梦见妈妈_梦见文字!
梦见妈妈
“DeepDream is an experiment that visualizes the patterns learned by a neural network. Similar to when a child watches clouds and tries to interpret random shapes, DeepDream over-interprets and enhances the patterns it sees in an image.
“ DeepDream是一个可视化神经网络学习模式的实验。 类似于孩子看着云并尝试解释随机形状时,DeepDream会过度解释并增强其在图像中看到的图案。
It does so by forwarding an image through the network, then calculating the gradient of the image with respect to the activations of a particular layer. The image is then modified to increase these activations, enhancing the patterns seen by the network, and resulting in a dream-like image. This process was dubbed “Inceptionism” (a reference to InceptionNet, and the movie Inception).”
它是通过网络转发图像,然后计算图像相对于特定层的激活的梯度来实现的。 然后修改图像以增加这些激活,增强网络可见的模式,并生成类似梦境的图像。 这个过程被称为“ Inceptionism”(对InceptionNet和电影 Inception的引用)。
https://www.tensorflow.org/tutorials/generative/deep dream
https://www.tensorflow.org/tutorials/generative/dee梦
Let me break it down for you. Consider a Convolutional Neural Network.
让我为您分解。 考虑卷积神经网络。
Let us assume we want to check what happens when we increase the highlighted neuron activation h_{i,j}, and we want to reflect these changes onto input image when we increase these activations.
让我们假设我们想检查一下当增加突出显示的神经元激活h_ {i,j}时会发生什么,并且我们想在增加这些激活时将这些变化反映到输入图像上。
In other words, we are optimizing image so that neuron h_{i,j} fires more.
换句话说,我们正在优化图像,以使神经元h_ {i,j }激发更多。
We can pose this optimization problem as:
我们可以将此优化问题提出为:

That is, we need to maximize the square norm (in simple words magnitude), of h_{i,j} by changing image.
也就是说,我们需要通过更改图像来最大化h_ {i,j}的平方范数(简单而言,幅度)。
Here is what happens when we do as said above.
这就是我们如上所述所做的事情。

The reason here is that, when the CNN was trained, the neuron in intermediate layers learned to see some patterns(here dog faces). When we increased those activations, the input image started containing more and more dog faces, to maximize the activations.
原因是,当训练CNN时,中间层的神经元学会了看到一些模式(这里是狗的脸)。 当我们增加这些激活时,输入图像开始包含越来越多的狗脸,以最大化激活。
对文本实施深层梦想的直觉。 (The intuition behind implementing deep dream over text.)
Like deep dream in the image, what if we take any hidden layer activation and try to increase its norm, what will happen to the text input?To answer this, a text-classification model was taken and loss function was set-up to increase the magnitude of the hidden layer’s activation.We would expect to see the patterns/representation learned by this hidden layer.
就像图像中的深梦一样,如果我们进行任何隐藏层激活并尝试增加其范数,文本输入会发生什么呢?为此,我们采用了文本分类模型并设置了损失函数来增加隐藏层激活的大小。我们希望看到该隐藏层学习的模式/表示形式。
模型 (Model)

A model trained to classify IMDB reviews was used. The model achieved validation accuracy of 80.10%.
使用了经过训练可对IMDB评论进行分类的模型。 该模型的验证精度为80.10% 。
The experiment was set up to capture the representation given by Fully Connected layer 2 or FC2 in short with 512 dimensions.
设置实验以捕获512尺寸的全连接第2层或FC2给出的表示。
The cost function used was the norm of fc2 output.
使用的成本函数是fc2输出的范数。
Note: Because “Sequence of Words” are long tensors, they cannot be optimized by back-propagation. Instead, embedding representation of sentence was optimized.
注意:由于“单词序列”是长张量,因此无法通过反向传播进行优化。 相反,优化了句子的嵌入表示。
程序概要 (Outline of Procedure)
Step 1: Convert sentence to tensors.
步骤1:将句子转换为张量。
Step 2: Get the sentence embeddings.
第2步:获取句子嵌入 。
Step 3: Pass through the fc2 layer, and get the fc2 output.
步骤3:穿过fc2层 ,并获得fc2输出 。
Step 4: Optimize the sentence embeddings to increase fc2 layer output.
步骤4:优化句子嵌入,以增加fc2层输出 。
Step 5: Repeat step 2 to step 4 with the current sentence embeddings for a given number of iteration.
步骤5:对当前句子嵌入重复给定数量的迭代,重复步骤2至步骤4。

def dream(input, model, iterations, lr):""" Updates the image to maximize outputs for n iterations """model.eval()out, orig_embeddings, hidden = model(input)model.train()losses = []embeddings_steps = []embeddings = torch.autograd.Variable(orig_embeddings.mean(1), requires_grad=True)embeddings_steps.append(embeddings.clone())for i in range(iterations):out, embeddings, hidden = model.forward_from_embeddings(embeddings)loss = hidden.norm()embeddings.retain_grad()loss.backward(retain_graph=True)avg_grad = np.abs(embeddings.grad.data.cpu().numpy()).mean()norm_lr = lr / avg_gradembeddings.data += norm_lr * embeddings.grad.datamodel.zero_grad()embeddings.grad.data.zero_()losses.append(loss.item())embeddings_steps.append(embeddings.clone())plt.plot(losses)plt.title('activation\'s norm vs iteration')plt.ylabel('activation norm')plt.xlabel('iterations')embeddings_steps = torch.cat(embeddings_steps, dim=0).detach().numpy()return embeddings_steps结果 (Results)
实验1 (Experiment 1)
Simple sentences were used to get classification results and their corresponding sentence embedding we saved.
使用简单的句子来获得分类结果,并保存它们对应的句子嵌入。
For example: “I hate this.” , “I love this show.”, we used to classify. These sentences are very simple and convey a negative and positive emotion respectively.
例如: “我讨厌这个。” ,“我喜欢这个节目。” ,我们曾经进行过分类。 这些句子非常简单,分别传达了负面和正面情感。
Dreaming or optimization over these embeddings was done and a graph of activation over iteration was recorded.
完成了对这些嵌入的梦想或优化 ,并记录了迭代过程中的激活图。

There are a couple of things that can be observed here.
这里有几件事可以观察到。
- Activation of the hidden layer’s representation increased almost linearly for both these sentences
这两个句子的隐藏层表示激活几乎都呈线性增加 - Activations of these sentences are different, which means that model can easily differentiate between these two sentences.
这些句子的激活方式不同,这意味着模型可以轻松区分这两个句子。
For the sentence: “I hate this”. The model correctly predicts this as negative.
对于这句话:“我讨厌这个” 。 模型正确地将此预测为负 。
相似词测试 (Similar words test)
First, we observe what are the words similar (cosine similarity) to the sentence embeddings before and after dreaming.
首先,我们观察做梦之前和之后与句子嵌入相似的词(余弦相似度)。

Initially, sentence embedding as more similar to neutral words like “this, it, even, same” but as we increased the magnitude of the fc2 activations, the sentence embedding became similar to words like “bad, nothing, worse” which convey a negative meaning, which it makes sense, as the model predicted it a negative sentence.
最初,句子的嵌入与“ this,it,even,same ”之类的中性词更相似,但是随着我们增加fc2激活的幅度,句子的嵌入变得与诸如“ 坏,没事,更糟 ”之类的词相似,这传达了否定的含义。意思是有意义的,因为模型预测它为否定句。
可视化迭代中的嵌入。 (Visualizing embeddings over iterations.)
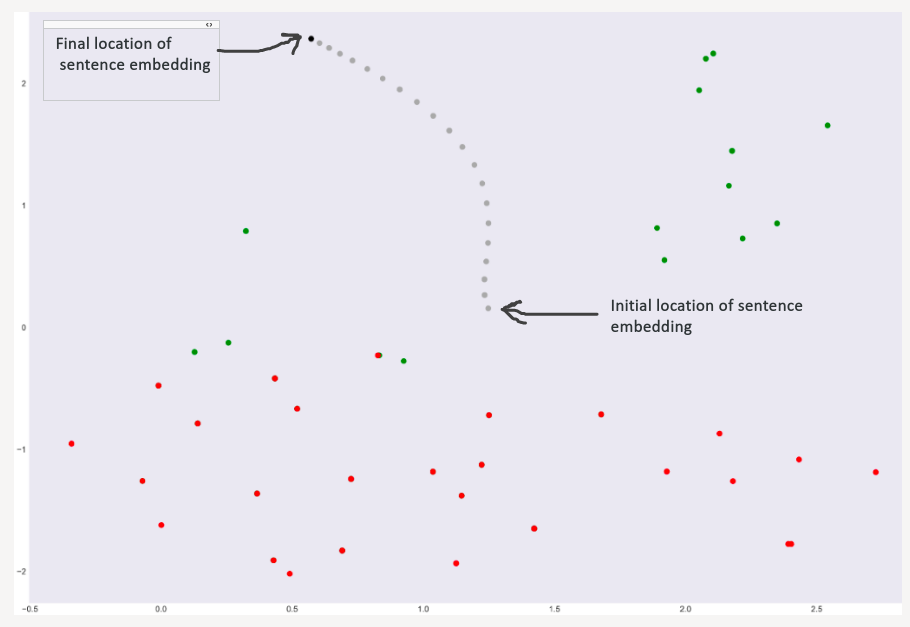
To visualize embeddings over iteration, TSNE algorithm was used to reduce the embedding dimension from 100 to 2. These embeddings were plotted on a 2d map with red dots as negative words(like a bad, worse, mean, mistake) and green dots as positive words(like great, celebrated, wonderful).
为了可视化迭代中的嵌入,使用TSNE算法将嵌入维数从100减小到2 。 这些嵌入被绘制在二维地图上,其中红色点表示否定词(例如,坏,坏,平均,错误), 绿色点表示阳性词(例如好,著名,奇妙)。
Grey dots are intermediate locations of sentence embedding and the black dot is the final location of sentence embedding.
灰点是句子嵌入的中间位置, 黑点是句子嵌入的最终位置。

The graph clearly shows that embeddings got away from positive words and got near negative words and this is in tune with the model prediction. Moreover, the final sentence embedding is now more similar to red dots(negative words) than green dots(positive words).
该图清楚地表明,嵌入远离正词而接近负词,这与模型预测相符。 而且,最终句子的嵌入现在比红点(否定词)更像红点(否定词)。
For the sentence: “I love this show.”. The model correctly predicts this as positive.
对于这句话:“我喜欢这个节目。” 模型正确地将其预测为正 。
相似词测试 (Similar words test)

Initially sentence embedding as more similar to neutral words like “this, it, even same” but as we increased the magnitude of the fc2 activations, the sentence embedding became similar to positive words like “great, unique”, which makes sense, as the model predicted it a positive sentence. Visualizing embeddings over iterations.
最初的句子嵌入与诸如“ this,it,even same”之类的中性词更相似,但是随着我们增加fc2激活的幅度,句子嵌入变得与诸如“伟大的,独特的”之类的正面词相似,这很有意义。模型预测它是一个肯定的句子。 可视化迭代中的嵌入。
The key observation here is that initially, the sentence embedding was in between positive and negative words, but as dreaming progresses the embeddings were pushed away from negative words.
此处的主要观察结果是,最初,句子的嵌入介于正词和负词之间,但是随着梦想的进行 ,嵌入被从负词推开。
结论 (Conclusion)
The word embeddings after dreaming become similar to the words in `model prediction`, though if we look at similar words of initial embeddings, they were more or less same for the two sentences even when they were conveying very different meanings, final sentence embedding showed some interesting patterns.
梦后的词嵌入与“模型预测”中的词相似,尽管如果我们看一下初始词嵌入的相似词,即使两个句子表达的含义非常不同,这两个句子的词也或多或少相同,这表明最终句子的嵌入一些有趣的模式。
E.g.
例如
1. negative prediction was pushed near to words like mistake, dirty, bad
1. 负面的预测被推到错误,肮脏,坏的地方
2. positive prediction was pushed near to words like unique, great, celebrated
2. 积极的预测被推到了诸如独特,伟大,著名的词语附近
演示地址
We visualize the embeddings of sentences. Observe how the sentence embedding change over iteration (specified by step_* )
我们将句子的嵌入可视化。 观察句子嵌入在迭代过程中如何变化(由step_ *指定)
Observe how sentence embedding starts from step_1 and move to step_21. The sentence embedding started in between positive and negative words and as algorithm dreams, the embedding move towards positive words.
观察如何从步骤_1 开始嵌入句子,然后移至步骤21。 句子的嵌入开始于正 词和负词之间,并且随着算法的梦想,嵌入趋向于正词。
You can try a few more things on hosted embeddings on TensorFlow projector here.
您可以在此处在TensorFlow投影仪上的托管嵌入中尝试更多操作。
试试这些。 (Try these things.)
- Observe embeddings in 3d.
观察3d中的嵌入。 Find words similar to step_1.
查找类似于step_1的单词 。
Find words similar to step_21.
查找类似于step_21的单词 。
实验2 (Experiment 2)
We will use difficult sentences now. Sentences which convey one emotion in the first half but change the sentiment in the second half.
我们现在将使用困难的句子。 在上半段传达一种情感但在下半段改变情感的句子。
Sentences like
像这样的句子
- The show was very long and boring but the direction was amazing.
节目很长很无聊,但方向却是惊人的。 - I hated the show because of nudity but the acting was classy.
我讨厌裸露的表演,但表演却很优雅。
These sentences are difficult for a human to judge what kind of emotion they convey.
这些句子对于人类来说很难判断他们传达了什么样的情感。
Again we will optimize the sentence embeddings, to maximize activations in fc2 layer.
再次,我们将优化句子嵌入,以最大化fc2层中的激活。

Unlike the first case. Activations of the two sentences don’t diverge much, i.e. activations for these sentence are more or less similar, this means there is no classifying power of the model for these sentences.Let’s look at the nearby words of these sentences before and after dreaming.
与第一种情况不同。 这两个句子的激活差异不大,也就是说,这两个句子的激活或多或少相似,这意味着这些句子没有模型的分类能力。让我们在做梦之前和之后看看这些句子附近的单词。
For sentence: “The show was very long and boring but the direction was really amazing.”, the model predicted positive
对于句子: “演出很长很无聊,但方向真的很棒。”,该模型预测为积极
Similar Word test
类似单词测试
We will find words similar to initial vs final sentence embedding.
我们会发现与初始句子和最终句子嵌入相似的词。

Hmm, even though the sentence was classified as positive, the words similar to final sentence embedding don’t reflect any positive sentiment.
嗯,即使该句子被归类为肯定句,但与最后一句嵌入类似的词也不能反映任何肯定的情绪。
For sentence: “I hated the show because of nudity but the acting was really classy.”, the model predicted negative
对于句子: “我因为裸露而讨厌演出,但表演确实很优雅。”,该模型预测为负面
Similar Word test
类似单词测试

The sentence was classified as negative, the embeddings after dreaming reflect negative sentiment.
该句子被归类为否定,梦后的嵌入反映了否定情绪。
结论 (Conclusion)
Because the model had no clear understanding of these sentences, the sentence embedding of these two sentences after dreaming are almost similar(look at similar words after dreaming). This is because model does not have a rich representation of these sentences in its hidden layers.
因为模型对这些句子没有清晰的了解,所以梦后这两个句子的句子嵌入几乎相似(梦后看相似的词)。 这是因为模型在其隐藏层中没有这些句子的丰富表示。
We started by looking at how deep dream on images work, then we proposed how we can implement deep dream over text. Finally, we have shown how to correctly interpret the results. This method can be used to understand what kind of hidden representation the language model has learnt.
我们首先研究图像上的深梦,然后提出如何在文本上实现深梦。 最后,我们展示了如何正确解释结果。 此方法可用于了解语言模型学习了哪种隐藏表示。
Experiments like these help us understand these black boxes better.
这样的实验有助于我们更好地理解这些黑匣子。
You can try a demo in this notebook.
您可以在此笔记本中尝试演示 。
All the related code is available at my Github Repo.
我的Github Repo上提供了所有相关代码。
翻译自: https://towardsdatascience.com/dreaming-over-text-f6745c829cee
梦见妈妈
相关文章:
- Project 客户端如何将某一个项目日历应用到其他项目
- Android 在系统日历中添加日程
- Android向系统日历中添加日程事件
- el-calendar 自定义我的日程
- element el-calendar 日历组件可添加展示日程
- “会议室使用情况”实现周日历和日程,可新建日程,鼠标悬浮显示当日日程
- 桌面日历任务管理
- GIS应用技巧之栅格数据裁剪后去锯齿
- gma 教程 | 栅格处理 | 栅格镶嵌
- 10 栅格的使用
- QGIS 3.10 栅格样式与栅格分析
- 传统栅格地图的构建和自定义地图栅格化
- 栅格化布局的简单示例
- ArcGIS中的土地利用变化分析(栅格篇)
- 工程复现 -- 占据栅格地图 G-VOM
- 好看的动漫html页面,漂亮的页面过渡动画
- 页面过渡 页面切换
- 如何在PowerPoint中使用变形过渡
- 页面过渡效果
- 【PPT008】过渡页模板(含资源下载和制作教程)
- 过渡页(桥页)
- 面对新技术,必须找到与其发展相辅相成的长期主义的方法
- Ajax技术的先进性与局限性
- 细数Ajax技术的先进性与局限性
- 率先布局 RWA 赛道,PoseiSwap 成为最具先进性的 DEX
- 日本产品的低成本,德国产品的稳定性,美国产品的先进性,是我们赶超的基准。
- 考研政治——思修-社会主义核心价值观+道德修养
- 专精特新定义及认定标准!
- IP网络广播对讲系统的先进性及系统功能
- 你的先进性体现在哪里?
梦见妈妈_梦见文字!相关推荐
- 昨晚梦见妈妈给做了好多包子
昨晚梦见妈妈给做了好多包子,各种馅的都有,还有煎包,白白的小包子,真好看. 梦里自己吃的可香了--
- zxing换行_让文字自动换行
2018-06-21 让文字上下居中_让文字起舞经典散文 闲来无事,在废纸上写了几句话,仔细一瞧,感觉"套路很深",索然无味.怎样才能"去陈言,得新语",让文字 ...
- PDMS插件_三维文字工具_Text3D
PDMS插件_三维文字工具_Text3D 插件介绍 技术难点 相对优势 存在问题 插件介绍 在PDMS中创建三维实体文字,数字及字母个数有限,容易实现,生成中文比较困难.PDMS三维文字工具Text3 ...
- 最近常常梦见家乡,梦见儿时的同伴了.....
今天想家了,无意识的. 也就是在意识深处的那种想,连自己都觉察不到. 记得读大学的时候,女同学经常打电话回家,边聊边哭.我诧异,问她,你家里出事了吗.她说没什么,就是想家了,听到家里人的声音就禁不住哭 ...
- 古人对梦的解释_梦见古人如何解释梦意_周公解梦梦到古人如何解释梦意是什么意思_做梦梦见古人如何解释梦意好不好...
梦见古人如何解释梦意_周公解梦梦到古人如何解释梦意是什么意思_做梦梦见古人如何解释梦意好不好以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶 ...
- um是代表什么意思_梦见厕所很脏全是屎是什么意思,好不好,代表什么
梦见厕所是什么意思准备考试的人梦见厕所屎,意味着接近录取成绩,稍加努力有希望.谈婚论嫁的人梦见厕所屎,说明水火不相容,未能沟通互相了解,无缘份.创业的人梦见厕所屎,代表反覆不定,多阻碍,重新整顿再开业 ...
- 蓝字冲销是什么意思_梦见上学 做梦梦到上学是什么意思 梦到上学有哪些预兆...
点击上方蓝字关注我们 查看更多 梦见上学是什么意思 做梦梦到上学是什么意思 梦到上学有哪些预兆 梦见上学 做梦梦到念书是什么意思 梦见上学代表什么意思预兆 梦见上学,吉兆,生活会幸福快乐. 梦见上学, ...
- 树莓派安装python3.5_梦见树_周公解梦梦到树是什么意思_做梦梦见树好不好_周公解梦官网...
梦见树是什么意思?做梦梦见树好不好?梦见树有现实的影响和反应,也有梦者的主观想象,请看下面由(周公解梦官网www.zgjm.org)小编帮你整理的梦见树的详细解说吧. 树主健康,树笔直挺拔,象征着人的 ...
- 梦到计算机坏了无法算账,梦见算账,做梦梦见算账是什么征兆?
梦见算账是什么意思,梦见算账究竟好不好呢,很多人都有这方面的 梦见算账 梦见算账,意味着生活会贫困. 做生意的人梦见算账,代表损失较多.不可太过自信,大损失. 本命年的人梦见算账,意味着诸事宜守,不可 ...
最新文章
- 详解Oracle安装与配置.
- 公司-弹出页回调之后加载页面
- KNNClassifier
- Select 可编辑 - 完美支持各大主流浏览器
- (92)FPGA模块例化传递参数(parameter)
- Java学习日报—Swagger介绍 与 布隆过滤器详解—2021/12/01
- 正则表达式大全(汇总)
- 删除60天之前的elasticsearch索引
- Java核心技术卷一基础知识-第3章-Java的基本程序设计结构-读书笔记
- java weblogic 下载_JAVA_weblogic企业级技术 PDF 下载
- 计算机必备四大游戏,超大型游戏必备插件
- 万年历插件软件测试,万年历软件测试方案.docx
- python题目-判断素数
- 中国电信php,一个基于中国电信开放应用平台的短信发送函数(PHP版)
- 87键键盘insert键使用方法
- 控制面板里卸载软件的入口注册表项
- 数据结构基础--搜索树
- Ubuntu 18.04 安装搜狗拼音
- 学习笔记-应用编程与网络编程-2(文件属性+附代码)
- 拓扑结构和几何结构的区别