Flink x Zeppelin ,Hive Streaming 实战解析
行业解决方案、产品招募中!想赚钱就来传!>>> 
Flink 1.11 正式发布已经三周了,其中最吸引我的特性就是 Hive Streaming。正巧 Zeppelin-0.9-preview2 也在前不久发布了,所以就写了一篇 Zeppelin 上的 Flink Hive Streaming 的实战解析。本文主要从以下几部分跟大家分享:
- Hive Streaming 的意义
- Checkpoint & Dependency
- 写入 Kafka
- Hive Streaming Sink
- Hive Streaming Source
- Hive Temporal Table
Hive Streaming 的意义
很多同学可能会好奇,为什么 Flink 1.11 中,Hive Streaming 的地位这么高?它的出现,到底能给我们带来什么?
其实在大数据领域,一直存在两种架构 Lambda 和 Kappa:
- Lambda 架构——流批分离,静态数据通过定时调度同步到 Hive 数仓,实时数据既会同步到 Hive,也会被实时计算引擎消费,这里就引出了一点问题。
- 数据口径问题
- 离线计算产出延时太大
- 数据冗余存储
- Kappa 架构——全部使用实时计算来产出数据,历史数据通过回溯消息的消费位点计算,同样也有很多的问题,毕竟没有一劳永逸的架构。
- 消息中间件无法保留全部历史数据,同样数据都是行式存储,占用空间太大
- 实时计算计算历史数据力不从心
- 无法进行 Ad-Hoc 的分析
为了解决这些问题,行业内推出了实时数仓,解决了大部分痛点,但是还是有些地方力不从心。比如涉及到历史数据的计算怎么办?我想做 Ad-Hoc 的分析又怎么玩?所以行业内现在都是实时数仓与离线数仓并行存在,而这又带来了更多的问题:模型需要多份、数据产出不一致、历史数据的计算等等 。
而 Hive Streaming 的出现就可以解决这些问题!再也不用多套模型了;也不需要同一个指标因为涉及到历史数据,写一遍实时 SQL 再写一遍离线 SQL;Ad-Hoc 也能做了,怎么做?读 Hive Streaming 产出的表就行!
接下来,让我们从参数配置开始,接着流式的写入 Hive,再到流式的读取 Hive 表,最后再 Join 上 Hive 维表吧。这一整套流程都体验后,想必大家对 Hive Streaming 一定会有更深入的了解,更能够体会到它的作用。
Checkpoint & Dependency
因为只有在完成 Checkpoint 之后,文件才会从 In-progress 状态变成 Finish 状态,所以,我们需要合理的去配置 Checkpoint,在 Zeppelin 中配置 Checkpoint 很简单。
%flink.conf# checkpoint 配置pipeline.time-characteristic EventTimeexecution.checkpointing.interval 120000execution.checkpointing.min-pause 60000execution.checkpointing.timeout 60000execution.checkpointing.externalized-checkpoint-retention RETAIN_ON_CANCELLATION# 依赖jar包配置flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.11.0,org.apache.flink:flink-connector-kafka-base_2.11:1.11.0
又因为我们需要从 Kafka 中读取数据,所以将 Kafka 的依赖也加入进去了。
写入Kafka
我们的数据来自于天池数据集,是以 CSV 的格式存在于本地磁盘,所以需要先将他们写入 Kafka。
先建一下 CSV Source 和 Kafka Sink 的表:
%flink.ssqlSET table.sql-dialect=default;DROP TABLE IF EXISTS source_csv;CREATE TABLE source_csv (user_id string,theme_id string,item_id string,leaf_cate_id string,cate_level1_id string,clk_cnt int,reach_time string) WITH ('connector' = 'filesystem','path' = 'file:///Users/dijie/Downloads/Cloud_Theme_Click/theme_click_log.csv','format' = 'csv')
%flink.ssqlSET table.sql-dialect=default;DROP TABLE IF EXISTS kafka_table;CREATE TABLE kafka_table (user_id string,theme_id string,item_id string,leaf_cate_id string,cate_level1_id string,clk_cnt int,reach_time string,ts AS localtimestamp,WATERMARK FOR ts AS ts - INTERVAL '5' SECOND) WITH ('connector' = 'kafka','topic' = 'theme_click_log','properties.bootstrap.servers' = '10.70.98.1:9092','properties.group.id' = 'testGroup','format' = 'json','scan.startup.mode' = 'latest-offset')
因为 注册的表即可以读又可以写,于是我在建表时将 Watermark 加上了;又因为源数据中的时间戳已经很老了,所以我这里采用当前时间减去5秒作为我的 Watermark。
大家可以看到,我在语句一开始指定了 SQL 方言为 Default,这是为啥呢?还有别的方言吗?别急,听我慢慢说。
其实在之前的版本,Flink 就已经可以和 Hive 打通,包括可以把表建在 Hive 上,但是很多语法和 Hive 不兼容,包括建的表在 Hive 中也无法查看,主要原因就是方言不兼容。所以,在 Flink 1.11 中,为了减少学习成本(语法不兼容),可以用 DDL 建 Hive 表并在 Hive 中查询,Flink 支持了方言,默认的就是 Default 了,就和之前一样,如果想建 Hive 表,并支持查询,请使用 Hive 方言,具体可以参考下方链接。
Hive 方言: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/hive_catalog.html
再把数据从 CSV 中读取后写入 Kafka。
%flink.ssql(type=update)insert into kafka_table select * from source_csv ;
再瞄一眼 Kafka,看看数据有没有被灌进去:
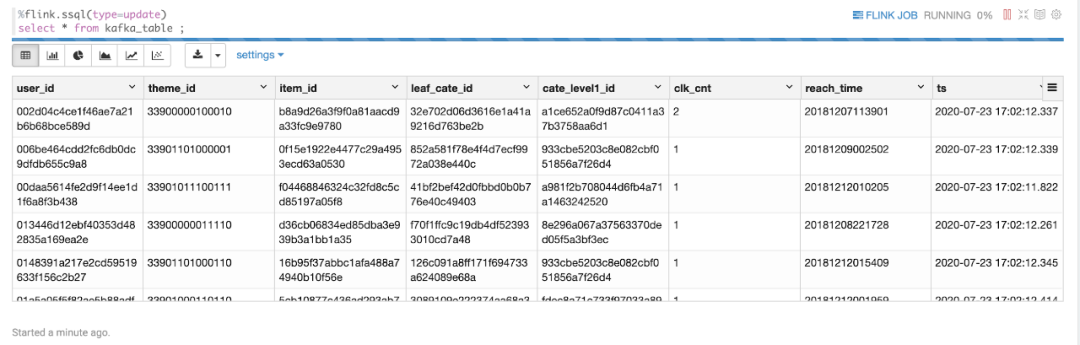
看来没问题,那么接下来让我们写入 Hive。
Hive Streaming Sink
建一个Hive Sink Table,记得将方言切换到 Hive,否则会有问题。
%flink.ssqlSET table.sql-dialect=hive;DROP TABLE IF EXISTS hive_table;CREATE TABLE hive_table (user_id string,theme_id string,item_id string,leaf_cate_id string,cate_level1_id string,clk_cnt int,reach_time string) PARTITIONED BY (dt string, hr string, mi string) STORED AS parquet TBLPROPERTIES ('partition.time-extractor.timestamp-pattern'='$dt $hr:$mi:00','sink.partition-commit.trigger'='partition-time','sink.partition-commit.delay'='1 min','sink.partition-commit.policy.kind'='metastore,success-file');
参数给大家稍微解释一下:
- partition.time-extractor.timestamp-pattern :分区时间抽取器,与 DDL 中的分区字段保持一致;
- sink.partition-commit.trigger :分区触发器类型,可选 process-time 或partition-time。process-time:不需要上面的参数,也不需要水印,当当前时间大于分区创建时间 +sink.partition-commit.delay 中定义的时间,提交分区;partition-time:需要 Source 表中定义 watermark,当 watermark > 提取到的分区时间 +sink.partition-commit.delay 中定义的时间,提交分区;
- sink.partition-commit.delay :相当于延时时间;
- sink.partition-commit.policy.kind :怎么提交,一般提交成功之后,需要通知 metastore,这样 Hive 才能读到你最新分区的数据;如果需要合并小文件,也可以自定义 Class,通过实现 PartitionCommitPolicy 接口。
接下来让我们把数据插入刚刚创建的 Hive Table:
%flink.ssqlinsert into hive_table select user_id,theme_id,item_id,leaf_cate_id,cate_level1_id,clk_cnt,reach_time,DATE_FORMAT(ts, 'yyyy-MM-dd'), DATE_FORMAT(ts, 'HH') ,DATE_FORMAT(ts, 'mm') from kafka_table
让程序再跑一会儿~我们先去倒一杯 95 年的 Java☕️ 。
然后再看看我们的 HDFS,看看路径下的东西。
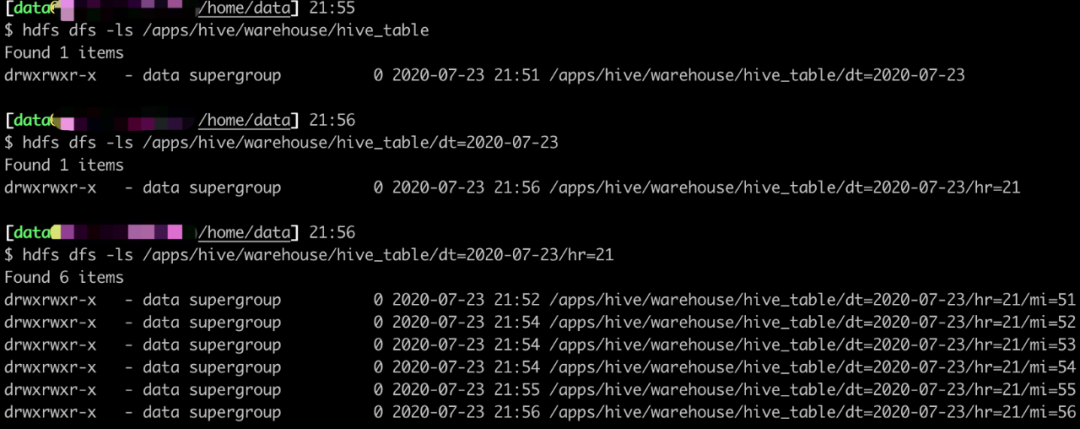
大家也可以用 Hive 自行查询看看,我呢就先卖个关子,一会儿用 Hive Streaming 来读数据。
Hive Streaming Source
因为 Hive 表上面已经创建过了,所以这边读数据的时候直接拿来用就行了,不同的地方是需要使用 Table Hints 去覆盖参数。
Hive Streaming Source 最大的不足是,无法读取已经读取过的分区下新增的文件。简单来说就是,读过的分区,就不会再读了。看似很坑,不过仔细想想,这样才符合流的特性。
照旧给大家说一下参数的意思:
- stream-source.enable :显而易见,表示是否开启流模式。
- stream-source.monitor-interval :监控新文件/分区产生的间隔。
- stream-source.consume-order :可以选 create-time 或者 partition-time;create-time 指的不是分区创建时间,而是在 HDFS 中文件/文件夹的创建时间;partition-time 指的是分区的时间;对于非分区表,只能用 create-time。官网这边的介绍写的有点模糊,会让人误以为可以查到已经读过的分区下新增的文件,其实经过我的测试和翻看源码发现并不能。
- stream-source.consume-start-offset :表示从哪个分区开始读。
光说不干假把式,让我们捞一把数据看看~
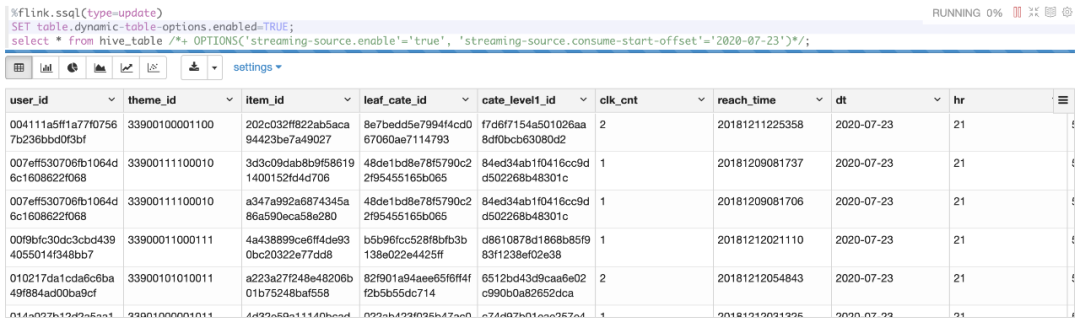
SET 那一行得带着,不然无法使用 Table Hints。
Hive Temporal Table
看完了 Streaming Source 和 Streaming Sink,让我们最后再试一下 Hive 作为维表吧。
其实用 Hive 维表很简单,只要是在 Hive 中存在的表,都可以当做维表使用,参数完全可以用 Table Hints 来覆盖。
- lookup.join.cache.ttl :表示缓存时间;这里值得注意的是,因为 Hive 维表会把维表所有数据缓存在 TM 的内存中,如果维表量很大,那么很容易就 OOM;如果 ttl 时间太短,那么会频繁的加载数据,性能会有很大影响。

因为是 LEFT JOIN,所以维表中不存在的数据会以 NULL 补全。
再看一眼 DAG 图:

大家看一下画框的地方,能看到这边是使用的维表关联 LookupJoin。 如果大家 SQL 语句写错了,丢了 for system_time as of a.p,那么 DAG 图就会变成这样:
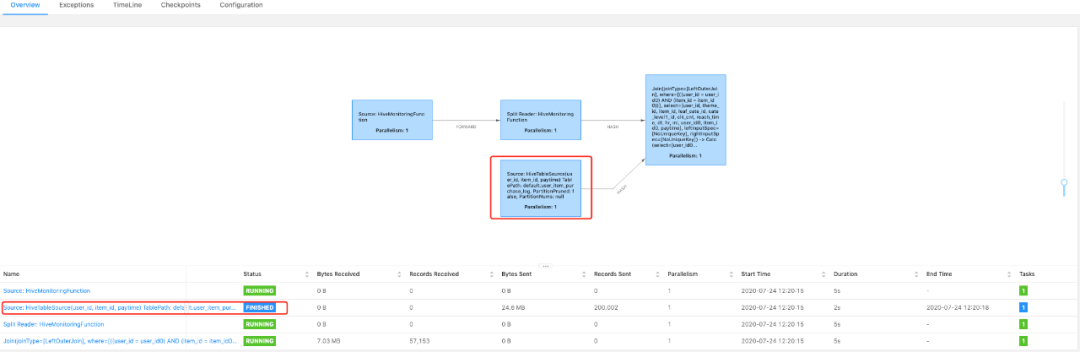
这种就不是维表 JOIN 其实更像是流和批在 JOIN。
写在最后
Hive Streaming 的完善意味着打通了流批一体的最后一道壁垒,既可以做到历史数据的 OLAP 分析,又可以实时吐出结果,这无疑是 ETL 开发者的福音,想必接下来的日子,会有更多的企业完成他们实时数仓的建设。
参考文档:
[1]https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/ [2]https://github.com/apache/zeppelin/blob/master/docs/interpreter/flink.md
Note 下载:
https://github.com/lonelyGhostisdog/flinksql/blob/master/src/main/resources/Flink%20on%20Zeppelin/Hive%20Streaming%20Test.zpln
最后,给大家介绍一下 Flink on Zeppelin 的钉钉群,大家有问题可以在里面讨论,Apache Zeppelin PMC 简锋大佬也在里面,有问题可以直接在钉群中提问交流~

作者介绍:
狄杰,蘑菇街资深数据专家,负责蘑菇街实时计算平台 。目前 Focus 在 Flink on Zeppelin,Apache Zeppelin Contributor。
专注大数据技术、架构、实战
关注我,带你不同角度看数据架构

本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Flink x Zeppelin ,Hive Streaming 实战解析相关推荐
- Flink on Zeppelin 系列之:Yarn Application 模式支持
简介:Zeppelin 如何实现并使用 Yarn Application 模式. 作者:章剑锋(简锋) 去年 Flink Forward 在讲 Flink on Zeppelin 这个项目的未来时我们 ...
- 重磅!《Apache Flink 十大技术难点实战》发布
简介:总结生产环境十大常见难点,10篇技术实战文章帮你完成故障识别.问题定位.性能优化等全链路过程,实现从基础概念的准确理解到上手实操的精准熟练,从容应对生产环境中的技术难题! <Apache ...
- Flink on Zeppelin (4) - 机器学习篇
今天我来讲下如何在 Zeppelin 里做机器学习.机器学习的重要性我就不多说了,我们直奔主题. Flink 在机器学习这个领域发力较晚,社区版没有一个完整的机器学习算法库可以用,Alink[1]是目 ...
- 重磅福利!《Apache Flink 十大技术难点实战》发布,帮你从容应对生产环境中的技术难题...
精选30+云产品,助力企业轻松上云!>>> 简介: 总结生产环境十大常见难点,10篇技术实战文章帮你完成故障识别.问题定位.性能优化等全链路过程,实现从基础概念的准确理解到上手实操的 ...
- flink sql 知其所以然(八):flink sql tumble window 的奇妙解析之路
感谢您的小爱心(关注 + 点赞 + 再看),对博主的肯定,会督促博主持续的输出更多的优质实战内容!!! 1.序篇-本文结构 大数据羊说 用数据提升美好事物发生的概率~ 34篇原创内容 公众号 源码 ...
- Flink on zeppelin第五弹设置checkpoint
概述 Flink的exactly-once语义实现是需要依赖checkpoint的,对于一个有状态的Flink任务来说如果想要在任务发生failover,或者手动重启任务的时候任务的状态不丢失是必须要 ...
- 性能提升约 7 倍!Apache Flink 与 Apache Hive 的集成
导读:随着 Flink 在流式计算的应用场景逐渐成熟和流行,如果 Flink 能同时把批量计算的应用场景处理好,就能减少用户在使用 Flink 时开发和维护的成本,并且能够丰富 Flink 的生态.S ...
- 性能提升约7倍!Apache Flink 与 Apache Hive 的集成
导读:随着 Flink 在流式计算的应用场景逐渐成熟和流行,如果 Flink 能同时把批量计算的应用场景处理好,就能减少用户在使用 Flink 时开发和维护的成本,并且能够丰富 Flink 的生态.S ...
- Radware负载均衡项目配置实战解析之四-VRRP双机配置与同步
接上一小节内容,这一节主要介绍RADWARE负载均衡实战项目中的VRRP双机配置与同步问题.radware在实际的业务与配置中,一般都会配置双机来实现冗余.无论是主用设备还是备用设备都要进行基本配置. ...
最新文章
- 一份C++学习资源整理,咬牙切齿地好用。
- 为什么磁盘存储引擎用 b+树来作为索引结构?
- php 怎么循环数组取有值的,php怎么循环数组取有值的-PHP问题
- appium启动APP配置参数:
- 论文中的MS流程01
- php奖学金系统,java/php/net/pythont奖助学金管理系统设计
- 数据分析案例——航空公司客户价值分析
- 一年时间,拿到了人生中的第一个20万
- 寒武纪 android实习
- 理想中2.5D的网络拓扑图
- Easyexcel 获取表格具体位置的内容
- CoreData多线程安全
- delete、truncate 、Drop删除表的区别
- matlab读取jra55数据,[转载][原创]灰色关联分析及Matlab程序实现
- 金牛来到,福气来到——TcaplusDB新年放送
- 设银行1年期定期存款年利率c语言,4.计算定期存款本利之和设银行定期存款的年......
- TP5 短信宝 发送短信验证码
- Go实现 Bit 数组(集合)
- 【笔记】《计算机网络系统方法》(by Larry L.Peterson)第二章 开始连接
- MySQL的函数和约束