分类变量要编码成哑变量_停止对分类变量进行热编码
分类变量要编码成哑变量
重点 (Top highlight)
One-hot encoding, otherwise known as dummy variables, is a method of converting categorical variables into several binary columns, where a 1 indicates the presence of that row belonging to that category.
单热编码(也称为伪变量)是一种将分类变量转换为几个二进制列的方法,其中1表示存在属于该类别的该行。

It is, pretty obviously, not a great a choice for the encoding of categorical variables from a machine learning perspective.
从机器学习的角度来看,对于分类变量的编码显然不是一个很好的选择。
Most apparent is the heavy amount of dimensionality it adds, and it is common knowledge that generally a lower amount of dimensions is better. For example, if we were to have a column representing a US state (e.g. California, New York), a one-hot encoding scheme would result in fifty additional dimensions.
最明显的是它添加了大量的尺寸,并且众所周知,通常尺寸越小越好。 例如,如果我们要有一个代表美国州(例如加利福尼亚州,纽约州)的列,那么一键式编码方案将导致另外五十个维度。
Not only does it add a massive number of dimensions to the dataset, there really isn’t much information — ones occasionally dotting a sea of zeroes. This results in an exceptionally sparse landscape, which makes it hard to grapple with optimization. This is especially true with neural networks, whose optimizers have enough trouble navigating the error space without dozens of empty dimensions.
它不仅增加了数据集的数量,而且实际上没有太多信息-偶尔会散布零乱的信息。 这导致异常稀疏的景观,这使得难以进行优化。 对于神经网络来说尤其如此,因为神经网络的优化器在导航错误空间时会遇到很多麻烦,而没有很多空白。
Worse, each of the information-sparse columns have a linear relationship with each other. This means that one variable can be easily predicted using the others, can causes problems of parallelism and multicollinearity in high dimensions.
更糟糕的是,每个信息稀疏列之间都具有线性关系。 这意味着一个变量可以容易地使用其他变量进行预测,并可能在高维中引起并行性和多重共线性问题。

The optimal dataset consists of features whose information is independently valuable, and one-hot encoding creates an environment of anything but that.
最佳数据集包含特征,这些特征的信息具有独立的价值,并且一键编码可创建除此以外的任何环境。
Granted, if there are only three or perhaps even four classes, one-hot encoding may not be that bad a choice, but chances are it’s worth exploring the alternatives, depending on the relative size of the dataset.
当然,如果只有三个或什至四个类,那么一键编码可能不是一个糟糕的选择,但是根据数据集的相对大小,有机会探索替代方法是值得的。
Target encoding is a very effective way to represent a categorical column and only takes up the space of one feature. Also known as mean encoding, each value in the column is replaced with the mean target value for that category. This allows for a more direct representation of the relationship between the categorical variable and the target variable, and is a tremendously popular technique (especially on Kaggle competitions).
目标编码 是表示分类列的一种非常有效的方法,仅占用一个要素的空间。 也称为均值编码,该列中的每个值都被该类别的平均目标值代替。 这可以更直接地表示类别变量和目标变量之间的关系,并且是一种非常流行的技术(尤其是在Kaggle比赛中)。
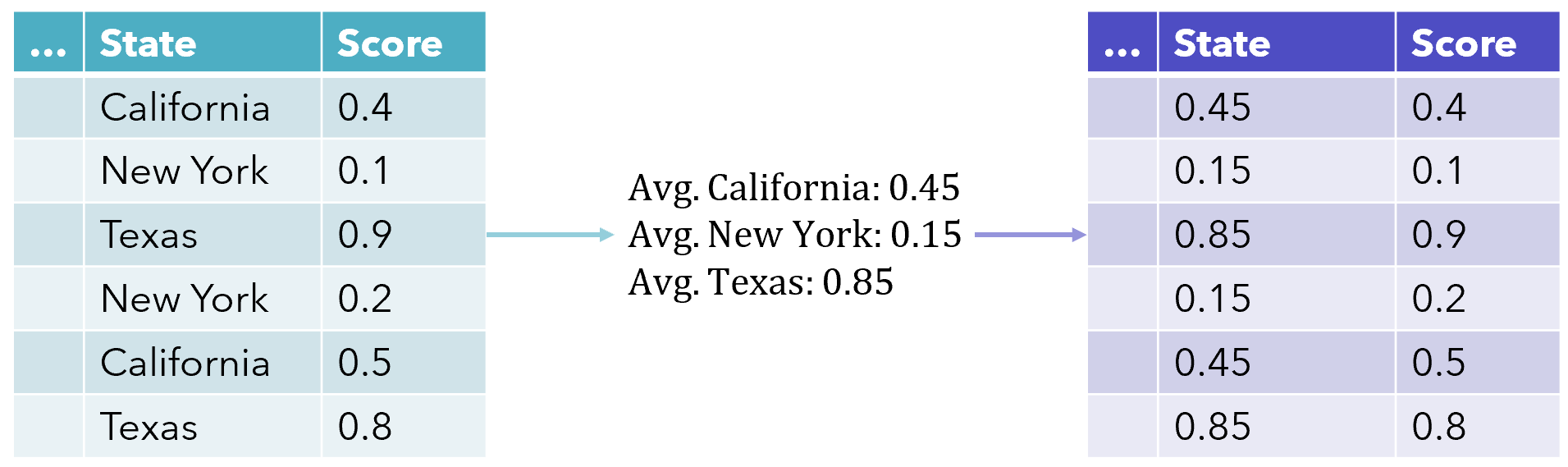
This method of encoding has some downsides. For one, it makes it more difficult for the model to learn relationships between a mean-encoded variable and another variable, It draws similarity in a column based only on its relationship with the target, which may either be a pro or a con.
这种编码方法有一些缺点。 首先,它使模型更难于学习均值编码变量和另一个变量之间的关系。仅根据列与目标的关系(可能是赞成或反对),在列中绘制相似性。
Primarily, however, this method of encoding can be very sensitive to the y-variable, which affects the model’s ability to extract the encoded information.
但是,首先,这种编码方法可能对y变量非常敏感,这会影响模型提取编码信息的能力。
Since every one of the category’s values is replaced with the same numerical value, the model may tend to overfit to the encoded values it has seen (e.g. associating 0.8 with something entirely different than 0.79). This is an effect of treating values on a continuous scale as heavily repeated classes.
由于类别的每个值都被相同的数值替换,因此该模型可能趋于过度拟合其已看到的编码值(例如,将0.8与完全不同于0.79的值相关联)。 这是将连续规模上的值视为严重重复的类的效果。
Hence, the y-variable needs to be carefully monitored for things like outliers.
因此,需要仔细监视y变量是否存在异常值。
To implement this, use the category_encoders library. Since the target encoder is a supervised method, it requires both X and y training sets.
要实现此目的,请使用category_encoders库。 由于目标编码器是一种监督方法,因此它需要X和y训练集。
from category_encoders import TargetEncoder
enc = TargetEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)Leave-one-out encoding attempts to remedy such a reliance on the y-variable and more diversity in terms of value by calculating the average, excluding the current row value. This levels off the effect of outliers and creates more diverse encoded values.
留一法编码试图通过计算平均值(不包括当前行值)来弥补对y变量的依赖,以及在值方面的更多多样性。 这使异常值的影响趋于平稳,并创建了更多不同的编码值。

Since the model is exposed to not only the same value for each encoded class but a range, it learns to better generalize.
由于模型不仅为每个编码的类提供了相同的值,还为范围提供了一个值,因此可以更好地进行概括。
Implementation can be performed, as usual, in the category_encoders library, using the LeaveOneOutEncoder.
可以像往常一样,使用LeaveOneOutEncoder在category_encoders库中执行LeaveOneOutEncoder 。
from category_encoders import LeaveOneOutEncoder
enc = LeaveOneOutEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)Another strategy towards achieving a similar effect is adding normally distributed noise to the encoded scores, where the standard deviation is a parameter that can be tuned.
实现类似效果的另一种策略是将正态分布的噪声添加到编码分数中,其中标准偏差是可以调整的参数。
Bayesian Target Encoding is a more mathematically involved approach towards using the target as an encoding method. Using only the mean can be a deceiving metric, so Bayesian target encoding seeks to incorporate other statistical measures of the target variable’s distribution, such as its variance or its skewness — referred to as ‘higher moments’.
贝叶斯目标编码是一种将目标用作编码方法的数学方法。 仅使用均值可能是一种欺骗性度量,因此贝叶斯目标编码试图合并目标变量分布的其他统计度量,例如其方差或偏度(称为“较高矩”)。
These attributes of the distribution are then incorporated through a Bayesian model, which is able to produce an encoding that is more aware of various aspects of the category’s target distribution. The result, however, is less interpretable.
然后,通过贝叶斯模型合并这些分布的属性,该模型能够产生一种更了解类别目标分布的各个方面的编码。 但是,结果难以解释。
Weight of Evidence is another nuanced view towards the relationship between a categorical independent variable and a dependent variable. WoE evolved from the credit scoring world, and was used to measure the separation between customers who defaulted or paid back on a loan. The mathematical definition of Weight of Evidence is the natural log of the odds ratio, or:
证据权重是对分类自变量和因变量之间关系的另一种细微看法。 WoE源自信用评分世界,用于衡量拖欠或偿还贷款的客户之间的距离。 证据权重的数学定义是优势比的自然对数,或:
ln (% of non events / % of events)The higher the WoE, the more likely an event will occur. ‘Non-events’ would be the percent of those not in a certain class. Using Weight of Evidence establishes a monotonic (never stops going in one direction) relationship with the dependent variable and secures categories on a logistic scale, natural for logistic regression. WoE is a key component in another metric, Information Value, which measures how information a feature provides for prediction.
WoE越高,事件发生的可能性就越大。 “非事件”是指不在某个类别中的人所占的百分比。 使用证据权重与因变量建立单调(永不停止朝一个方向发展)关系,并在逻辑对数范围内确保类别,这对于逻辑回归很自然。 WoE是另一个指标“信息价值”的关键组成部分,该指标衡量功能如何为预测提供信息。
from category_encoders import WOEEncoder
enc = WOEEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)These methods are supervised encoders, or methods of encoding that consider the target variable and hence are usually more effective encoders in the task of prediction. However, this is not necessarily the case when unsupervised analysis needs to be performed.
这些方法是监督编码器,或者是考虑目标变量的编码方法,因此在预测任务中通常是更有效的编码器。 但是,当需要执行无监督分析时,并不一定是这种情况。
Nonlinear PCA is a method of approaching PCA that can handle categorical variables by using categorical quantization. This finds the best numerical values for categories such that the performance (explained variance) of the regular PCA is maximized. Read more about it here:
非线性PCA是一种接近PCA的方法,可以通过使用分类量化来处理分类变量。 这样可以找到类别的最佳数值,从而使常规PCA的性能(解释的方差)最大化。 在这里关于它的信息:
Explore several other encoding alternatives in the category_encoders documentation here.
在这里的category_encoders文档中探索其他几种编码替代方法。
Thanks for reading!
谢谢阅读!
All images created by author.
作者创作的所有图像。
翻译自: https://towardsdatascience.com/stop-one-hot-encoding-your-categorical-variables-bbb0fba89809
分类变量要编码成哑变量
http://www.taodudu.cc/news/show-4514335.html
相关文章:
- Elasticsearch7.6(windows版单机版)api使用及JD搜索高亮显示
- WEB 前端面试题 (高能)
- 计算机网络————Wireshark 实验
- MongoDB——数据类型详解
- 关于计算机固态硬盘正确的是,SSD的不正确使用说明,建议你们不要打开
- ghost系统之家Ghost XP SP3加强版V8.0_2010.4[NTFS版]
- 【安全知识】——常见杀软对应进程名
- 网络协议-TCP
- icmp回复报文_如果目标主机阻塞了,ICMP回显请求报文,我们可以
- 八招教你解决网络故障!
- 金山发布毒霸V及网镖V新品 坚持高定价策略
- 总是封群怎么解决_我的群被封了怎么办
- 顶一下金山公司
- 金山发布毒霸V及网镖V新品 坚持高定价策略 (转)
- 求可以统计网络流量的VC代码,就象是金山网镖下面的那样
- 金山毒霸6 、金山网镖6 增强版 发布在即!!!
- TCP标志位
- 考试三级网络技术笔试
- 一个人的思想:漫谈技术社区
- 个人作业2:APP案例分析
- IT168 CIO频道11月28日至12月01日文章精选
- 五款音乐小程序,安抚你度过颓废的时光
- 音乐app用户推荐系统构建_一款专门给用户推荐动听音乐的音乐期刊类的应用。画面极简优美...
- android好玩界面,哪些好玩的APP富有好看界面?推荐一波设计独到的APP
- 记一下网络电台收集网址
- 小众音乐电台推荐
- 使用python抓取落网期刊图片
- 开发落网电台windows phone 8应用的计划(3)
- 开发落网电台windows phone 8应用的计划(4)
- 开发落网电台windows phone 8应用的计划(5)
分类变量要编码成哑变量_停止对分类变量进行热编码相关推荐
- 三、数据预处理——处理分类型数据:编码与哑变量
三.处理分类型特征:编码与哑变量 点击标题即可获取文章相关的源代码文件哟! 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn ...
- 数据预处理和特征工程2-缺失值处理、分类型特征:编码与哑变量
缺失值处理 import pandas as pd data = pd.read_csv(r"E:\机器学习\sklearn学习\数据\Narrativedata.csv",ind ...
- 连续数值变量的离散化、哑变量
#还是Age字段,一般连续数据要做离散化 #某些分类数据,为了可以更好的使用,可以转换为哑变量使用 ##连续数据离散化的好处: #1)有些算法的输入要求必须是离散化的数据,如贝叶斯和树模型 #2)离散 ...
- 自变量是分类变量的线性拟合+哑变量
哑变量 dummy variable(也相当于对数据分类) 何时引入哑变量 顺序变量如(高,中,低)可按比例引入值(如1,3,5) 而分类变量,或连续变量的划分:(如:1-10,11-20,21-30 ...
- python 独热码_数据预处理:独热编码(One-Hot Encoding)
问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male", "female"] ["from ...
- python编码解码的过程_使用Python过程中的编码和解码
编码和解码的问题纠结了我很久了,对他一直只有是是而非的理解,好像是那么回事,但是又不懂,今天终于来认真解决一下这个问题,总结一下大神们的回答,做一下笔记. 首先,我们知道,计算机中的所有数据都以二进制 ...
- 南邮哈夫曼编码c语言代码_漫画:“哈夫曼编码” 是什么鬼?
在上一期,我们介绍了一种特殊的数据结构 "哈夫曼树",也被称为最优二叉树.没看过的小伙伴可以点击下方链接: 漫画:什么是 "哈夫曼树" ? 那么,这种数据结构 ...
- 哑变量(Dummy Variable)、独热编码(one-hot Encoding)、label-encoding归纳
1 概念 1.1 定类型变量 定类类型就是纯分类,不排序,没有逻辑关系. 当某特征具有k个属性值,那么: a 哑变量(虚拟变量)-- 具有k-1个二进制特征,基准类别将被忽略,若基准类别选择不合理,仍 ...
- Python超实用小技巧:分类变量转化为哑变量(附哑变量详解)
代码示例 features = ["Pclass", "Sex", "SibSp", "Parch"]# 筛选出分类变量 ...
最新文章
- Cissp-【第4章 通信与网络安全】-2021-3-14(543页-560页)
- NKOJ 1791 Party at Hali-Bula(树状DP)
- 第二章 java常用开发工具以及程序的编写
- visio的字体复制到word_学会这6个常用Word技巧,文档做起来又快又好看,办公如有神助...
- 用Navicat_SSH 连接数据库服务器
- VS2019-C++警告-C6385读取数据无效
- 最低什么样的学历,才可以选择转行web前端?
- CSS 7阶层叠水平
- 汇编指令大全(带注释)
- 产品初探(一):面试经验记录
- PhotoDraweeView for Fresco
- Firefox 地址栏的“手气不错”
- 与其去雄安买房,不如找中企动力建自己的平台
- 使用Busybox制作根文件系统
- 设置常量 java_Java——常量与变量-java变量设置
- (绝对防御勒索病毒)装机员 ghost win7 Sp1 64位纯净6月版
- PageRank算法和HITS算法
- 12星座的出生年月日性格_十二个星座的出生年月日
- 新手上路,如何迅速搭建一套源码系统
- 你用 Python 做过什么有趣的数据挖掘项目?
热门文章
- Servlet中关于Session数据存储遇到的数据转换问题
- java中数据类型的等级_Java 数据类型、变量
- 分布式事务的BASE理论
- 20 21九死一生、22上半年读20本书(含15本管理书单/笔记):继续百年征程
- 结对编程实况录像-2022北航软工
- Schema being registered is incompatible with an earlier schema
- 华为云早报 谷歌亚马逊抢食美军100亿美元云计划
- 【MindSpore,ModelArts】华为云ModelArts简明教程 | 图文
- 王者荣耀改名神器助手微信小程序
- 「 论文投稿 」《IEEE Robotics and Automation Letters》与ICRA会议,录用经历