SparkSession
翻译自:How to use SparkSession in Apache Spark 2.0
转载自:
- SparkSession简单介绍 (是否为原创初始翻译不详)
- Spark 2.0系列之SparkSession详解 (最后三节)
向原文作者以及原创翻译者的辛勤劳动致敬!
前言
Apache Spark 2.0引入了SparkSession,为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。
本文将介绍在Spark 2.0中如何使用SparkSession。
探索SparkSession统一的功能
首先,我们介绍一个简单的Spark应用案例:SparkSessionZipsExample,其从JSON文件中读取邮政编码,并且通过DataFrame API进行一些分析,之后使用Spark SQL进行一些查询,这些操作并没有使用到SparkContext, SQLContext 或者HiveContext。
创建SparkSession
在2.0版本之前,与Spark交互之前必须先创建SparkConf和SparkContext,代码如下:
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc) 然而在Spark 2.0中,我们可以通过SparkSession来实现同样的功能,而不需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。使用生成器的设计模式(builder design pattern),如果我们没有创建SparkSession对象,则会实例化出一个新的SparkSession对象及其相关的上下文。
// Create a SparkSession. No need to create SparkContext
// You automatically get it as part of the SparkSession
val warehouseLocation = "file:${system:user.dir}/spark-warehouse"
val spark = SparkSession .builder() .appName("SparkSessionZipsExample") .config("spark.sql.warehouse.dir", warehouseLocation) .enableHiveSupport() .getOrCreate() 到现在我们可以使用上面创建好的spark对象,并且访问其public方法。
配置Spark运行相关属性
一旦我们创建好了SparkSession,我们就可以配置Spark运行相关属性。比如下面代码片段我们修改了已经存在的运行配置选项。
//set new runtime options
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//get all settings
val configMap:Map[String, String] = spark.conf.getAll() 获取Catalog元数据
通常我们想访问当前系统的Catalog元数据。SparkSession提供了catalog实例来操作metastore。这些方法放回的都是Dataset类型的,所有我们可以使用Dataset相关的API来访问其中的数据。如下代码片段,我们展示了所有的表并且列出当前所有的数据库:
//fetch metadata data from the catalog
scala> spark.catalog.listDatabases.show(false)
+--------------+---------------------+--------------------------------------------------------+
|name |description |locationUri |
+--------------+---------------------+--------------------------------------------------------+
|default |Default Hive database|hdfs://iteblogcluster/user/iteblog/hive/warehouse |
+--------------+---------------------+--------------------------------------------------------+ scala> spark.catalog.listTables.show(false)
+----------------------------------------+--------+-----------+---------+-----------+
|name |database|description|tableType|isTemporary|
+----------------------------------------+--------+-----------+---------+-----------+
|iteblog |default |null |MANAGED |false |
|table2 |default |null |EXTERNAL |false |
|test |default |null |MANAGED |false |
+----------------------------------------+--------+-----------+---------+-----------+ 创建Dataset和Dataframe
使用SparkSession APIs创建 DataFrames 和 Datasets的方法有很多,其中最简单的方式就是使用spark.range方法来创建一个Dataset。当我们学习如何操作Dataset API的时候,这个方法非常有用。操作如下:
scala> val numDS = spark.range(5, 100, 5)
numDS: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> numDS.orderBy(desc("id")).show(5)
+---+
| id|
+---+
| 95|
| 90|
| 85|
| 80|
| 75|
+---+
only showing top 5 rows scala> numDS.describe().show()
+-------+------------------+
|summary| id|
+-------+------------------+
| count| 19|
| mean| 50.0|
| stddev|28.136571693556885|
| min| 5|
| max| 95|
+-------+------------------+
scala> val langPercentDF = spark.createDataFrame(List(("Scala", 35), | ("Python", 30), ("R", 15), ("Java", 20)))
langPercentDF: org.apache.spark.sql.DataFrame = [_1: string, _2: int] scala> val lpDF = langPercentDF.withColumnRenamed("_1", "language").withColumnRenamed("_2", "percent")
lpDF: org.apache.spark.sql.DataFrame = [language: string, percent: int] scala> lpDF.orderBy(desc("percent")).show(false)
+--------+-------+
|language|percent|
+--------+-------+
|Scala |35 |
|Python |30 |
|Java |20 |
|R |15 |
+--------+-------+ 使用SparkSession读取CSV
创建完SparkSession之后,我们就可以使用它来读取数据,下面代码片段是使用SparkSession来从csv文件中读取数据:
val df = sparkSession.read.option("header","true"). csv("src/main/resources/sales.csv") 上面代码非常像使用SQLContext来读取数据,我们现在可以使用SparkSession来替代之前使用SQLContext编写的代码。下面是完整的代码片段:
package com.iteblog import org.apache.spark.sql.SparkSession /** * Spark Session example * */
object SparkSessionExample { def main(args: Array[String]) { val sparkSession = SparkSession.builder. master("local") .appName("spark session example") .getOrCreate() val df = sparkSession.read.option("header","true").csv("src/main/resources/sales.csv") df.show() } } 使用SparkSession API读取JSON数据
我们可以使用SparkSession来读取JSON、CVS或者TXT文件,甚至是读取parquet表。比如在下面代码片段里面,我将读取邮编数据的JSON文件,并且返回DataFrame对象:
// read the json file and create the dataframe
scala> val jsonFile = "/user/iteblog.json"
jsonFile: String = /user/iteblog.json
scala> val zipsDF = spark.read.json(jsonFile)
zipsDF: org.apache.spark.sql.DataFrame = [_id: string, city: string ... 3 more fields] scala> zipsDF.filter(zipsDF.col("pop") > 40000).show(10, false)
+-----+----------+-----------------------+-----+-----+
|_id |city |loc |pop |state|
+-----+----------+-----------------------+-----+-----+
|01040|HOLYOKE |[-72.626193, 42.202007]|43704|MA |
|01085|MONTGOMERY|[-72.754318, 42.129484]|40117|MA |
|01201|PITTSFIELD|[-73.247088, 42.453086]|50655|MA |
|01420|FITCHBURG |[-71.803133, 42.579563]|41194|MA |
|01701|FRAMINGHAM|[-71.425486, 42.300665]|65046|MA |
|01841|LAWRENCE |[-71.166997, 42.711545]|45555|MA |
|01902|LYNN |[-70.941989, 42.469814]|41625|MA |
|01960|PEABODY |[-70.961194, 42.532579]|47685|MA |
|02124|DORCHESTER|[-71.072898, 42.287984]|48560|MA |
|02146|BROOKLINE |[-71.128917, 42.339158]|56614|MA |
+-----+----------+-----------------------+-----+-----+
only showing top 10 rows 在SparkSession中还用Spark SQL
通过SparkSession我们可以访问Spark SQL中所有函数,正如你使用SQLContext访问一样。下面代码片段中,我们创建了一个表,并在其中使用SQL查询:
// Now create an SQL table and issue SQL queries against it without
// using the sqlContext but through the SparkSession object.
// Creates a temporary view of the DataFrame
scala> zipsDF.createOrReplaceTempView("zips_table") scala> zipsDF.cache()
res3: zipsDF.type = [_id: string, city: string ... 3 more fields] scala> val resultsDF = spark.sql("SELECT city, pop, state, _id FROM zips_table")
resultsDF: org.apache.spark.sql.DataFrame = [city: string, pop: bigint ... 2 more fields] scala> resultsDF.show(10)
+------------+-----+-----+-----+
| city| pop|state| _id|
+------------+-----+-----+-----+
| AGAWAM|15338| MA|01001|
| CUSHMAN|36963| MA|01002|
| BARRE| 4546| MA|01005|
| BELCHERTOWN|10579| MA|01007|
| BLANDFORD| 1240| MA|01008|
| BRIMFIELD| 3706| MA|01010|
| CHESTER| 1688| MA|01011|
|CHESTERFIELD| 177| MA|01012|
| CHICOPEE|23396| MA|01013|
| CHICOPEE|31495| MA|01020|
+------------+-----+-----+-----+
only showing top 10 rows 使用SparkSession读写Hive表
下面我们将使用SparkSession创建一个Hive表,并且对这个表进行一些SQL查询,正如你使用HiveContext一样:
scala> spark.sql("DROP TABLE IF EXISTS iteblog_hive")
res5: org.apache.spark.sql.DataFrame = [] scala> spark.table("zips_table").write.saveAsTable("iteblog_hive")
16/08/24 21:52:59 WARN HiveMetaStore: Location: hdfs://iteblogcluster/user/iteblog/hive/warehouse/iteblog_hive specified for non-external table:iteblog_hive scala> val resultsHiveDF = spark.sql("SELECT city, pop, state, _id FROM iteblog_hive WHERE pop > 40000")
resultsHiveDF: org.apache.spark.sql.DataFrame = [city: string, pop: bigint ... 2 more fields] scala> resultsHiveDF.show(10)
+----------+-----+-----+-----+
| city| pop|state| _id|
+----------+-----+-----+-----+
| HOLYOKE|43704| MA|01040|
|MONTGOMERY|40117| MA|01085|
|PITTSFIELD|50655| MA|01201|
| FITCHBURG|41194| MA|01420|
|FRAMINGHAM|65046| MA|01701|
| LAWRENCE|45555| MA|01841|
| LYNN|41625| MA|01902|
| PEABODY|47685| MA|01960|
|DORCHESTER|48560| MA|02124|
| BROOKLINE|56614| MA|02146|
+----------+-----+-----+-----+
only showing top 10 rows 正如你所见,你使用DataFrame API, Spark SQL 以及 Hive查询的结果都一样。关于这个例子的完整代码可以到这里获取。
Spark REPL和Databricks Notebook中的SparkSession对象
在之前的Spark版本中,Spark shell会自动创建一个SparkContext对象sc。2.0中Spark shell则会自动创建一个SparkSession对象(spark),在输入spark时就会发现它已经存在了。
在Databricks notebook中创建集群时也会自动生成一个SparkSession,这里用的名字也是spark。
SparkSession和SparkContext
下图说明了SparkContext在Spark中的主要功能。
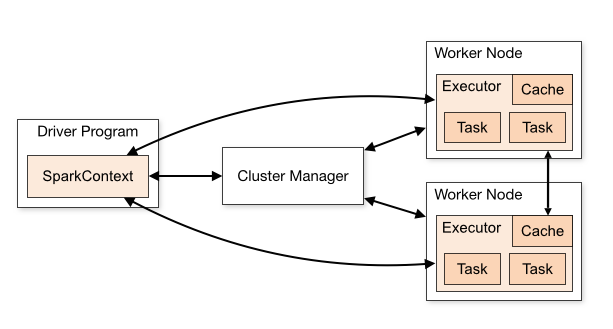
从图中可以看到SparkContext起到的是一个中介的作用,通过它来使用Spark其他的功能。每一个JVM都有一个对应的SparkContext,driver program通过SparkContext连接到集群管理器来实现对集群中任务的控制。Spark配置参数的设置以及对SQLContext、HiveContext和StreamingContext的控制也要通过SparkContext进行。
不过在Spark2.0中上述的一切功能都是通过SparkSession来完成的,同时SparkSession也简化了DataFrame/Dataset API的使用和对数据的操作。
小结
本文通过一个简单的例子演示了SparkSession的使用方法并与Spark2.0之前版本中的SparkContext进行了对比。总而言之SparkSession是既容易学又方便用。
SparkSession相关推荐
- 客快物流大数据项目(五十六): 编写SparkSession对象工具类
编写SparkSession对象工具类 后续业务开发过程中,每个子业务(kudu.es.clickhouse等等)都会创建SparkSession对象,以及初始化开发环境,因此将环境初始化操作封装成工 ...
- 【spark】SparkSession的API
SparkSession是一个比较重要的类,它的功能的实现,肯定包含比较多的函数,这里介绍下它包含哪些函数. builder函数 public static SparkSession.Builder ...
- Spark SQL 之SparkSession
SparkSession是Spark2.x中推荐使用的Spark SQL的入口点. 代码如下: package cn.ac.iie.sparkimport org.apache.spark.sql.S ...
- 关于SQLContext过期,SparkSession登场
关于SQLContext过期问题. 源码中解释道: spark2.0之后使用sparksession替代,不过仍然保留了SQLContext. 那么他们两个有不同吗?这里只说一个重要的.在你使用Spa ...
- Spark基本操作SparkSession,DatasetRow,JavaRDDRow
一.Spark创建 1.创建SparkSession /** * local[*]表示使用本机的所有处理器创建工作节点 * spark.driver.memory spark的驱动器内存 * Spar ...
- SparkContext、SparkConf和SparkSession的初始化
SparkContext 和 SparkConf 任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spar ...
- error: not found: value SparkSession
报错如下 : error: not found: value SparkSession 解决方案: import org.apache.spark.sql.SparkSession
- sparkSession常见参数设置
def getSparkSession(sparkConf:SparkConf):SparkSession = {val sparkSession: SparkSession = SparkSessi ...
- Unable to instantiate SparkSession with Hive support because Hive classes are not found
文章目录 1.美图 2.背景 1.美图 2.背景 Exception in thread "main" java.lang.IllegalArgumentException: Un ...
- spark学习-55-源代码:SparkSession的的创建
1.概述 1.首先我们在自己的程序中创建SparkSession spark= SparkSession.builder() .appName("lcc_java_habase_local& ...
最新文章
- golang中的strings.LastIndexAny
- 介绍一个JSONP 跨域访问代理API-yahooapis
- OpenGl 绘制一个立方体
- 系统安装,重装与优化:chapter1 安装操作系统前的准备
- SecureCRT文件传输
- fxml设置背景_JavaFX – 如何获取Tab,Button等的背景颜色
- JS 基础知识点及常考面试题(一)
- 乐玩自动化测试模块_五大测试框架介绍,附带全套黑马自动化测试视频教程(完结)...
- python 调用rpc服务_在Django项目中对Python函数进行RPC调用的优雅方式
- iSPRINT:Google 最高能的创新加速课程,清华老师都来给点赞!
- 机场精细化管理_全国首家!西安咸阳国际机场通过民航局安全管理体系专项审核...
- 学术 | 如何写一篇学术论文?(下)
- python读取cad_SmartSoft中用C#.Net实现AutoCAD块属性提取|python基础教程|python入门|python教程...
- linux多线程实验实验报告,Linux多线程实验.ppt
- SM2算法和RSA算法简介
- 蓝桥杯:座次问题(枚举法 回溯) java
- 哈希表查找 的 平均长度
- C++中string类下的begin,end,rbegin,rend的用法
- 几款.Net加密/加壳工具的比较
- origin修复中_win10系统中Origin Access出错如何修复