一个百亿级日志系统是怎么设计出来的?
日志是记录系统中各种问题信息的关键,也是一种常见的海量数据。

日志平台为集团所有业务系统提供日志采集、消费、分析、存储、索引和查询的一站式日志服务。
主要为了解决日志分散不方便查看、日志搜索操作复杂且效率低、业务异常无法及时发现等等问题。
随着有赞业务的发展与增长,每天都会产生百亿级别的日志量(据统计,平均每秒产生 50 万条日志,峰值每秒可达 80 万条)。日志平台也随着业务的不断发展经历了多次改变和升级。
本文跟大家分享有赞在当前日志系统的建设、演进以及优化的经历,这里先抛砖引玉,欢迎大家一起交流讨论。
原有日志系统
有赞从 2016 年就开始构建适用于业务系统的统一日志平台,负责收集所有系统日志和业务日志,转化为流式数据。
通过 Flume 或者 Logstash 上传到日志中心(Kafka 集群),然后供 Track、Storm、Spark 及其他系统实时分析处理日志。
并将日志持久化存储到 HDFS 供离线数据分析处理,或写入 ElasticSearch 提供数据查询。
整体架构如图 2-1 所示:
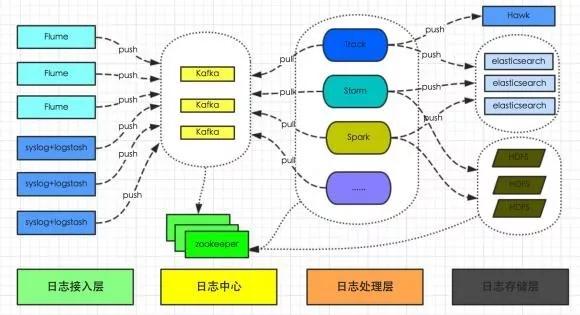
图 2-1:原有日志系统架构
随着接入的应用越来越多,接入的日志量越来越大,逐渐出现一些问题和新的需求,主要在以下几个方面:
- 业务日志没有统一的规范,业务日志格式各式各样,新应用接入无疑大大的增加了日志的分析、检索成本。
- 多种数据日志数据采集方式,运维成本较高。
- 日志平台收集了大量用户日志信息,当时无法直接的看到某个时间段,哪些错误信息较多,增加定位问题的难度。
- 存储方面。
关于存储方面:
- 采用了 ES 默认的管理策略,所有的 Index 对应 3*2 Shard(3 个 Primary,3 个 Replica)。
有部分 Index 数量较大,对应单个 Shard 对应的数据量就会很大,导致有 Hot Node,出现很多 bulk request rejected,同时磁盘 IO 集中在少数机器上。
- 对于 bulk request rejected 的日志没有处理,导致业务日志丢失。
- 日志默认保留 7 天,对于 SSD 作为存储介质,随着业务增长,存储成本过于高昂。
- 另外 Elasticsearch 集群也没有做物理隔离,ES 集群 OOM 的情况下,使得集群内全部索引都无法正常工作,不能为核心业务运行保驾护航。
现有系统演进
日志从产生到检索,主要经历以下几个阶段:
- 采集
- 传输
- 缓冲
- 处理
- 存储
- 检索
详细架构如图 3-1 所示:
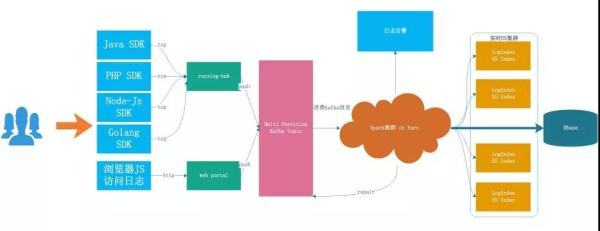
图 3-1:现有系统架构
日志接入
日志接入目前分为两种方式:
- SDK 接入:日志系统提供了不同语言的 SDK,SDK 会自动将日志的内容按照统一的协议格式封装成最终的消息体,并最后最终通过 TCP 的方式发送到日志转发层(Rsyslog-Hub)。
- HTTP Web 服务接入:有些无法使用 SDK 接入日志的业务,可以通过 HTTP 请求直接发送到日志系统部署的 Web 服务,统一由 Web Protal 转发到日志缓冲层的 Kafka 集群。
日志采集

现在有 Rsyslog-Hub 和 Web Portal 做为日志传输系统,Rsyslog 是一个快速处理收集系统日志的程序,提供了高性能、安全功能和模块化设计。
之前系统演进过程中使用过直接在宿主机上部署 Flume 的方式,由于 Flume 本身是 Java 开发的,会比较占用机器资源而统一升级为使用 Rsyslog 服务。
为了防止本地部署与 Kafka 客户端连接数过多,本机上的 Rsyslog 接收到数据后,不做过多的处理就直接将数据转发到 Rsyslog-Hub 集群。
通过 LVS 做负载均衡,后端的 Rsyslog-Hub 会通过解析日志的内容,提取出需要发往后端的 Kafka Topic。
日志缓冲
Kafka 是一个高性能、高可用、易扩展的分布式日志系统,可以将整个数据处理流程解耦。
将 Kafka 集群作为日志平台的缓冲层,可以为后面的分布式日志消费服务提供异步解耦、削峰填谷的能力,也同时具备了海量数据堆积、高吞吐读写的特性。
日志切分
日志分析是重中之重,为了能够更加快速、简单、精确地处理数据。日志平台使用 Spark Streaming 流计算框架消费写入 Kafka 的业务日志。
Yarn 作为计算资源分配管理的容器,会跟不同业务的日志量级,分配不同的资源处理不同日志模型。
整个 Spark 任务正式运行起来后,单个批次的任务会将拉取到的所有的日志分别异步的写入到 ES 集群。
业务接入之前可以在管理台对不同的日志模型设置任意的过滤匹配的告警规则,Spark 任务每个 Excutor 会在本地内存里保存一份这样的规则。
在规则设定的时间内,计数达到告警规则所配置的阈值后,通过指定的渠道给指定用户发送告警,以便及时发现问题。
当流量突然增加,ES 会有 bulk request rejected 的日志重新写入 Kakfa,等待补偿。
日志存储
原先所有的日志都会写到 SSD 盘的 ES 集群,LogIndex 直接对应 ES 里面的索引结构。
随着业务增长,为了解决 ES 磁盘使用率单机最高达到 70%~80% 的问题,现有系统采用 Hbase 存储原始日志数据和 ElasticSearch 索引内容相结合的方式,完成存储和索引。
Index 按天的维度创建,提前创建 Index 会根据历史数据量,决定创建明日 Index 对应的 Shard 数量,也防止集中创建导致数据无法写入。
现在日志系统只存近 7 天的业务日志,如果配置更久的保存时间的,会存到归档日志中。
对于存储来说,Hbase、ES 都是分布式系统,可以做到线性扩展。
多租户
随着日志系统不断发展,全网日志的 QPS 越来越大,并且部分用户对日志的实时性、准确性、分词、查询等需求越来越多样。
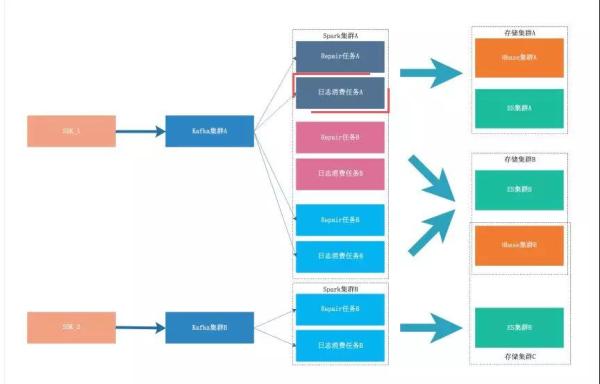
为了满足这部分用户的需求,日志系统支持多租户的的功能,根据用户的需求,分配到不同的租户中,以避免相互影响。
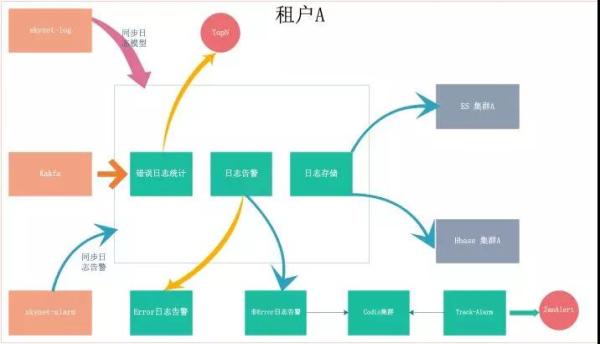
针对单个租户的架构如下:
- SDK:可以根据需求定制,或者采用天网的 TrackAppender 或 SkynetClient。
- Kafka 集群:可以共用,也可以使用指定 Kafka 集群。
- Spark 集群:目前的 Spark 集群是在 Yarn 集群上,资源是隔离的,一般情况下不需要特地做隔离。
- 存储:包含 ES 和 Hbase,可以根据需要共用或单独部署 ES 和 Hbase。
现有问题和未来规划
目前,有赞日志系统作为集成在天网里的功能模块,提供简单易用的搜索方式,包括时间范围查询、字段过滤、NOT/AND/OR、模糊匹配等方式。
并能对查询字段高亮显示,定位日志上下文,基本能满足大部分现有日志检索的场景。
但是日志系统还存在很多不足的地方,主要有:
- 缺乏部分链路监控:日志从产生到可以检索,经过多级模块,现在采集,日志缓冲层还未串联,无法对丢失情况进行精准监控,并及时推送告警。
- 现在一个日志模型对应一个 Kafka Topic,Topic 默认分配三个 Partition。
由于日志模型写入日志量上存在差异,导致有的 Topic 负载很高,有的 Topic 造成一定的资源浪费,且不便于资源动态伸缩。
Topic 数量过多,导致 Partition 数量过多,对 Kafka 也造成了一定资源浪费,也会增加延迟和 Broker 宕机恢复时间。
- 目前 Elasticsearch 中文分词我们采用 ikmaxword,分词目标是中文,会将文本做最细粒度的拆分,但是日志大部分都是英文,分词效果并不是很好。
上述的不足之处也是我们以后努力改进的地方,除此之外,对于日志更深层次的价值挖掘也是我们探索的方向,从而为业务的正常运行保驾护航。
一个百亿级日志系统是怎么设计出来的?相关推荐
- 如何设计日志系统_架构 - 如何设计一个百亿级日志系统
" 日志是记录系统中各种问题信息的关键,也是一种常见的海量数据. 日志平台为集团所有业务系统提供日志采集.消费.分析.存储.索引和查询的一站式日志服务. 主要为了解决日志分散不方便查看.日志 ...
- 百亿级日志系统架构设计及优化
作者:杨津萍,大数据架构师,从业十余年,专攻 Web 架构及大数据架构. 来自:51cto技术栈(ID:blog51cto) " 日志数据是最常见的一种海量数据,以拥有大量用户群体的电商平台 ...
- 系统分析之100亿级日志系统是怎么设计出来的?
日志是记录系统中各种问题信息的关键,也是一种常见的海量数据. 日志平台为集团所有业务系统提供日志采集.消费.分析.存储.索引和查询的一站式日志服务. 主要为了解决日志分散不方便查看.日志搜索操作复杂且 ...
- Github星标90K?京东架构师一篇讲明白百亿级并发系统架构设计
学习高并发系统设计的原因 高并发到底是什么,想必各位多多少少对此都有所了解,那我在这就不多说了.真正经历过"双11"以及"618"的小伙伴应该都知道,在大促时如 ...
- 日均百亿级日志处理:微博基于Flink的实时计算平台建设
来自:DBAplus社群 作者介绍 吕永卫,微博广告资深数据开发工程师,实时数据项目组负责人. 黄鹏,微博广告实时数据开发工程师,负责法拉第实验平台数据开发.实时数据关联平台.实时算法特征数据计算.实 ...
- 百亿级通用推荐系统实践
我们每个人每天都会使用到不同的推荐系统,无论是听歌,购物,看视频,还是阅读新闻,推荐系统都可以根据你的喜好给你推荐你可能感兴趣的内容.不知不觉之间,推荐系统已经融入到我们的生活当中.作为大数据时代最重 ...
- 双良集团:从百亿级市场向万亿级市场的跃迁 | 倒计时15天
关注ITValue,查看企业级市场最新鲜.最具价值的报道! 摘要:从卖设备到卖服务,从卖空调到卖能源管理,双良在为自己寻求转型升级的同时,也打开了一个全新的市场."双良做服务型制造企业是一 ...
- 开元媒体观察之:传统媒体的生死劫与重大机遇——百亿级网络版权平台或将诞生
开元研究陈愈超 2013年,对于中国传统媒体来讲,无疑是糟糕的一年,对于平面媒体,各种报纸杂志被关停的消息不断传来:对于电视媒体,广电总局发布的<中国视听新媒体发展报告>调查显示,北京地区 ...
- redis 亿级查询速度_亿级流量系统架构之如何保证百亿流量下的数据一致性(上)...
欢迎关注头条号:石杉的架构笔记 周一至周五早八点半!精品技术文章准时送上!!! 目录 一.前情提示 二.什么是数据一致性? 三.一个数据计算链路的梳理 四.数据计算链路的bug 五.电商库存数据的不一 ...
最新文章
- boost::safe_numerics模块实现混合类型产生令人惊讶的结果的测试程序
- C | 构成和编码规范
- 336计算机考研怎么做到啊,【图片】2020考研,老学长教你如何规划!【计算机考研吧】_百度贴吧...
- c# 客户端 服务器传输文件,通过TCP在C++客户端/ C#服务器之间传输文件
- greasyfork脚本怎么取消_更新了js脚本,回答一些常见问题
- Quick Sort(三向切分的快速排序)(Java)
- python 抓取搜狗微信出现的问题,求大神解决
- 企业应当如何编制信息安全策略
- 【win10】装机必备推荐软件,提升你的计算机使用效率!
- 鸿蒙开发工具下载设置Mac
- 《终极算法》读书笔记(二)终极算法
- 使用 SnakeYAML 操作 YAML 数据
- 什么软件可以查手机卡的imsi_怎么查看手机的IMSI?
- 科学技术法-正则表达式-QT
- app installation failed 的问题的解决过程
- 基于第二届易观算法大赛——性别年龄预测中数据的分析(娱乐向)
- 头条校招(今日头条2017秋招真题)
- 【零基础微信小程序入门开发一】小程序介绍及环境搭建
- vbs和java有关系吗_Java程序员所需的批处理和VBS脚本 (转载)
- 虚拟机soft lockup CPU死锁问题
热门文章
- python爬取数据
- c语言版票务管理系统,火车票务管理系统(C语言版)【TXT文件,改后缀即可】
- 位运算 c语言 头文件 linux,1. 位运算_C语言_C语言入门-Linux C编程一站式学习...
- url模糊匹配优化_详情页怎么做SEO优化?
- python删除文本中指定内容_Python实现删除文件中含“指定内容”的行示例
- mysql clob转string_Java获取Oracle中CLOB字段转换成String
- java强制执行方法_java – 在多台机器上强制执行单一速率限制的好方法是什么?...
- Linux 进内核,arm linux 启动流程之 进入内核
- python正则表达式匹配模式屠夫之桥_Python 编程快速上手 第 7章 模式匹配与正则表达式...
- centos mysql pmm_【MySQL】MySQL监控利器PMM