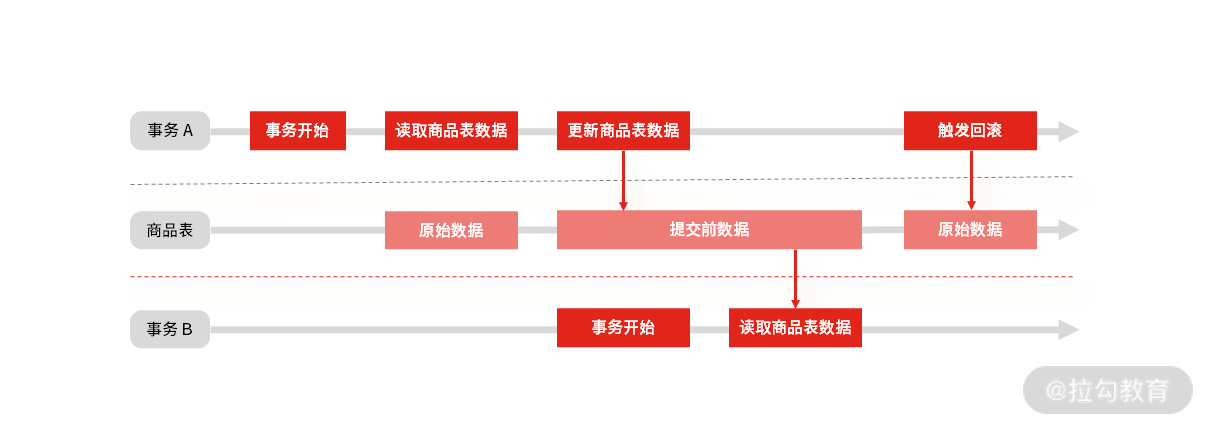
事务并发时的“脏读”现象
假设有 A 和 B 两个事务,在并发情况下,事务 A 先开始读取商品数据表中的数据,然后再执行更新操作,如果此时事务 A 还没有提交更新操作,但恰好事务 B 开始,然后也需要读取商品数据,此时事务 B 查询得到的是刚才事务 A 更新后的数据。
如果接下来事务 A 触发了回滚,那么事务 B 刚才读到的数据就是过时的数据,这种现象就是脏读。
“脏读”面试关注点:
脏读对应的隔离级别是“读未提交”,只有该隔离级别才会出现脏读。
脏读的解决办法是升级事务隔离级别,比如“读已提交”。
不可重复读: 事务 A 先读取一条数据,然后执行逻辑的过程中,事务 B 更新了这条数据,事务 A 再读取时,发现数据不匹配,这个现象就是“不可重复读”。
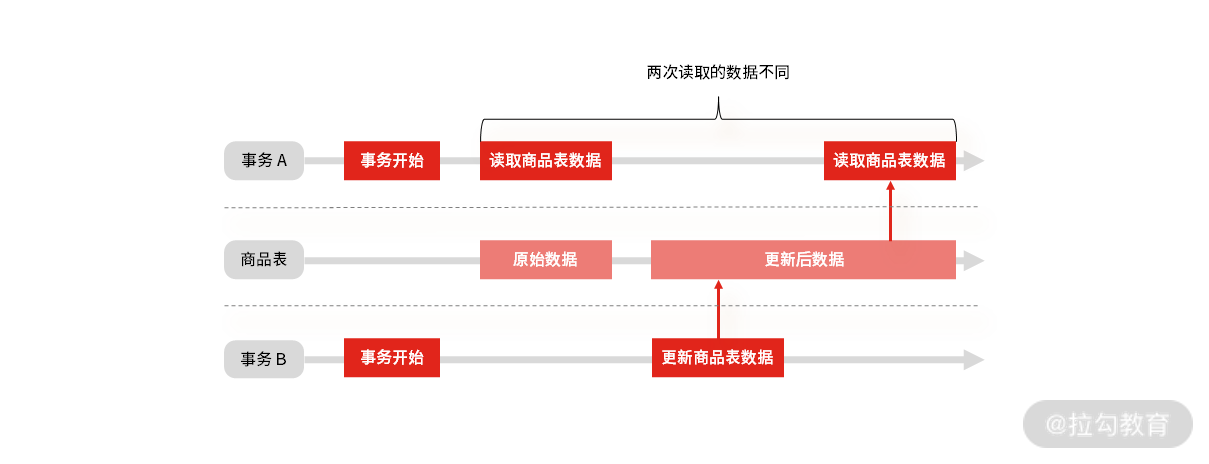
事务并发时的“不可重复读”现象
“不可重复读”面试关注点:
简单理解是两次读取的数据中间被修改,对应的隔离级别是“读未提交”或“读已提交”。
不可重复读的解决办法就是升级事务隔离级别,比如“可重复度”。
幻读: 在一个事务内,同一条查询语句在不同时间段执行,得到不同的结果集。
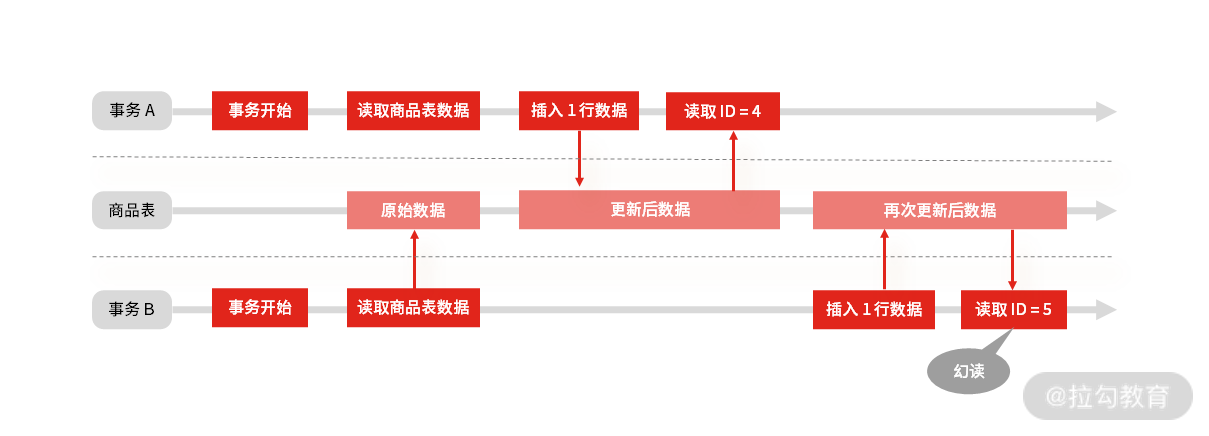
事务并发时的“幻读”现象
事务 A 读了一次商品表,得到最后的 ID 是 3,事务 B 也同样读了一次,得到最后 ID 也是 3。接下来事务 A 先插入了一行,然后读了一下最新的 ID 是 4,刚好是前面 ID 3 加上 1,然后事务 B 也插入了一行,接着读了一下最新的 ID 发现是 5,而不是 3 加 1。
这时,你发现在使用 ID 做判断或做关键数据时,就会出现问题,这种现象就像是让事务 B 产生了幻觉一样,读取到了一个意想不到的数据,所以叫幻读。当然,不仅仅是新增,删除、修改数据也会发生类似的情况。
“幻读”面试关注点:
要想解决幻读不能升级事务隔离级别到“可串行化”,那样数据库也失去了并发处理能力。
行锁解决不了幻读,因为即使锁住所有记录,还是阻止不了插入新数据。
解决幻读的办法是锁住记录之间的“间隙”,为此 MySQL InnoDB 引入了新的锁,叫间隙锁(Gap Lock),所以在面试中,你也要掌握间隙锁,以及间隙锁与行锁结合的 next-key lock 锁。
怎么理解死锁
除了事务隔离级别,很多同学在面试时,经常会被面试官直奔主题地问:“谈谈你对死锁的理解”。要回答这样开放的问题,你就要在脑海中梳理出系统化的回答思路:死锁是如何产生的,如何避免死锁。
死锁一般发生在多线程(两个或两个以上)执行的过程中。因为争夺资源造成线程之间相互等待,这种情况就产生了死锁。我在 06 讲也提到了死锁,但是并没有讲它产生的原因以及怎么避免,所以接下来我们就来了解这部分内容。
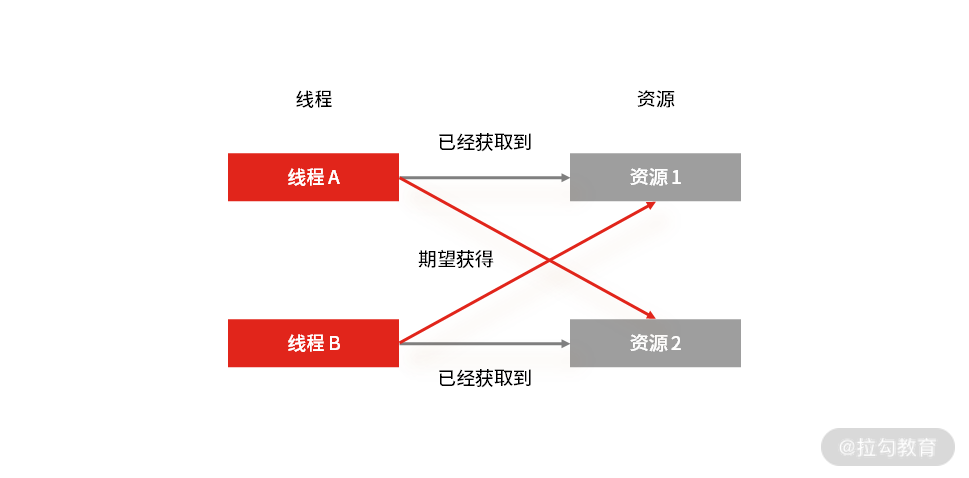
线程死锁
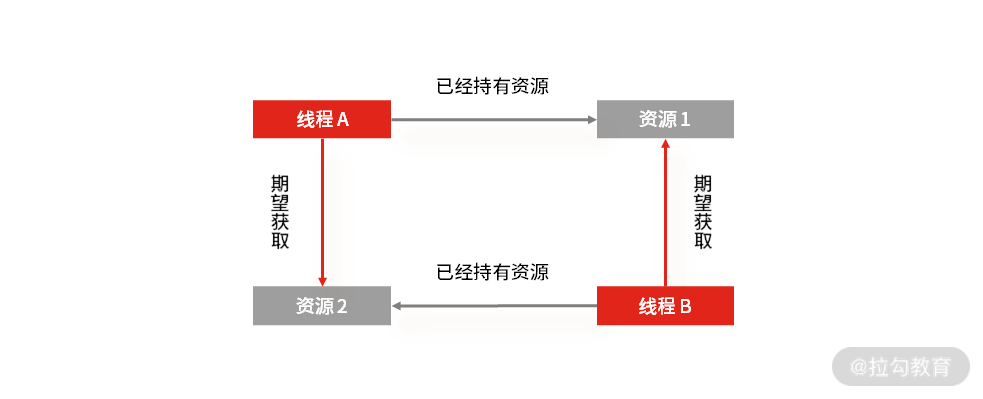
比如你有资源 1 和 2,以及线程 A 和 B,当线程 A 在已经获取到资源 1 的情况下,期望获取线程 B 持有的资源 2。与此同时,线程 B 在已经获取到资源 2 的情况下,期望获取现场 A 持有的资源 1。
那么线程 A 和线程 B 就处理了相互等待的死锁状态,在没有外力干预的情况下,线程 A 和线程 B 就会一直处于相互等待的状态,从而不能处理其他的请求。
死锁产生的四个必要条件。
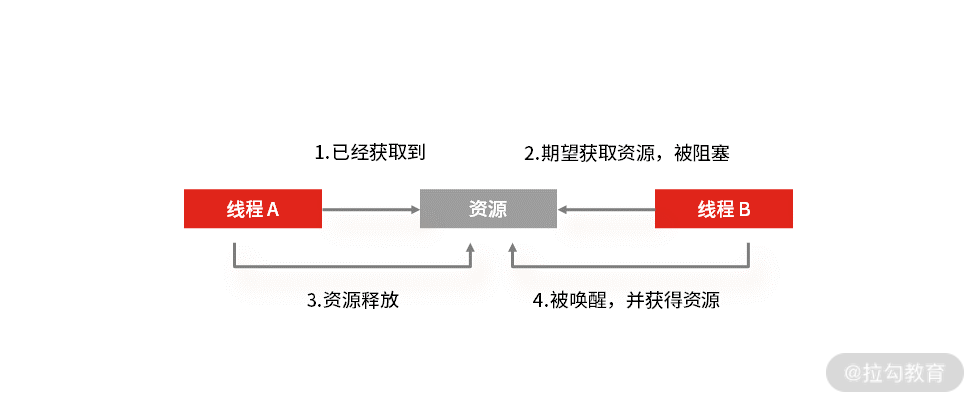
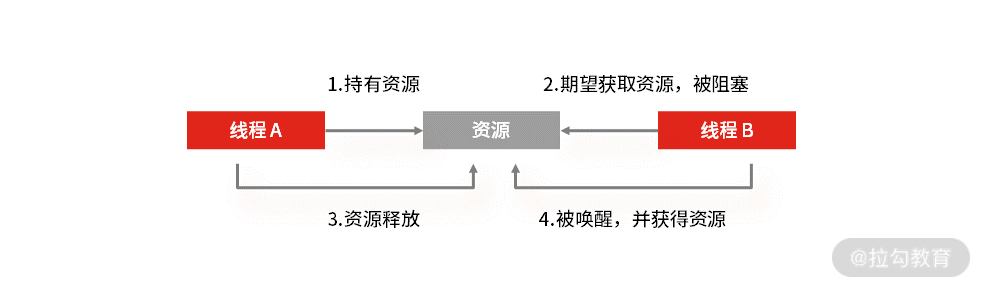
互斥条件
互斥: 多个线程不能同时使用一个资源。比如线程 A 已经持有的资源,不能再同时被线程 B 持有。如果线程 B 请求获取线程 A 已经占有的资源,那线程 B 只能等待这个资源被线程 A 释放。
持有并等待
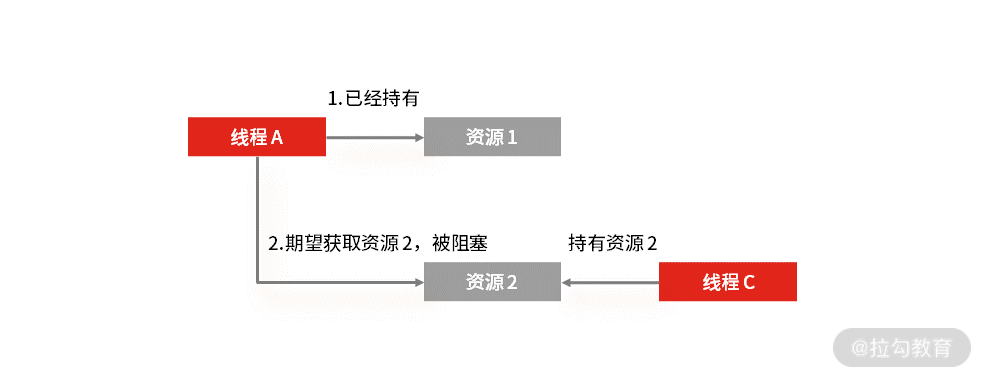
持有并等待: 当线程 A 已经持有了资源 1,又提出申请资源 2,但是资源 2 已经被线程 C 占用,所以线程 A 就会处于等待状态,但它在等待资源 2 的同时并不会释放自己已经获取的资源 1。
不可剥夺条件
不可剥夺: 线程 A 获取到资源 1 之后,在自己使用完之前不能被其他线程(比如线程 B)抢占使用。如果线程 B 也想使用资源 1,只能在线程 A 使用完后,主动释放后再获取。
循环等待
循环等待: 发生死锁时,必然会存在一个线程,也就是资源的环形链。比如线程 A 已经获取了资源 1,但同时又请求获取资源 2。线程 B 已经获取了资源 2,但同时又请求获取资源 1,这就会形成一个线程和资源请求等待的环形图。
死锁只有同时满足互斥、持有并等待、不可剥夺、循环等待时才会发生。并发场景下一旦死锁,一般没有特别好的方法,很多时候只能重启应用。因此,最好是规避死锁,那么具体怎么做呢?答案是:至少破坏其中一个条件(互斥必须满足,你可以从其他三个条件出发)。
持有并等待:我们可以一次性申请所有的资源,这样就不存在等待了。
不可剥夺:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可剥夺这个条件就破坏掉了。
循环等待:可以靠按序申请资源来预防,也就是所谓的资源有序分配原则,让资源的申请和使用有线性顺序,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样的线性化操作就自然就不存在循环了。
总结
我们花了两讲的时间,把 MySQL 数据库面试中的高频问题熟悉了一遍,但是如果从数据库领域应用开发者角度出发,至少还需要掌握以下几部分内容。
数据库设计基础:掌握数据库设计中的基本范式,以及基础概念,例如表、视图、索引、外键、序列号生成器等,掌握数据库的数据类型的使用,清楚业务实体关系与数据库结构的映射。
数据库隔离级别:掌握 MySQL 四种事务隔离级别的基础知识,并进一步了解 MVCC、Locking 等机制对于处理的进阶问题的解决;还需要了解不同索引类型的使用,甚至是底层数据结构和算法等。
SQL 优化:掌握基础的 SQL 调优技巧,至少要了解基本思路是怎样的,例如 SQL 怎样写才能更好利用索引、知道如何分析 SQL 执行计划等。
数据库架构设计:掌握针对高并发等特定场景中的解决方案,如读写分离、分库分表等。
当然在准备面试时我并不建议你找一堆书闷头苦读,还是要从实际工作中,从使用数据库出发,并结合实践,完善和深化自己的知识体系,今天的内容就讲到这里,我们下一讲见。
11 读多写少:MySQL 如何优化数据查询方案?
今天这一讲,我们将面试继续聚焦到 MySQL 上,看一看当面试官提及“在读多写少的网络环境下,MySQL 如何优化数据查询方案”时,你要从哪些角度出发回答问题。
案例背景
假设你目前在某电商平台就职,公司面临双 11 大促,投入了大量营销费用用于平台推广,这带来了巨大的流量,如果你是订单系统的技术负责人,要怎么应对突如其来的读写流量呢?
这是一个很典型的应用场景,我想很多研发同学会回答:通过 Redis 作为 MySQL 的缓存,然后当用户查看“订单中心”时,通过查询订单缓存,帮助 MySQL 抗住大部分的查询请求。
如果你也是这么想,说明没认真思考过问题。因为应用缓存的原则之一是保证缓存命中率足够高,不然很多请求会穿透缓存,最终打到数据库上。然而在“订单中心”这样的场景中,每个用户的订单都不同,除非全量缓存数据库订单信息(又会带来架构的复杂度),不然缓存的命中率依旧很低。
所以在这种场景下,缓存只能作为数据库的前置保护机制,但是还会有很多流量打到数据库上,并且随着用户订单不断增多,请求到 MySQL 上的读写流量会越来越多,当单台 MySQL 支撑不了大量的并发请求时,该怎么办?
案例分析
互联网大部分系统的访问流量是读多写少,读写请求量的差距可能达到几个数量级,就好比你在京东上的商品的浏览量肯定远大于你的下单量。
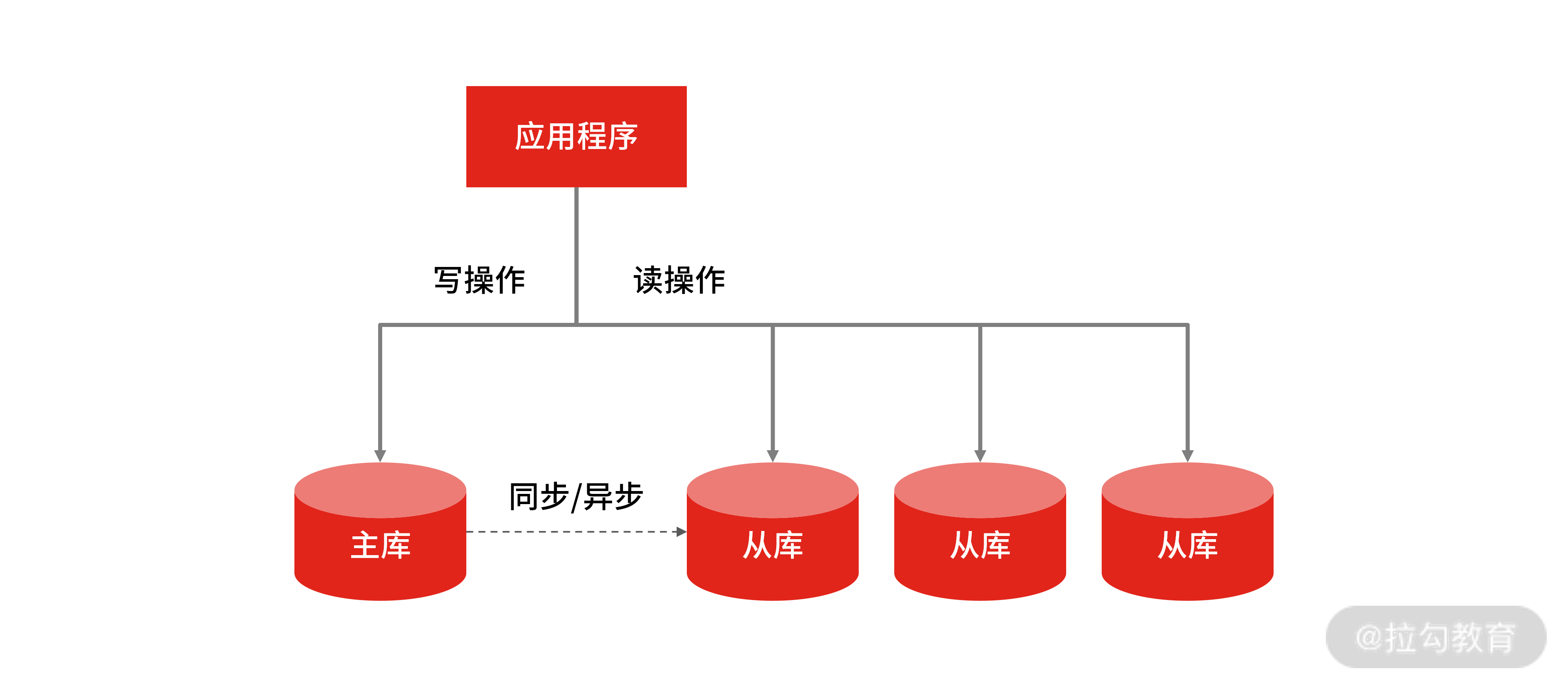
所以你要考虑优化数据库来抗住高查询请求,首先要做的就是区分读写流量区,这样才方便针对读流量做单独扩展,这个过程就是流量的“读写分离”。
读写分离是提升 MySQL 并发的首选方案,因为当单台 MySQL 无法满足要求时,就只能用多个具有相同数据的 MySQL 实例组成的集群来承担大量的读写请求。
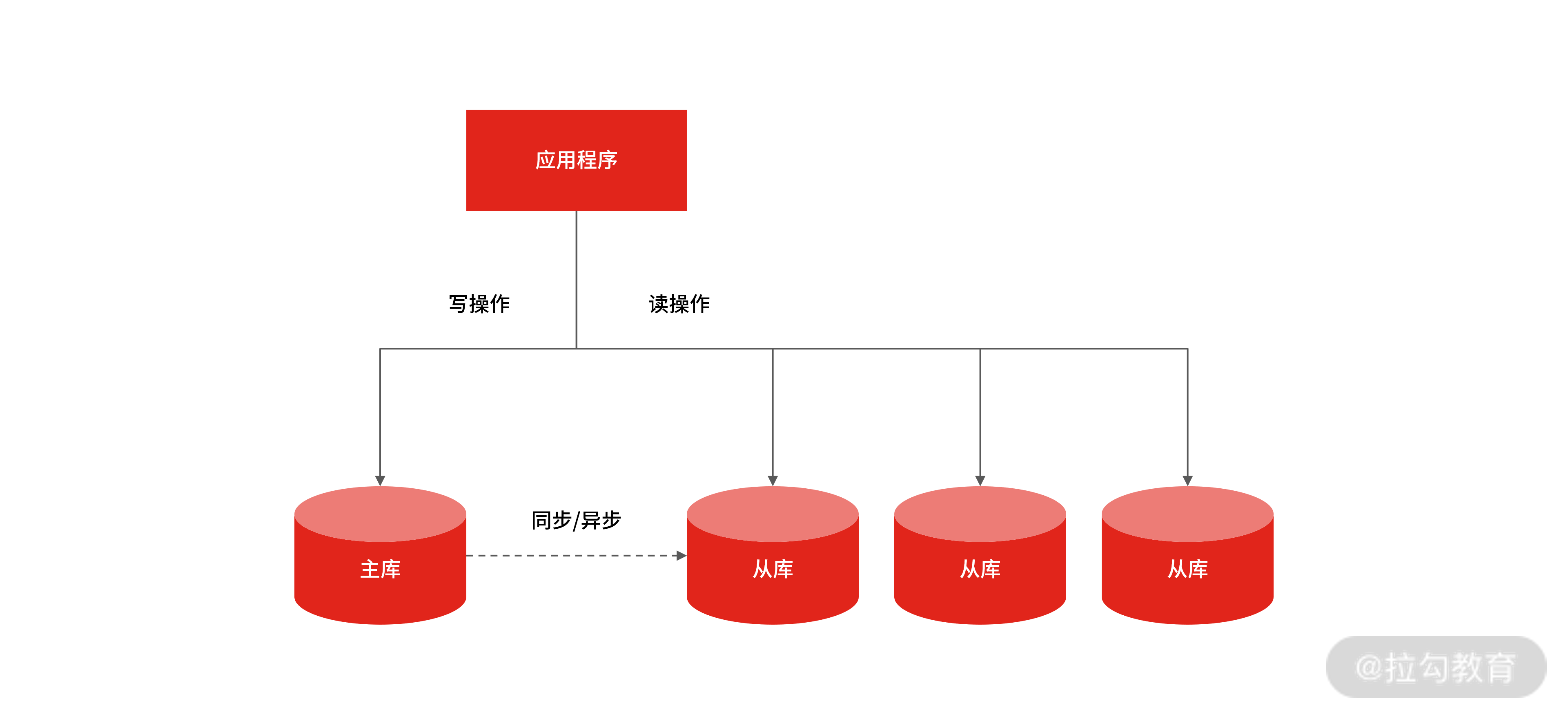
MySQL 主从结构
MySQL 做读写分离的前提,是把 MySQL 集群拆分成“主 + 从”结构的数据集群,这样才能实现程序上的读写分离,并且 MySQL 集群的主库、从库的数据是通过主从复制实现同步的。
那么面试官会问你“MySQL 集群如何实现主从复制?” 换一种问法就是“当你提交一个事务到 MySQL 集群后,MySQL 都执行了哪些操作?”面试官往往会以该问题为切入点,挖掘你对 MySQL 集群主从复制原理的理解,然后再模拟一个业务场景,让你给出解决主从复制问题的架构设计方案。
所以,针对面试官的套路,你要做好以下的准备:
掌握读多写少场景下的架构设计思路,知道缓存不能解决所有问题,“读写分离”是提升系统并发能力的重要手段。
深入了解数据库的主从复制,掌握它的原理、问题,以及解决方案。
从实践出发,做到技术的认知抽象,从方法论层面来看设计。
案例解答
MySQL 主从复制的原理
无论是“MySQL 集群如何实现主从复制”还是“当你提交一个事务到 MySQL 集群后,MySQL 集群都执行了哪些操作?”面试官主要是问你:MySQL 的主从复制的过程是怎样的?
总的来讲,MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。
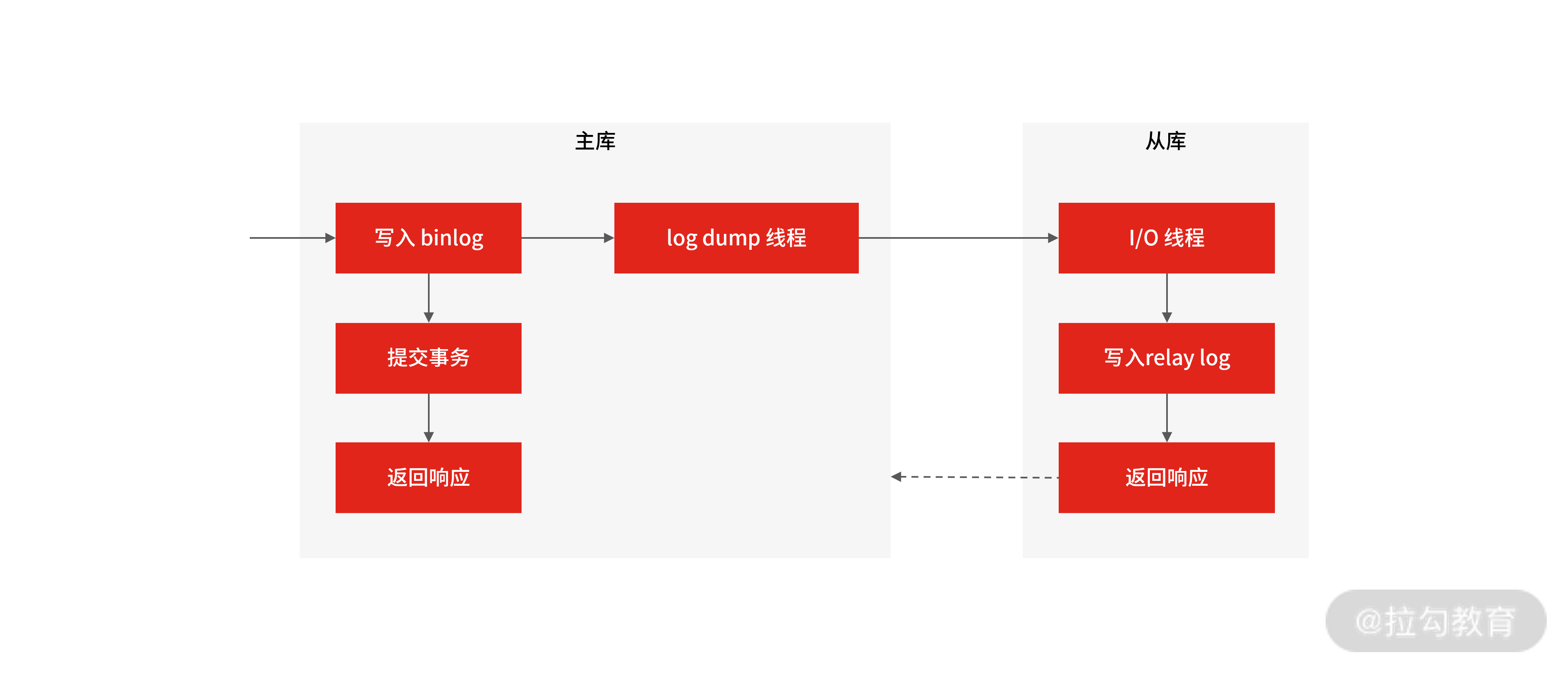
为了方便你记忆,我把 MySQL 集群的主从复制过程梳理成 3 个阶段。
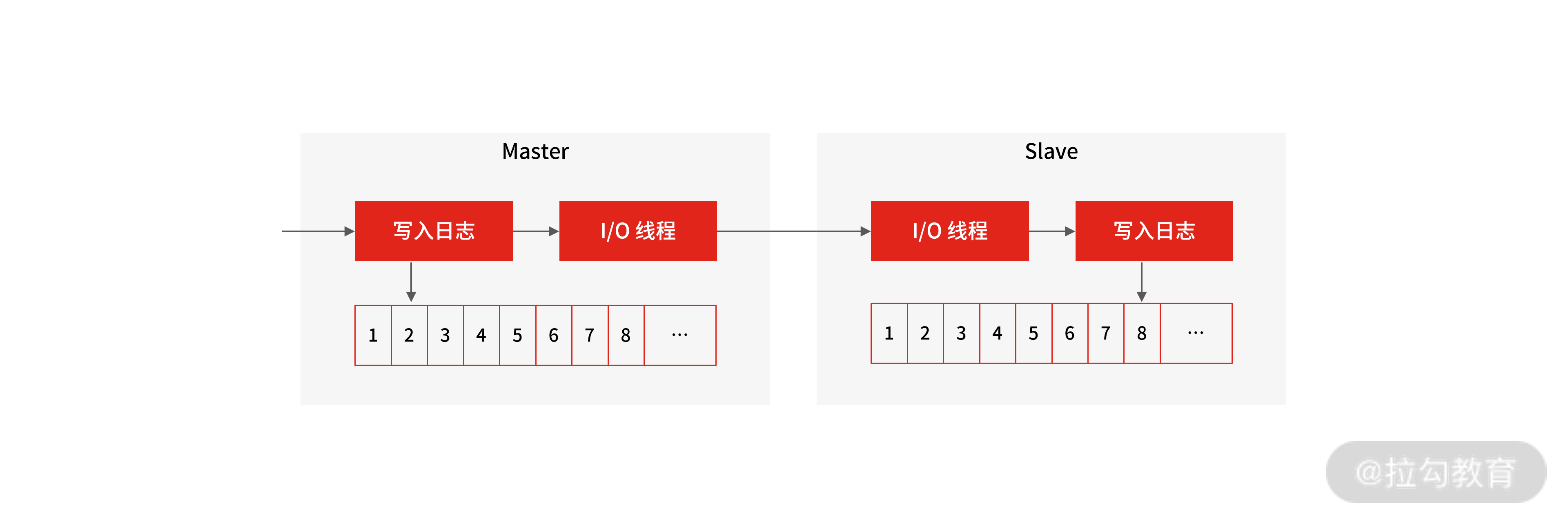
写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
回放 Binlog:回放 binlog,并更新存储数据。
主从复制过程
但在面试中你不能简单地只讲这几个阶段,要尽可能详细地说明主库和从库的数据同步过程,为的是让面试官感受到你技术的扎实程度(详细过程如下)。
MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。

一主多从
同时,在读流量比较大时,你可以部署多个从库共同承担读流量,这就是“一主多从”的部署方式,你在垂直电商项目中可以用该方式抵御较高的并发读流量。另外,从库也可以作为一个备库,以避免主库故障导致的数据丢失。
MySQL 一主多从
当然,一旦你提及“一主多从”,面试官很容易设陷阱问你:那大促流量大时,是不是只要多增加几台从库,就可以抗住大促的并发读请求了?
当然不是。
因为从库数量增加,从库连接上来的 I/O 线程也比较多,主库也要创建同样多的 log dump 线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。所以在实际使用中,一个主库一般跟 2~3 个从库(1 套数据库,1 主 2 从 1 备主),这就是一主多从的 MySQL 集群结构。
其实,你从 MySQL 主从复制过程也能发现,MySQL 默认是异步模式:MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客户端结果。这种模式一旦主库宕机,数据就会发生丢失。
而这时,面试官一般会追问你“**MySQL 主从复制还有哪些模型?”**主要有三种。
同步复制:事务线程要等待所有从库的复制成功响应。
异步复制:事务线程完全不等待从库的复制成功响应。
半同步复制:MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。
这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。
讲到这儿,你基本掌握了 MySQL 主从复制的原理,但如果面试官想挖掘你的架构设计能力,还会从架构设计上考察你怎么解决 MySQL 主从复制延迟的问题,比如问你“在系统设计上有哪些方案可以解决主从复制的延迟问题?”
从架构上解决主从复制延迟
我们来结合实际案例设计一个主从复制延迟的解决方案。
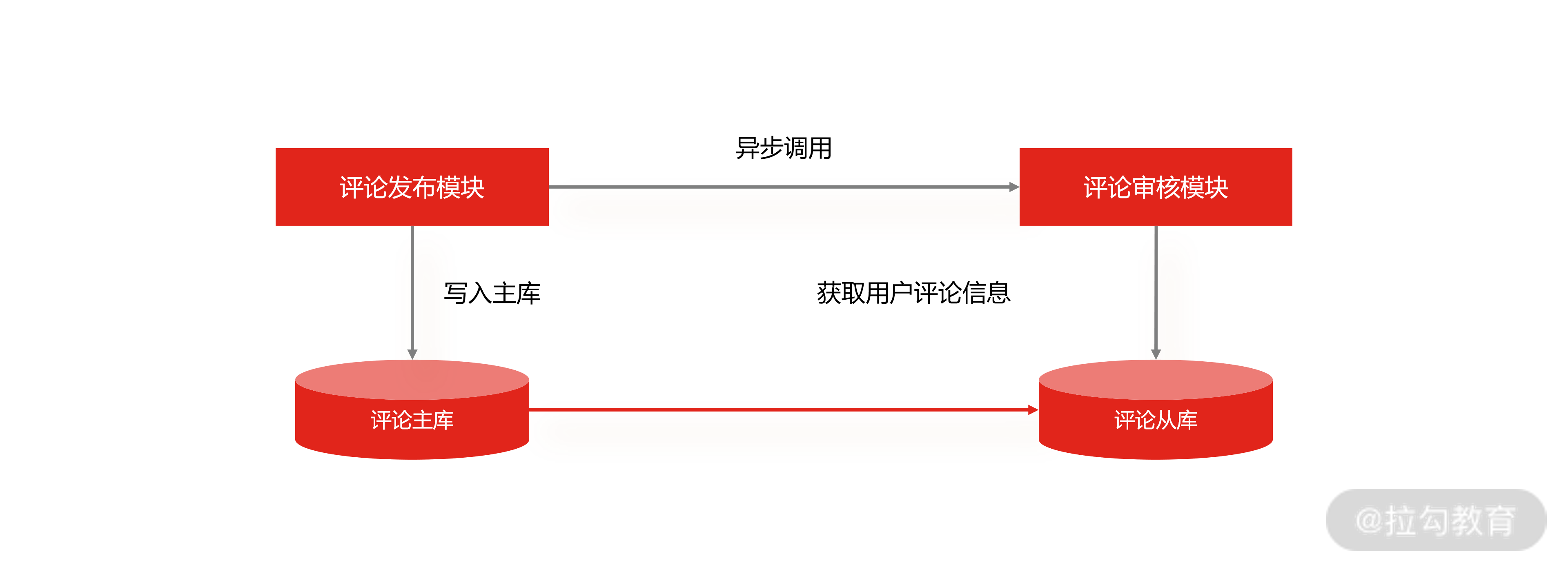
在电商平台,每次用户发布商品评论时,都会先调用评论审核,目的是对用户发布的商品评论进行如言论监控、图片鉴黄等操作。
评论在更新完主库后,商品发布模块会异步调用审核模块,并把评论 ID 传递给审核模块,然后再由评论审核模块用评论 ID 查询从库中获取到完整的评论信息。此时如果主从数据库存在延迟,在从库中就会获取不到评论信息,整个流程就会出现异常。
主从延迟影响评论读取的实时性
这是主从复制延迟导致的查询异常,解决思路有很多,我提供给你几个方案。
使用数据冗余
可以在异步调用审核模块时,不仅仅发送商品 ID,而是发送审核模块需要的所有评论信息,借此避免在从库中重新查询数据(这个方案简单易实现,推荐你选择)。但你要注意每次调用的参数大小,过大的消息会占用网络带宽和通信时间。
使用缓存解决
可以在写入数据主库的同时,把评论数据写到 Redis 缓存里,这样其他线程再获取评论信息时会优先查询缓存,也可以保证数据的一致性。
不过这种方式会带来缓存和数据库的一致性问题,比如两个线程同时更新数据,操作步骤如下:
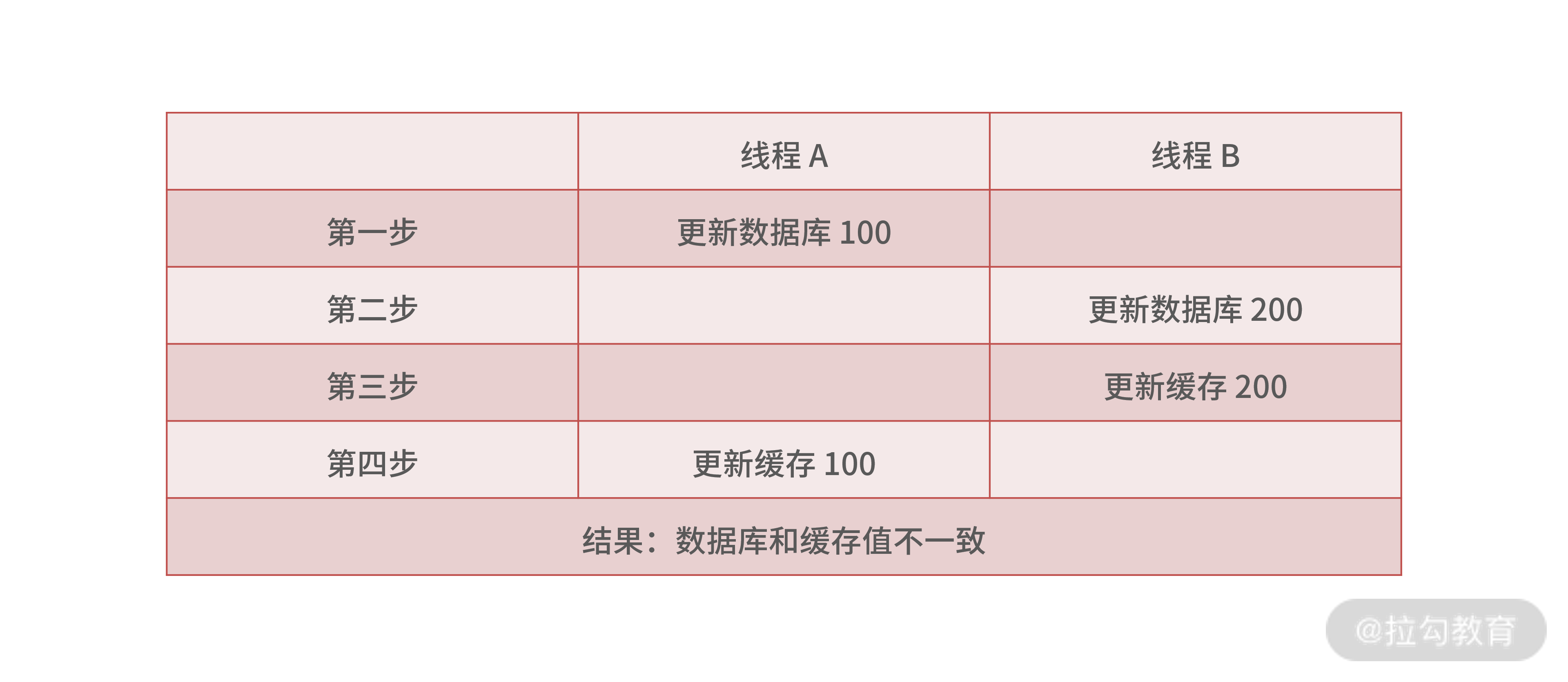
线程 A 先更新数据库为 100,此时线程 B 把数据库和缓存中的数据都更新成了 200,然后线程 A 又把缓存更新为 100,这样数据库中的值 200 和缓存中的值 100 就不一致了,解决这个问题,你可以参考 06 讲。
总的来说,通过缓存解决 MySQL 主从复制延迟时,会出现数据库与缓存数据不一致的情况。虽然它和“使用数据冗余”的方案相比并不优雅,但我还是建议你在面试中做一下补充,这样可以引出更多的技术知识,展现自己与其他人的差异。
直接查询主库
该方案在使用时一定要谨慎,你要提前明确查询的数据量不大,不然会出现主库写请求锁行,影响读请求的执行,最终对主库造成比较大的压力。
当然了,面试官除了从架构上考察你对 MySQL 主从复制延迟的理解,还会问你一些扩展问题,比如:当 MySQL 做了主从分离后,对于数据库的使用方式就发生了变化,以前只需要使用一个数据库地址操作数据库,现在却要使用一个主库地址和多个从库地址,并且还要区分写入操作和查询操作,那从工程代码上设计,怎么实现主库和从库的数据访问呢?
实现主库和从库的数据库访问
一种简单的做法是:提前把所有数据源配置在工程中,每个数据源对应一个主库或者从库,然后改造代码,在代码逻辑中进行判断,将 SQL 语句发送给某一个指定的数据源来处理。
这个方案简单易实现,但 SQL 路由规则侵入代码逻辑,在复杂的工程中不利于代码的维护。
另一个做法是:独立部署的代理中间件,如 MyCat,这一类中间件部署在独立的服务器上,一般使用标准的 MySQL 通信协议,可以代理多个数据库。
该方案的优点是隔离底层数据库与上层应用的访问复杂度,比较适合有独立运维团队的公司选型;缺陷是所有的 SQL 语句都要跨两次网络传输,有一定的性能损耗,再就是运维中间件是一个专业且复杂的工作,需要一定的技术沉淀。
技术认知
以上就是你在应聘初中级工程师时需要掌握的内容,如果你应聘的是高级研发工程师,在回答问题时,还要尽可能地展示自己对 MySQL 数据复制的抽象能力。因为在网络分布式技术错综复杂的今天,如果你能将技术抽象成一个更高层次的理论体系,很容易在面试中脱颖而出。
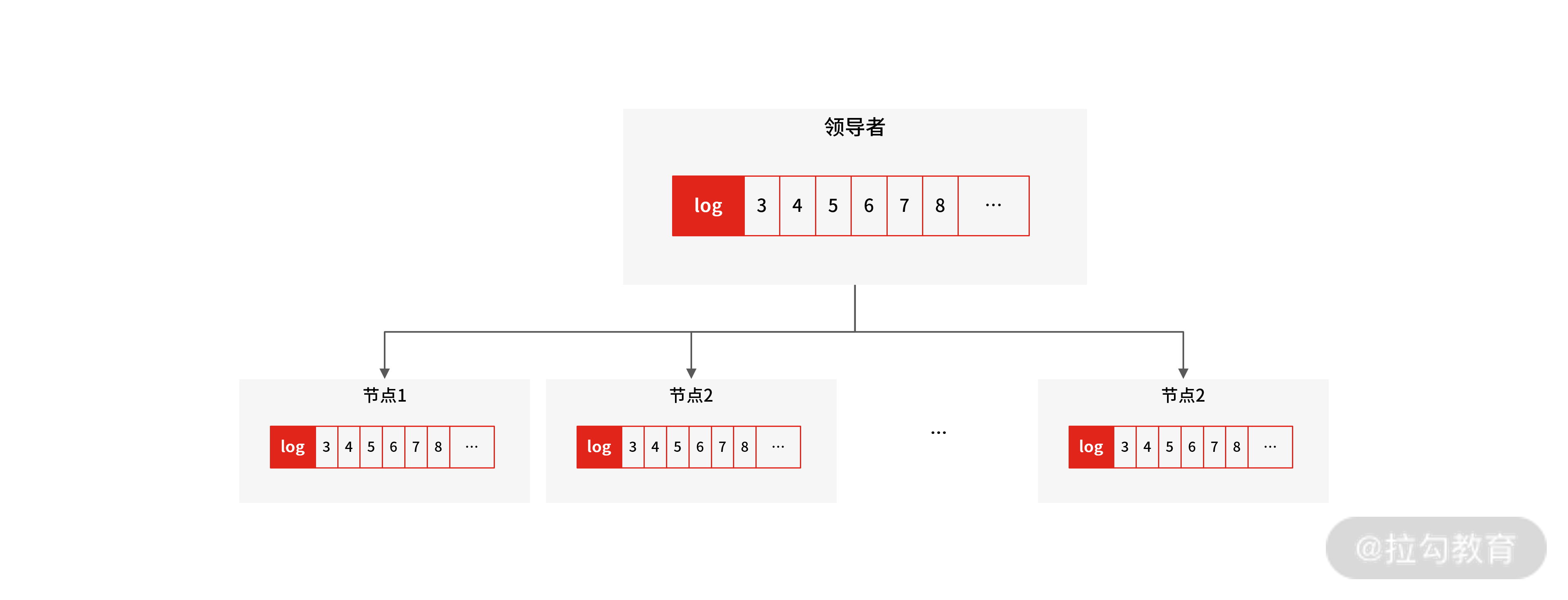
以 Raft 协议为例,其内部是通过日志复制同步的方式来实现共识的,例如在领导者选举成功后,它就会开始接收客户端的请求,此时每一个客户端请求都将被解析成一条指令日志,然后并行地向其他节点发起通知,要求其他节点复制这个日志条目,并最终在各个节点中回放日志,实现共识。
我们抽象一下它的运作机制:
运作机制
如果客户端将要执行的命令发送给集群中的一台服务器,那么这台服务器就会以日志的方式记录这条命令,然后将命令发送给集群内其他的服务,并记录在其他服务器的日志文件中,注意,只要保证各个服务器上的日志是相同的,并且各服务器都能以相同的顺序执行相同的命令的话,那么集群中的每个节点的执行结果也都会是一样的。
这种数据共识的机制就叫复制状态机,目的是通过日志复制和回放的方式来实现集群中所有节点内的状态一致性。
其实 MySQL 中的主从复制,通过 binlog 操作日志来实现从主库到从库的数据复制的,就是应用了这种复制状态机的机制。所以这种方式不是 MySQL 特有的。
除了我上面提到的 Raft 协议以外,在 Redis Cluster 中也用到了 backlog 来实现主从节点的数据复制,其方式和 MySQL 一模一样。
可以这么说,几乎所有的存储系统或数据库,基本都用了这样一套方法来解决数据复制和备份恢复等问题。这一点你可以在学习中进一步体会。
总结
今天,我们先从一个案例出发,了解了在互联网流量读多写少的情况下,需要通过“读写分离”提升系统的并发能力,又因为“读写分离”的前提是做 “主+从”的数据集群架构,所以我们又讲了主从复制的原理,以及怎么解决主从复制带来的延迟。
总的来说,在面试中,回答 MySQL 实现读写分离问题的前提,是你要掌握这些内容(这是初中级研发工程师都需要了解并掌握的):MySQL 主从复制的原理、模式、存在的问题,怎么解决。
对于中高级研发工程师来说,不仅要掌握这些内容,还要展现出对技术的抽象能力,例如本讲中的复制状态机的原理和应用场景。
今天的作业是:数据库读写分离一般应用于什么场景?你考虑过它能抗住多大的业务规模吗?我们下一讲见。
12 写多读少:MySQL 如何优化数据存储方案?
上一讲,我带你学习了在高并发读多写少的场景下,数据库的一种优化方案:读写分离。通过主从复制的技术把数据复制多份,读操作只读取从数据库中的数据,这样就增强了抵抗大量并发读请求的能力,提升了数据库的查询性能。这时,你的系统架构如下:
系统架构图
案例背景
假设在这样的背景下,面试官出了一道考题:
公司现有业务不断发展,流量剧增,交易数量突破了千万订单,但是订单数据还是单表存储,主从分离后,虽然减少了缓解读请求的压力,但随着写入压力增加,数据库的查询和写入性能都在下降,这时你要怎么设计架构?
这个问题可以归纳为:数据库写入请求量过大,导致系统出现性能与可用性问题。
要想解决该问题,你可以对存储数据做分片,常见的方式就是对数据库做“分库分表”,在实现上有三种策略:垂直拆分、水平拆分、垂直水平拆分。所以一些候选人通常会直接给出这样的回答“可以分库分表,比如垂直拆分、水平拆分、垂直水平拆分”。
这么回答真的可以吗?
案例分析
我在面试候选人时发现,大部分研发工程师都能把分库分表策略熟练地回答出来,因为这个技术是常识,那你可能会问了:既然这个技术很普遍,大家都知道,面试官为什么还要问呢?
虽然分库分表技术方案很常见,但是在面试中回答好并不简单。因为面试官不会单纯浮于表面问你“分库分表的思路”,而是会站在业务场景中,当数据出现写多读少时,考察你做分库分表的整体设计方案和技术实现的落地思路。一般会涉及这样几个问题:
什么场景该分库?什么场景该分表?
复杂的业务如何选择分片策略?
如何解决分片后的数据查询问题?
案例解答
如何确定分库还是分表?
针对“如何确定分库还是分表?”的问题,你要结合具体的场景。
何时分表
当数据量过大造成事务执行缓慢时,就要考虑分表,因为减少每次查询数据总量是解决数据查询缓慢的主要原因。你可能会问:“查询可以通过主从分离或缓存来解决,为什么还要分表?”但这里的查询是指事务中的查询和更新操作。
何时分库
为了应对高并发,一个数据库实例撑不住,即单库的性能无法满足高并发的要求,就把并发请求分散到多个实例中去(这种应对高并发的思路我之前也说过)。
总的来说,分库分表使用的场景不一样: 分表是因为数据量比较大,导致事务执行缓慢;分库是因为单库的性能无法满足要求。
如何选择分片策略?
在明确分库分表的场景后,面试官一般会追问“怎么进行分片?”换句话说就是按照什么分片策略对数据库进行分片?
垂直拆分
垂直拆分是根据数据的业务相关性进行拆分。比如一个数据库里面既存在商品数据,又存在订单数据,那么垂直拆分可以把商品数据放到商品库,把订单数据放到订单库。一般情况,垂直拆库常伴随着系统架构上的调整。
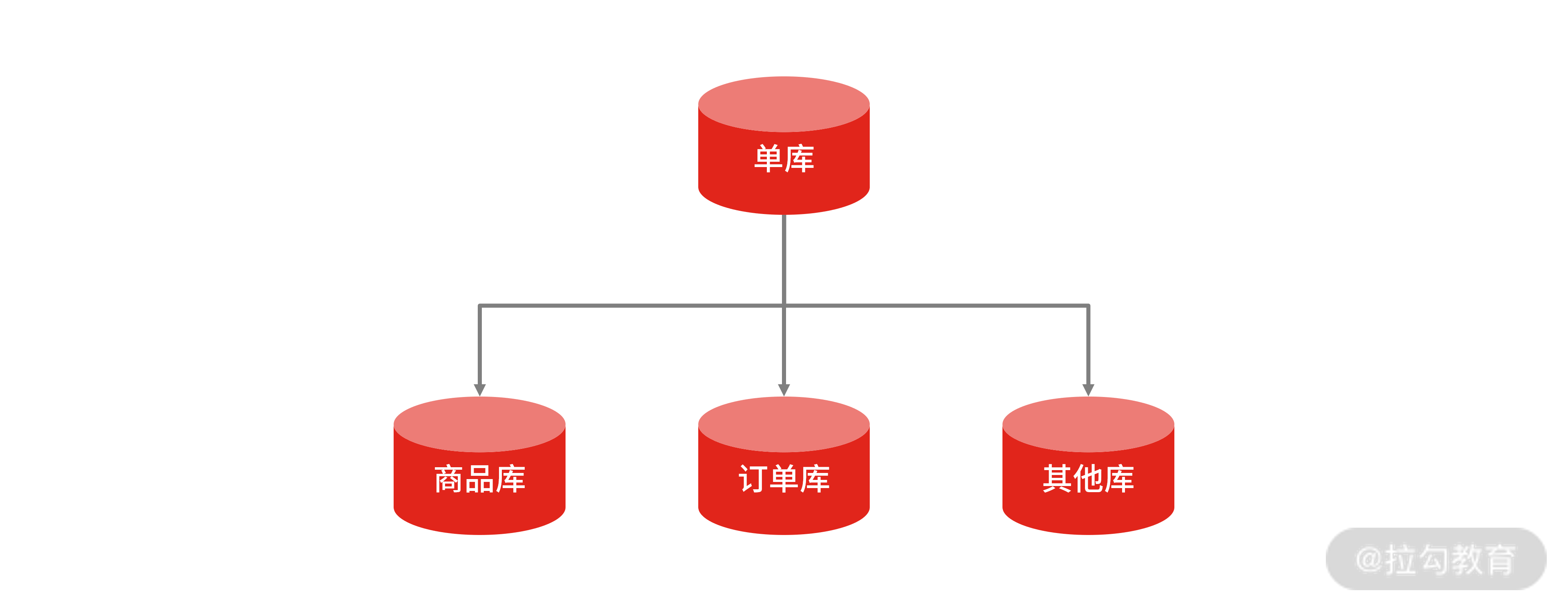
垂直拆分
比如在对做系统“微服务”改造时,将原本一个单体系统拆分成多个子系统,每个系统提供单独的服务,那么随着应用层面的拆分带来的也有数据层面的拆分,将一个主库的数据表,拆分到多个独立的子库中去。
对数据库进行垂直拆分最常规,优缺点也很明显。
垂直拆分可以把不同的业务数据进行隔离,让系统和数据更为“纯粹”,更有助于架构上的扩展。但它依然不能解决某一个业务的数据大量膨胀的问题,一旦系统中的某一个业务库的数据量剧增,比如商品系统接入了一个大客户的供应链,对于商品数据的存储需求量暴增,在这个时候,就要把数据拆分到多个数据库和数据表中,也就是对数据做水平拆分。
水平拆分
垂直拆分随架构改造而拆分,关注点在于业务领域,而水平拆分指的是把单一库表数据按照规则拆分到多个数据库和多个数据表中,比如把单表 1 亿的数据按 Hash 取模拆分到 10 个相同结构的表中,每个表 1 千万的数据。并且拆分出来的表,可以分别存放到不同的物理数据库中,关注点在于数据扩展。
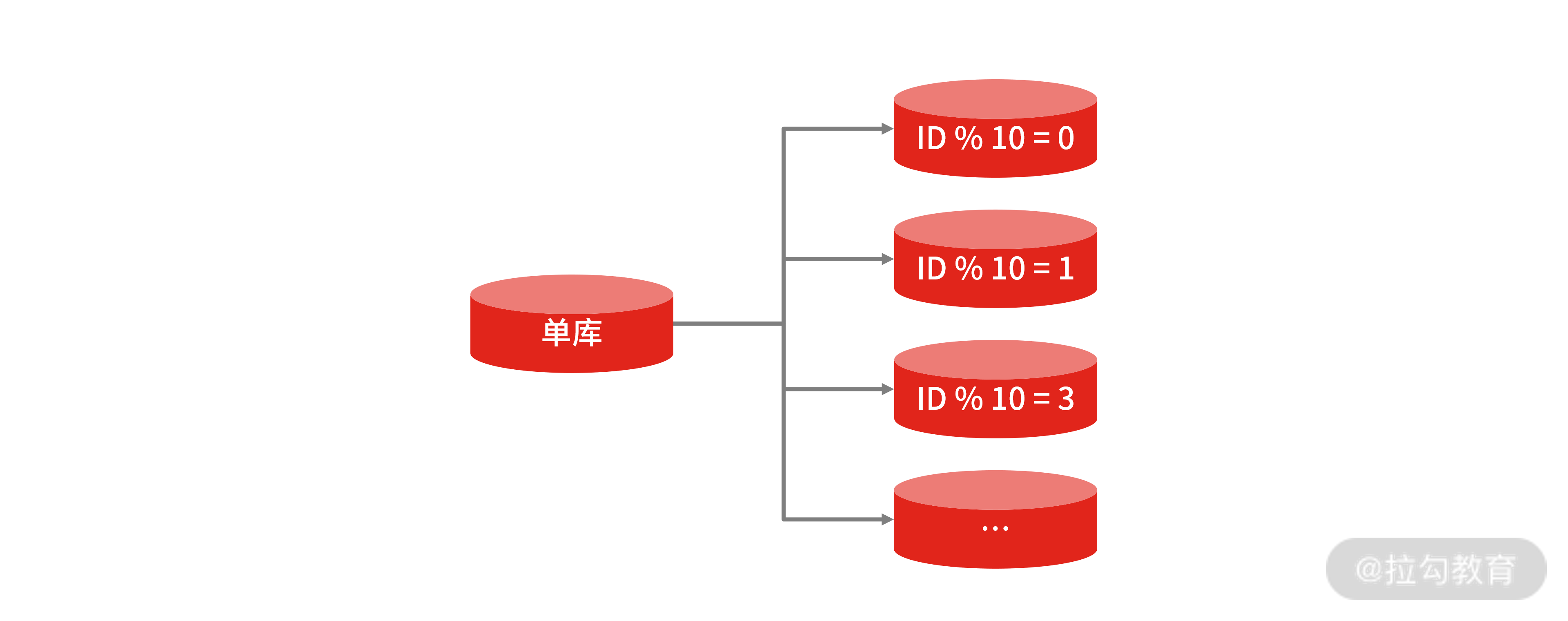
水平拆分
拆分的规则就是哈希分片和范围分片(这部分内容你可以参考 04 讲中的内容,我就不赘述了)。但我要强调一下 Range 分片,因为 04 讲中有些同学对 Range 分片解决数据热点的问题有些误解。
Range(范围分片)
是按照某一个字段的区间来拆分,最好理解的就是按照时间字段分片,比如可以把一个月的数据放入一张表中,这样在查询时就可以根据时间先定位数据存储在哪个表里面,再按照查询条件来查询。
但是按时间字段进行范围分片的场景并不多,因为会导致数据分布不均,毕竟不是每个月的销量都是平均的。所以常见的 Range 分片是按照字段类型,比如按照商品的所属品类进行分片。这样与 Hash 分片不同的是,Range 分片就可以加入对于业务的预估。
Range 分片
但是同样的,由于不同“商品品类”的业务热点不同,对于商品数据存储也会存在热点数据问题,这个时候处理的手段有两个。
1、垂直扩展
由于 Range 分片是按照业务特性进行的分片策略,所以可以对热点数据做垂直扩展,即提升单机处理能力。在业务发展突飞猛进的初期,建议使用“增强单机硬件性能”的方式提升系统处理能力,因为此阶段,公司的战略往往是发展业务抢时间,“增强单机硬件性能”是最快的方法。
2、分片元数据
单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是水平扩展,所以结合业务的特性,就需要在 Range 的基础上引入“分片元数据”的概念:分片的规则记录在一张表里面,每次执行查询的时候,先去表里查一下要找的数据在哪个分片中。
这种方式的优点是灵活性高,并且分片规则可以随着业务发展随意改动。比如当某个分片已经是热点了,那就可以把这个分片再拆成几个分片,或者把这个分片的数据移到其他分片中去,然后修改一下分片元数据表,就可以在线完成数据的再分片了。
分片元数据
但你要注意,分片元数据本身需要做高可用(面试考察点可以参考 04 讲中的内容)。方案缺点是实现起来复杂,需要二次查询,需要保证分片元数据服务的高可用。不过分片元数据表可以通过缓存进行提速。
垂直水平拆分
垂直水平拆分,是综合垂直和水平拆分方式的一种混合方式,垂直拆分把不同类型的数据存储到不同库中,再结合水平拆分,使单表数据量保持在合理范围内,提升性能。
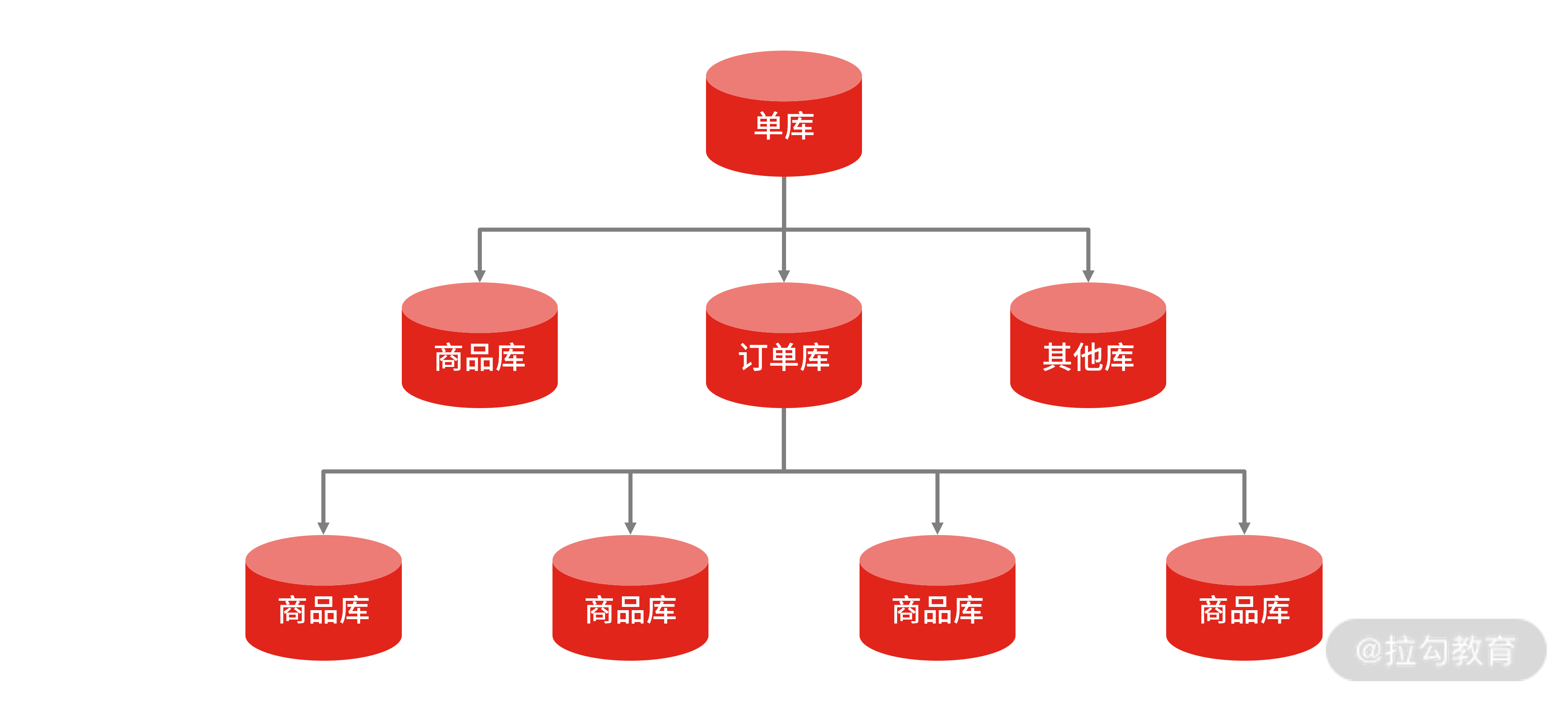
垂直水平拆分
如何解决数据查询问题?
分库分表引入的另外一个问题就是数据查询的问题(比较常见),比如面试官会问类似的问题:
在未分库分表之前,我们查询数据总数时,可以直接通过 SQL 的 count() 命令,现在数据分片到多个库表中,如何解决呢?
解题思路很多,你可以考虑其他的存储方案,比如聚合查询使用频繁时,可以将聚合查询的数据同步到 ES 中,或者将计数的数据单独存储在一张表里。如果是每日定时生成的统计类报表数据,也可以将数据同步到 HDFS 中,然后用一些大数据技术来生成报表。
技术认知
不夸张地说,MySQL 是每个后端开发人员都要精通的数据库,因为其开源、轻量级,且有着金融级别的事务保证,所以一直是互联网项目的标配。
但是随着近些年技术的发展,下一代存储技术上出现了 NewSQL ,我觉得未来它可能会取代 MySQL :
NewSQL 是新一代的分布式数据库,不但具备分布式存储系统的高性能、高可用,弹性扩容等能力,还兼容传统关系型数据库的 SQL 标准。并且,还提供了和传统关系型数据库不相上下的事务保证,是具备了支撑未来交易类业务能力的。
为了能体现你个人的技术视野,我希望你在面试的过程中,也谈一些与存储这个技术领域有关的内容,比如 NewSQL 的发展和相关开源产品,如 CockroachDB、TiDB。你可以在面试前熟悉一下 NewSQL 数据库的原理,然后以其和现有关系型的区别为切入点,和面试官讨论即可。
总结
总的来说,在面对数据库容量瓶颈和写请求并发量大时,你可以选择垂直分片和水平分片:垂直分片一般随着业务架构拆分来进行;水平分片通常按照 Hash(哈希分片)取模和 Range(范围分片)进行,并且,通常的形态是垂直拆分伴随着水平拆分,即先按照业务垂直拆分后,再根据数据量的多少决定水平分片。
Hash 分片在互联网中应用最为广泛,简单易实现,可以保证数据非常均匀地分布到多个分片,但其过滤掉了业务属性,不能根据业务特性进行调整。而 Range 分片却能预估业务,更高效地扫描数据记录(Hash 分片由于数据被打散,扫描操作的 I/O 开销更大)。除了 Hash 分片和 Range 分片,更为灵活的方式是基于分片元数据。
不过你要注意,这几种方式也会引入诸如聚合查询的问题,要想解决聚合查询,你可以让聚合查询记录存储在其他存储设备中(比如 ES、HDFS)。
最后,除了中规中矩地回答面试官提出的问题,我也希望你能展示自己的技术视野,选择 NewSQL 作为切入点。
今天的作业是:做数据库分片时,比如对商品表进行分片,那么商品的关联表如何处理呢?感谢你的阅读,我们下一讲见。
13 缓存原理:应对面试你要掌握 Redi 哪些原理?
这一讲我们聊一聊与 Redis 有关的话题。
提及缓存,就不得不提 Redis,Redis 已经是现在使用最广泛的缓存中间件了,这一讲,我以 Redis 的原理为切入点,带你了解在面试过程中那些与 Redis 原理有关的题目,帮你捋清答题思路,抓住重点。
案例背景
我们现在就模拟一场面试,假如我是面试官,你是候选人,我问你:
Redis 属于单线程还是多线程?
这道题其实就在考察 Redis 的线程模型(这几乎是 Redis 必问的问题之一)。
案例分析
很多初级研发工程师基本都知道 Redis 是单线程的,并且能说出 Redis 单线程的一些优缺点,比如,实现简单,可以在无锁的情况下完成所有操作,不存在死锁和线程切换带来的性能和时间上的开销,但同时单线程也不能发挥多核 CPU 的性能。
很明显,如果你停留在上面的回答思路上,只能勉强及格,因为对于这样一道经典的面试题,你回答得没有亮点,几乎丧失了机会。一个相对完整的思路应该基于 Redis 单线程,补充相关的知识点,比如:
Redis 只有单线程吗?
Redis 是单线程的,主要是指 Redis 的网络 I/O 线程,以及键值的 SET 和 GET 等读写操作都是由一个线程来完成的。但 Redis 的持久化、集群同步等操作,则是由另外的线程来执行的。
Redis 采用单线程为什么还这么快?
一般来说,单线程的处理能力应该要比多线程差才对,但为什么 Redis 还能达到每秒数万级的处理能力呢?主要有如下几个原因。
首先,一个重要的原因是,Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,比如哈希表和跳表。
其次,因为是单线程模型避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
最后,也是最重要的一点, Redis 采用了 I/O 多路复用机制(参考 07 讲,这里不再赘述)处理大量的客户端 Socket 请求,这让 Redis 可以高效地进行网络通信,因为基于非阻塞的 I/O 模型,就意味着 I/O 的读写流程不再阻塞。
但是因为 Redis 不同版本的特殊性,所以对于 Redis 的线程模型要分版本来看。
Redis 4.0 版本之前,使用单线程速度快的原因就是上述的几个原因;
Redis 4.0 版本之后,Redis 添加了多线程的支持,但这时的多线程主要体现在大数据的异步删除功能上,例如 unlink key、flushdb async、flushall async 等。
Redis 6.0 版本之后,为了更好地提高 Redis 的性能,新增了多线程 I/O 的读写并发能力,但是在面试中,能把 Redis 6.0 中的多线程模型回答上来的人很少,如果你能在面试中补充 Redis 6.0 多线程的原理,势必会增加面试官对你的认可。
你可以在面试中这样补充:
虽然 Redis 一直是单线程模型,但是在 Redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上,所以为了提高网络请求处理的并行度,Redis 6.0 对于网络请求采用多线程来处理。但是对于读写命令,Redis 仍然使用单线程来处理。
当然了, “Redis 的线程模型”只是 Redis 原理中的一个考点,如果你想做足准备,回答好 Redis 相关的问题,还需前提掌握 Redis 的主线知识点。我从高性能、高可用的角度出发,把 Redis 的核心原理考点梳理成一张图(之所以整理这样的体系结构,是因为你最容易在以下的考点中出错、踩坑,也是为了便于你的记忆):
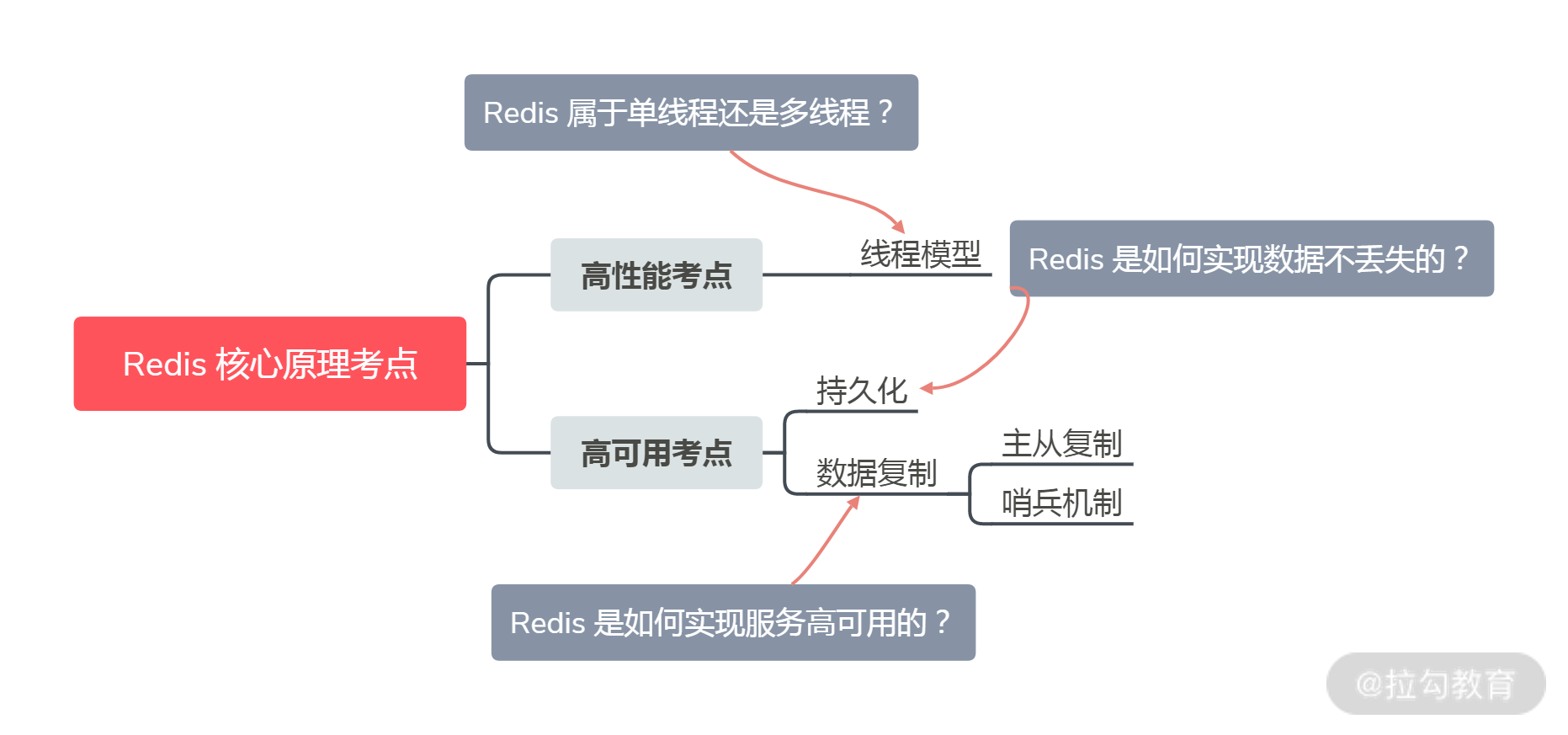
Redis 高性能和高可用的核心考点
从图中,你可以看到,线程模型只是高性能考点中的一环,而高可用考点中,包括了持久化、数据复制(主从复制,哨兵复制)等内容。所以在讲完 Redis 的线程模型的考点之后,接下来咱们再来了解持久化和数据复制的考点。
关于持久化和数据复制,面试官不会问得很直白,比如“Redis 的持久化是怎么做的?”而是立足在某一个问题点:
Redis 是如何实现数据不丢失的(考察持久化)?
Redis 是如何实现服务高可用的(考察数据复制)?
案例解答
Redis 如何实现数据不丢失?
我们知道,缓存数据库的读写都是在内存中,所以它的性能才会高,但在内存中的数据会随着服务器的重启而丢失,为了保证数据不丢失,要把内存中的数据存储到磁盘,以便缓存服务器重启之后,还能够从磁盘中恢复原有的数据,这个过程就是 Redis 的数据持久化。
这也是 Redis 区别于其他缓存数据库的优点之一(比如 Memcached 就不具备持久化功能)。Redis 的数据持久化有三种方式。
AOF 日志(Append Only File,文件追加方式):记录所有的操作命令,并以文本的形式追加到文件中。
RDB 快照(Redis DataBase):将某一个时刻的内存数据,以二进制的方式写入磁盘。
混合持久化方式:Redis 4.0 新增了混合持久化的方式,集成了 RDB 和 AOF 的优点。
接下来我们看一下这三种方式的实现原理。
AOF 日志是如何实现的?
通常情况下,关系型数据库(如 MySQL)的日志都是“写前日志”(Write Ahead Log, WAL),也就是说,在实际写数据之前,先把修改的数据记到日志文件中,以便当出现故障时进行恢复,比如 MySQL 的 redo log(重做日志),记录的就是修改后的数据。
而 AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的,不同的是,Redis 的 AOF 日志的记录顺序与传统关系型数据库正好相反,它是写后日志,“写后”是指 Redis 要先执行命令,把数据写入内存,然后再记录日志到文件。
AOF 执行过程
那么面试的考察点来了:Reids 为什么先执行命令,在把数据写入日志呢?为了方便你理解,我整理了关键的记忆点:
因为 ,Redis 在写入日志之前,不对命令进行语法检查;
所以,只记录执行成功的命令,避免了出现记录错误命令的情况;
并且,在命令执行完之后再记录,不会阻塞当前的写操作。
当然,这样做也会带来风险(这一点你也要在面试中给出解释)。
数据可能会丢失: 如果 Redis 刚执行完命令,此时发生故障宕机,会导致这条命令存在丢失的风险。
可能阻塞其他操作: 虽然 AOF 是写后日志,避免阻塞当前命令的执行,但因为 AOF 日志也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
又因为 Redis 的持久化离不开 AOF 和 RDB,所以我们就需要学习 RDB。
那么 RDB 快照是如何实现的呢?
因为 AOF 日志记录的是操作命令,不是实际的数据,所以用 AOF 方法做故障恢复时,需要全量把日志都执行一遍,一旦日志非常多,势必会造成 Redis 的恢复操作缓慢。
为了解决这个问题,Redis 增加了 RDB 内存快照(所谓内存快照,就是将内存中的某一时刻状态以数据的形式记录在磁盘中)的操作,它即可以保证可靠性,又能在宕机时实现快速恢复。
和 AOF 不同的是,RDB 记录 Redis 某一时刻的数据,而不是操作,所以在做数据恢复时候,只需要直接把 RDB 文件读入内存,完成快速恢复。
以上是 RDB 的主要原理,这里存在两个考点。
RDB 做快照时会阻塞线程吗?
因为 Redis 的单线程模型决定了它所有操作都要尽量避免阻塞主线程,所以对于 RDB 快照也不例外,这关系到是否会降低 Redis 的性能。
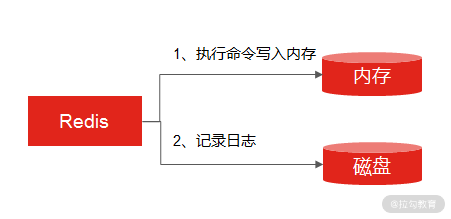
为了解决这个问题,Redis 提供了两个命令来生成 RDB 快照文件,分别是 save 和 bgsave。save 命令在主线程中执行,会导致阻塞。而 bgsave 命令则会创建一个子进程,用于写入 RDB 文件的操作,避免了对主线程的阻塞,这也是 Redis RDB 的默认配置。
RDB 做快照的时候数据能修改吗?
这个问题非常重要,考察候选人对 RDB 的技术掌握得够不够深。你可以思考一下,如果在执行快照的过程中,数据如果能被修改或者不能被修改都会带来什么影响?
如果此时可以执行写操作:意味着 Redis 还能正常处理写操作,就可能出现正在执行快照的数据是已经被修改了的情况;
如果此时不可以执行写操作:意味着 Redis 的所有写操作都得等到快照执行完成之后才能执行,那么就又出现了阻塞主线程的问题。
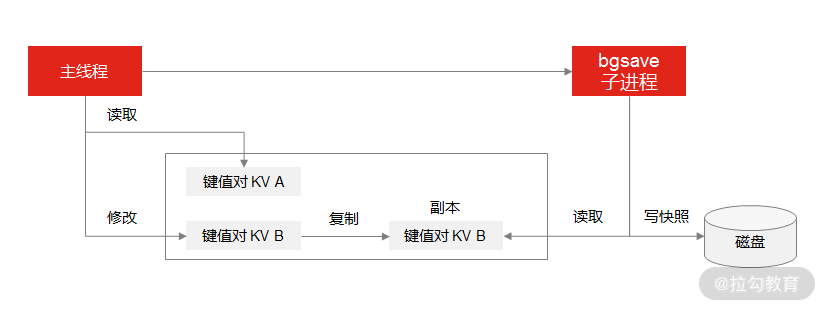
那Redis 是如何解决这个问题的呢? 它利用了 bgsave 的子进程,具体操作如下:
如果主线程执行读操作,则主线程和 bgsave 子进程互相不影响;
如果主线程执行写操作,则被修改的数据会复制一份副本,然后 bgsave 子进程会把该副本数据写入 RDB 文件,在这个过程中,主线程仍然可以直接修改原来的数据。
Redis 是如何保证执行快照期间数据可修改
要注意,Redis 对 RDB 的执行频率非常重要,因为这会影响快照数据的完整性以及 Redis 的稳定性,所以在 Redis 4.0 后,增加了 AOF 和 RDB 混合的数据持久化机制: 把数据以 RDB 的方式写入文件,再将后续的操作命令以 AOF 的格式存入文件,既保证了 Redis 重启速度,又降低数据丢失风险。
我们来总结一下,当面试官问你“Redis 是如何实现数据不丢失的”时,你首先要意识到这是在考察你对 Redis 数据持久化知识的掌握程度,那么你的回答思路是:先说明 Redis 有几种持久化的方式,然后分析 AOF 和 RDB 的原理以及存在的问题,最后分析一下 Redis 4.0 版本之后的持久化机制。
Redis 如何实现服务高可用?
另外,Redis 不仅仅可以用来当作缓存,很多时候也会直接作为数据存储,那么你就要一个高可用的 Redis 服务,来支撑和保证业务的正常运行。那么你怎么设计一个不宕机的 Redis 高可用服务呢?
思考一下,解决数据高可用的手段是什么?是副本。那么要想设计一个高可用的 Redis 服务,一定要从 Redis 的多服务节点来考虑,比如 Redis 的主从复制、哨兵模式,以及 Redis 集群。这三点是你一定要在面试中回答出来的。
主从同步 (主从复制)
这是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,这样我们就可以对 Redis 做读写分离了,来承载更多的并发操作,这里和 MySQL 的主从复制原理上是一样的。
Redis Sentinel(哨兵模式)
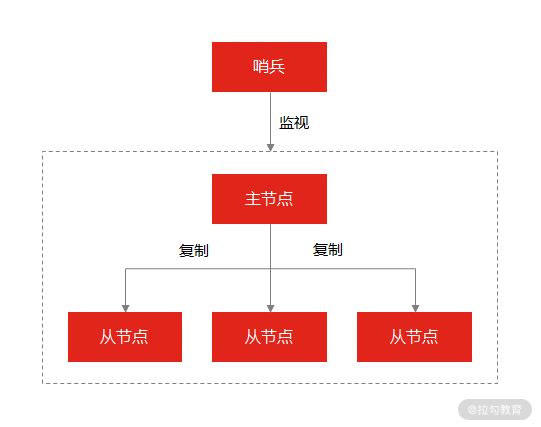
在使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复,为了解决这个问题,Redis 增加了哨兵模式(因为哨兵模式做到了可以监控主从服务器,并且提供自动容灾恢复的功能)。
哨兵模式
Redis Cluster(集群)
Redis Cluster 是一种分布式去中心化的运行模式,是在 Redis 3.0 版本中推出的 Redis 集群方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
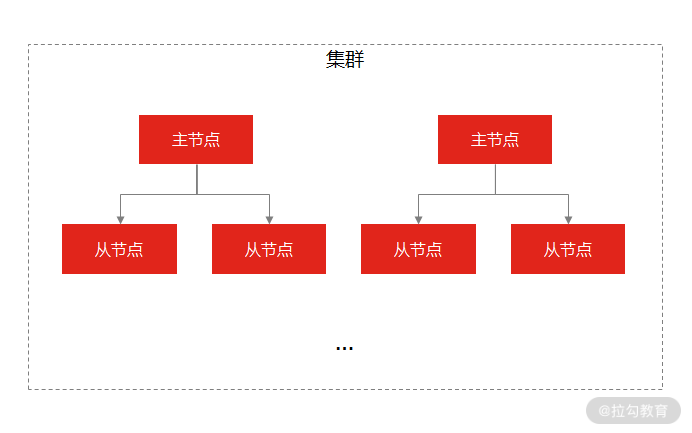
集群
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步。
根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。
再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
剩下的一个问题就是,这些哈希槽怎么被映射到具体的 Redis 实例上的呢?有两种方案。
平均分配: 在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群实例上。比如集群中有 9 个实例,则每个实例上槽的个数为 16384/9 个。
手动分配: 可以使用 cluster meet 命令手动建立实例间的连接,组成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数,为了方便你的理解,我通过一张图来解释数据、哈希槽,以及实例三者的映射分布关系。
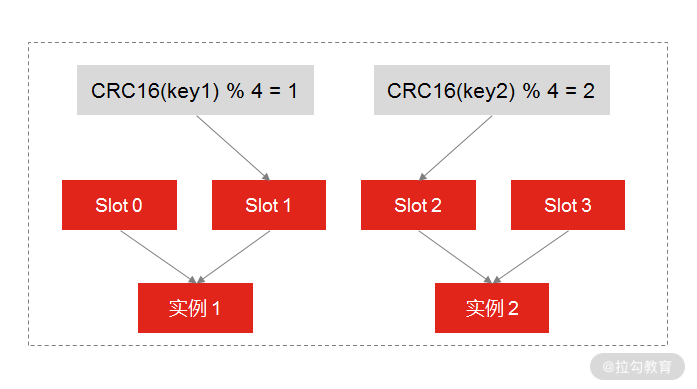
Redis 手动分配哈希槽
示意图中的分片集群一共有 3 个实例,假设有 4 个哈希槽时,我们就可以通过命令手动分配哈希槽,比如实例 1 保存哈希槽 0 和 1,实例 2 保存哈希槽 2 和 3。
然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 5 进行取模,再根据各自的模数结果,就可以被映射到对应的实例 1 和实例 3 上了。
我们再来总结一下,主从同步是 Redis 高可用最基础的服务高可用方案,但它当发生故障时,需要手动恢复故障,因此就有了哨兵模式用于监控和实现主从服务器的自动容灾。最后我讲了目前最常用的高可用方案 Redis 集群,这三种高可用方式都是你需要掌握的。
总结
这一讲,我讲了 Redis 的三个核心问题:线程模型、数据持久化,以及高可用,我想强调这样几个重点:
对于线程模型的知识点,你要分开三条线进行理解(Redis 4.0 之前、Redis 4.0 之后,以及 Redis 6.0)。
对于数据持久化,你要掌握 Redis 持久化的几种方案,AOF 和 RDB 的原理,以及为了弥补他们的缺点,Redis 增加了混合持久化方式,以较小的性能开销保证数据的可靠性。
实现高可用的三种手段:主从同步、哨兵模式和 Redis 集群服务,对于 Redis 集群,你要掌握哈希槽的数据分布机制,以及自动分配和手动分配的实现原理 。
最后,我还要强调一下,Redis 是应聘初中级研发工程师必问的知识点,它是目前缓存数据库的代名词,所以对于 Redis 知识点的掌握,无论是在面试过程中,还是在实际的工作中,都是经常要用到的。
这就是今天的全部内容,留一道思考题给你吧,如何实现 Redis 和 MySQL 的数据一致性?我们下一讲见。
14 缓存策略:面试中如何回答缓存穿透、雪崩等问题?
上一讲,我带你学习了开源缓存数据库 Redis 的原理(比如线程模型、数据持久化,以及数据复制)。这一讲,我们从应用案例入手,来了解经常遇到的缓存设计问题,比如缓存雪崩、缓存并发,缓存穿透等。
案例背景
我们来模拟一个面试场景(如图所示) :
系统收到用户的频繁查询请求时,会先从缓存中查找数据,如果缓存中有数据,直接从中读取数据,响应给请求方;如果缓存中没有数据,则从数据库中读取数据,然后再更新缓存,这样再获取这条数据时,可以直接从缓存中获取,不用再读取数据库。
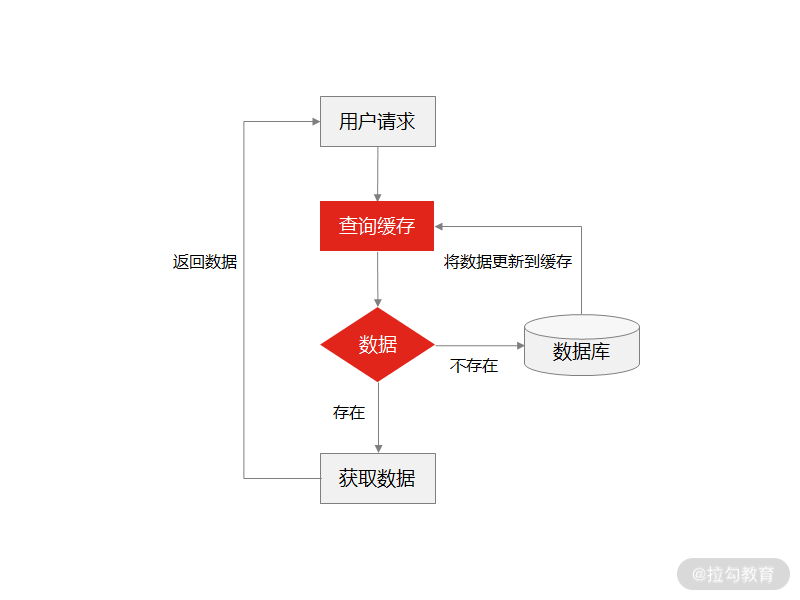
缓存设计方案
这是一种常见的解决“查询请求频繁”的设计方案,那么这种方案在查询请求并发较高时,会存在什么问题呢?
案例分析
从“案例背景”中,你可以发现,在面试中面试官通常考察“缓存设计”的套路是:给定一个场景(如查询请求量较高的场景)先让候选人说明场景中存在的问题,再给出解决方案。
我们以“电商平台商品详情页”为例,商品详情页中缓存了商品名称、描述、价格、优惠政策等信息,在双十一大促时,商品详情页的缓存经常存在缓存穿透、缓存并发、缓存雪崩,以及缓存设计等问题,接下来我们就重点解决这些高频问题,设计出一套高可用高性能的缓存架构方案。
案例解答
缓存穿透问题
缓存穿透指的是每次查询个别 key 时,key 在缓存系统不命中,此时应用系统就会从数据库中查询,如果数据库中存在这条数据,则获取数据并更新缓存系统。但如果数据库中也没有这条数据,这个时候就无法更新缓存,就会造成一个问题:查询缓存中不存在的数据时,每次都要查询数据库。
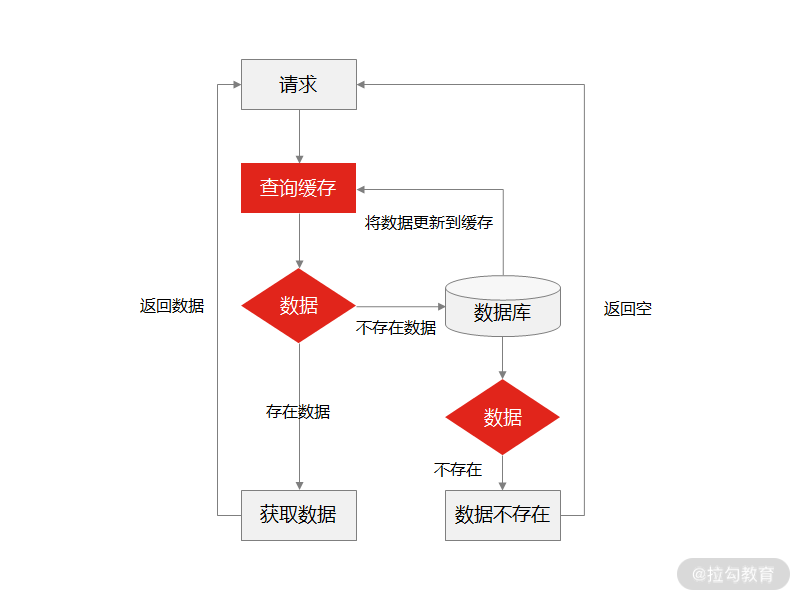
缓存穿透
那么如果有人利用“查询缓存中不存在的数据时,每次都要查询数据库”恶意攻击的话,数据库会承担非常大的压力,甚至宕机。
解决缓存穿透的通用方案是: 给所有指定的 key 预先设定一个默认值,比如空字符串“Null”,当返回这个空字符串“Null”时,我们可以认为这是一个不存在的 key,在业务代码中,就可以判断是否取消查询数据库的操作,或者等待一段时间再请求这个 key。如果此时取到的值不再是“Null”,我们就可以认为缓存中对应的 key 有值了,这就避免出现请求访问到数据库的情况,从而把大量的类似请求挡在了缓存之中。
缓存并发问题
假设在缓存失效的同时,出现多个客户端并发请求获取同一个 key 的情况,此时因为 key 已经过期了,所有请求在缓存数据库中查询 key 不命中,那么所有请求就会到数据库中去查询,然后当查询到数据之后,所有请求再重复将查询到的数据更新到缓存中。
这里就会引发一个问题,所有请求更新的是同一条数据,这不仅会增加数据库的压力,还会因为反复更新缓存而占用缓存资源,这就叫缓存并发。那你怎么解决缓存并发呢?
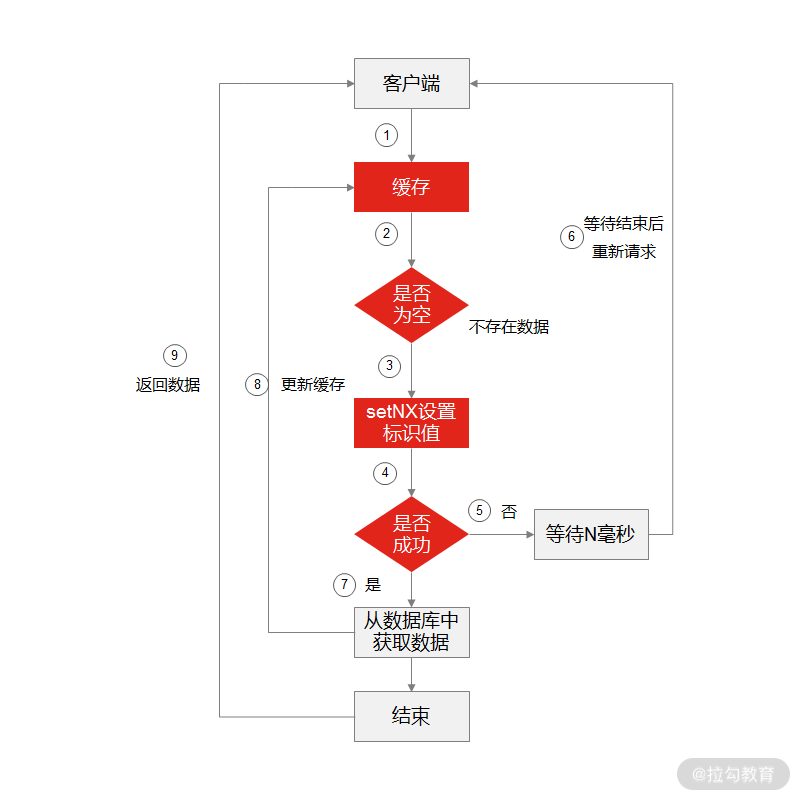
解决缓存并发
首先,客户端发起请求,先从缓存中读取数据,判断是否能从缓存中读取到数据;
如果读取到数据,则直接返回给客户端,流程结束;
如果没有读取到数据,那么就在 Redis 中使用 setNX 方法设置一个状态位,表示这是一种锁定状态;
如果锁定状态设置成功,表示已经锁定成功,这时候请求从数据库中读取数据,然后更新缓存,最后再将数据返回给客户端;
如果锁定状态没有设置成功,表示这个状态位已经被其他请求锁定,此时这个请求会等待一段时间再重新发起数据查询;
再次查询后发现缓存中已经有数据了,那么直接返回数据给客户端。
这样就能保证在同一时间只能有一个请求来查询数据库并更新缓存系统,其他请求只能等待重新发起查询,从而解决缓存并发的问题。
缓存雪崩问题
我们在实际开发过程中,通常会不断地往缓存中写数据,并且很多情况下,程序员在开发时,会将缓存的过期时间设置为一个固定的时间常量(比如 1 分钟、5 分钟)。这就可能出现系统在运行中,同时设置了很多缓存 key,并且这些 key 的过期时间都一样的情况,然后当 key 到期时,缓存集体同时失效,如果此时请求并发很高,就会导致大面积的请求打到数据库,造成数据库压力瞬间增大,出现缓存雪崩的现象。
对于缓存雪崩问题,我们可以采用两种方案解决。
将缓存失效时间随机打散: 我们可以在原有的失效时间基础上增加一个随机值(比如 1 到 10 分钟)这样每个缓存的过期时间都不重复了,也就降低了缓存集体失效的概率。
设置缓存不过期: 我们可以通过后台服务来更新缓存数据,从而避免因为缓存失效造成的缓存雪崩,也可以在一定程度上避免缓存并发问题。
讲到这儿,缓存穿透、并发、雪崩的相关问题我们就讲完了。在通常情况下,面试官还会出一些缓存设计问题,比如:
怎么设计一个动态缓存热点数据的策略?
怎么设计一个缓存操作与业务分离的架构?
这是作为中高级研发工程师必须要掌握的内容。
面试官会这样问:由于数据存储受限,系统并不是将所有数据都需要存放到缓存中的,而只是将其中一部分热点数据缓存起来,那么就引出来一个问题,即如何设计一个缓存策略,可以动态缓存热点数据呢?
我们同样举电商平台场景中的例子,现在要求只缓存用户经常访问的 Top 1000 的商品。
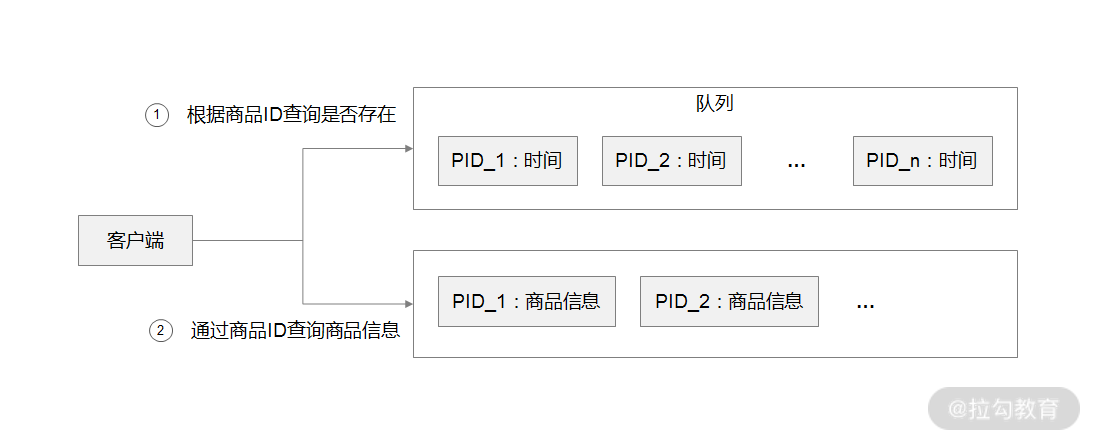
解决缓存热点问题
那么缓存策略的总体思路:就是通过判断数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据,具体细节如下。
先通过缓存系统做一个排序队列(比如存放 1000 个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前。
同时系统会定期过滤掉队列中排名最后的 200 个商品,然后再从数据库中随机读取出 200 个商品加入队列中。
这样当请求每次到达的时候,会先从队列中获取商品 ID,如果命中,就根据 ID 再从另一个缓存数据结构中读取实际的商品信息,并返回。
在 Redis 中可以用 zadd 方法和 zrange 方法来完成排序队列和获取 200 个商品的操作。
前面的内容中,我们都是将缓存操作与业务代码耦合在一起,这样虽然在项目初期实现起来简单容易,但是随着项目的迭代,代码的可维护性会越来越差,并且也不符合架构的“高内聚,低耦合”的设计原则,那么如何解决这个问题呢?
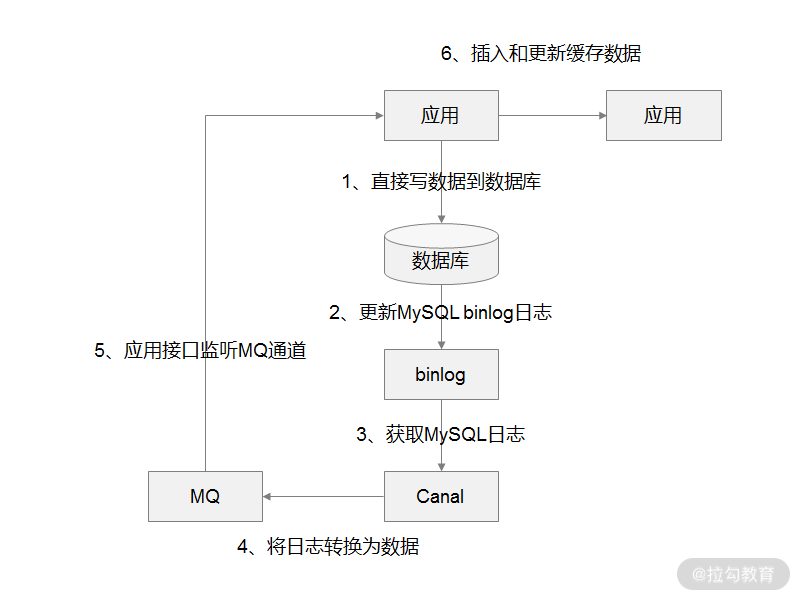
回答的思路可以是这样:将缓存操作与业务代码解耦,实现方案上可以通过 MySQL Binlog + Canal + MQ 的方式。
我举一个实际的场景,比如用户在应用系统的后台添加一条配置信息,配置信息存储到了 MySQL 数据库中,同时数据库更新了 Binlog 日志数据,接着再通过使用 Canal 组件来获读取最新的 Binlog 日志数据,然后解析日志数据,并通过事先约定好的数据格式,发送到 MQ 消息队列中,最后再由应用系统将 MQ 中的数据更新到 Redis 中,这样就完成了缓存操作和业务代码之间的解耦。
解决缓存操作与业务系统分离
总结
为了方便你记忆,我总结一下今天的内容:
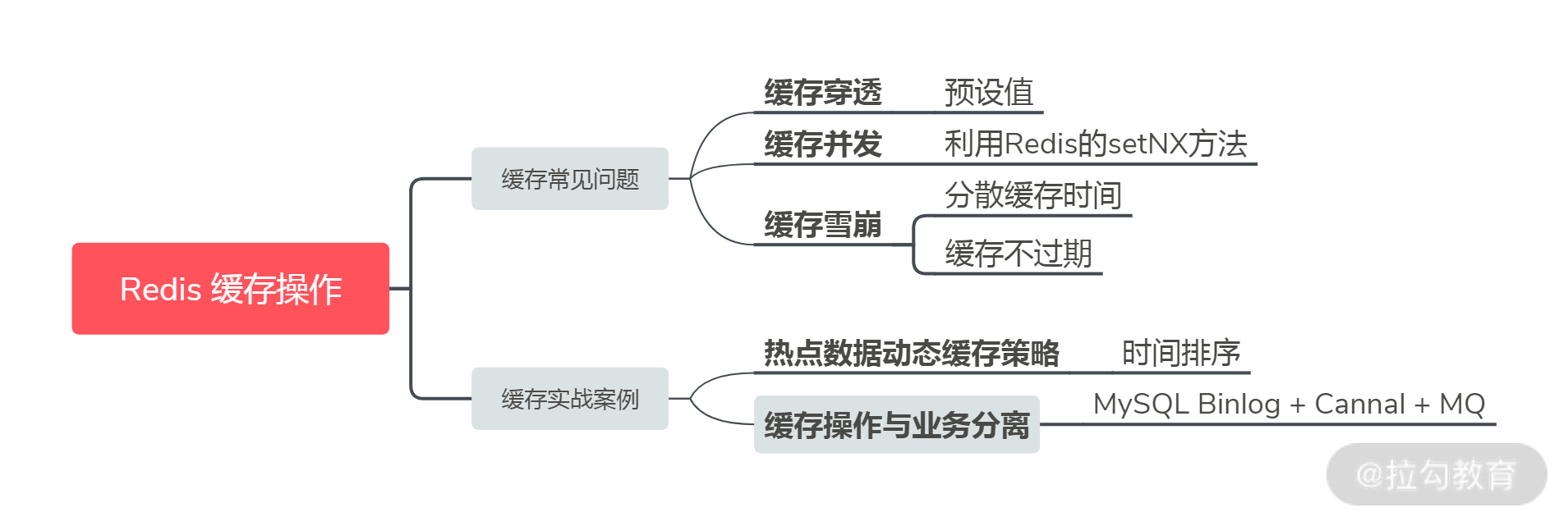
今天这一讲,我推荐采用预设值方案解决缓存穿透(当然还有基于布隆过滤器的实现方式,但它本身存在误判的情况,实现起来也较复杂,所以我不推荐使用,不过你可以了解一下)。另外,你可以利用 Redis 的 setNX 方法来配合解决缓存并发。除此之外,你可以通过将缓存失效时间随机打散,或者设置缓存不过期,解决缓存雪崩的问题。
最后,要强调一下,缓存的使用虽然给我们带来非常多的好处,但你也要充分考虑缓存使用上的一些坑。比如缓存和数据库的一致性、缓存容量限制,以及每次存放到缓存的数据大小等。今天的作业是:如何用 Redis 实现一个计数器?我们下一讲见。
架构面试精讲第三节 分布式技术RPC、MQ、Redis、Mysql、restful详解相关推荐
- 架构面试精讲第四节 高并发下高可用、高性能架构详解
15 如何向面试官证明你做的系统是高可用的? 我们已经用了五个模块分别讲了架构原理.分布式技术.中间件.数据库,以及缓存,这些都是面试中必考的技术领域和技术点,又因为我们处在大数据和互联网时代,所以高 ...
- Python精讲:在Python中添加和删除集合元素详解
欢迎你来到站长在线的站长学堂学习Python知识,本文学习的是<在Python中添加和删除集合元素详解>.本知识点主要讲的是添加和删除元素,包括:在Python中向集合里面添加元素可以使用 ...
- 站长在线python精讲:在Python中使用“+”运算符来拼接字符串详解
欢迎你来到站长在线的站长学堂学习Python知识,本文学习的是<在Python中使用"+"运算符来拼接字符串详解>.本知识点主要内容有:在Python中,我们可以使用& ...
- 站长在线Python精讲:在Python中函数的定义与创建详解
欢迎你来到站长在线的站长学堂学习Python知识,本文学习的是<在Python中函数的定义与创建详解>.本文的主要内容有:函数的定义.函数的定义规则.函数的创建. 目录 1.函数的定义 2 ...
- 新概念英语精讲 钟平 pdf_新概念英语500核心词汇详解(14)well
新概念英语原汁原味的英文精品,语言优美,词汇实用,句型工整又富于变化.今天我们来学习well这个单词,well这个单词在新概念英语第一册第九课中第一次出现. well [wel] 基本词义 ❶adj. ...
- Python精讲:在Python中遍历字典的三大方法详解
欢迎你来到站长在线的站长学堂学习Python知识,本文学习的是<在Python中遍历字典的三大方法详解>.本知识点主要内容有:使用字典对象的items()方法可以遍历字典的项和字典的&qu ...
- 面试精讲之面试考点及大厂真题 - 分布式专栏 09 缓存必问:Reids持久化,高可用集群
09缓存必问:Reids持久化,高可用集群 宝剑锋从磨砺出,梅花香自苦寒来. 引言 Redis 的优点中提到 Redis 支持持久化数据,宕机后可恢复数据,持久化就是基于内存读写的 Redis 数据一 ...
- java基础:Java七大外企经典面试精讲视频
java基础:Java七大外企经典面试精讲视频 对于很多应聘java程序员的求职者来说,全面掌握java面试技巧,确实是自己找到一个好工作的敲门砖.今天小编在这里给大家分享一个关于java基础的Jav ...
- 视频教程-华为路由交换精讲系列20:OSPF技术精讲 [肖哥]视频课程-华为认证
华为路由交换精讲系列20:OSPF技术精讲 [肖哥]视频课程 肖老师(肖哥),思科认证讲师讲师(CCIE#27529),RedHat Linux认证讲师讲师,Juniper 认证讲师讲师,微软认证讲师 ...
最新文章
- HTML特殊字符过滤器
- Python 这么火,如何快速掌握?
- 关闭socket以及Socket选项
- 中国.NET域名注册量近55万个 稳居全球第三位
- DYNP_VALUES_READ
- javascript箭头函数和this的指向问题
- VUE data传值
- ASP对很长的文章做分页输出
- (3)Node.js APIS
- js读取http chunk流_极简 Node.js入门 教程双工流
- NRF24L01发送接收调试记录
- Django_基本配置保存
- [linux命令]基本命令
- 小米笔记本网卡驱动失效,无法联网
- java对象转map_java中实现map与对象相互转换的几种实现
- WGCLOUD在windows部署运行怎么实现隐藏窗口
- 【java毕业设计】基于javaEE+原生Servlet+MySql的企业员工信息管理系统设计与实现(毕业论文+程序源码)——企业员工信息管理系统
- 五面拿下阿里飞猪offer,java基础入门pdf百度云
- Hadoop、Hive、HDFS、Hbase、KUDU、Spark之间关系
- SQL和Oracle获取每周、每月、每年第一天和最后一天
热门文章
- linux常用脚本的使用方法,Linux常用命令用法100个
- eclipse检出svn项目后,该文件夹并没有显示绿色
- 从零开始学习Java-Java语言基础(一)
- android 颜色搭配表
- selenium实现12306火车购票网站滑块自动验证登录
- 【读书2】【2014】基于MATLAB的雷达信号处理基础(第二版)——雷达散射截面的统计描述(7)
- 计算机视觉(八):图像分割
- 系统服务器查看snmp,windows7系统打开snmp服务的方法(图文)
- Python3 网易有道词典结合PyInstaller,tkinter制作一个简单的中英文翻译exe文件
- 【六祎 - Java】Oracle官方提供的Java8语言规范;英文版翻译