机器学习算法概述:随机森林逻辑回归
摘要: 机器学习算法入门介绍:随机森林与逻辑回归!

随机森林是用于分类和回归的监督式集成学习模型。为了使整体性能更好,集成学习模型聚合了多个机器学习模型。因为每个模型单独使用时性能表现的不是很好,但如果放在一个整体中则很强大。在随机森林模型下,使用大量“弱”因子的决策树,来聚合它们的输出,结果能代表“强”的集成。
权衡偏差与方差
在任何机器学习模型中,有两个误差来源:偏差和方差。为了更好地说明这两个概念,假设已创建了一个机器学习模型并已知数据的实际输出,用同一数据的不同部分对其进行训练,结果机器学习模型在数据的不同部分产生了不同的输出。为了确定偏差和方差,对这两个输出进行比较,偏差是机器学习模型中预测值与实际值之间的差异,而方差则是这些预测值的分布情况。
简而言之:
偏差是当算法作了太多简化假设之后出现的错误,这导致模型预测值与实际值有所出入。
方差是由于算法对训练数据集中小变化的敏感性而产生的误差;方差越大,意味着算法受数据变化的影响更大。
理想情况下,偏差和方差都会很小,这意味模型在相同数据集的不同数据中的预测值很接近真值。当这种情况发生时,模型可以精确地学习数据集中的潜在模式。
随机森林是一种减少方差的算法
决策树以高方差、低偏差为人所知。这主要是因为它能够对复杂的关系,甚至是过拟合数据中的噪声进行建模。简单地说:决策树训练的模型通常是精确的,但常常在同一数据集中的不同数据样本之间显示出很大程度的变化。
随机森林通过聚合单个决策树的不同输出来减少可能导致决策树错误的方差。通过多数投票算法,我们可以找到大多数单个树给出的平均输出,从而平滑了方差,这样模型就不容易产生离真值更远的结果。
随机森林思想是取一组高方差、低偏差的决策树,并将它们转换成低方差、低偏差的新模型。
为什么随机森林是随机的?
随机森林中的随机来源于算法用训练数据的不同子集训练每个单独的决策树,用数据中随机选择的属性对每个决策树的每个节点进行分割。通过引入这种随机性元素,该算法能够创建彼此不相关的模型。这导致可能的误差均匀分布在模型中,意味着误差最终会通过随机森林模型的多数投票决策策略被消除。
随机森林实际是如何工作的?
想象一下,你厌倦了一遍又一遍地听着同样的电子音乐,强烈地想找到一些可能喜欢的新音乐,所以你上网去寻找推荐,找到了能让真实的人根据你的喜好给你音乐建议的一个网站。
那么它是如何工作的呢?首先,为了避免建议的随机性,先填写一份关于自己的基本音乐喜好的问卷,为可能喜欢的音乐类型提供一个标准。然后网友利用这些信息开始根据你提供的标准(特征)来分析歌曲,此时每个人本质上都是一个决策树。
就个人而言,网上提出建议的人并不能很好地概括你的音乐喜好。比如,有人可能会认为你不喜欢80年代之前的任何歌曲,因此不会给你推荐这些歌曲。但是这假设可能不准确,并可能会导致你不会收到喜欢的音乐的建议。
为什么会发生这种错误?每一个推荐人对你的喜好的了解都是有限的,而且他们对自己个人的音乐品味也是有偏见的。为了解决这个问题,我们统计来自许多个人的建议(每个人都扮演决策树的角色),并对他们的建议使用多数投票算法(本质上是创建一个随机森林)。
然而,还有一个问题——因为每个人都在使用来自同一份问卷的相同数据,因此得出的建议将会是类似的,而且可能具有高度的偏见和相关性。为了扩大建议的范围,每个推荐人都会得到一组调查问卷的随机答案,而不是所有的答案,这意味着他们的推荐标准更少。最后,通过多数投票消除了极端异常值,你就会得到一个准确而多样的推荐歌曲列表。
总结
随机森林的优点:
1.不需要特征归一化;
2.可并行化:单个决策树可以并行训练;
3.广泛使用的;
4.减少过拟合;
随机森林的缺点:
1.不容易解释
2.不是最先进的方法

逻辑回归是一个使用分类因变量预测结果的监督式统计模型。分类变量的值为名称或标签,例如:赢/输、健康/生病或成功/失败。该模型也可用于两类以上的因变量,这种情况称多项逻辑回归。
逻辑回归是基于历史信息构建给定数据集的分类规则,这些数据集被划分为不同的类别。模型公式为:

相关术语定义如下:
c=1,...,C是因变量Y的所有可能类别;
P(Y=c)是因变量为类别c的概率;
\beta_{{i}},i=1,...,I是回归系数,当进行转换时,表示每个变量在解释概率方面的重要性;
X_{{i}},i=1,...,I是自变量。
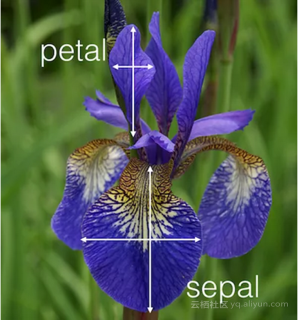
我们将使用之前博文中的鸢尾花数据集来说明逻辑回归是如何工作的。这些数据由150种鸢尾花组成,按照植物种类(这个数据集中有三种不同的种类)、萼片和花瓣长度、萼片和花瓣宽度等特征进行分类,我们仅使用萼片和花瓣来描述每朵鸢尾花。我们还将建立一个分类规则来判断数据集中引入的新植物的种类。图1展示了一朵鸢尾的萼片和花瓣的尺寸。
首先,我们必须将数据集分成两个子集:训练和测试。训练集占整个数据集的60%,用于使模型与数据相匹配,测试集占其余40%的数据,用于检查模型是否与给定的数据正确匹配。
利用上述公式,我们将数据拟合到逻辑回归模型中。在这种情况下,因变量为植物种类,类别数等于3,自变量(x_{{i}},i=1,...4\right)是萼片和花瓣的长度和宽度。图2显示了数据的一个子集。
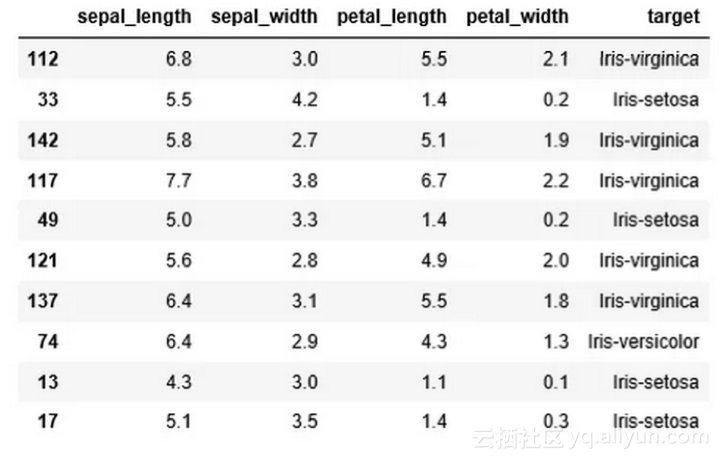
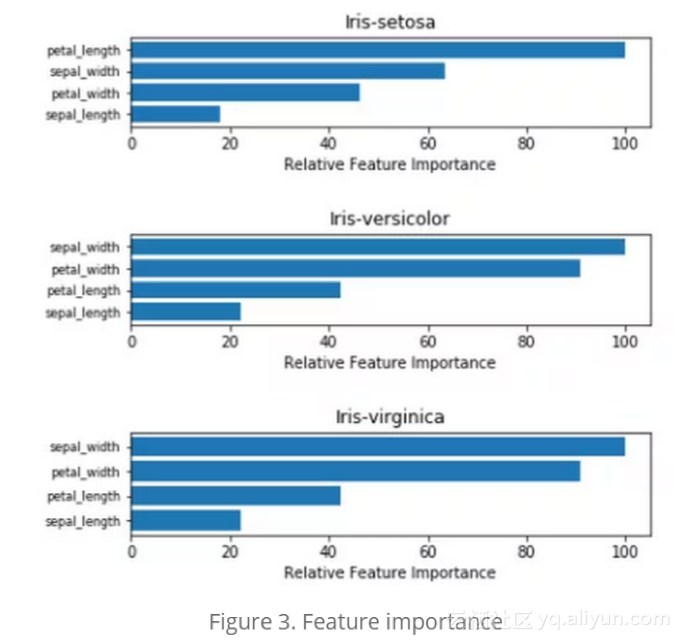
表1给出了三种植物中每个自变量系数的估计。显而易见,花瓣的长度和宽度是特征描述过程中最重要的变量。因此,在每个物种的特征重要性图中强调了这两个变量(图3)。
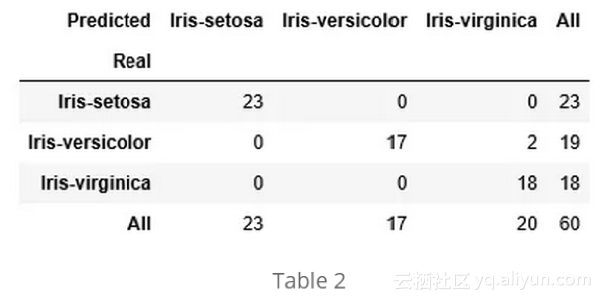
接下来,我们创建了一个混淆矩阵(误差矩阵)来检验模型的性能。这个矩阵把测试数据集中已知的鸢尾花植物类别与拟合模型预测的鸢尾花植物类别进行比较,我们的目标是两者相同。在表2中,我们看到模型的性能相对较好,只有两种花色植物被错误分类。
基于这些结果,我们能够对数据集中的各种鸢尾植物进行正确的分类。然而,正如前面提到的,我们现在必须制定一个分类规则。接着是通过新鸢尾属植物的自变量值乘以表1中的系数估计来计算新鸢尾植物属于给定类别的概率,新鸢尾的结果如下表3所示:
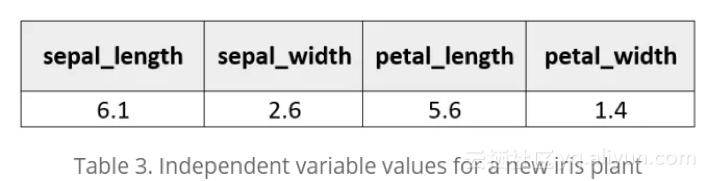
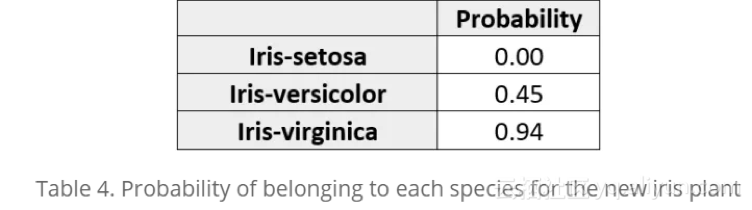
然后,我们使用前面的公式计算了鸢尾植物为各个类别的概率。结果证实上述鸢尾植物很可能属于维吉尼亚鸢尾。
总结
逻辑回归的优点:
1.可解释性;
2.模型简单;
3.可扩展性;
逻辑回归的缺点:
1.假设特征之间的相对独立性;
原文链接
本文为云栖社区原创内容,未经允许不得转载。
机器学习算法概述:随机森林逻辑回归相关推荐
- 机器学习算法:随机森林
在经典机器学习中,随机森林一直是一种灵丹妙药类型的模型. 该模型很棒有几个原因: 与许多其他算法相比,需要较少的数据预处理,因此易于设置 充当分类或回归模型 不太容易过度拟合 可以轻松计算特征重要性 ...
- 【机器学习算法笔记系列】逻辑回归(LR)算法详解和实战
逻辑回归(LR)算法概述 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 逻辑 ...
- 机器学习算法(3)—— 逻辑回归算法
逻辑回归算法 1 逻辑回归介绍 2 损失及优化 3 逻辑回归的使用 4 分类评估方法 4.1 混淆矩阵 4.2 ROC曲线与AUC指标 4.3 ROC曲线绘制 5 分类中类别不平衡问题 5.1 过采样 ...
- 机器学习算法总结--随机森林
简介 随机森林指的是利用多棵树对样本进行训练并预测的一种分类器.它是由多棵CART(Classification And Regression Tree)构成的.对于每棵树,其使用的训练集是从总的训练 ...
- 机器学习算法总结--线性回归和逻辑回归
1. 线性回归 简述 在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析.这种函数是一个或多个称为回 ...
- 机器学习算法(四)逻辑回归理论与python实现+经典示例(从疝气病预测病马的死亡率)
学习笔记更新 什么是逻辑回归? 简要介绍 逻辑回归是用来解决线性回归问题的,它将线性回归得到的结果通过逻辑函数映射到[0,1]之间,因此称逻辑回归.逻辑回归模型主要用于解决二分类问题,是一个分 ...
- 【机器学习算法-python实现】逻辑回归的实现(LogicalRegression)
1.背景知识 在刚刚结束的天猫大数据s1比赛中,逻辑回归是大家都普遍使用且效果不错的一种算法. (1)回归 先来说说什么是回归,比如说我们有两类数据,各有50十个点 ...
- 金融风控机器学习第三十一天---拜师课堂 机器学习算法--决策树 随机森林
ID3 c4.5的核心是熵 ID3 c4.5 cart 过拟合解决一般 用 剪枝 或者 随机森林 随机森林代码: #!/usr/bin/python # -*- coding:utf-8 -*-imp ...
- 随机森林实例:利用基于CART算法的随机森林(Random Forest)树分类方法对于红酒质量进行预测
随机森林实例:利用基于CART算法的随机森林(Random Forest)树分类方法对于红酒质量进行预测 1.引言 2.理论基础 2.1 什么是决策树 2.2 特征选择的算法 2.2.1 ID3:基于 ...
最新文章
- 使用ssh连接gitHub
- C# AutoMapper的简单扩展
- 架构师之路 — API 经济 — RESTful API
- 定向输出命令_Linux系统管理-输入输出
- 【五】搜索推荐技术在电商导购领域的应用——截图小王子
- 全面解析java注解
- 12月16日文章排行点评及编辑部训练
- kafka生产者和消费者端的数据不一致
- This generally means that another instance of this process was already runni
- mysql分区表mycat_MySQL 中间件之Mycat垂直分表配置
- c#实现对sqlserver的增删改操做 1117
- 大话设计模式读书笔记(十三) 状态模式
- 腾讯联手国家信息中心启动共筑疫情“数据长城”计划
- redis 哨兵的原理
- 最齐全的装饰贴图素材,速来收藏
- Java面向对象三大特征
- 典型飞行控制系统的回路构成
- SVN版本管理的回滚(SmartSVN)
- c语言max()头文件,C语言:min和max头文件
- CDH5 安装需求和相关软件支持的版本信息
热门文章
- python怎么理解_讨论 - 廖雪峰的官方网站
- lisp正负调换_lisp中如何把符号转换为字符串
- python 取余_玩转Python源码(一) quot;%squot;与“%d”
- 启动马达接线实物图_东元伺服驱动马达
- mysql5.7.24 安装步骤_MySQL5.7.24解压版安装步骤
- python打包出现乱码_python解压zip包中文乱码解决方法
- mesh 协调器 路由器_关于Mesh网络中,协调器和路由器之间的几个问题?
- 该计算机没有运行windows无线服务器,老司机示范win7系统诊断提示此计算机上没有运行的windows无线服务的恢复方法...
- 通过思科构造局域网_cisco设备构建典型局域网
- java 网络编程connection timed out是什么意思_什么?听说这四个概念,很多 Java 老手都说不清...